MongoDB部署
MongoDB部署
一、MongoDB安装配置
1. 下载安装包
# https://www.mongodb.com/try/download/community
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-7.0.14.tgz
2. 解压
tar fx mongodb-linux-x86_64-rhel70-7.0.14.tgz -C /usr/local/
3. 创建软链接
ln -s /usr/local/mongodb-linux-x86_64-rhel70-7.0.14/ /usr/local/mongodb
4. 创建数据和日志目录
mkdir /usr/local/mongodb/{data,logs}
touch /usr/local/mongodb/logs/mongodb.log
5. 设置环境变量
vim /etc/profile
export MONGODB_HOME=/usr/local/mongodb
export PATH=$MONGODB_HOME/bin:$PATH
6. 生效环境变量
source /etc/profile
7. 修改配置文件
vim /etc/mongodb.conf
#指定数据库路径
dbpath=/usr/local/mongodb/data
#指定MongoDB日志文件
logpath=/usr/local/mongodb/logs/mongodb.log
# 使用追加的方式写日志
logappend=true
#端口号
port=27017
#方便外网访问
bind_ip=0.0.0.0
fork=true # 以守护进程的方式运行MongoDB,创建服务器进程
#auth=true #启用用户验证
#bind_ip=0.0.0.0 #绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定则默认本地所有IP
#replSet=single #开启oplog日志用于主从复制
8. 启动和关闭服务
# 启动
mongod -f /etc/mongodb.conf
# 关闭
mongod --shutdown -f /etc/mongodb.conf
9. 验证
ps -ef|grep mongodb
netstat -ntlp|grep 27017
二、MongoDB Shell安装
1. 下载安装包
# 下载链接:https://www.mongodb.com/try/download/shell
wget https://downloads.mongodb.com/compass/mongosh-2.3.2-linux-x64.tgz
2. 解压
tar fx mongosh-2.3.2-linux-x64.tgz
3 . 修改命令目录
cp mongosh-2.3.2-linux-x64/bin/mongosh /usr/local/bin/
4. 登录
# 不需要认证
mongosh
# 需要认证
mongosh mongodb://192.168.9.25:27017/admin -u "admin" -p "abc123456"
三、常用命令合集
1. 角色操作
1)管理员角色
# 只能创建在admin逻辑库
readAnyDatabase: 只可以把用户创建在admin逻辑库中,允许读取任何逻辑库
readWriteAnyDatabase: 只可以把用户创建在admin逻辑库中,允许读写任何逻辑库
dbAdminAnyDatabase: 只可以把用户创建在admin逻辑库中,允许管理任何逻辑库
userAdminAnyDatabase: 只可以把用户创建在admin逻辑库中,允许管理任何逻辑库用户
clusterAdmin: 只可以把用户创建在admin逻辑库中,允许管理MongoDB集群
root: 只可以把用户创建在admin逻辑库中,超级管理员,拥有最高权限
2)普通角色
# 在指定逻辑库上创建
Read: 允许用户读取指定逻辑库
readWrite: 允许用户读写指定逻辑库
dbAdmin: 可以管理指定的逻辑库
userAdmin: 可以管理指定逻辑库的用户
3)创建角色
# 创建管理员
use admin
db.createUser({user:"admin",pwd:"abc123456",roles:[{role:"root",db:"admin"}]})
# 创建普通角色
use common
db.createUser({user:"qyc",pwd:"abc123456",roles:[{role:"dbAdmin",db:"common"},{role:"readWrite",db:"common"}]})
4)查询角色
# 查询所有
db.system.users.find().pretty()
show users
# 查询指定角色
db.getUser('qyc')
db.runCommand({usersInfo:"qyc"})
5) 更新角色
db.updateUser('qyc',{'roles':[{'role':'userAdmin','db':'common'},{'role':'read','db':'common'}]})
6) 修改角色密码
db.changeUserPassword("qyc", "123456")
7) 删除角色
db.dropUser('qyc')
8) 角色认证
db.auth('qyc','123456')
2. 数据库操作
1)查看所有库
show dbs
2) 切换库
# 切换到指定库,不存在会自动创建
use common
3)查看当前库
db
4)删除当前库
db.dropDatabase()
3. 集合操作
1)创建集合
db.createCollection("student")
2)查看集合
show collections
3)重命名集合
db.student.renameCollection("stu")
4) 查看集合记录数量
db.student.count()
5) 查看集合数据空间容量
# db.student.dataSize()
# 查看集合总大小(字节为单位)
db.student.totalSize()
# 查看集合的统计信息
db.student.stats()
6) 删除集合
db.student.drop()
4. 文档操作
1)在集合中插入文档
# 插入单条
db.student.insertOne({name:"Scott",sex:"male",age:25,city:"Beijing"})
# 插入多条,save在_id主键存在就更新,不存在就插入
db.student.insert([{name:"Scott3",sex:"male",age:22,city:"Beijing"},{name:"Scott2",sex:"male",age:22,city:"Beijing"}])
db.student.insertMany([{name:"Scott3",sex:"male",age:22,city:"Beijing"},{name:"Scott2",sex:"male",age:22,city:"Beijing"}])
db.student.save([{name:"Scott3",sex:"male",age:22,city:"Beijing"},{name:"Scott2",sex:"male",age:22,city:"Beijing"}])
2)更新文档
# 修改一条记录
db.student.update({name:"Scott2"},{$set:{age:26,classno:"2-6"}})
# 修改多条记录
db.student.updateMany({name:"Scott3"},{$set:{classno:"2-7"}})
# 在age属性上都加2
db.student.updateMany({},{$inc:{age:2}})
# 向数组属性添加元素
db.student.update({name:"Scott"},{$push:{role:"班长"}})
3)从文档主键ID中提取时间
ObjectId("66dac03ddf68fdd4c95796d4").getTimestamp()
4) 删除文档
# 删除文档中的字段,{}代表修改所有
db.student.update({name:"Scott"},{$unset:{classno:"2-6"}})
# 删除数组中的某个元素
db.student.update({name:"Scott"},{$pull:{role:"班长"}})
# 删除所有文档
db.student.remove({})
# 删除指定文档
db.student.remove({name:"Scott2"})
5) 简单查询
表达式 说明
$lt 小于
$gt 大于
$lte 小于等于
$gte 大于等于
$in 包括
$nin 不包括
$ne 不等于
$all 全部匹配
$not 取反
$or 或
$exists 含有字段
# 查询所有文档
db.student.find()
# 查询指定文档,并显示指定字段,1为显示,0不显示
db.student.find({name:"Scott3",classno:"2-8"},{name:1,_id:0})
