
K8S-K8S基础概念

为了能够统一管理集群上大量的资源,我们需要给Pod添加一些元数据信息
Pod 标签:Lable Key=value
而且在Key和value还有一定的限制,定义完后就可以使用所谓的标签选择器了,定义过滤条件来挑选符合我们的pod资源
我们知道在K8s上我们运行的容器以后,同一类容器,或者运行pod之后,同一类pod可能不止一个,既然如此,(1)当用户请求到达是我们如何去接入用户请求,到底给同一类的pod中哪一个pod来相应
(2)pod是需要所谓的控制器来管理pod的,尽量不要人手工去管理它
pod我们可以自己分类:
(1)自主式pod:自我管理的,创建以后,任然是提交给API Server,由API Server接收后借助Scheduler将其调度到指定的node节点,然后由node启动此节点,如果有pod中容器出现问题了,需要重启容器,那是由Keepalived来完成,但是如果节点故障了,pod也就消失了,所以,它有这样的坏处,没办法实现全局的调度,所以建议使用第二种pod
(2)控制器管理的pod,正是控制器这种机制的使用,使得在K8S上的集群设计中,pod完全就可以叫做有生命周期的对象,而后由调度器调度到集群中的某节点,运行以后,它的任务终止也就随着被删除掉,但是有一些任务,大家知道传统上有nginx、tomcat,它们是做为守护进程运行的,那么这种运行为pod容器的话,我们要确保它是时刻运行的,一旦出现故障我们要第一时间发现,要么是重建取代它,要么是重启,那么pod控制器就可以观测并实现
pod控制器早期的时候是:
RreplicationContrller,副本控制器
当我们启动一个pod时候,比如一个nginx pod,这个pod不够了,我可以再起一个副本,而后呢,控制器专门控制着同一pod资源,使得pod多退少补

万一另一个pod调度到另一个node上运行,但是调度到的node也宕机了,那么就少了一个副本,但是控制器会重新请求一个API Server重新创建一个新pod,API Server借助Scheeduler调度以后,找另外一个node然后把pod再起起来,到此为止又是符合人们期望的
滚动更新:
比如此前启动容器是靠所谓的1.0版的镜像启动的,后来做了有1.1的镜像,那么现在需要pod中的容器替换成1.1的镜像那么怎么办?可以做滚动更新,比如先创建新版本的pod然后再慢慢去除老的pod
此外还可以回滚操作:
新版本的控制器为ReplicaSet

像Deployment这种控制器还二级控制器叫HPA (HorizonlPodAutoscaler)
我们叫做水平pod自动伸缩器
解释:

