定时任务实现方式
实现定时任务有5种方式:
- 使用线程创建定时任务
- 使用
TimerTask创建定时任务 - 使用线程池创建定时任务
- 使用
Quartz框架实现定时任务 - 使用
@Scheduled注解实现定时任务 xxl-job实现分布式定时任务
一、使用线程创建定时任务
public class ThreadTask {
public static class Demo01 {
static long count = 0;
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(1000);
count++;
System.out.println(count);
} catch (Exception e) {
// TODO: handle exception
}
}
}
};
Thread thread = new Thread(runnable);
thread.start();
}
}
}
二、使用TimerTask创建定时任务
public class Timer4Task {
static long count = 0;
public static void main(String[] args) {
TimerTask timer4Task = new TimerTask() {
@Override
public void run() {
count++;
System.out.println(count);
}
};
//创建timer对象设置间隔时间
Timer timer = new Timer();
// 间隔天数
long delay = 0;
// 间隔毫秒数
long period = 1000;
timer.scheduleAtFixedRate(timer4Task, delay, period);
}
}
三、使用线程池创建定时任务
public class ThreadPoolTask {
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
// task to run goes here
System.out.println("Hello !!");
}
};
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor();
// 第二个参数为首次执行的延时时间,第三个参数为定时执行的间隔时间
service.scheduleAtFixedRate(runnable, 1, 1, TimeUnit.SECONDS);
}
}
四、使用Quartz框架实现定时任务
public class QuartzTask {
public static void main(String[] args) throws SchedulerException {
//1.创建Scheduler的工厂
SchedulerFactory sf = new StdSchedulerFactory();
//2.从工厂中获取调度器实例
Scheduler scheduler = sf.getScheduler();
//3.创建JobDetail,
JobDetail jb = JobBuilder.newJob(SelfJob.class)
//job的描述
.withDescription("this is a ram job")
//job 的name和group
.withIdentity("ramJob", "ramGroup")
.build();
//任务运行的时间,SimpleSchedle类型触发器有效,3秒后启动任务
long time = System.currentTimeMillis() + 3 * 1000L;
Date statTime = new Date(time);
//4.创建Trigger
//使用SimpleScheduleBuilder或者CronScheduleBuilder
Trigger t = TriggerBuilder.newTrigger()
.withDescription("")
.withIdentity("ramTrigger", "ramTriggerGroup")
//.withSchedule(SimpleScheduleBuilder.simpleSchedule())
//默认当前时间启动
.startAt(statTime)
//两秒执行一次,Quartz表达式,支持各种牛逼表达式
.withSchedule(CronScheduleBuilder.cronSchedule("0/5 * * * * ?"))
.build();
//5.注册任务和定时器
scheduler.scheduleJob(jb, t);
//6.启动 调度器
scheduler.start();
}
}
————————————————
/**
* 继承Quartz框架中的Job,并重写execute方法
*/
public class SelfJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println("quartz Job date:" + System.currentTimeMillis());
}
}
五、使用 @Scheduled 注解实现定时任务
@Configuration // 这里使用@Component也行
public class ScheduleTask {
//添加定时任务-- 50分钟执行一次
@Scheduled(fixedRate = 50 * 60 * 1000)
private void updateTask() {
Console.log("@Scheduled 注解实现定时任务 执行-------------------");
}
}
启动类增加 @EnableScheduling 注解,启动服务。
