Python基础day4 函数对象、生成器 、装饰器、迭代器、闭包函数
一、函数对象
正确理解 Python函数,能够帮助我们更好地理解 Python 装饰器、匿名函数(lambda)、函数式编程等高阶技术。
函数(Function)作为程序语言中不可或缺的一部分,太稀松平常了。但函数作为第一类对象(First-Class Object)却是 Python 函数的一大特性。那到底什么是第一类对象(First-Class Object)呢?
在 Python 中万物皆为对象,函数作为第一类对象有如下特性:
#函数身为一个对象,拥有对象模型的三个通用属性:id(内存地址)、类型、和值
def foo(text):
return len(text)
print(type(foo)) #函数类型
print(id(foo))#函数id 内存地址
print(foo)#函数值
- 可以作为变量赋值
#函数可以被引用,即函数可以赋值给一个变量
#!/usr/bin/env python # -*- coding:utf-8 -*- def foo(): print('from foo') foo() func=foo #引用,赋值 print(foo) print(func) func()
输出:
from foo
内存地址一样说明func引用的是foo函数地址,也就是foo将地址赋值给func变量
<function foo at 0x0000000002063E18>
<function foo at 0x0000000002063E18>
- 可以作为容器类型(集合)的元素
#容器对象(list、dict、set等)中可以存放任何对象,包括整数、字符串,函数也可以作存放到容器对象中
def foo():
print("hanjialong")
dif={"func":foo}
# foo()
if __name__ == '__main__':
dif={"func":foo}
dif["func"]()
#比较函数地址
def foo():
print("hanjialong")
dif={"func":foo}
print(foo)
# dif={"func":foo}
# dif["func"]()
print(dif["func"])
- 作为参数传递给其他函数
def foo(name):#传入数据类型并计算长度 size = len(name) return size #将结果return def show(func): size = func("jjjjj")#相当于在show函数内部运行foo函数,size接受foo函数的return结果 print("length of string is %s"%size)
show(foo)
- 可以作函数的返回值
"""
函数接受一个或多个函数作为输入或者函数输出(返回)的值是函数时,我们称这样的函数为高阶函数
"""
def foo():
print("返回值")
def bar(func):
return func
f = bar(foo)
f()
bar(foo())
- 函数嵌套
1、嵌套调用
#嵌套函数的意义相当于把一个大需求拆成多个小需求然后组合一起,以如下为例
max2函数式做两个值得大小比如如果要做多个如10 100个就需要在max4中组合
def max2(x,y):
return x if x > y else y
def max4(a,b,c,d):
res1=max2(a,b)
res2=max2(res1,c)
res3=max2(res2,d)
return res3
print(max4(10,99,31,22))
2、函数嵌套定义
#函数的嵌套定义
def f1():#第一步进入f1函数
def f2():#第二部f1函数体中有f2函数声明
print('from f2')
def f3():#第四部f2函数体中有f3函数声明
print('from f3')
f3()#第五部f2函数体中运行f3函数
f2()#第三部f1函数体重运行f2内容
f1()
二、命名空间与作用域
1.命名空间定义
命名空间是名字和对象的映射,就像是字典,key是变量名,value是变量的值
#定义名字的方法
import time
name='egon' #定义变量
def func(): #定义函数
pass
class Foo:#定义类
pass
2.命名空间的分类
- 内置名称空间: 随着python解释器的启动而产生,包括异常类型、内建函数和特殊方法,可以代码中任意地方调用
print(sum)
print(max)
print(min)
print(max([1,2,3]))
import builtins
for i in dir(builtins): #打印所有的内置函数
print(i)
复制代码
结果:
C:\Python\Python36\python.exe D:/Python/课件/day4/cc.py
<built-in function sum>
<built-in function max>
<built-in function min>
3
ArithmeticError
AssertionError
AttributeError
BaseException
BlockingIOError
BrokenPipeError
BufferError
BytesWarning
ChildProcessError
ConnectionAbortedError
ConnectionError
ConnectionRefusedError
ConnectionResetError
DeprecationWarning
EOFError
Ellipsis
EnvironmentError
Exception
False
FileExistsError
FileNotFoundError
FloatingPointError
FutureWarning
GeneratorExit
IOError
ImportError
ImportWarning
IndentationError
IndexError
InterruptedError
IsADirectoryError
KeyError
KeyboardInterrupt
LookupError
MemoryError
ModuleNotFoundError
