关于查询类接口的一些总结
由于项目需要,最近在写一个接口测试脚本,所以许久没有更新了,不过写完后,也有一些收获和大家分享一下
本次写的主要是查询类接口,所以重点说一下编写查询类接口时用到的一些方法
1. 按照日期查询
这类查询功能,在平时测试时往往需要选定一个日期,点击查询,然后查看列表中列出的结果是否符合预期
那么针对日期类的查询,如何构造有效的参数呢
要考虑一点:如何使所选定的日期长久有效
假如选定2019-05-01至2019-05-29,
它存在的问题是,到了2020年再执行这个脚本时,数据就显得比较旧,甚至由于清除数据库脏数据,再也查不到结果了,所以尽量不要指定日期
有一个解决方法,先获取当前日期,然后往前倒退30天、50天等
例如今天是2019-10-29,那就查询2019-09-29至2019-10-29的数据,永远以当前日期为基准
获取当前日期,可以用python自带的datetime模块
#coding:UTF-8 import datetime now_date = datetime.datetime.now() # 获取今天时间 # print(now_date) end_date = now_date.strftime("%Y-%m-%d") # 定义今天时间为查询结束时间,并转为字符串对象,以年-月-日格式输出 offset = datetime.timedelta(days=-50) # 定义偏移量,即与当前日期的时间间隔 begin_date = (now_date + offset).strftime("%Y-%m-%d") # 定义查询开始时间=当前时间回退50天
2. 从一批响应内容中随机取出一个进行断言
使用random.choice()方法,从一组数据中随机取出一个,一般是从一个列表、元祖或字符串中抽取数据
假如一个查询接口中返回了多组数据,每组数据的构造相似,这时做断言的话,不可能每个数据都匹配一次
如下拉勾网搜索一个职位时
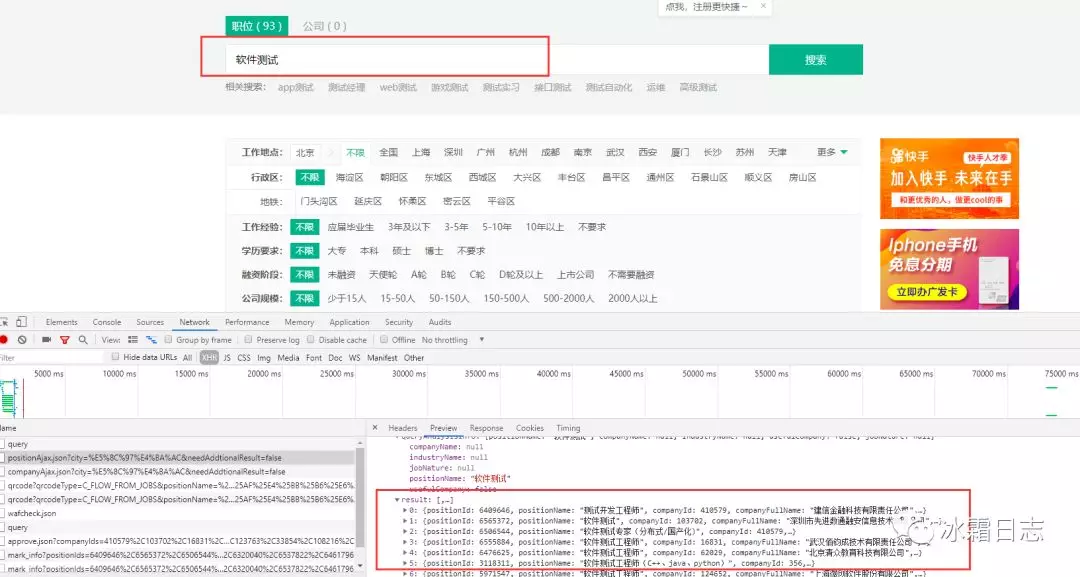
可以看到result列表中包含许多条职位信息,每个职位信息都各自在一个json字符串中,断言时,只需取其中一组数据即可;
问题来了,选哪一组进行断言,第一组?最后一组?指定一组?
第一组可以达到目的,最后一组也行
但是指定断言一组不靠谱,因为这次查询可能返回了3组,下次可能返回了2组
还有一种方式,就是随机取一组数据进行断言,
这时候就可以使用random.choice()方法,从所有返回结果中随机取出一组数据,再将那一组数据的某个值与预期断言即可
示例:
>>>import random >>>numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9] >>>random.choice(numbers) 5 >>> for i in range(3): # 循环8次,每次随机取一个数 random.choice(numbers) 4 4 9
之前写过一个电话号码生成器(可以到历史文章中查看详细介绍),也用到了random.choice()
3.利用字符串切片断言电话号码后四位
有时候一些敏感信息需要进行脱敏处理,例如会把电话号码或身份证号码的中间几位进行加密处理,常见形式如下
188****8888
当以电话号码进行查询时,返回结果中一般也会把电话加密,不过既然是根据电话号码来查询,如果响应中有返回号码信息,最好还是用电话号码进行断言
这时候可以匹配电话号码的后四位,如果匹配成功则认为查询结果正确
因此可以使用切片方法来取出电话号码的后四位
>>> phone = "188****8888" >>> phone '188****8888' >>> phone[-4:] '8888' >>>
4. 使用zip()函数遍历2个列表,将信息组合显示
场景:比如按照某个主题进行查询时,实际传参传的是该主题对应的编号,
例如『主题A』对应编号『11』,『主题B』对应编号『22』
在编写脚本时,我希望打出的日志更人性化,
可以打印出:查询『主题编号"11",对应的主题名称为"主题A"』的数据有xx条
由于主题名称和主题编号是在2个列表中,所以就想如何把2个列表关联起来呢? 能不能同时迭代2个列表,将主题名称与主题编号对应起来?