db.student.find({age:{$gte:24}})
db.student.find({name:/^S/})
# 查看单条记录
db.student.findOne({name:/3$/})
# 文档嵌套查询
# {class:{type: 1, data: [1,2,3]}}
db.student.find({data.class.type:1})
db.student.find({data.class.data.1:2})
db.student.find({data.class.data:[1,2,3]})
6)分页查询
# 取前十条
db.student.find().limit(10)
# 从21条开始取十条
db.student.find().skip(20).limit(10)
7) 文档排序
# 数据排序(1代表升序,-1代表降序)
db.student.find().sort({name:1})
8) 文档去重
# 返回去重后指定数据,格式为数组
db.student.distinct("name")
# 为去重后数据排序,(-1为正序,1为倒序)
db.student.distinct("name").sort(function(){return -1})
# 截取数组中指定数据,(0,5)表示截取从第一行到第六行,(5)表示截取第六行到最后一行
db.stuent.distinct("name").slice(0,5)
5. 索引操作
1) 创建索引
# 1升序,-1降序,background代表在空闲时创建
db.student.createIndex({name:1})
db.student.createIndex({name:-1},{background:true,name:"index_name"})
2) 创建唯一性索引
db.student.createIndex({sid:1},{background:true,unique:true})
3) 查看索引
db.student.getIndexes()
4) 删除索引
db.student.dropIndexes()
四、备份与恢复
1. 全库备份
mongodump --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin -o /data
2. 备份逻辑库
# --dumpDbUsersAndRoles参数可以备份隶属于逻辑库的用户
mongodump --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin -d school -o /data
3. 备份集合数据
# --gzip压缩备份,--oplog使用oplog进行时间点快照
mongodump --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin -d school -c student -o /data
# 数据导出JSON或CSV格式数据,-f指定输出字段,-q指定查询语句
mongoexport --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin -d school -c student -f "_id,name,sex,age" -o student.json
4. 单库恢复
# --drop表示导入前删除数据库中集合
mongorestore --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin --drop -d school /data/school
5. 集合恢复
# --gzip解压Gzip压缩存档还原,--oplogReplay重放oplog.bson中的操作内容,--oplogLimit与--oplogReplay一起使用时,可以限制重放到指定的时间点
mongorestore --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin -d school -c student /data/school/student.bson
# 导入json数据
mongoimport --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin -d school -c student --file student.json
6. 增量恢复
# 使用oplog参数全备,需要开启副本集
mongodump --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin --oplog -o /data
# 解析oplog文件,找出全备最后一个时间的数据
bsondump /data/oplog.bson > /data/oplog.json
# 导出增量数据,这里修改为oplog.json最近一行的时间戳
mongodump --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin -d local -c oplog.rs -q '{ts:{$gt:Timestamp(1610789118,416)}}' -o /data/oplog
# 恢复全备
mongorestore --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin --oplogReplay /data
# 复制增量的oplog到备份目录,重命名为oplog.bson,将原来的oplog.bson覆盖
cp oplog.rs.bson /data/oplog.bson
# 将增量的oplog进行恢复,指定要恢复的时间点
mongorestore --host=localhost --port=27017 -u admin -p abc123456 --authenticationDatabase=admin --oplogReplay --oplogLimit "1610789168:1" /data
-------------------------------------------------------------------------------------
MongoDB中4种日志的详细介绍
作者:think123
这篇文章主要给大家介绍了关于MongoDB中4种日志的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用MongoDB具有一定的参考学习价值,需要的朋友们下面来一起学习学习吧
前言
任何一种数据库都有各种各样的日志,MongoDB也不例外。MongoDB中有4种日志,分别是系统日志、Journal日志、oplog主从日志、慢查询日志等。这些日志记录着MongoDB数据库不同方面的踪迹。下面分别介绍这几种日志。
系统日志
系统日志在MongoDB数据库中很重要,它记录着MongoDB启动和停止的操作,以及服务器在运行过程中发生的任何异常信息。
配置系统日志的方法比较简单,在启动mongod时指定logpath参数即可
mongod -logpath=/data/log/mongodb/serverlog.log -logappend
系统日志会向logpath指定的文件持续追加。
Journal日志
journaling(日记) 日志功能则是 MongoDB 里面非常重要的一个功能 , 它保证了数据库服务器在意外断电 、 自然灾害等情况下数据的完整性。它通过预写式的redo日志为MongoDB增加了额外的可靠性保障。开启该功能时,MongoDB会在进行写入时建立一条Journal日志,其中包含了此次写入操作具体更改的磁盘地址和字节。因此一旦服务器突然停机,可在启动时对日记进行重放,从而重新执行那些停机前没能够刷新到磁盘的写入操作。
MongoDB配置WiredTiger引擎使用内存缓冲区来保存journal记录,WiredTiger根据以下间隔或条件将缓冲的日志记录同步到磁盘
- 从MongoDB 3.2版本开始每隔50ms将缓冲的journal数据同步到磁盘
- 如果写入操作设置了j:true,则WiredTiger强制同步日志文件
- 由于MongoDB使用的journal文件大小限制为100MB,因此WiredTiger大约每100MB数据创建一个新的日志文件。当WiredTiger创建新的journal文件时,WiredTiger会同步以前journal文件
MongoDB达到上面的提交,便会将更新操作写入日志。这意味着MongoDB会批量地提交更改,即每次写入不会立即刷新到磁盘。不过在默认设置下,系统发生崩溃时,不可能丢失超过50ms的写入数据。
数据文件默认每60秒刷新到磁盘一次,因此Journal文件只需记录约60s的写入数据。日志系统为此预先分配了若干个空文件,这些文件存放在/data/db/journal目录中,目录名为_j.0、_j.1等
长时间运行MongoDB后,日志目录中会出现类似_j.6217、_j.6218的文件,这些是当前的日志文件,文件中的数值会随着MongoDB运行时间的增长而增大。数据库正常关闭后,日记文件会被清除(因为正常关闭后就不在需要这些文件了).