六、使用 xxl-job 实现分布式定时任务
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.2.0</version>
</dependency>
————————————————
xxl:
job:
accessToken:
executor:
appname: demo
ip:
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: -1
port: 9966
admin:
# addresses: http://127.0.0.1:8089/xxl-job-admin
addresses: http://49.234.28.149:8086/xxl-job-admin
————————————————
@Component
@Slf4j
@RequiredArgsConstructor
public class XxlJobHandler{
@XxlJob("demoHandler")
public ReturnT<Object> run (Object s) throws Exception {
XxlJobLogger.log("xxl-job测试任务开始执行。【args: {}】", s);
try {
System.out.println("执行一次xxl-job打印任务!");
XxlJobLogger.log("xxl-job测试任务执行结束。");
return null;
} catch (Exception e) {
XxlJobLogger.log("xxl-job测试任务执行出错!", e);
return null;
}
}
}
————————————————
@JobHandler(value="demoHandler")
@Component
public class DemoJobHandler extends IJobHandler {
static int count;
@Override
public ReturnT<String> execute(String param) throws Exception {
System.out.println("执行job任务"+count++);
return SUCCESS;
}
}
————————————————
6.4 下载并启动 xxl-job
下载地址:https://github.com/xuxueli/xxl-job/
找到 xxl-job-admin 模块,初始化数据库并配置数据库资源、端口等,最后启动服务。
启动后在浏览器输入: http://localhost:8061/xxl-job-admin ,进入 xxl-job 管理后台:
添加好执行器,再新建一个任务:
启动服务后会每5秒执行一次,可以根据需求自定义执行时间和周期。
————————————————
多机部署之定时任务完整方案
1.场景描述
老项目需要多机部署,项目中有几十个定时任务,一旦多机部署,定时任务就会重复执行,固定ip与错开时间方案都存在较大弊端,最终采用的方案是:AOP+排他锁的方式,软件老王已验证通过,介绍下,有需要的朋友可以参考下。
2.解决方案
软件老王基本方案是采用:AOP+排他锁的方式。
(1)目前老项目有几十个定时任务,采用AOP的方式,可以保证代码的无侵入(即使简单的微侵入,例如增加几行代码,测试验证的工作量也会比较大的)。
(2)采用排他锁的方式,保证批处理的高可用,不重复执行。
2.1 AOP编程
Aop的概念就不说了,就是面向切面编程,通俗点就是统一处理一类问题,比如日志、请求鉴权等,刚开始不确定是否可行,系统中的批处理是使用spring注解的方式@Scheduled进行批处理,采用aop对注解@Scheduled进行编程,统一拦截批处理,代码如下:
/**
* 软件老王-AOP处理类
*/
@Aspect
@Component
public class ScheduledAspect {
@Autowired
ScheduleService scheduleService ;
@Pointcut( "@annotation(org.springframework.scheduling.annotation.Scheduled)")
public void scheduled() {
}
@Around("scheduled()")
public Object scheduled(ProceedingJoinPoint pjd) {
Object result = null;
String taskName = pjd.getSignature().getName();
try {
if (scheduleService.isInvoke(taskName)){
return result;
}
result = pjd.proceed();
scheduleService.end(taskName);
} catch (Throwable e) {
throw new RuntimeException(e);
}
return result;
}
}
说明:
(1)面向标签编程
@Pointcut( "@annotation(org.springframework.scheduling.annotation.Scheduled)")
这样注解会拦截标签@Scheduled。
(2)使用aop的环绕标签 @Around("scheduled()")
@before标签拿不到执行完成状态,需要使用环绕标签@@Around,在标签中可以拿到执行完成后状态,以便放开锁。
result = pjd.proceed();
(3)结合排他锁使用
@Autowired
ScheduleService scheduleService ;
2.2 排他锁
排他锁,简单来说就是通过数据库总的标志位+版版号进行的控制.
