Java代码执行机制
1、Java代码执行流程

- 第一步:*.java-->*.class(编译期)
- 第二步:从*.class文件将其中的内容加载到内存(类加载)(运行期)
- 第三步:执行代码(运行期)
说明:
- 整个白框部分表示JVM管理的内存
- 包含栈帧的地方称作JVM方法栈,一个栈帧就是一个方法
- 在Hotspot JVM中,JVM方法栈和本地方法栈是同一个
- java方法是通过出栈操作来执行的(在类加载后入栈),所以执行引擎直接操作的是栈帧(即一个方法)
- 具体的JVM内存结构
2、代码编译
javac命令将源码文件编译为*.class文件。
后边将介绍:
- javac将*.java编译成*.class文件的过程
- class文件的文件格式,以及其存储的内容
3、类加载
主要是指将*.class文件加载到JVM,并形成Class对象的机制,之后就可以对Class对象实例化并调用了。
特点:
- 类加载机制可以在运行时动态加载外部类
后边将介绍:
- 类加载的过程
- 类加载的双亲委托机制
- 类加载器的层次关系及源码
4、执行代码
两种执行方式:
- 解释执行(运行期解释字节码并执行)
- 速度慢,效率低
- 但是要比编译为机器码执行省内存
- 编译为机器码执行(将字节码编译为机器码并执行,这个编译过程发生在运行期,称为JIT编译),下面是两种模式
- client(即C1):只做少量性能开销比高的优化,占用内存少,适用于桌面程序。
- server(即C2):进行了大量优化,占用内存多,适用于服务端程序。会收集大量的运行时信息。
注意:
- 32为机器默认选择C1,可在启动时添加-client或-server来指定,64位机器若CPU>2且物理内存>2G则默认为C2,否则为C1
- Sun JDK执行代码的机制:对在执行过程中执行频率高的代码进行编译,对执行频率不高的代码继续解释执行
后边将介绍:
- Sun JDK执行代码的过程
- C1以及C2执行的一些优化
- 编译执行与解释执行的使用的衡量点
第二章 Javac编译原理
1、javac作用
- 将*.java源代码文件转化为*.class文件
2、编译流程
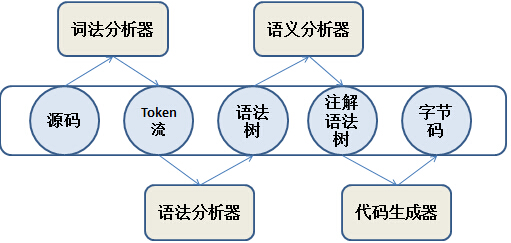
流程:
- 词法分析器:将源码转换为Token流
- 将源代码划分成一个个Token(Token包含的元素类型看3.2)
- 语法分析器:将Token流转化为语法树
- 将上述的一个个Token组成一句句话(或者说成一句句代码块),检查这一句句话是不是符合Java语言规范
- 语义分析器:将语法树转化为注解语法树
- 将复杂的语法转化成简单的语法(eg.注解、foreach转化为for循环)并做一些检查,添加一些代码
- 代码生成器:将注解语法树转化为字节码
3、词法分析
3.1、作用
- 将源码转换为Token流。
3.2、流程
一个字节一个字节的读取源代码,形成规范化的Token流。规范化的Token包含:
- java关键词:package、import、public、class、int等
- 自定义单词:包名、类名、变量名、方法名
- 符号:=、;、+、-、*、/、%、{、}等
3.3、示例
代码:
1 package compile;
2
3 /**
4 * 词法
5 */
6 public class Cifa {
7 int a;
8 int c = a + 1;
9 }
以上代码转化为的Token流:
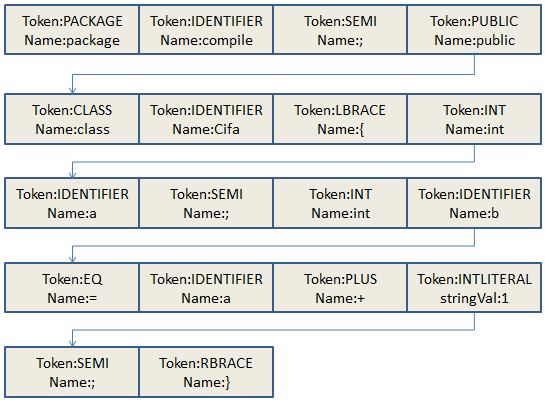
说明:完成以上示例的是JavacParser的parseCompilationUnit()方法,源代码见文章开头的书籍。
注意:上边的token流符合java语言规范。
3.4、疑问
- 怎样判断package是java关键词还是自定义变量?
- JavacParser会根据java语言规范来控制什么顺序、什么地方出现什么Token(这个查看parseCompilationUnit()源码就知道了),所以package在文件的最开头出现,我们会知道是一个Token.PACKAGE类型,而非自定义的Token.IDENTIFIER类型。
- 一条实践:在编写程序的时候,不要用java关键词来定义变量名、类名、包名、方法名,而是采取一定有意义的单词来定义,当然,你再eclipse中编写代码的时候,如果使用了java关键词来定义变量,eclipse会提醒你这是一个错误的定义。
- 怎样确定package是一个Token,而packa不是?