向mongodb中写入数据是先写入内存,然后每隔60s在刷盘,同样写入journal,也是先写入对应的buffer,然后每隔50ms在刷盘到磁盘的journal文件
使用WiredTiger,即使没有journal功能,MongoDB也可以从最后一个检查点(checkpoint,可以想成镜像)恢复;但是,要恢复在上一个检查点之后所做的更改,还是需要使用Journal
如发生系统崩溃或使用kill -9命令强制终止数据库的运行,mongod会在启动时重放journal文件,同时会显示出大量的校验信息。
上面说的都是针对WiredTiger引擎,对于MMAPv1引擎来说有一点不一样,首先它是每100ms进行刷盘,其次它是通过private view写入journal文件,通过shared view写入数据文件。这里就不过多讲解了,因为MongoDB 4.0已经不推荐使用这个存储引擎了。
从MongoDB 3.2版本开始WiredTiger是MongoDB推荐的默认存储引擎
需要注意的是如果客户端的写入速度超过了日记的刷新速度,mongod则会限制写入操作,直到日记完成磁盘的写入。这是mongod会限制写入的唯一情况。
固定集合(Capped Collection)
在讲下面两种日志之前先来认识下capped collection。
MongoDB中的普通集合是动态创建的,而且可以自动增长以容纳更多的数据。MongoDB中还有另一种不同类型的集合,叫做固定集合。固定集合需要事先创建好,而且它的大小是固定的。固定集合的行为类型与循环队列一样。如果没有空间了,最老的文档会被删除以释放空间,新插入的文档会占据这块空间。
创建固定集合:
db.createCollection(``"collectionName"``,{``"capped"``:``true``, ``"size"``:100000, ``"max"``:100})
创建了一个大小为100000字节的固定大小集合,文档数量为100.不管先到达哪个限制,之后插入的新文档就会把最老的文档挤出集合:固定集合的文档数量不能超过文档数量限制,也不能超过大小限制。
固定集合创建之后就不能改变,无法将固定集合转换为非固定集合,但是可以将常规集合转换为固定集合。
db.runCommand({``"convertToCapped"``: ``"test"``, ``"size"` `: 10000});
固定集合可以进行一种特殊的排序,称为自然排序(natural sort),自然排序返回结果集中文档的顺序就是文档在磁盘的顺序。自然顺序就是文档的插入顺序,因此自然排序得到的文档是从旧到新排列的。当然也可以按照从新到旧:
db.my_capped_collection.find().sort({``"$natural"``: -1});
oplog主从日志
Replica Sets复制集用于在多台服务器之间备份数据。MongoDB的复制功能是使用操作日志oplog实现的,操作日志包含了主节点的每一次写操作。oplog是主节点的local数据库中的一个固定集合。备份节点通过查询这个集合就可以知道需要进行复制的操作。
一个mongod实例中的所有数据库都使用同一个oplog,也就是所有数据库的操作日志(插入,删除,修改)都会记录到oplog中
每个备份节点都维护着自己的oplog,记录着每一次从主节点复制数据的操作。这样,每个成员都可以作为同步源给其他成员使用。
如图所示,备份节点从当前使用的同步源中获取需要执行的操作,然后在自己的数据集上执行这些操作,最后再将这些操作写入自己的oplog,如果遇到某个操作失败的情况(只有当同步源的数据损坏或者数据与主节点不一致时才可能发生),那么备份节点就会停止从当前的同步源复制数据。

oplog中按顺序保存着所有执行过的写操作,replica sets中每个成员都维护者一份自己的oplog,每个成员的oplog都应该跟主节点的oplog完全一致(可能会有一些延迟)
如果某个备份节点由于某些原因挂了,但它重新启动后,就会自动从oplog中最后一个操作开始进行同步。由于复制操作的过程是想复制数据在写入oplog,所以备份节点可能会在已经同步过的数据上再次执行复制操作。MongoDB在设计之初就考虑到了这种情况:将oplog中的同一个操作执行多次,与只执行一次的效果是一样的。
由于oplog大小是固定的,它只能保持特定数量的操作日志。通常,oplog使用空间的增长速度与系统处理写请求的速率几乎相同:如果主节点上每分钟处理了1KB的写入请求,那么oplog很可能也会在一分钟内写入1KB条操作日志。