NameError
None
NotADirectoryError
NotImplemented
NotImplementedError
OSError
OverflowError
PendingDeprecationWarning
PermissionError
ProcessLookupError
RecursionError
ReferenceError
ResourceWarning
RuntimeError
RuntimeWarning
StopAsyncIteration
StopIteration
SyntaxError
SyntaxWarning
SystemError
SystemExit
TabError
TimeoutError
True
TypeError
UnboundLocalError
UnicodeDecodeError
UnicodeEncodeError
UnicodeError
UnicodeTranslateError
UnicodeWarning
UserWarning
ValueError
Warning
WindowsError
ZeroDivisionError
__build_class__
__debug__
__doc__
__import__
__loader__
__name__
__package__
__spec__
abs
all
any
ascii
bin
bool
bytearray
bytes
callable
chr
classmethod
compile
complex
copyright
credits
delattr
dict
dir
divmod
enumerate
eval
exec
exit
filter
float
format
frozenset
getattr
globals
hasattr
hash
help
hex
id
input
int
isinstance
issubclass
iter
len
license
list
locals
map
max
memoryview
min
next
object
oct
open
ord
pow
print
property
quit
range
repr
reversed
round
set
setattr
slice
sorted
staticmethod
str
sum
super
tuple
type
vars
zip
Process finished with exit code 0
- 全局名称空间:文件的执行会产生全局名称空间,指的是文件级别定义的名字都会放入该空间
x=1 #全局命名空间
def func():
money=2000 #非全局
x=2
print('func',x)#打印的是x=2的值如果没有将打印全局的
print(x)#打印的是全局
print(func)
func()
- 局部名称空间:调用函数时会产生局部名称空间,只在函数调用时临时绑定,调用结束解绑定
x=10000 #全局
def func():
x=1 #局部
def f1():
pass
3.作用域
- 1. 全局作用域:内置名称空间,全局名层空间
- 2. 局部作用:局部名称空间
名字的查找顺序:局部名称空间---》全局名层空间---》内置名称空间
x=1#全局
def func():
x=2#x作用域优先从局部中查找
print(x)
sum=123123
print(sum)
func()
查看全局作用域内的名字:gloabls()
查看局局作用域内的名字:locals()
全局作用域的名字:
全局作用域:全局有效,在任何位置都能被访问到,除非del删掉,否则会一直存活到文件执行完毕
局部作用域的名字:局部有效,只能在函数里(局部范围调用),只在函数调用时才有效,调用结束就失效
x=1000
def func(y):
x=2
print(locals())#查询func函数使用的局部{'x': 2, 'y': 1}
print(globals())#查看使用的全局
func(1)
三、闭包函数
1.定义在内部函数,包含对外部作用域非全局作用域的引用,该内部函数就成为闭包函数
def f1():
x = 1#x全局不可见
def f2():
print(x)#调用外部作用域x
return f2#将内部函数返回
f=f1()#得到f2
f()# f2()
2.闭包函数应用:惰性计算
from urllib.request import urlopen
#爬床老方法 def index(url): def get(): return urlopen(url).read() return get #oldboy= get()函数 存放在内存中还未执行 oldboy=index('http://crm.oldboyedu.com') #调用后才执行,什么时候用什么时候执行 print(oldboy().decode('utf-8'))
闭包函数相对与普通函数会多出一个__closure__的属性,里面定义了一个元组用于存放所有的cell对象,每个cell对象一一保存了这个闭包中所有的外部变量
# print(oldboy.__closure__[0].cell_contents)
res=urlopen('http://crm.oldboyedu.com').read()
print(res.decode('utf-8'))
四、装饰器
1.什么是装饰器
装饰别人的工具,修饰添加功能,工具指的是函数,装饰器本身可以使任何可调用对象,被装饰的对象也可以使任何可调用对象。
2.为什么要用装饰器
- 开放封闭原则:对修改时封闭的,对扩招是开放的
- 装饰器就是为了在不修改被装饰对象的源代码以及调用方式的前提下,为其添加新功能
装饰器的功能是将被装饰的函数当作参数传递给与装饰器对应的函数(名称相同的函数),并返回包装后的被装饰的函数”
直接看示意图,其中 a 为与装饰器 @a 对应的函数, b 为装饰器修饰的函数,装饰器@a的作用是:
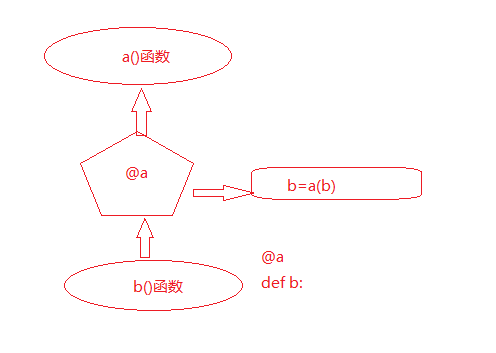
简而言之:@a 就是将 b 传递给 a(),并返回新的 b = a(b)
1.无返回值的修饰器