- 我的理解是,主要看空格和符号(符号见3.2),对于package是一个单词,中间没有空格也没有符号,所以是一个Token
- 一条实践:在编写代码时,例如:int a = b + c;//a与=中间有一个空格、=与b之间有一个空格、b与+之间有一个空格、+与c之间有一个空格,当然,这里没有空格也行,因为每一个变量之间正好都是由符号来隔开的,但是之前看了一个视频说,如果上边这句话没有这些空格的话,可能编译不通过,所以我们最好还是加上空格,当然加上空格后显得整个代码也清晰。
4、语法分析
4.1、作用
- 将进行词法分析后形成的Token流中的一个个Token组成一句句话,检查这一句句话是不是符合Java语言规范。
4.2、语法分析三部分:
- package
- import
- 类(包含class、interface、enum),一下提到的类泛指这三类,并不单单是指class
最终语法树:

说明:
- 每一个包package下的所有类都会放在一个JCCompilationUnit节点下,在该节点下包含:package语法树(作为pid)、各个类的语法树
- 每一个从JCClassDecl发出的分支都是一个完整的代码块,上述是四个分支,对应我们代码中的两行属性操作语句和两个方法块代码块,这样其实就完成了语法分析器的作用:将一个个Token单词组成了一句句话(或者说成一句句代码块)
- 在上述的语法树部分,对于属性操作部分是完整的,但是对于两个方法块,省略了一些语法节点,例如:方法修饰符public、方法返回类型、方法参数。
疑问:
import节点的语法树与package的相似,但是import语法树放在了哪一个地方?
5、语义分析
5.1、作用
- 将语法树转化为注解语法树
5.2、步骤
- 添加默认的无参构造器(在没有指定任何有参构造器的情况下)
- 处理注解
- 标注:检查语义合法性、进行逻辑判断
- 检查语法树中的变量类型是否匹配(eg.String s = 1 + 2;//这样"="两端的类型就不匹配)
- 检查变量、方法或者类的访问是否合法(eg.一个类无法访问另一个类的private方法)
- 变量在使用前是否已经声明、是否初始化
- 常量折叠(eg.代码中:String s = "hello" + "world",语义分析后String s = "helloworld")
- 推导泛型方法的参数类型
- 数据流分析
- 变量的确定性赋值(eg.有返回值的方法必须确定有返回值)
- final变量只能赋一次值,在编译的时候再赋值的话会报错
- 所有的检查型异常是否抛出或捕获
- 所有的语句都要被执行到(return后边的语句就不会被执行到,除了finally块儿)
- 进一步语义分析
- 去掉永假代码(eg.if(false))
- 变量自动转换(eg.int和Integer)
- 去掉语法糖(eg.foreach转化为for循环,assert转化为if,内部类解析成一个与外部类相关联的外部类)
- 最后,将经过上述处理的语法树转化为最后的注解语法树
6、生成字节码
6.1、作用
- 将注解语法树转化成字节码,并将字节码写入*.class文件。
6.2、步骤
- 将java的代码块转化为符合JVM语法的命令形式,这就是字节码
- 按照JVM的文件组织格式将字节码输出到*.class文件中
具体的源代码与步骤查看com.sun.tools.javac.jvm.Gen类与《分布式Java应用:基础与实践》P42
6.3、class文件包含的内容
在生成的*.class文件中不只包含字节码信息,具体包含:
- 结构信息
- class文件格式版本号
- 各部分的数量与大小
- 元数据
- 类、父类、实现接口的声明信息
- 属性声明信息
- 方法声明信息
- 常量池
- 方法信息
- 字节码
- 异常处理器表
- 局部变量区的大小
- 操作数栈的大小
- 操作数栈的类型记录
- 调试用符号信息
这里提到的局部变量区和操作数栈组成了了方法栈,
第三章 类文件结构与javap的使用
1、javap的使用与类文件结构
使用过程:
java源代码:

1 package compile;
2 /**
3 * class字节码
4 */
5 public class TestClass {
6 private int m;
7
8 public int inc() {
9 return m + 1;
10 }
11 }

1 package compile;
2 /**
3 * class字节码
4 */
5 public class TestClass {
6 private int m;
7
8 public int inc() {
9 return m + 1;
10 }
11 }
在硬盘上找到java源文件所在目录(eg.E:\Java\workspaceOfMyBatis3\baseUtil\src\compile)
打开命令窗口,执行"javac -g TestClass.java"生成TestClass.class字节码文件,然后使用"javap -c TestClass > TCC.txt"将字节码文件的处理结果输出到TCC.txt中。

打开TCC.txt,如下:
Compiled from "TestClass.java"
public class compile.TestClass extends java.lang.Object{
public compile.TestClass();
Code:
0: aload_0
1: invokespecial #1; //Method java/lang/Object."<init>":()V
4: return
public int inc();
Code:
0: aload_0
1: getfield #2; //Field m:I
4: iconst_1
5: iadd
6: ireturn
}
Compiled from "TestClass.java"
public class compile.TestClass extends java.lang.Object{
public compile.TestClass();
Code:
0: aload_0
1: invokespecial #1; //Method java/lang/Object."<init>":()V
4: return
public int inc();
Code:
0: aload_0
1: getfield #2; //Field m:I
4: iconst_1