于是就找到了zip()函数
网上的一个简单例子:
>>> list1 = ['a', 'b', 'c', 'd'] >>> list2 = ['apple', 'boy', 'cat', 'dog'] >>> for x, y in zip(list1, list2): print(x, 'is', y) # 输出 a is apple b is boy c is cat d is dog
复杂一点的例子,列表中包含字典
>>> a = [{"first_name":1,"second_name":2,"third_name":3},
{"first_name":4,"second_name":5,"third_name":6},
{"first_name":7,"second_name":8,"third_name":9}]
b = [{"first":11,"second":22,"third":33},
{"first":44,"second":55,"third":66},
{"first":77,"second":88,"third":99}]
>>> for x,y in zip(a,b):
print("一级主题名称:{},一级id:{}~二级主题名称:{},二级id:{}~三级主题名称:{},三级id:{}".format(x["first_name"],y["first"],x["second_name"],y["second"],x["third_name"],y["third"]))
运行结果如下:
一级主题名称:1,一级id:11~二级主题名称:2,二级id:22~三级主题名称:3,三级id:33
一级主题名称:4,一级id:44~二级主题名称:5,二级id:55~三级主题名称:6,三级id:66
一级主题名称:7,一级id:77~二级主题名称:8,二级id:88~三级主题名称:9,三级id:99
5.format()函数在编写sql语句中的应用
python中的sql语句需要写在一对引号中,例如
original_sql = "select * from movies where movie_name = '疯狂动物城'"
上面语句中movie_name字段目前是一个固定值,假如切换环境执行,如果对应的数据库没有"疯狂动物城"这条数据,那么这个sql查询就会失效,返回为空
所以我们需要保证要查询的movie_name尽可能有值
假如此时有一个接口可以获取movie_name或者事先准备好一批movie_name值
那么就可以读取接口返回的movie_name或者读取提前准备好的amovie_name
因此需要想办法使sql语句中的movie_name参数化,能够动态读取传进来的值
仔细看上面的sql语句,注意到sql语句包含在一对引号中,所以它就相当于一个字符串,因此可以利用format()函数来达到目的
使用方法如下
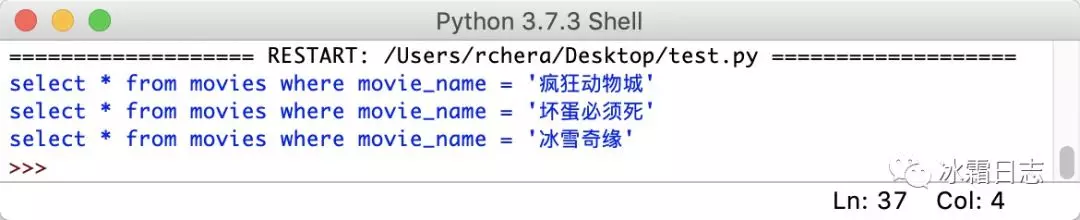
movies = ["疯狂动物城", "坏蛋必须死", "冰雪奇缘"] original_sql = "select * from movies where movie_name = '{}'" # 注意因为sql中字符要用引号包裹,所以这里的{}也需要用引号括起来({}可以看作是一个预定的位置,存放movie_name的值) for i in movies: sql = original_sql.format(i) print(sql)
运行结果
再来看例子,假如一个名为get_name()的方法,返回电影的名称,一个名为get_date()的方法,返回电影的上映日期
接下来要把电影名称和上映时间放到sql的查询条件中
original_sql = "select * from movies where movie_name = '{}' and release_date = '{}'" sql = original_sql.format(self.get_name(), self.get_date())
另外format()函数也可以设置参数
上面的例子,可以改为
original_sql = "select * from movies where movie_name = '{name}' and release_date = '{date}'" sql = original_sql.format(name=self.get_name(), date=self.get_date())
6.正则表达式提取中文字符
有时接口返回的某个字段值得时候,会自动加上某个后缀
例如姓名:张三qt,李四1,王五rw
其实数据库中存在的数据不带后缀,就是单纯的中文字符
例如:
select * from name_list where name = '张三' #可以查到数据
select * from name_list where name = '张三qt' #查不到数据
所以在通过接口获取到这些数据后,需要处理一下,只保留中文字符,然后传给sql查询语句
这里通过正则表达式的方式来处理
import re name = "张三rx" pattern = re.compile(r'[\u4e00-\u9fa5]') # 定义一个正则表达式,去掉字符串末尾的数字 m = pattern.findall(name) # 匹配结果,返回每个汉字组成的列表 print(m) real_name = "".join(m) # 将每个汉字组成一个字符串 print(real_name)
运行结果
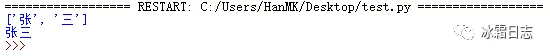

 浙公网安备 33010602011771号
浙公网安备 33010602011771号