import time def timmer(func): def wrapper(*args,**kwargs): start_time=time.time()#运行函数前纪录开始时间 func(*args,**kwargs)#装饰器执行函数(*args,**kwargs)可接受任意长度任意类型 stop_time=time.time()#装饰器函体运行完成后纪录结束时间 print('run time is %s' %(stop_time-start_time))#结束时间减去开始时间就是装饰器修饰的函数运行时间 return wrapper#返回装饰器函数给timmer @timmer# index = timmer(index) def index():# time.sleep(3) print('welcome to index') if __name__ == '__main__': index()#相当于执行 index = timeer(index)
f=timmer(index)
print(f)
f() #wrapper()---->index()
index=timmer(index) #index==wrapper
index() #wrapper()----->
2.有返回值的
def timmer(func):
def wapper(*args,**kwargs):
start_time = time.time()
sum = func(*args,**kwargs)
end_time = time.time()
# print("用时%s"%(end_time-start_time))
return sum,(end_time-start_time)#将index函数的计算结果sum以及 用时返回
return wapper
@timmer
def index(x,y=4):
time.sleep(1)
return x+y
if __name__ == '__main__':
p = index(3)
print(p)
3.模拟用户登录验证是否有session
#全局变量纪录登陆状态
login_user ={"user":None,"status":False}
def auth(func):
def wrapper(*args,**kwargs):
if login_user["user"] and login_user["status"]:#判断用户状态user = none是false
res = func(*args,**kwargs)
return res
else:#否则输入用户名密码验证
name = input('user:')
password = input("password:")
if name == "hanjialong" and password == "123456":#如果验证通过后在执行
login_user["user"] = "hanjialong"
login_user["status"] = True
print("'\033[45mlogin successful\033[0m'")
res = func(*args,**kwargs)
return res
return wrapper
@auth
def index():
print("欢迎登陆")
@auth
def home(name):
print("%s welconme to home page"%name)
if __name__ == '__main__':
index()
home("韩佳龙")
4.装饰器叠加执行顺序
def timmer(func):
def wapper(*args,**kwargs):
start_time = time.time()
res = func(*args,**kwargs)
end_time = time.time()
print("用时%s"%(end_time-start_time))
return res
return wapper
#全局变量纪录登陆状态
login_user ={"user":None,"status":False}
def auth(func):
def wrapper(*args,**kwargs):
if login_user["user"] and login_user["status"]:#判断用户状态user = none是false
res = func(*args,**kwargs)
return res
else:#否则输入用户名密码验证
name = input('user:')
password = input("password:")
if name == "hanjialong" and password == "123456":#如果验证通过后在执行
login_user["user"] = "hanjialong"
login_user["status"] = True
print("'\033[45mlogin successful\033[0m'")
res = func(*args,**kwargs)
return res
return wrapper
@auth
@timmer
def index():
print("欢迎登陆")
@auth
@timmer
def home(name):
print("%s welconme to home page"%name)
if __name__ == '__main__':
index()
home("韩佳龙")
5.有参装饰器
user_login = {"user":None,"status":False}
def aut(dirver="file"):3#带参数的装饰器比不带参数的多一层 装饰器最多就三层函数
def aut1(fuch):
def wrapper(*args,**kwargs):
if dirver = "file":
if user_login["user"] and user_login["status"]:
res = fuch(*args,**kwargs)
return res
else:
name = input("user:")
pwd= input("passworld:")
if name = "hanjialong" and pwd = "123456":
res = fuch(*args,**kwargs)
return res
else:
print('\033[45mlogin err\033[0m')