5: iadd
6: ireturn
}
说明:
- javac -g TestClass.java
- -g:生成所有的调试信息,包括局部变量名和行号信息。
- javap -c TestClass > TCC.txt,对于javap常用的参数:
- -c:输出字节码Code
- -l(小写L):输出Code、LineNumberTable与LocalVariableTable
- -s:输出方法签名(方法的接收参数列表和返回值)
- -verbose:包含-c、-l以及输出class文件的编译版本,常量池,Stack, Locals, Args_size
- 对于javap而言,常用的就是-c或-verbose
这里列出使用"javap -verbose TestClass > TCV.txt的结果:
Compiled from "TestClass.java"
public class compile.TestClass extends java.lang.Object
SourceFile: "TestClass.java" /* 源文件名称 */
minor version: 0 /* 次版本号 */
major version: 50 /* 主版本号,50-->jdk6 */
Constant pool: /* 常量池:存放所有的方法名、field名、方法签名(方法参数+返回值)、类型名、class文件中的常量值 */
const #1 = Method #4.#18; // java/lang/Object."<init>":()V
const #2 = Field #3.#19; // compile/TestClass.m:I
const #3 = class #20; // compile/TestClass
const #4 = class #21; // java/lang/Object
const #5 = Asciz m; /*field名*/
const #6 = Asciz I; /*类型名*/
const #7 = Asciz <init>; /*方法名(构造器)*/
const #8 = Asciz ()V; /*方法签名(方法参数+返回值)*/
const #9 = Asciz Code;
const #10 = Asciz LineNumberTable; /*class文件中的常量值:Java源码的行号与字节码指令对应关系*/
const #11 = Asciz LocalVariableTable; /*class文件中的常量值:局部变量表*/
const #12 = Asciz this;
const #13 = Asciz Lcompile/TestClass;; /*当前类的类型"Lxxx;"表示xxx引用类型*/
const #14 = Asciz inc; /*方法名*/
const #15 = Asciz ()I; /*方法签名(方法参数+返回值)*/
const #16 = Asciz SourceFile; /*class文件中的常量值:源文件名称*/
const #17 = Asciz TestClass.java; /*class文件中的常量值:源文件名称*/
const #18 = NameAndType #7:#8;// "<init>":()V
const #19 = NameAndType #5:#6;// m:I
const #20 = Asciz compile/TestClass; /*类型名*/
const #21 = Asciz java/lang/Object; /*类型名*/
{
public compile.TestClass();
Code: /* 方法字节码 */
/* Stack:操作数栈的深度(这个值就是类加载阶段为操作数栈分配的深度)
* Locals:局部变量的分配空间(单位是slot,不是个数),对于double和long这两个64bit的,需要两个slot,对于其他<=32bit的,只需要一个slot
* Args_size:方法参数的个数,包括方法参数、this(this只针对实例方法,static方法不会自动添加this)
*/
Stack=1, Locals=1, Args_size=1
0: aload_0 /*将第0个Slot中的引用类型的本地变量推到操作数栈顶,这里就是LocalVariableTable的this*/
1: invokespecial #1; //Method java/lang/Object."<init>":()V /* invokespecial #1:调用#1常量代表的方法,这里就是super(),当前栈顶的元素作为该方法#1的接收者 */
4: return /*返回该方法,该方法的返回值为Void,执行了return指令,方法结束*/
LineNumberTable: /* Java源码的行号与字节码指令对应关系 */
line 5: 0
LocalVariableTable: /* 局部变量表 */
Start Length Slot Name Signature
0 5 0 this Lcompile/TestClass;
public int inc();
Code:
Stack=2, Locals=1, Args_size=1
0: aload_0 /*将第0个Slot中的引用类型的本地变量推到操作数栈顶,这里就是LocalVariableTable的this*/
1: getfield #2; //Field m:I /*getfield #2:获取常量表中定义的#2实例(即实例m),然后将m推到操作数栈顶*/
4: iconst_1 /*向栈顶压入一个int常量1*/
5: iadd /*将栈顶的两个元素相加(这里是1和m),然后将结果压入栈顶*/
6: ireturn /*从当前方法返回栈顶的int型数值结果*/
LineNumberTable:
line 9: 0
LocalVariableTable:
Start Length Slot Name Signature
0 7 0 this Lcompile/TestClass;
}
说明:
- 上述文件中/*xxx*/这样的注释是我添加的,//这样的注释是javap自己生成的
- 需要知道的是,上述的文件并非是生成的*.class文件,*.class文件的内容是一串接近于机器码的十六进制字符,开头是一个魔数"0xCAFEBABE",该魔数是确定一个文件是否是class文件的标准。之后就是class编译版本(minor version,major version),然后下边的顺序与TCV.txt的顺序一样了。