但是,有一些例外:如果单次请求能够影响到多个文档(比如删除多个文档或者多文档更新),oplog中就会出现多条操作日志。如果单个操作会影响多个文档,那么每个受影响的文档都会对应oplog的一条日志。因此,如果执行db.student.remove()删除了10w个文档,那么oplog中也就会有10w条操作日志,每个日志对应一个被删除的文档。如果执行大量的批量操作,oplog很快就会被填满。
慢查询日志
MongoDB中使用系统分析器(system profiler)来查找耗时过长的操作。系统分析器记录固定集合system.profile中的操作,并提供大量有关耗时过长的操作信息,但相应的mongod的整体性能也会有所下降。因此我们一般定期打开分析器来获取信息。
默认情况下,系统分析器处于关闭状态,不会进行任何记录。可以在shell中运行db.setProfilingLevel()开启分析器
db.setProfilingLevel(``level``,<slowms>) 0=``off` `1=slow 2=``all
第一个参数是指定级别,不同的级别代表不同的意义,0表示关闭,1表示默认记录耗时大于100毫秒的操作,2表示记录所有操作。第二个参数则是自定义“耗时过长"标准,比如记录所有耗时操作500ms的操作
db.setProfilingLevel(1,500);
如果开启了分析器而system.profile集合并不存在,MongoDB会为其建立一个大小为若干MB的固定集合(capped collection)。如希望分析器运行更长时间,可能需要更大的空间记录更多的操作。此时可以关闭分析器,删除并重新建立一个新的名为system.profile的固定集合,并令其容量符合要求。然后在数据库上重新启用分析器。
引言
在分布式数据库系统中,确保数据的高可用性和一致性是至关重要的。MongoDB使用副本集(Replica Set)来实现数据的冗余和高可用性,而操作日志(oplog)是副本集的核心机制之一。oplog记录了所有对主节点的写操作,副节点通过读取oplog实现数据的同步。了解如何查看和管理oplog日志,不仅有助于监控数据库的状态,还能够有效地进行故障排除和性能优化。
本文将详细讲解MongoDB的oplog日志,包括oplog的定义、查看方法、常见问题及最佳实践。
一、什么是oplog?
1. 定义
oplog(操作日志)是MongoDB中用于记录所有写操作的日志。它是一个特殊的集合,存储在副本集的主节点中。oplog用于确保副本集中的副节点与主节点的数据保持一致。当主节点执行写操作时,相应的操作将被记录到oplog中,副节点则通过读取oplog来获取最新的数据变化。
2. oplog的结构
oplog是一个无限增长的集合,包含以下主要字段:
ts:时间戳,表示操作的时间。
h:哈希值,用于唯一标识该操作。
op:操作类型,可能的值包括“i”(插入)、“u”(更新)、“d”(删除)。
ns:命名空间,表示操作所属的数据库和集合。
o:操作的详细内容,具体取决于操作类型。
3. oplog的作用
数据同步:副节点通过读取oplog来同步主节点的写入操作,确保数据一致性。
故障恢复:在主节点发生故障时,可以根据oplog中的信息快速恢复数据。
查询历史:oplog提供了一个操作历史的记录,有助于审计和问题排查。
二、如何查看oplog日志
1. 连接到MongoDB实例
首先,您需要连接到MongoDB的主节点。使用MongoDB shell(mongo命令)连接到主节点。例如:
mongo --host <主节点IP>:<端口>
2. 切换到oplog数据库
oplog存储在local数据库中。进入MongoDB shell后,您需要切换到local数据库:
use local
3. 查看oplog集合
oplog日志实际存储在oplog.rs集合中。要查看该集合中的数据,可以使用以下命令:
db.oplog.rs.find().sort({$natural: -1}).limit(10).pretty()
这里的$natural: -1表示按自然顺序从最新的日志开始排序,limit(10)表示只显示最新的10条记录。pretty()方法使输出格式更易读。
4. 监控oplog的大小
您可以通过以下命令查看oplog的大小和状态:
db.runCommand({ replSetGetStatus: 1 })
该命令将返回副本集的状态信息,其中包括oplog的大小、当前操作等。
5. 过滤oplog日志
如果您只对特定操作或特定时间范围内的日志感兴趣,可以使用查询条件过滤结果。例如,查看类型为“插入”的操作:
db.oplog.rs.find({ op: "i" }).pretty()
6. 检查oplog的操作频率
您还可以计算oplog日志中不同操作类型的频率,以评估数据库的写入性能:
db.oplog.rs.aggregate([