elif dirver = 'mysql':
if user_login["user"] and user_login["status"]:
res = fuch(*args,**kwargs)
return res
else:
name = input("user:")
pwd= input("passworld:")
if name = "hanjialong" and pwd = "123456":
res = fuch(*args,**kwargs)
return res
elif dirver = 'ldap':
if user_login["user"] and user_login["status"]:
res = fuch(*args,**kwargs)
return res
else:
name = input("user:")
pwd= input("passworld:")
if name = "hanjialong" and pwd = "123456":
res = fuch(*args,**kwargs)
return res
else:
print("未知认证")
return wrapper
@auth('file') #@auth2====>index=auth2(index)===>index=auth_wrapper
@timmer #index=timmer(auth_wrapper) #index=timmer_wrapper
def index():
time.sleep(3)
print('welcome to index page')
@auth(driver='mysql')
def home(name):
print('%s welcome to home page' %name)
index() #timmer_wrapper()
# home('egon') #wrapper('egon'
五、迭代器
1.什么是迭代器
重复执行并且迭代结果作为下一次迭代的初始值,这个重复的过程称为迭代每次重复,并且每次迭代的结果是下一次迭代的初始值
#案例1
while True: #只满足重复,因而不是迭代
print('====>')
#案例2
#以下才是迭代
l = [1, 2, 3]
count = 0
while count < len(l): # 只满足重复,因而不是迭代
print('====>', l[count])
count += 1
l = (1, 2, 3)
count = 0
while count < len(l): # 只满足重复,因而不是迭代
print('====>', l[count])
count += 1
s='hello'
count = 0
while count < len(s):
print('====>', s[count])
count += 1
2.为什么要使用迭代器
对于没有索引的数据类型,必须提供一种不依赖索引的迭代方式
可迭代的对象:内置__iter__方法的,都是可迭代的对象
迭代器:执行__iter__方法,得到的结果就是迭代器,迭代器对象有__next__方法
#有_iter_()方法的都是课迭代对象 # [1,2].__iter__() # 'hello'.__iter__() # (1,2).__iter__() # # {'a':1,'b':2}.__iter__() # {1,2,3}.__iter__()
# i=[1,2,3].__iter__()
#
# print(i)
#
# print(i.__next__())
# print(i.__next__())
# print(i.__next__())
# print(i.__next__()) #抛出异常:StopIteration
#使用迭代遍历字典
dic={'a':1,'b':2,'c':3}
i=dic.__iter__()
while True:
try:
key=i.__next__()
print(dic[key])
except StopIteration:
break
3.如何判断一个对象是可迭代的对象,还是迭代器对象
#有iter是可迭代对象
# 'abc'.__iter__() 字符串
# ().__iter__() 元祖tuple
# [].__iter__() 列表list
# {'a':1}.__iter__() 字典dict
# {1,2}.__iter__() 集合set
# f=open('a.txt','w') 文件file
# f.__iter__()
- 可迭代对象:只有__iter__方法,执行该方法得到的迭代器对象
from collections import Iterable,Iterator print(isinstance('abc',Iterable)) print(isinstance([],Iterable)) print(isinstance((),Iterable)) print(isinstance({'a':1},Iterable)) print(isinstance({1,2},Iterable)) f = open('a.txt','w') print(isinstance(f,Iterable)) 结果: True True True True True True
- 迭代器对象:对象有__next__,对象有__iter__,对于迭代器对象来说,执行__iter__方法,得到的结果仍然是它本身
1.迭代对象
# 只有文件是迭代器对象
from collections import Iterable,Iterator
print(isinstance('abc',Iterator))
print(isinstance([],Iterator))
print(isinstance((),Iterator))
print(isinstance({'a':1},Iterator))
print(isinstance({1,2},Iterator))
f = open('a.txt','w')
print(isinstance(f,Iterator))
结果:
False
False
False
False
False
True
2.迭代器