- 在TCV.txt文件中,多了一个无参构造器方法,该无参构造器调用的是TestClass的父类Object的无参构造器(即执行了super()方法),这个无参构造器是在javac变异的第三步"语义分析"的时候添加的,
注意:
- 常量池的存放内容
- 存放所有的方法名
- field名
- 方法签名(方法参数+返回值)
- 类型名
- class文件中的常量值
- 常量池的前四部分可以称作是符号引用(即只有一些名称,但没有实际的地址,在运行期进行类的加载过后,会为这些东西分配实际的内存,到时候符号引用就会转化为直接引用,就能被JVM用了)
- 常量池的组成:符号引用、常量(这个常量包含我们代码中定义的常量,eg、字符串常量,也包括class文件中的常量,eg.SourceFile)。
- 主版本号的对应(eg.50对应jdk6,51对应jdk7),查看《深入理解java虚拟机(第二版)》P167
- Stack:操作数栈的深度(这个值就是类加载阶段为操作数栈分配的深度)
- Locals:局部变量的分配空间(单位是slot,不是个数),对于double和long这两个64bit的,需要两个slot,对于其他<=32bit的,只需要一个slot
- Args_size:方法参数的个数,包括方法参数、this(this只针对实例方法,static方法不会自动添加this)
- inc()方法:我详细注释了该方法的执行过程,这也就是JVM执行一个方法的基本流程(基于栈)
提醒:
- Code部分是我们主要关注的部分,这一部分中关键的部分就是每一条字节码指令的意义是什么。具体的可以查看《深入分析Java Web技术内幕(修订版)》P124-P135
总结:
- 掌握类文件结构,有利于我们理解类加载机制,而了解了类加载机制,最直接的好处,就是我们可以自己编写类加载工具,例如,smarty框架就是自己编写了一个类加载器
- 读懂执行javap之后的字节码指令有利于我们理解java代码的执行流程,对我们定位问题也有一定的好处(虽然我在开发中还没有用这种方式定位过问题)
第四章 类加载机制
1、类加载流程
- 把描述类的数据从xxx.class文件加载到JVM内存
- 对这些数据进行校验、准备、解析(这三个过程总称为"链接")
- 对这些数据进行初始化,最终形成可被JVM直接使用的Class对象
注意:
- 类加载过程是在运行期完成的
2、加载
- 作用:把描述类的数据从xxx.class文件加载到JVM内存
- 此阶段完成三件事
- 通过一个类的全限定类名来获取定义此类的二进制字节流
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在方法区生成一个java.lang.Class对象,作为方法区内该类的各种数据的访问入口
- 注意:
- 类加载的完成是靠全限定类名和类加载器(ClassLoaderA实例)完成,这两个元素也是标识一个已被加载类的标识
- 接口、类:名称为"全限定类名+ClassLoader实例ID",这种类型的类由所在的ClassLoader负责加载
- 数组:"[基本类型"或"[L引用类型;"(eg.byte[] bytes = new byte[512];//类名为"[B";Object[] objs = new Object[10];//类名为"[Ljava.lang.Object;")
- 注意基本类型名称都是取自首字母大写(eg.byte:B),有两个例外boolean:Z;long:J
- 数组类由JVM直接创建,其数组元素由类加载器加载
3、验证
- 四部分验证
- 文件格式验证:当通过一个类的全限定类名获取了定义此类的二进制字节流后,检验该字节流是否满足class文件格式(例如:开头是魔数,主次版本号是否是当前虚拟机处理范围之内,即是否在次到主之间的版本,高于主的版本不加载(这就是低版本的jdk无法执行高版本jdk的原因),等等),检验过后,执行"加载"部分的第二件事,将数据放入方法区并存储
- 格式不符合:java.lang.VerifyError
- 元数据验证:保证类的元数据信息符合java语言规范(例如:这个类若是普通类,是否实现了其实现接口下的所有类)
- 关于类的元数据有哪些,查看 第二章 Javac编译原理
- 验证方法体的字节码指令,确定指令顺序符合逻辑
- 符号引用验证:
- 发生在解析阶段:将符号引用转化为直接引用的过程
- 对符号引用的验证,保证这些符号引用(属性、方法等)存在,并且具备相应的权限(eg.保证private的方法不可被其他类访问)
- NoSuchMethodError、NoSuchFieldError、IllegalAccessError
- 文件格式验证:当通过一个类的全限定类名获取了定义此类的二进制字节流后,检验该字节流是否满足class文件格式(例如:开头是魔数,主次版本号是否是当前虚拟机处理范围之内,即是否在次到主之间的版本,高于主的版本不加载(这就是低版本的jdk无法执行高版本jdk的原因),等等),检验过后,执行"加载"部分的第二件事,将数据放入方法区并存储
- 注意:
- 验证阶段可能会穿插在类加载的其他阶段
- -Xverify:none:关闭大部分的验证操作,这个我们一般不会配置这个参数(即我们一般还是会去做验证的),因为类加载虽然发生运行期,但是大部分的类加载行为是在服务器启动的时候就发生了,实际上不影响我们的程序运行。当然,如果我们手动调用了Class.forName(),this.getClass.getClassLoader().loadClass(),这样就会执行到这句代码的时候加载类,但毕竟是少数。通常我们会使用Class.forName()来引入MySQL驱动,这也就是在maven中引入MySQL驱动包的时候,其scope是runtime的原因。
4、准备
- 作用:为类变量分配内存(这些内存在方法区分配)、设置类变量零值
- 注意:
- 为类变量分配内存(为static对象分配内存,这也就是static变量存储在方法区的原理)
- 类中的实例变量会随着对象实例的创建一起分配在堆中,当然若是基本数据类型的话,会随着对象的创建直接压入操作数栈
- 为static变量分配零值(默认零值)(eg.static int x = 123;//这时候x = 0,而x = 123是在"初始化"阶段发生的)
- 为final变量分配初始值(期望值)(eg.final int y = 456;//这时候y = 456)