{ $group: { _id: "$op", count: { $sum: 1 } } }
])
该命令将返回每种操作类型的计数。
三、常见问题及解决方案
1. oplog日志的大小限制
oplog的大小默认是固定的,通常是根据MongoDB的数据集大小来设置的。在某些情况下,oplog可能会满,这会导致副节点无法同步数据。解决此问题的方法包括:
增加oplog大小:可以在启动MongoDB实例时设置--oplogSize参数来增加oplog的大小。例如:
mongod --replSet "myReplicaSet" --oplogSize 1024
监控和维护:定期监控oplog的使用情况,确保其不会达到上限。
2. oplog丢失数据
如果副节点在oplog日志被清除之前没有及时同步数据,可能会导致数据丢失。为防止这种情况,可以:
增加副本集节点数量:确保有足够的副节点来分担负载,并提高数据冗余。
使用持久化存储:确保MongoDB实例的存储是持久化的,以便在故障恢复时能够从oplog中恢复数据。
3. 查询性能问题
当oplog日志过大时,查询性能可能会下降。可以通过以下方式优化查询:
限制返回数据量:使用limit()限制返回的记录数。
创建索引:可以在oplog.rs集合上创建索引,以加快查询速度。
四、最佳实践
为了有效管理和查看oplog日志,建议遵循以下最佳实践:
1. 定期监控oplog
通过设置监控工具(如Prometheus、MongoDB Atlas等)定期检查oplog的状态和大小,以便及时发现潜在问题。
2. 增加oplog大小
根据实际业务需求和数据增长情况,适时增加oplog的大小,以确保副本集能够高效同步数据。
3. 日志审计
利用oplog进行日志审计,以便在发生问题时追踪操作历史。可以定期将oplog的相关信息导出以备查。
4. 备份策略
实施定期的备份策略,确保在数据丢失或损坏时可以迅速恢复。结合oplog进行增量备份,以减少数据恢复时间。
5. 测试故障恢复
定期进行故障恢复测试,验证副本集的高可用性和数据一致性。确保在主节点故障时,副节点能够顺利接管。
五、总结
oplog是MongoDB副本集的重要组成部分,承担着数据同步和故障恢复的关键任务。通过查看和管理oplog日志,数据库管理员可以有效监控数据状态,排查问题,以及优化系统性能。掌握oplog的查看方法和常见问题解决方案,不仅有助于维护系统的健康运行,也为企业的数据安全提供了保障。
在实际操作中,建议结合监控工具、备份策略和故障恢复测试等手段,以实现对MongoDB数据库的全面管理。随着企业对数据管理需求的不断增加,深入理解oplog的使用和管理将为数据库的高可用性和一致性提供有力支持。
-------------------------------------------------------------------------------------
MongoDB有多种部署模式,可以根据业务需求选择适合的架构和部署方式。
单节点模式(Standalone)
单节点部署是单个MongoDB示例,也是最简单的部署方式,数据都存储在一个节点上,这种方式现在很少使用。
特点:
适用于开发、测试或小型应用场景。
无数据冗余,不具备高可用性。
单节点故障会导致服务中断。
优点:
易于设置和维护,资源消耗低。
适用场景:
开发测试环境。
对高可用性要求不高的应用。
副本集模式(Replica Set)
MongoDB 中的副本集是一组维护相同数据集的 mongod 进程。副本集提供冗余和高可用性,是所有生产部署的基础,副本集包含多个数据承载节点和一个可选的仲裁节点。在数据承载节点中,只有一个主节点,其他被为从节点。
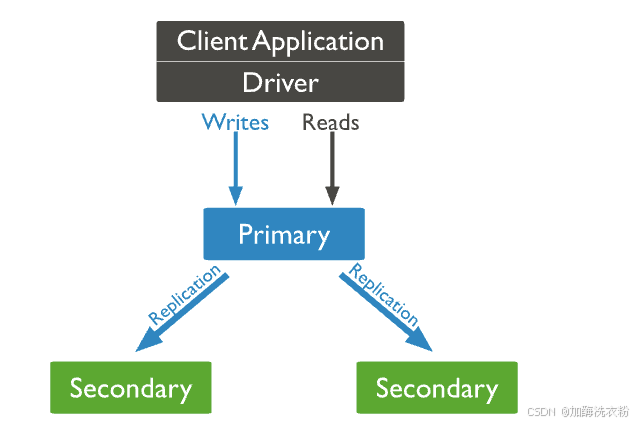
主节点:主节点会接受所有的写入操作,副本集中只会有一个主节点
从节点:从节点存储也是一个完整的数据集,会复制主节点的oplog(oplog是主节点上的操作日志),并将这些操作应用于其数据集,以便从节点的数据集反映主节点的数据集状态。如果主节点不可用,则某个符合条件的从节点将进行选举,以将自己选举为新的主节点。
特点:
一组MongoDB实例组成,提供数据冗余和高可用性。
自动故障切换:主节点宕机后,剩余节点选举出新的主节点。
数据一致性高(强一致性)。
优点:
提供高可用性,保障数据安全。
适用于生产环境。
缺点:
需要额外的硬件资源。
配置和维护比单节点稍复杂。
适用场景:
需要高可用性和自动故障恢复的生产环境。
分片集群模式(Sharded Cluster)
副本集模式就是一个主从架构,虽然可以提升了高可用性,但是每个节点都需要存储全部数据,这种冗余的方式增加了资源的消耗。而分片集群可以提供更好的可用性。