# 对象有__iter__,对于迭代器对象来说,执行__iter__方法,得到的结果仍然是它本身
f = open("a.txt","r")
t=f.__iter__()
print(t)
print(f)
print(f is t)#f 结果和t结果比较是True
# 可迭代对象list,可以看出就是一个迭代器
l = []
i = l.__iter__()
print(i)
print(i.__iter__())
print(l)
dic={'name':'egon','age':18,'height':'180'}
# print(dic.items())
# for k,v in dic.items():
# print(k,v)
#通过迭代器方式
dic={'name':'egon','age':18,'height':'180'}
i = dic.__iter__()
while True:
try:
c = next(i)#d得到字典的所以key
# print(c)
print(dic[c])
except StopIteration:
break
#for循环本身就是迭代器的实现
dic={'name':'egon','age':18,'height':'180'}
for i in dic:
print(dic[i])
l=['a','b',3,9,10]
for i in l:
print(i)
with open('a.txt','r',encoding='utf-8') as f:
for line in f:
print(line)
3.迭代器的优缺点
- 优点:
1.提供了一种不依赖下标的迭代方式
l=[10000,2,3,4,5] i=iter(l) print(next(i))
2.就迭迭代器本身来说,更节省内存
- 缺点:
1. 无法获取迭代器对象的长度
2. 不如序列类型取值灵活,是一次性的,只能往后取值,不能往前退
六、生产器函数
只要函数体包含yield关键字,该函数就是生成器函数,生成器就是迭代器
1.生成器写法
普通函数结果只能有一个
def foo():
return 1
return 2
return 3
return 4
res1=foo()
print(res1)
res2=foo()
print(res2)
结果:
1
1
#生成器就是迭代器
def foo():
print('first')
yield 1
print('second')
yield 2
print('third')
yield 3
print('fourth')
yield 4
print('fifth')
# print(next(g)) #触发迭代器g的执行,进而触发函数的执行
g=foo() for i in g: print(i) 结果: first 1 second 2 third 3 fourth 4 fifth
2.生成器应用
def counter(n):
print('start...')
i=0
while i < n:
yield i
i+=1
print('end...')
counter(5)
g=counter(5)
# print(next(g))
# print(next(g))
# print(next(g))
# print(next(g))
for i in g:
print(i)
总结
a. 相当于为函数封装好__iter__和__next__
b. return只能返回一次值,函数就终止了,而yield能返回多次值,每次返回都会将函数暂停,下一次next会从上一次暂停的位置继续执行
#模拟#tail -f a.txt | grep 'python'
import time
def tail(filepath):
"""
tail功能
:param filepath: 文件路径
:return: 相当于return文件最后一行,后等待文件输入
"""
with open(filepath,encoding='utf-8') as f:
"""
seek(offset,whence=0)
offset:开始的偏移量,也就是代表需要移动偏移的字节数
whence:给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,
1代表从当前位置开始算起,2代表从文件末尾算起。默认为0
"""
f.seek(0,2)
while True:
line=f.readline().strip()
if line:
yield line
else:
time.sleep(0.2)
# t=tail('a.txt')
#
# for line in t:
# print(line)
def grep(pattern,lines):
for line in lines:
if pattern in line:#如果内容中有patern字符
yield line#返回line字符并等待下次输入
# for i in g:
# print(i)
if __name__ == '__main__':
t = tail('a.txt')#返回内存地址
g = grep('python',t)
for i in g:
print(i)
七、内置函数
- abs 返回一个数字的绝对值
print(abs(-1000))
结果: 1000
- all 如果iterable的所有元素不为0、''、False或者iterable为空,all(iterable)返回True,否则返回False
注意:空元组、空列表返回值为True,这里要特别注意
print(all(['a', 'b', 'c', 'd'])) #列表list,元素都不为空或0
print(all(['a', 'b', '', 'd'])) #列表list,存在一个为空的元素
print(all([0,1,2,3])) #列表list,存在一个为0的元素
print(all(('a', 'b', 'c', 'd'))) #元组tuple,元素都不为空或0
print(all(('a', 'b', '', 'd'))) #元组tuple,存在一个为空的元素
print(all((0,1,2,3))) #元组tuple,存在一个为0的元素
print(all([])) # 空列表
print(all(())) # 空元组
结果:
True
False
False
True
False
False
True