5、解析
- 作用:符号引用转化为直接引用
- 符号引用(编译期):存储于class文件的常量池中(见 第三章 类文件结构与javap的使用),只有一些名称,没有实际的地址
- 直接引用(运行期):在该阶段,会为符号引用分配实际的内存,之后符号引用就转化为了直接引用,存储于运行时常量池
- 常量池:class文件中的概念
- 运行时常量池:JVM内存结构中方法区内的一个组成部分
- 注意
- 该步骤在"初始化"阶段之前不一定发生,但是一定要在一个符号引用被使用前解析。
6、初始化
- 作用:执行静态块(static{})、初始化(按意愿)static变量(eg.static int x = 123;//"准备"阶段后,x = 0;"初始化"后,x = 123)、执行构造器
- 发生的时机:
- new:执行构造器
- 子类调用了初始化,若父类没有初始化,则父类先要初始化(eg.子类调用了"new 无参构造器",则先要执行父类的"无参构造器")
- 反射调用了类,若类没有初始化,需要先初始化
- 虚拟机启动时,包含main()方法的类要初始化
- 注意:static{}与static变量初始化的发生不一定会发生在服务器启动时(即不一定发生在类加载时),若想要达到容器启动后,就执行一段代码xxx,可以将类实现spring的InitalizingBean,重写该接口下的afterPropertiesSet()方法,将xxx代码写入该方法中。
总结:
- 类加载流程
- "加载"第一阶段:通过一个类的全限定类名来获取定义此类的二进制字节流
- "验证"第一阶段:文件格式验证
- "加载"第二阶段:将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- "加载"第三阶段:在方法区生成一个java.lang.Class对象,作为方法区内该类的各种数据的访问入口
- "验证"第二阶段:元数据验证
- "验证"第三阶段:验证方法体的字节码指令
- "准备"第一阶段:类变量分配内存
- "准备"第二阶段:设置类变量零值
- "验证"第四阶段:符号引用验证(追随于"解析",仅发生在"解析"的时候)
- "解析":符号引用转化为直接引用(不是必须要在"初始化"之前的步骤的步骤)
- "初始化":不一定发生在何时,但是一定要在"加载"、"验证"、"准备"之后
- 关于验证部分,我们可能会怀疑既然javac在"语法分析"和"语义分析"部分已经做了大量的验证,类加载的时候为什么还要进行验证?
- javac并没有做在类加载部分的所有验证,例如:魔数验证
- 不是所有的class文件都是由javac产生的,还有第三方的jar,甚至是自己伪造的class
- 以上步骤,从"验证"第二阶段开始到"初始化"之前,都是在方法区进行,这个地方也是类加载的主要场所。
第五章 类加载器ClassLoader源码解析
1、ClassLoader作用
- 类加载流程的"加载"阶段是由类加载器完成的。
2、类加载器结构
结构:BootstrapClassLoader(祖父)-->ExtClassLoader(爷爷)-->AppClassLoader(也称为SystemClassLoader)(爸爸)-->自定义类加载器(儿子)
关系:看括号中的排位;彼此相邻的两个为父子关系,前为父,后为子
2.1、BootstrapClassLoader
- 下边简称为boot
- C++编写
- 为ExtClassLoader的父类,但是通过ExtClassLoader的getParent()获取到的是null(在类加载器部分:null就是指boot)
- 主要加载:E:\Java\jdk1.6\jre\lib\*.jar(最重要的就是:rt.jar)
2.2、ExtClassLoader:
- 下边简称为ext
- java编写,位于sun.misc包下,该包在你导入源代码的时候是没有的,需要重新去下
- 主要加载:E:\Java\jdk1.6\jre\lib\ext\*.jar(eg.dnsns.jar)
2.3、AppClassLoader:
- 下边简称为app
- java编写,位于sun.misc包下
- 主要加载:类路径下的jar
2.4、自定义类加载器:
- 下边简称为custom
- 自己编写的类加载器,需要继承ClassLoader类或URLClassLoader,并至少重写其中的findClass(String name)方法,若想打破双亲委托机制,需要重写loadClass方法
- 主要加载:自己指定路径的class文件
3、全盘负责机制
概念:假设ClassLoaderA要加载class B,但是B引用了class C,那么ClassLoaderA先要加载C,再加载B,"全盘"的意思就是,加载B的类加载器A,也会加载B所引用的类
4、双亲委托机制
这也是类加载器加载一个类的整个过程。
过程:假设我现在从类路径下加载一个类A,
1)那么app会先查找是否加载过A,若有,直接返回;
2)若没有,去ext检查是否加载过A,若有,直接返回;
3)若没有,去boot检查是否加载过A,若有,直接返回;
4)若没有,那就boot加载,若在E:\Java\jdk1.6\jre\lib\*.jar下找到了指定名称的类,则加载,结束;
5)若没找到,boot加载失败;
6)ext开始加载,若在E:\Java\jdk1.6\jre\lib\ext\*.jar下找到了指定名称的类,则加载,结束;
7)若没找到,ext加载失败;
8)app加载,若在类路径下找到了指定名称的类,则加载,结束;
9)若没有找到,抛出异常ClassNotFoundException
注意:
- 在上述过程中的1)2)3)4)6)8)后边,都要去判断是否需要进行"解析"过程 ("解析"见 第四章 类加载机制)
- 类的加载过程只有向上的双亲委托,没有向下的查询和加载,假设是ext在E:\Java\jdk1.6\jre\lib\ext\*.jar下加载一个类,那么整个查询与加载的过程与app无关。
- 假设A加载成功了,那么该类就会缓存在当前的类加载器实例对象C中,key是(A,C)(其中A是类的全类名,C是加载A的类加载器对象实例),value是对应的java.lang.Class对象
- 上述的1)2)3)都是从相应的类加载器实例对象的缓存中进行查找
- 进行缓存的目的是为了同一个类不被加载两次
- 使用(A,C)做key是为了隔离类,假设现在有一个类加载器B也加载了A,key为(A,B),则这两个A是不同的A。这种情况怎么发生呢?