分片:分片是一种跨多台机器分布数据的方法,mongo将数据分化为多个分片,每个分片保存的是数据的一部分,所有分片的数据叠加起来就是完整的数据。
分片集群:数据虽然被分配到多个分片节点上,但是每个分片也需要做冗余这样才能提高可用性,所有每个分片也会有多个副本集,就是一个副本集模式,有主分片和从分片数据。
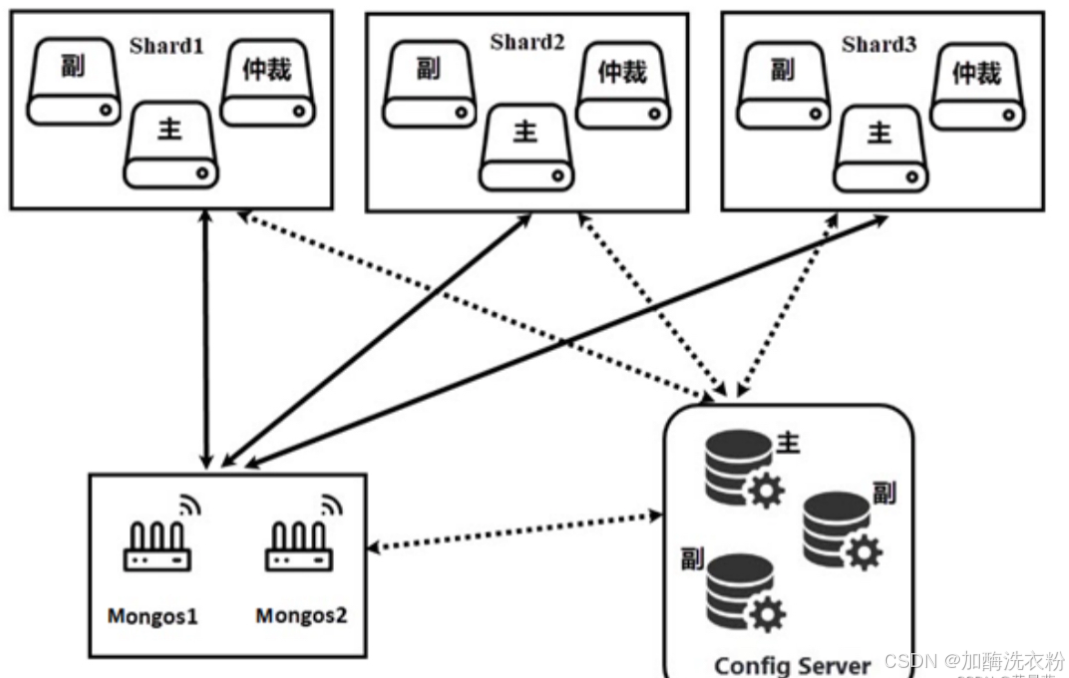
MongoDB的分片集群由一下几个组件构成:
分片(shard):分片是存储数据的位置,每个分片都包含分片数据的一个子集,每个分片都必须作为一个副本集进行部署。
路由服务器(mongos):mongos 充当查询路由器,在客户端应用程序和分片集群之间提供接口,客户端访问分片集群是直接和mongos服务器连接而不会直接和具体的分片连接,mongos会将请求分配到具体的分片上进行操作,同时多个分片的结果也会聚合到mongos上进行处理。
配置服务器(config sderver):配置服务器会存储集群的元数据和配置设置,配置服务器最主要的作用就是记录集群分片的情况,mongos进行路由的时候需要知道路由到哪个分片,而这就要依据config server的分片配置数据,配置服务器也是副本集模式部署。
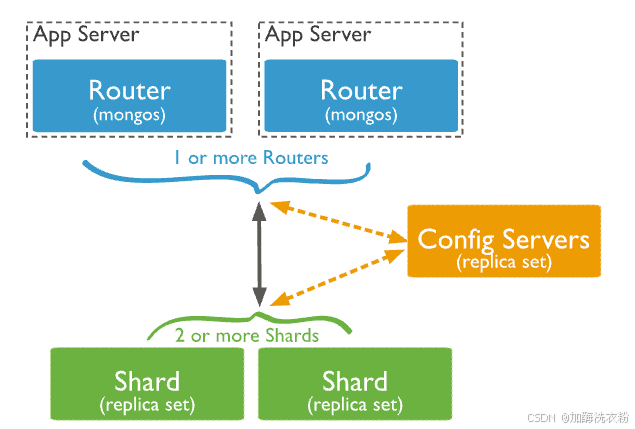
特点:
提供水平扩展能力,适合大规模数据和高并发应用。
数据根据分片键分布在不同的分片中。
MongoDB 在分片集群中的分片之间分配读写工作负载,支持每个分片处理集群操作的子集。通过添加更多的分片,读写工作负载都可以在集群中横向扩展。
优点:
支持大数据集和高吞吐量。
可按需扩展存储和计算能力。
缺点:
部署和维护复杂,要求分片键设计合理。
Config Server成为潜在的性能瓶颈。
适用场景:
大型分布式系统。
数据量超出单节点存储能力的场景。
-------------------------------------------------------------------------------------
一、MongoDB集群架构介绍
MongoDB 有三种集群架构模式,分别为主从复制(Master-Slaver)、副本集(Replica Set)和分片(Sharding)模式。
1.1 主从复制
这种表述方式描述的是早期 MongoDB 中的一种复制模式,即一个主节点(Master)负责处理写入操作,多个从节点(Slave)被动复制主节点的数据。主从复制模式在现代 MongoDB 中已经不再推荐使用,因为它缺乏自动故障转移、数据一致性保障和灵活的读负载均衡能力。
自 MongoDB 3.6 版本起,官方已弃用主从复制模式,并推荐使用副本集(Replica Set)替代。因此,严格来说,现代 MongoDB 不再将主从复制作为一种推荐或官方支持的集群架构模式。
1.2 副本集
副本集是现代 MongoDB 中用于实现数据冗余、高可用性和读负载均衡的主要方式。它包含一个主节点(Primary)和一个或多个从节点(Secondary)。与主从复制相比,副本集提供了自动故障转移、数据一致性保证以及对从节点读取能力的精细控制。
副本集是目前 MongoDB 中主流且推荐的集群架构模式之一,用于实现数据的高可用性和读写分离。
1.3 分片集群
分片是 MongoDB 用于水平扩展、处理大规模数据集和高并发读写的架构模式。通过将数据划分为多个分片(shards),每个分片可以是一个副本集,数据根据分片键(shard key)分布在不同的分片上。此外,还包括配置服务器集群(Config Server)和路由进程(Mongos)。
分片是现代 MongoDB 中另一种重要的集群架构模式,用于处理超出单个服务器或副本集处理能力的大规模数据集。
二、副本集
MongoDB 副本集架构如下图,副本集简单来说就是有故障恢复功能的主从集群。成员身份包括主节点、从节点、仲裁者。任何时间,集群中只有一个活跃节点,其他的都为备份节点,活跃节点实际上是活跃服务器。有几种不同的类型节点可以存在于副本集中
主节点:主节点是副本集中唯一接受写操作的节点,负责处理客户端的所有写请求,如插入、更新、删除等。主节点通过心跳机制与从节点保持通信,报告自身的状态并接收从节点的状态信息。
从节点:从节点通过复制主节点的 oplog 来保持与主节点数据的同步。它们可以处理只读查询,分担主节点的读负载。从节点在保持数据同步的同时,参与副本集的选举过程,当主节点不可用时,有能力成为新的主节点。
仲裁节点:从节点在保持数据同步的同时,参与副本集的选举过程,当主节点不可用时,有能力成为新的主节点。仲裁节点的存在可以减少需要维护数据副本的服务器数量,尤其适用于资源有限的环境,或者需要额外投票节点以满足法定人数(quorum)要求的场景。