True
- any()
如果所有元素中有一个值非0、''或非False,那么结果就为True,当iterable所有的值都是0、''或False时,那么结果为False
print(any(['a', 'b', 'c', 'd'])) #列表list,元素都不为空或0
print(any(['a', 'b', '', 'd'])) #列表list,存在一个为空的元素
print(any([0,1,2,3])) #列表list,存在一个为0的元素
print(any(('a', 'b', 'c', 'd'))) #元组tuple,元素都不为空或0
print(any(('a', 'b', '', 'd'))) #元组tuple,存在一个为空的元素
print(any((0,1,2,3))) #元组tuple,存在一个为0的元素
print(any([])) # 空列表
print(any(())) # 空元组
结果
True
True
True
True
True
True
False
False
- ascii()
调用对象的__repr__()方法,获得该方法的返回值
print(ascii([1,2,3,1,22,123])) #[1, 2, 3, 1, 22, 123]
- bin()
将十进制数分别转换为2进制
print(bin(10)) #0b1010
- bool()
测试一个对象是True还是False
print(bool([])) #False
- bytes()
将一个字符串转换成字节类型
s="apple" v=bytes(s,encoding="utf-8") print(v) #b'apple'
- callable(object)
callable()函数用于测试对象是否可调用,如果可以则返回1(真);否则返回0(假)。可调用对象包括函数、方法、代码对象、类和已经定义了 调用 方法的类实例。
a = '123' print(callable(a)) #False
- chr(i)
chr()函数返回ASCII码对应的字符串。
print(chr(65)) #A
- complex(real[,imaginary])
complex()函数可把字符串或数字转换为复数。
print(complex(2,1)) #(2+1j)
- delattr()
删除对象的属性
- dict()
创建数据字典
print(dict()) #{}
- dir()
不带参数时返回当前范围内的变量,方法和定义的类型列表,带参数时返回参数的属性,方法列表
print(dir())
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'time']
- divmod(x,y)
divmod(x,y)函数完成除法运算,返回商和余数。
print(divmod(10,3)) #(3, 1)
- enumerate()
返回一个可以枚举的对象,该对象的next()方法将返回一个元组
s = ["a","b","c"]
for i ,v in enumerate(s,1):
print(i,v)
1 a 2 b 3 c
- eval()
将字符串str当成有效的表达式来求值并返回计算结果
s = "1 + 3 +5" print(eval(s)) #9
- exec()
执行字符串或complie方法编译过的字符串,没有返回值
- float(x)
float()函数把一个数字或字符串转换成浮点数。
print(float("12")) #12.0
- format()
格式化输出字符串
print("i am {0},age{1}".format("tom",18))
i am tom,age18
- frozenset()
创建一个不可修改的集合
set和frozenset最本质的区别是前者是可变的,后者是不可变的。当集合对象会被改变时(例如删除,添加元素),只能使用set,
一般来说使用fronzet的地方都可以使用set。
参数iterable:可迭代对象。
- globals()
返回一个描述当前全局变量的字典
a = "apple" print(globals())
{'__package__': None, '__file__': '/Users/hexin/PycharmProjects/py3/day4/2.py', '__name__': '__main__', 'a': 'apple', 'time': <module 'time' (built-in)>, '__cached__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x10bd73c88>, '__builtins__': <module 'builtins' (built-in)>, '__spec__': None, '__doc__': None}
- hash()
哈希值hash(object)注意:可哈希的即不可变数据类型,不可哈希即可变数据类型
如果对象object为哈希表类型,返回对象object的哈希值。哈希值为整数,在字典查找中,哈希值用于快递比价字典的键。
两个数值如果相等,则哈希值也相等。
- help()
返回对象的帮助文档
调用内建的帮助系统,如果不包含参数,交互式帮助系统将在控制台启动。如果参数为字串,则可以是模块,类,方法等名称,并且帮助页面将会在控制台打印。参数也可以为任意对象
- hex(x)
hex()函数可把整数转换成十六进制数。
print(hex(12)) #0xc
- id()
返回对象的内存地址
a = "apple" print(id(a)) #4562197840
- input()
获取用户输入内容
- int(x[,base])
int()函数把数字和字符串转换成一个整数,base为可选的基数。
- iter()
返回一个iterator对象。
- len()函数返回字符串和序列的长度。
print(len('aa')) #2
- list(x)
list()函数可将序列对象转换成列表。
print(list("hello world"))
['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']
- locals()
打印当前可用的局部变量的字典
- max(x[,y,z...])