- 假设有custom1、custom2两个自定义类加载器,他们是兄弟关系,同时加载A,这就是有可能的了
总结:
- 从底向上检查是否加载过指定名称的类;从顶向下加载该类。(在其中任何一个步骤成功之后,都会中止类加载过程)
- 双亲委托的好处:假设自己编写了一个java.lang.Object类,编译后置于类路径下,此时在系统中就有两个Object类,一个是rt.jar的,一个是类路径下的,在类加载的过程中,当要按照全类名去加载Object类时,根据双亲委托,boot会加载rt.jar下的Object类,这是方法结束,即类路径下的Object类就没有加载了。这样保证了系统中类不混乱。
5、源代码
/**
2 * 根据指定的binary name加载class。
3 * 步驟:
4 * 假设我现在从类路径下加载一个类A,
5 * 1)那么app会先查找是否加载过A(findLoadedClass(name)),若有,直接返回;
6 * 2)若没有,去ext检查是否加载过A(parent.loadClass(name, false)),若有,直接返回;
7 * findBootstrapClassOrNull(name) 3)4)5)都是这个方法
8 * 3)若没有,去boot检查是否加载过A,若有,直接返回;
9 * 4)若没有,那就boot加载,若在E:\Java\jdk1.6\jre\lib\*.jar下找到了指定名称的类,则加载,结束;
10 * 5)若没找到,boot加载失败;
11 * findClass(name) 6)7)8)9)都是这个方法
12 * 在findClass中调用了defineClass方法,该方法会生成当前类的java.lang.Class对象
13 * 6)ext开始加载,若在E:\Java\jdk1.6\jre\lib\ext\*.jar下找到了指定名称的类,则加载,结束;
14 * 7)若没找到,ext加载失败;
15 * 8)app加载,若在类路径下找到了指定名称的类,则加载,结束;
16 * 9)若没有找到,抛出异常ClassNotFoundException
17 * 注意:在上述过程中的1)2)3)4)6)8)后边,都要去判断是否需要进行"解析"过程
18 */
19 protected synchronized Class<?> loadClass(String name, boolean resolve)
20 throws ClassNotFoundException {
21 Class c = findLoadedClass(name);//检查要加载的类是不是已经被加载了
22 if (c == null) {//没有被加载过
23 try {
24 if (parent != null) {
25 //如果父加载器不是boot,递归调用loadClass(name, false)
26 c = parent.loadClass(name, false);
27 } else {//父加载器是boot
28 /*
29 * 返回一个由boot加载过的类;3)
30 * 若没有,就去试着在E:\Java\jdk1.6\jre\lib\*.jar下查找 4)
31 * 若在bootstrap class loader的查找范围内没有查找到该类,则返回null 5)
32 */
33 c = findBootstrapClassOrNull(name);
34 }
35 } catch (ClassNotFoundException e) {
36 //父类加载器无法完成加载请求
37 }
38 if (c == null) {
39 //如果父类加载器未找到,再调用本身(这个本身包括ext和app)的findClass(name)来查找类
40 c = findClass(name);
41 }
42 }
43 if (resolve) {
44 resolveClass(c);
45 }
46 return c;
47 }
说明:
- 该段代码中引用的大部分方法实质上都是native方法
- 其中findClass方法的类定义如下:
/** * 查找指定binary name的类 * 该类应该被ClassLoader的实现类重写 */ protected Class<?> findClass(String name) throws ClassNotFoundException { throw new ClassNotFoundException(name); } - 关于findClass可以查看URLClassLoader.findClass(final String name),其中引用了defineClass方法,在该方法中将二进制字节流转换为了java.lang.Class对象。
采用模板模式,我们实现自定义类加载器:
public class UserDefineClassLoader extends ClassLoader {
/**
* 自定义加载器的名称
*/
private String loaderName;
/**
* 指定自定义加载器的名称
*/
public UserDefineClassLoader(String loaderName) {
// 父类加载器 this(checkCreateClassLoader(), getSystemClassLoader())
super();
this.loaderName = loaderName;
}
/**
* 指定父类加载器
*/
public UserDefineClassLoader(String loaderName, ClassLoader parent) {
super(parent);
this.loaderName = loaderName;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 1. 读取文件内容为byte[]