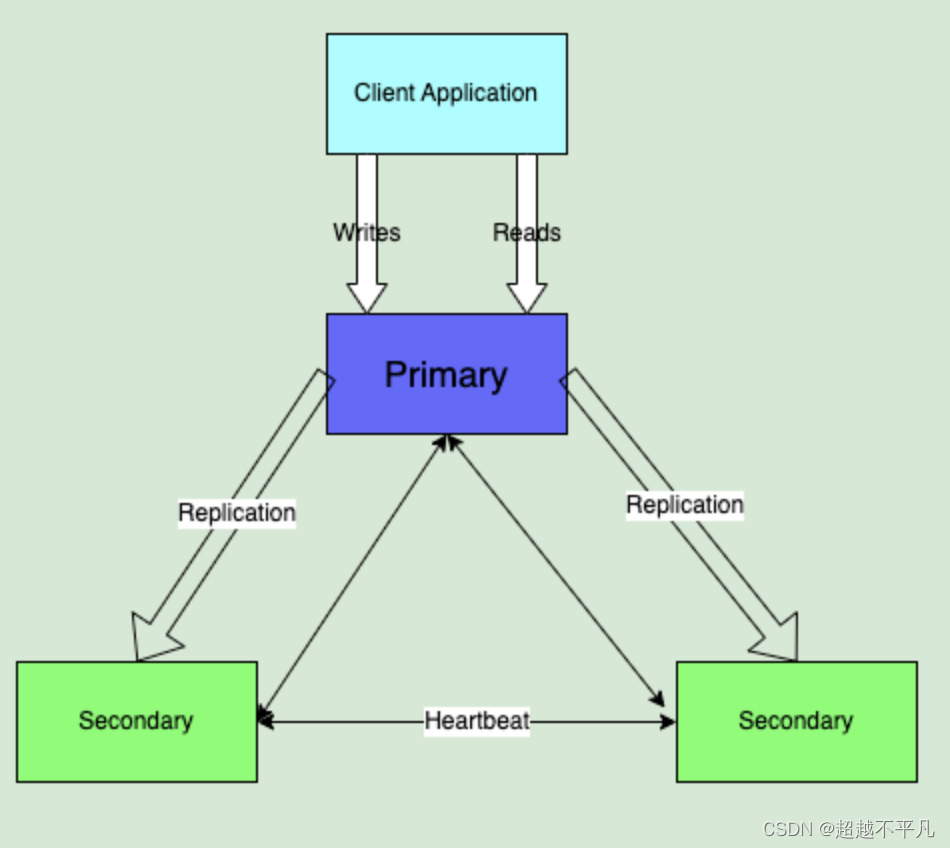
MongoDB 提供了读扩展机制,默认情况下,客户端从 Primary 读取数据,但是可以通过配置将读取操作发送到 Secondary。当负载是读取密集型时这是不错的选择。如果是写入密集型,就需要用分片来实现扩展。
3.1 主节点选举
MongoDB 在副本集中会自动进行主节点的选举,主节点选举被触发的条件:
主节点故障
主节点网络不可达(默认心跳时间为10s)
人工干预
一旦触发选举,就要根据一定规则来选举主节点,选举根据票数来决定谁获胜。
只有具有投票权的节点(包括主节点、从节点和仲裁节点)才能参与选举投票。
发起选举,符合资格的节点会向其他副本集成员发送选举请求(即投票消息),包含自己的投票意图(希望成为主节点)和当前的选举轮次信息。节点收到选举请求后,会根据自身状态和请求信息决定是否投票支持该候选节点。
每个节点在一个选举轮次中只能投一票。投票规则:
优先选择具有最新数据的节点,即 oplog 时间戳最新的节点。
考虑节点的优先级(priority),优先级高的节点更可能获得选票。
如果优先级和数据新鲜度相同,选择具有更高节点 ID 的节点。
票数最高,获得了"大多数"成员的投票支持的节点获胜。大多数的定义为:假设集群内投票成员数量为N,最大数为N/2 + 1。例如3个成员投票,则大多数的值为2。当集群存活的成员数不足大多数时,整个复制集群无法选举Primary,集群将停止提供写服务,处于只读状态。
3.2 oplog
MongoDB 的复制集至少需要两个服务器或者节点,其中一个是主节点,负责处理客户端请求,其他的都是从节点,负责映射主节点数据。主节点记录在其上执行的所有操作。从节点定期轮询主节点获得这些操作,然后对自己的副本数据进行操作。由于和主节点执行相同的操作,从节点就能保持与主节点的数据同步。
主节点的操作记录称为 oplog,oplog 存储在一个特殊的数据库中,叫做 local。对于老版本主从复制的名称为 oplog oplog.$main,对于副本集名称为 oplog.rs。oplog 中每个文档都代表了主节点上的一个操作,文档内容如下:
ts:操作的时间戳,用于跟踪操作的执行时间
t:事务编号,用于标识属于同一事务的一组操作
v:记录oplog的版本
op:操作类型
i:insert
u:update
d:delete
c:db cmd
db:申明当前数据库
n:no op,即空操作,会定期执行,确保时效性
ns:操作的命名空间
o:操作所对应的具体文档,即当前操作的内容
实际的内容如下图:
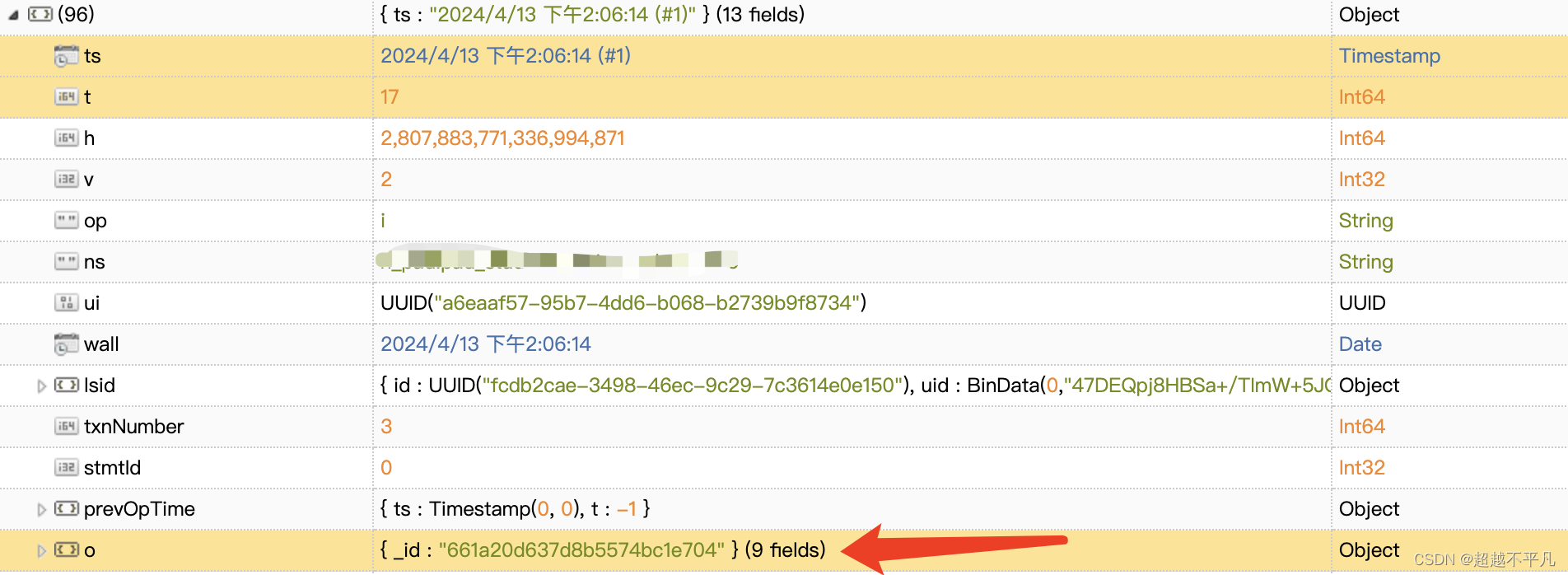
需要强调的是oplog只记录改变数据库状态的操作。比如,查询就不在存储oplog中。
3.2 主从同步
从节点第一次启动时,会对主节点的数据进行完整同步。从节点复制主节点上的每个文档,耗费的资源可想而知。同步完成后,从节点通过心跳开始查询最新的 oplog 并执行这些操作,以保证数据是最新的。
从节点(Secondary)定期或持续的连接到主节点,读取并监视器 oplog。从节点将 oplog中的新记录下载到本地的 oplog 集合中,形成一个与主节点 oplog 相似的副本。从节点按照 oplog 记录的顺序,将每个操作在其本地数据副本上重新执行一遍,从而将主节点的写操作同步到自己的数据集中。这个过程通常称为“回放”(replay)。
oplog 是一个 capped collection(固定集合),这意味着它有一个预先设定的最大容量并且会自动覆盖。当达到这个容量后,oplog 会自动删除最早的记录以腾出空间给新的写操作记录。这个容量可以通过设置 oplogSize 参数来指定,单位通常是 MB 或 GB。
当 oplog 达到其上限时,新的写操作会推动旧的记录出 oplog。这个过程是自动的,由 MongoDB 内部管理。被清理的记录是那些已经过期(即从节点已经同步)或在主节点上被覆盖(如在回滚事务时)的记录。
如果从节点在 oplog 记录被清理后还没有同步到这些记录,理论上存在数据丢失的风险。然而,MongoDB 的复制机制设计旨在尽量避免这种情况的发生:
心跳与检查点:从节点定期向主节点发送心跳消息,报告其复制进度(已复制到 oplog 中的某个时间点)。主节点在清理 oplog 时会考虑到这些信息,确保已报告同步进度的从节点不会因为 oplog 清理而丢失数据。
延迟阈值:从节点如果在一段时间内没有报告复制进度,主节点会认为该从节点可能已落后太多或出现故障,此时主节点会更加保守地管理 oplog,避免过早清理可能仍有从节点需要的记录。