容器承载不了这么多流量访问怎么办?所以我们需要加更多的pod资源了,到底应该加几个呢?所以HP控制器可自动监控着,自动进行扩展,比如他会自动分析现在的cpu、内存利用率有多高,确保平均低于百60%,那么一计算,需要额外加两个,那么就HPA自动给加上两个,一旦小了也可以减少,可以确保有几个存在
服务发现:
此前我们配置个LAMP服务在Nginx端:我们通过配置文件写好对应后面那个M或者P的地址是什么,万一我们pod中的M、P发生变化了,地址是不是发生变化了,那么我们使用主机名可不可以,但是有没有想过新起一个pod主机名也变了,因为它已经是全新的pod了,大家想下应该怎么做?使用服务发现
客户端每次去访问后端的服务时,我们客户端不是直接访问的,因为它不知道后端是谁的,它需要先去找一个位置看看有没有这么一个服务
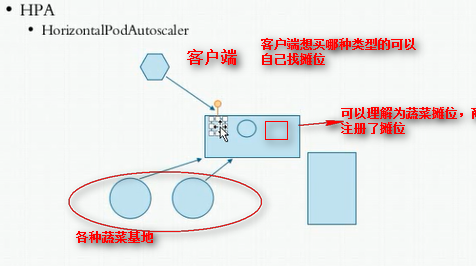
如果客户访问不到后端服务,定义为超时,那么这个摊位会自动移出该pod注册的信息,新建的pod会在摊位会注册服务信息
pod是有生命周期的,一个pod随时可能离去,随时也可能创建新的pod,假如它们提供的是同一种服务,我们客户端是没有办法采用固定的手段来访问这个pod的,因为pod是随时变化的,无论你是使用主机名还是ip地址都随时会替换掉,那怎么办?这就需要用到服务发现机制了,那么K8S为同一类pod或同一组pod与客户端之间添加了中间层这个中间层是固定的,这个中间层就叫做service,service只要不删除,它的地址是固定的,名称服务名也是固定的,这个服务不但能够提供一个稳定的访问入口还能起到调度的做作用,就算pod宕机了创建新的pod service会自动把pod关联进来,大家知道pod有一个固定的元数据,叫标签,它就是通过标签来关联的,关联后能够自动探测pod的IP地址和服务端口
而在K8S当中,service可不是什么应用程序,也不是什么组件,它只不过是iptables的DNAT规则
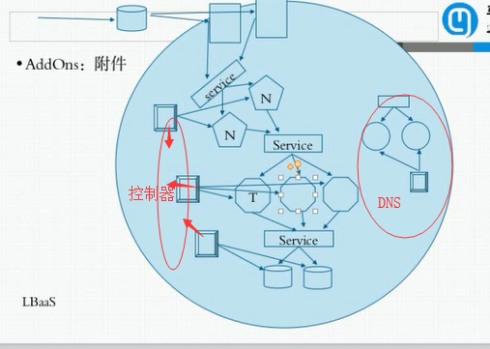
AddOns:附件:dns只是它们当中的一个
改附件能够动态删除动态变动:比如你把service名称改了,它会自动触发dns中的解析记录,把解析记录名称也改了,客户端访问的时候,dns解析的是service的地址而不是pod的地址
service是端口代理,大家知道是DNAT实现,但是后面很多pod资源,所以DNAT认为是多目标调度了,对Linux来讲iptables已经把负载均衡的功能主要交给IPVS来实现,所以调度效果上是不太近人意
所以在K8S的1.11版中,已经把iptables规则改为了IPVS规则,也就是说你每创建一个service的时候就相当于创建了一个IPVS规则
用Nginx+tomcat+mysql的例子类比所有的k8s集群架构:
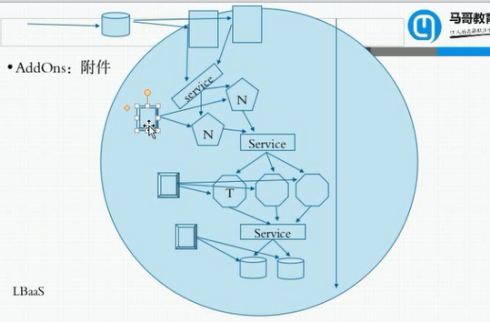
K8S中,dns自身也是个pod
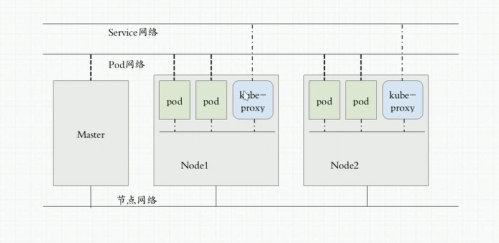
K8S有三种网络:
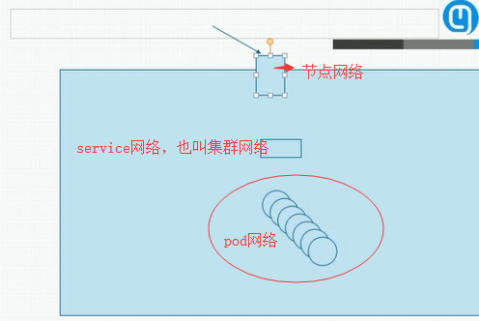
它们的网络关系是一层一层相互代理的
K8S的三类通信方式:
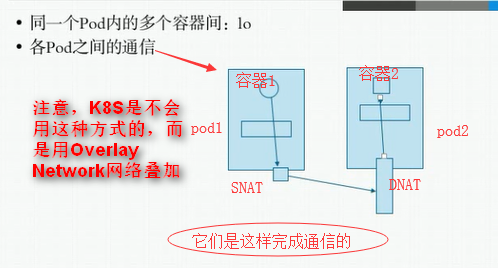
如果pod发生改变了,那么service怎么才能发现呢?当然是靠Lable标签,service怎么又能改变所有节点上ipvs或iptables规则呢?这需要专门的组建来实现,在每一个node节点上有一个组件,这个组件一般是运行在node之上的守护进程叫kube-proxy,它负责随时与API Server进行通信,因为每一个pod发生变化后,这个结果需要保存在API Server中的,而API Server内容发生改变后会生成一个通知事件,这个事件可以被任何关联的组件知道,比如kube-proxy组件,一旦发现service背后的pod发生改变地址发生改变,则对应的由kube-proxy在本地反应到iptables或ipvs规则中,所以service是靠kube-proxy实现的
所以大家发现API Server需要存储集群中各对象的各种状态信息,所以是存储不下的,怎么办呢?存哪里呢不能存内存也不能存磁盘,所以要存储在各Master共享存储中,这个存储叫做k8s的etcd,
etcd: 是一个键值对存储,
所有集群的节点状态信息都存储在etcd中,如果,它出现了故障,那么集群也完了,所以需要对它做高可用,至少有三个节点
etcd一般有两个端口,一个用于集群外部通信(向客户端提供服务),一个用于集群内部通信
内部通信需要专门的证书,叫点对点通信的证书来配置https,
而向客户端(API Server)提供服务的时候通过https协议,要想加密又要另外一套证书来实现
而客户端向API Server通信又需要另外一套ca颁发的证书
CNI:
插件体系来接入外部的网络服务解决方案,CNI叫做容器网络接口
k8s如果成千上万个pod都能够直接通信的话那么不安全,特别是多租户的环境中,所以pod的网络还是依赖service
事实上pod之间是可以直接通信的,那么怎么才能安全?用隔离,网络策略所以引入K8S的另一个组件:名称空间,注意不是docker上的名称空间
名称空间:
K8S网络:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号