byte[] classBytes = readClassDataFromFile("/Users/jigangzhao/Desktop/A.class");
// 2. 将byte[]转化为Class
Class<?> aClass = defineClass("classLoader.A", classBytes, 0, classBytes.length);
return aClass;
}
}
附:关于递归
递归基于栈实现。
上述的代码如果不清楚递归的意义是看不清的。
解释:
- app_loadClass()方法执行到ext_loadClass(),这时候对于app_loadClass()中剩余的findClass()会在栈中向下压;
- 然后执行ext_loadClass(),当执行到findBootstrapClassOrNull(name),这时候ext_loadClass()中剩余的findClass()也会从栈顶向下压,此时ext_loadClass()_findClass()仅仅位于app_loadClass()_findClass()的上方;
- 然后执行findBootstrapClassOrNull(name),当boot检测过后并且执行完加载后并且没成功,boot方法离开栈顶;
- 然后执行此时栈顶的ext_loadClass()_findClass()
- 然后执行此时栈顶的app_loadClass()_findClass()
这样,就完成了双亲委托机制。
注意点:
类隔离机制
- 同一个类Dog可以加载两次(只要loader1和loader3不是父子关系即可,加载出的 Class 对象不同),不同运行空间内的类不能互相访问(eg. loader1和loader3不是父子关系,则Loader1加载的Dog不能访问lodaer3加载的Sample)
- 父类加载器无法访问到子类加载器加载的类,除非使用反射。Eg. Loader1 的父加载器是 系统类加载器,假设 Sample 类由 loader1 加载, 使用 loader1 的类 Test 是由系统类加载器加载的,例如下面这段代码属于 Test 类,那么如果直接使用注释部分的代码(即通过常规的方式使用 Sample 是不行的),必须通过反射。
第六章 字节码执行方式--解释执行和JIT
1、两种执行方式:
- 解释执行(运行期解释字节码并执行)
- 强制使用该模式:-Xint
- 编译为机器码执行(将字节码编译为机器码并执行,这个编译过程发生在运行期,称为JIT编译)
- 强制使用该模式:-Xcomp,下面是两种编译模式
- client(即C1):只做少量性能开销比高的优化,占用内存少,适用于桌面程序。
- server(即C2):进行了大量优化,占用内存多,适用于服务端程序。会收集大量的运行时信息。
注意:
- 32为机器默认选择C1,可在启动时添加-client或-server来指定,64位机器若CPU>2且物理内存>2G则默认为C2,否则为C1
- Hotspot JVM执行代码的机制:对在执行过程中执行频率高的代码进行编译,对执行频率不高的代码继续解释执行
查看当前机器默认是client模式还是server模式,使用:"java -version"命令,如下

其中,mixed mode表示"解释执行+编译执行"的混合模式
2、解释执行
查看 第三章 类文件结构与javap的使用 中的inc()方法的执行
或者查看《深入了解java虚拟机(第二版)》P272-P275
3、编译执行
- 编译的对象
- 方法
- 方法中的循环体
- OSR编译:编译整段代码,但是只有循环体部分会执行机器码,其他部分还是解释执行
- 触发条件(执行频率大于多少)
- 方法调用计数器:方法被调用的次数
- client:1500 server:10000
- 该阈值可通过-XX:CompileThreshold来指定
- 这里"方法调用的次数"是指一段时间(半衰周期)内的调用次数,如果半衰周期内,该次数没有达到阈值,则该次数减半。
- -XX:-UseCounterDecay 关闭上述机制,即半衰周期的无穷大
- -XX:CounterHalfLifeTime 半衰周期
- 回边计数器:循环体内循环代码的执行次数(即for中代码的循环的次数)
- client:13995 server:10700
- 该阈值可通过-XX:OnStackReplacePercent(注意该OSRP只是一个计算回边计数阈值的中间值),回边计数阈值
- client:CompileThreshold*OSRP/100
- server:CompileThreshold*(OSRP-InterPreterProfilePercentage)/100
- -XX:OnStackReplacePercent:140 InterPreterProfilePercentage:33
- 方法调用计数器:方法被调用的次数
- 方法编译执行
- 解释器调用方法时,检查是否有已经存在的编译版本,如果有,执行机器码,如果没有,方法调用计数器+1,然后判断方法调用计数器是否超过阈值,若超过,进行编译,后台线程进行编译,前台线程继续解释执行(即不会阻塞),直到下一次调用方法时,如果编译好了,就直接执行机器码,如果没编译好,就解释执行。
- 循环体编译执行
- 解释器执行到循环体时,检查是否有已经存在的编译版本,如果有,执行机器码,如果没有,回边计数器+1,然后判断回边计数器是否超过阈值,若超过,进行编译,后台线程进行编译,前台线程继续解释执行(即不会阻塞),直到下一次执行到循环体时,如果编译好了,就直接执行机器码,如果没编译好,就解释执行。
4、C1优化
说明:关于全部的优化技术列表,查看《深入理解java虚拟机(第二版)》P346-P347
只做少量性能开销比高的优化,占用内存少,主要的优化包括:
- 方法内联
- 冗余消除
- 复写传播
- 消除无用代码
- 类型继承关系分析(CHA,辅助)
- 去虚拟化
4.1、方法内联、冗余消除、复写传播、消除无用代码
4.1.1、方法内联