max()函数返回给定参数的最大值,参数可以为序列。
print(max(1,2,3,4)) #4
- min(x[,y,z...])
min()函数返回给定参数的最小值,参数可以为序列。
print(min(1,2,3,4)) #1
- next()
返回一个可迭代数据结构(如列表)中的下一项
- object()
获取一个新的,无特性(geatureless)对象。Object是所有类的基类。它提供的方法将在所有的类型实例中共享。
- oct(x)
oct()函数可把给出的整数转换成八进制数。
print(oct(12)) #0o14
- ord(x)
ord()函数返回一个字符串参数的ASCII码或Unicode值。
print(ord("a")) #97
- open()
打开文件open(filename [, mode [, bufsize]])
打开一个文件,返回一个file对象。 如果文件无法打开,将处罚IOError异常
- pow(x,y[,z])
pow()函数返回以x为底,y为指数的幂。如果给出z值,该函数就计算x的y次幂值被z取模的值。
print(pow(2,5)) #32 print(pow(2,5,3)) #2
- range([lower,]stop[,step])
range()函数可按参数生成连续的有序整数列表。
print(range(1,10,2)) #range(1, 10, 2)
- repr()
将任意值转换为字符串,供计时器读取的形式
- reversed()
反转,逆序对象
- round(x[,n])
round()函数返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。
print(round(5.9)) #6
- set()
将对象转换成集合
- slice()
切片功能
s = ["a","b""c","d"] print(slice(1,3,s))
slice(1, 3, ['a', 'bc', 'd'])
- sorted()
排序
列表排序,按数轴方向排,高阶函数,以绝对值大小排序,字符串排序,按照ASCII的大小排序,如果需要排序的是一个元组,则需要使用参数key,也就是关键字。反向排序,reserve=True
- str(obj)
str()函数把对象转换成可打印字符串。
print(str(4)) #4
- sum()
求和
- tuple(x)
tuple()函数把序列对象转换成tuple。
print(tuple("hello world"))
('h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd')
- type(obj)
type()函数可返回对象的数据类型。
print(type('123'))
print(type(1))
<class 'str'> <class 'int'>
- vars()
本函数是实现返回对象object的属性和属性值的字典对象。如果默认不输入参数,就打印当前调用位置的属性和属性值,相当于locals()的功能。如果有参数输入,就只打印这个参数相应的属性和属性值。

print(vars())
#{'__name__': '__main__', '__spec__': None, '__package__': None, '__builtins__': <module 'builtins' (built-in)>, 'time': <module 'time' (built-in)>, '__cached__': None, '__doc__': None, '__file__': '/Users/hexin/PycharmProjects/py3/day4/2.py', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x10e5f3c88>}
print(vars(time))
- zip()
将对象逐一配对
s='helloo'
l=[1,2,3,4,5]
z=zip(s,l)
print(z)
for i in z:
print(i)
结果
<zip object at 0x1051d1608>
('h', 1)
('e', 2)
('l', 3)
('l', 4)
('o', 5)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号