数据安全窗口:管理员在配置 oplog 大小时,应考虑网络延迟、从节点处理速度等因素,确保 oplog 足够大,能容纳在最坏情况下从节点需要同步的所有操作。一般建议 oplog 大小应能容纳至少几个小时甚至一天的写操作,以应对网络中断或其他可能导致同步延迟的情况。
监控与报警:通过监控复制集的状态(如使用 rs.status() 或相关工具),及时发现复制延迟问题,并在必要时介入调整复制配置或解决网络问题,避免从节点长期落后导致数据丢失的风险。
数据一致性如何保障的?主节点在将写操作记录到 oplog 后,才会向客户端返回确认。这意味着只要主节点确认写入成功,即使此时从节点还未复制该数据,但该数据已经在主节点上持久化,能够在从节点故障时通过主节点的备份恢复。
三、分片集群
分片是 MongoDB 的扩展方式,分片是指将数据拆分,将其分散在不同机器上的过程,有时也用分区来表示这一概念。将数据分散在不同机器上,不需要功能强大的计算机就可以存储大量数据,处理更大的负载。
分片集群的组成如下
shard:每个分片包含分片数据的一个子集。每个分片都可以部署为副本集
mongos:mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口
config servers:配置服务器存储集群的元数据和配置设置,存储了分片列表、每个分片包含的 chunk、路由规则等等
分片集群架构图如下:
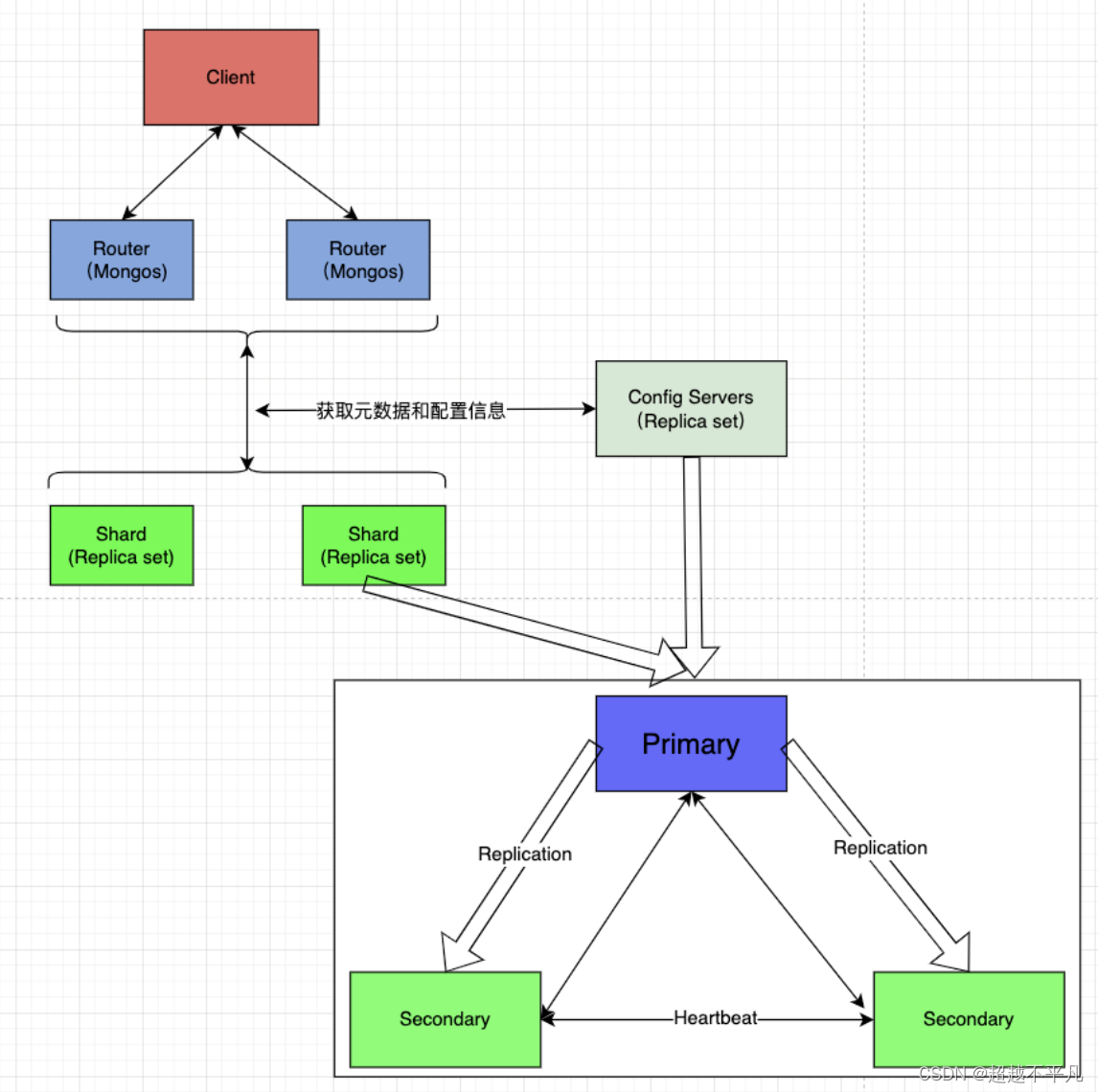
MongoDB支持自动分片,可以摆脱手动分片的困扰。集群自动切分数据,做负载均衡。分片集群的概念:
Shard Rules:分片规则,也叫分片算法,指分发读写请求的逻辑
Shard Key:分片键,也叫路由键,指基于文档中的哪个字段进行分片计算
Document:文档,一条数据
Chunk:块,指包含一定范围内多个文档的数据段,数据集群中分割、存储数据的基本单元
Shard:分片,每个分片都由一个副本集组成,一个分片中可以存储多个Chunk
Cluster:集群,由多个Shard分片组成,统一对外提供读写服务
MongoDB 分片的基本思想就是将集合切分成小块(chunk)。这些块分散到若干片里面,每个片只负责一部分数据。应用程序不必知道哪片对应哪些数据,甚至不知道数据已经拆分,所以在分片之前需要运行一个路由进程,该进程的名字为mongos。这个路由知道所有数据存放位置,所以应用可以链接他来正常发送请求。
3.1 分片策略
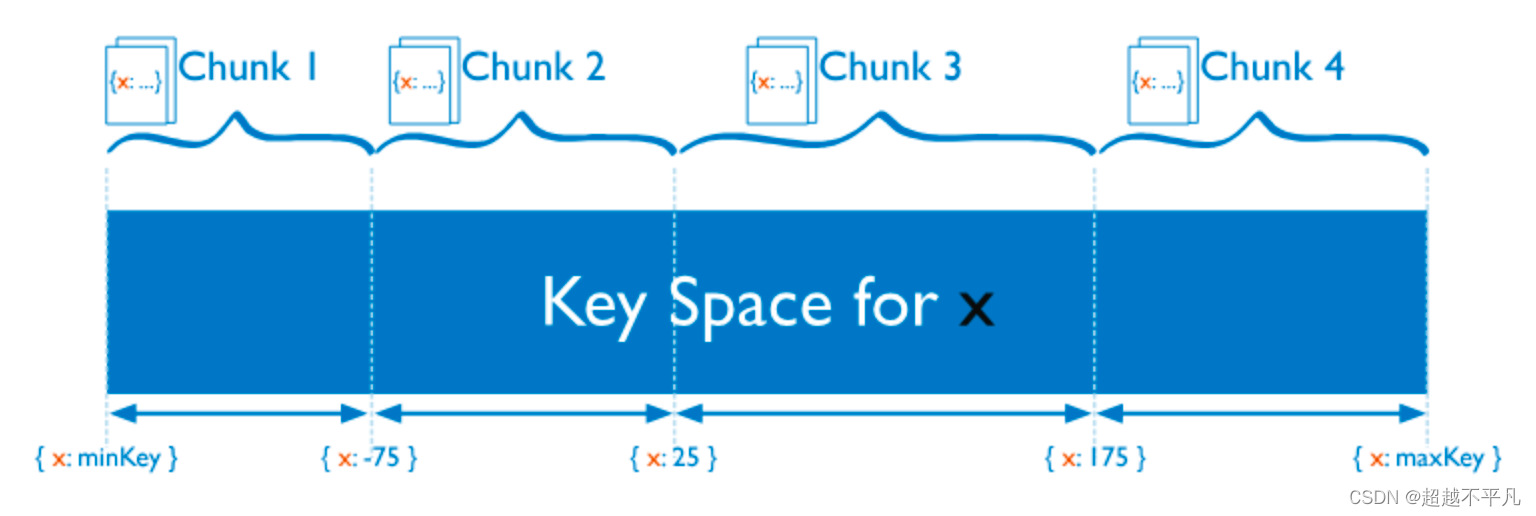
将数据分散到不同的机器上通常有两种方案,Hash和范围划分。
Hash分片:把 Key 作为输入,输入到一个 Hash 函数中,计算出一个整数值,值的集合形成了一个值域,我们按照固定步长去切分这个值域,每一个片叫做 Chunk ,这里的 Chunk 则就是整数的一段范围而已。
优点事速度快,均衡性好,但排序性差
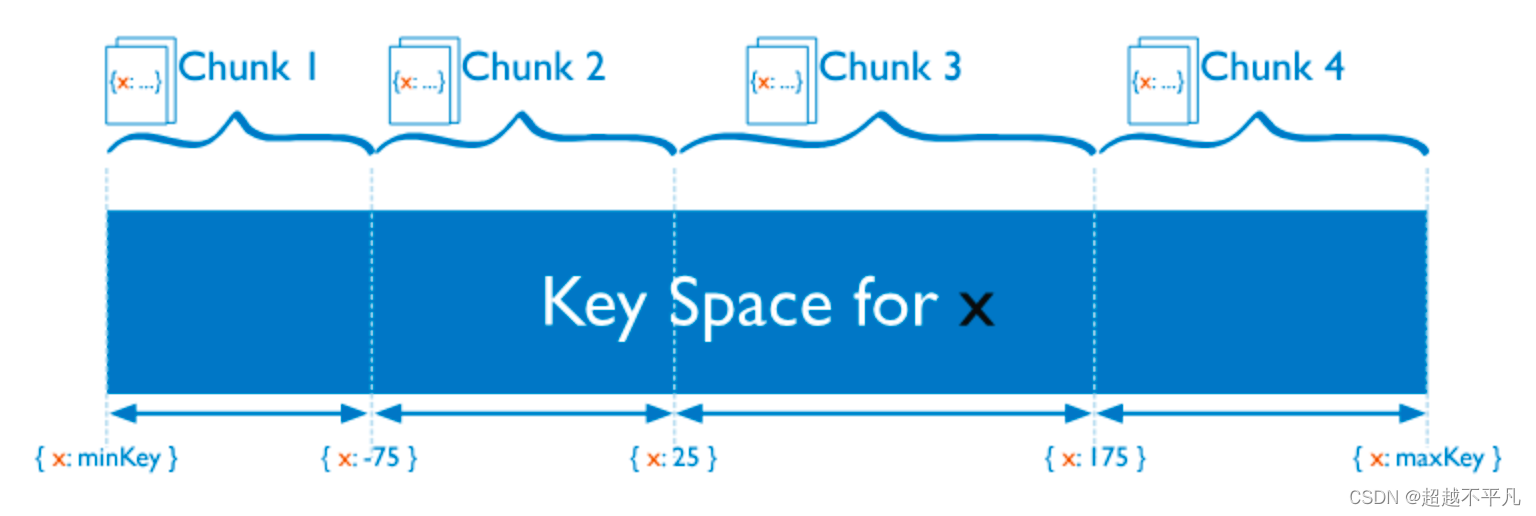
范围分片:按一定的范围进行切分,与 TiDB 类似。优点是排序性好,缺点是容易引起热点数据。
3.2 分片键的选择
设置分片时,需要从集合里选一个键,用该键的值作为数据拆分的依据。这个键称为片键(shard key)。
片键分为递增片键和随机片键,该如何选择呢?
如果写入负载很高的话,不适合使用递增片键,比如时间戳,因为写入会集中在一个片内,但递增片键查询效率非常高。如果写入负载很高的话,选择随机片键,均匀分散负载到各个片上。
不论片键随机跳跃还是稳定增加,片键的变化至关重要,例如,如果有个“logLevel”键只有3个值,DEBUG、WARN 或 ERROR,MongoDB 就无论如何也不会把他作为片键将数据分为3块。如果键的变化太少,但又想将其作为片键,可以将这个键与一个变化较大的键组合起来。
3.3 何时选择分片集群
出现下面信号时就可以考虑分片了
机器的磁盘不够用了
单个mongod已经不能满足写数据性能要求
想将大量数据放在内存中提高性能
一般来说,先要从不分片开始,然后再需要时将其转换成分片。虽然提供了更强的扩展性和容错能力,但分片集群架构更为复杂,需要管理配置服务器、路由节点(Mongos)、分片节点以及相关网络配置,运维成本较高。同时,硬件和云资源需求可能增加,导致成本上升。
四、总结
当讨论 MongoDB 的集群架构时,应强调副本集和分片这两种官方推荐和支持的模式。如果在历史背景下讨论,可以提及主从复制作为早期的一种复制方式,但需明确指出它在现代 MongoDB 中已不再适用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号