方法内联含义:假设方法A调用了方法B,把B的指令直接植入到A中。
static class B{
int value;
final int get() {
return value;
}
}
public void foo() {
y = b.get();
//do something
z = b.get();
sum = y + z;
}
说明:在上述代码中,b是B的一个实例。
方法内联之后,
public void foo() {
y = b.value;
//do something
z = b.value;
sum = y + z;
}
方法内联的条件:
- get()编译后的字节数<=35byte(默认) -XX:MaxInlineSize=35指定
方法内联的地位:
- 优化系列中最一开始使用的方式(因为是很多其他优化手段的基础)
- 消除方法调用的成本(建立栈帧、避免参数传递、避免返回值传递、避免跳转)
4.1.2、冗余消除
冗余消除:如上边的两个b.value冗余(前提,在do something部分没有对b.value进行操作,这也是我们在做优化之前需要先收集数据的原因)
假设在do something部分没有对b.value进行操作,进行冗余消除后,
public void foo() {
y = b.value;
//do something
z = y;
sum = y + z;
}
4.1.3、复写传播
当然,在冗余消除后,JIT对上述的代码进行分析,发现变量z没用(可以完全用y来代替),进行"复写传播"之后,
public void foo() {
y = b.value;
//do something
y = y;
sum = y + y;
}
4.1.4、无用代码消除
在"复写传播"后,发现"y=y"是无用代码,所以可以进行"无用代码的消除"操作,消除之后,
public void foo() {
y = b.value;
//do something
sum = y + y;
}
需要说明的是,这里的"无用代码的消除"是在前三部优化的基础上来做的,而javac编译中"语义分析"部分的"无用代码的消除"是直接消除一些直接写好的代码(例如:if(false){})
4.2、类型继承关系分析、去虚拟化
public interface Animal {
public void eat();
}
public class Cat implements Animal{
public void eat() {
System.out.println("cat eat fish");
}
}
public class Test{
public void methodA(Animal animal){
animal.eat();
}
}
首先分析Animal的整个"类型继承关系",发现只有一个实现类Cat,那么在methodA(Animal animal)的代码就可以优化为如下,
public void methodA(Animal animal){
System.out.println("cat eat fish");
}
但是,如果之后在运行过程中,"类型继承关系"发现Animal又多了一个实现类Dog,那么此时就不在执行之前优化编译好的机器码了,而是进行解释执行,即如下的"逆优化"。
逆优化:
当编译后的机器码的执行不再符合优化条件,则该机器码对应的部分回到解释执行。
eg.比如"去虚拟化",如果编译之后,发现类的实现方法多于一种了,此时就要执行"逆优化"
5、C2优化
进行了大量优化,占用内存多,适用于服务端程序,对于C2优化,除了具有C1的优化措施后,还有很多优化。
逃逸分析(辅助):
开启:-XX:+DoEscapeAnalysis
根据运行状况来判断方法中的变量是否会被方法或外部线程所读取,若不会,此变量是不逃逸的。基于此,C2在编译时会做:
- 标量替换:开启 -XX:+EliminateAllocations
- 栈上分配
- 同步削除:开启 -XX:+EliminateLocks
5.1、标量替换
含义:将一个java对象打散,根据程序,将该对象中的属性作为一个个标量来使用。
Point point = new Point(1,2);
System.out.println("point.x:" + point.x + ",point.y:" + point.y);
//do after
若在//do after中(即前边两句代码之后的所有代码中)再没有其他代码访问"point对象"了,则将"point对象"打散并进行标量替换,
int x = 1;
int y = 2;
System.out.println("point.x:" + x + ",point.y:" + y);
好处:
- 如果对象中定义的所有变量有的并没有被用到,"标量替换"可以节省内存
- 执行时,不需要寻找对象引用,速度会快
5.2、栈上分配
含义:确定一个方法的变量不会逃逸出当前方法之外(即该变量不会被其他方法引用),则该变量可以直接分配在栈上,随方法执行结束,栈帧消失,该变量也消失,减轻GC压力。
好处:
- 执行时,不需要根据对象引用去堆中找对象,速度会快
- 分配在栈上,随方法执行结束,栈帧消失,该变量也消失,减轻GC压力。
- 使用栈上分配,必须开启标量替换
5.3、同步削除
含义:确定一个方法的变量不会逃逸出当前线程之外(即该变量不会被其他线程使用),则对于该变量的同步策略就消除掉,如下,
synchronized(cat){
//do xxx
}
若cat不会逃逸出当前线程,则同步块可以去掉,如下,
//do xxx
总结:
解释器:
- 程序启动速度比编译快
- 节省内存(不需要编译,所以不需要放置编译后的机器码)
JIT编译器:
- 时间长了,对于"热点代码"的执行会快
注意:
- 使用JIT而不是使用在编译期直接编译成机器码,除了解释器部分的两条有点外,还为了在运行期收集数据,有目的的进行编译

 浙公网安备 33010602011771号
浙公网安备 33010602011771号