软件老王的代码如下,:
/**
* 软件老王-排他锁服务类
*/
@Service
public class ScheduleService {
@Autowired
ScheduleClusterMapper scheduleClusterMapper;
public boolean isInvoke(String taskName) {
boolean isValid = false;
try {
ScheduleCluster carIndexEntity = scheduleClusterMapper.selectByTaskName(taskName);
int execute = carIndexEntity.getExecute();
String ip = InetAddress.getLocalHost().getHostAddress();
long currentTimeMillis = System.currentTimeMillis();
long time = carIndexEntity.getUpdatedate().getTime();
if (execute == 0) {
isValid = start(taskName, carIndexEntity.getVersion(), ip);
}
} catch (UnknownHostException e) {
e.printStackTrace();
}
return isValid;
}
//执行锁机制,软件老王
public boolean start(String taskName, int version, String ip) {
ScheduleCluster scheduleCluster = new ScheduleCluster();
scheduleCluster.setVersion(version);
scheduleCluster.setExecuteIp(ip);
scheduleCluster.setUpdatedate(DateUtil.getCurrentTime());
scheduleCluster.setTaskName(taskName);
scheduleCluster.setExecute(1);
int count = scheduleClusterMapper.updateByTaskName(scheduleCluster);
if (count > 0) {
return true;
}
return false;
}
//执行解锁机制,软件老王
public void end(String taskName) {
ScheduleCluster scheduleCluster = new ScheduleCluster();
scheduleCluster.setUpdatedate(DateUtil.getCurrentTime());
scheduleCluster.setTaskName(taskName);
scheduleCluster.setExecute(0);
scheduleClusterMapper.updateNormalByTaskName(scheduleCluster);
}
}
说明:
大的原理是在where条件后带上版本号,在update中更新version+1,这样通过影响数据库的影响条数,来判断是否拿到锁。
(1)主类中调用start方法,该方法是更新批处理状态,软件老王这里设置了一个小点,在updateByTaskName的mybatis方法中,有个version+1的更新;
(2)end方法放在更新完成后,释放锁。
(3)其实还有一个点,可以考虑下,需要有个机制,比如出现异常情况,刚好批处理执行中,重启服务了等,下次批处理执行前,假如锁还未释放,代码中增加释放锁的机制。
2.3 数据库相关
(1)数据库表设计
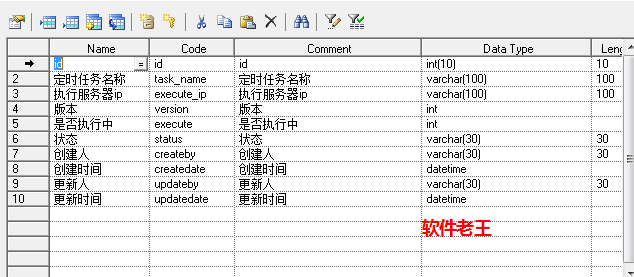
(2)mybatis相关方法
(1)第一个是start对应方法,执行锁和version增加。
<update id="updateByTaskName" parameterType="com.yutong.dmp.entity.ScheduleCluster">
update t_schedule_cluster
<set>
<if test="executeIp != null">
execute_ip = #{executeIp,jdbcType=VARCHAR},
</if>
<if test="version != null">
version = #{version,jdbcType=INTEGER} + 1,
</if>
<if test="execute != null">
execute = #{execute,jdbcType=INTEGER},
</if>
<if test="status != null">
status = #{status,jdbcType=VARCHAR},
</if>
<if test="createby != null">
createby = #{createby,jdbcType=VARCHAR},
</if>
<if test="createdate != null">
createdate = #{createdate,jdbcType=TIMESTAMP},
</if>
<if test="updateby != null">
updateby = #{updateby,jdbcType=VARCHAR},
</if>
<if test="updatedate != null">
updatedate = #{updatedate,jdbcType=TIMESTAMP},
</if>
</set>
where task_name = #{taskName,jdbcType=VARCHAR}
and version = #{version,jdbcType=INTEGER}
and status ='1'
</update>
(2)第二个是释放锁,更改excute为0。
<update id="updateNormalByTaskName" parameterType="com.yutong.dmp.entity.ScheduleCluster">
update t_schedule_cluster
<set>
<if test="executeIp != null">
execute_ip = #{executeIp,jdbcType=VARCHAR},
</if>
<if test="version != null">
version = #{version,jdbcType=INTEGER},
</if>
<if test="execute != null">
execute = #{execute,jdbcType=INTEGER},
</if>
<if test="status != null">
status = #{status,jdbcType=VARCHAR},
</if>
<if test="createby != null">
createby = #{createby,jdbcType=VARCHAR},
</if>
<if test="createdate != null">
createdate = #{createdate,jdbcType=TIMESTAMP},
</if>
<if test="updateby != null">
updateby = #{updateby,jdbcType=VARCHAR},
</if>
<if test="updatedate != null">
updatedate = #{updatedate,jdbcType=TIMESTAMP},
</if>
</set>
where task_name = #{taskName,jdbcType=VARCHAR}
and status ='1'
</update>
1、Oracle
思路:Insert表内容时,主键重复,无法插入
范围:适用于执行频率低的定时任务
方法:新建一张任务执行表,每次执行定时任务之前先insert该表。
比如:每天执行一次批处理操作。主键可以设置为批处理name+日期(年月日)。集群服务器可能会同时去insert该表,而只有一台服务器能插入成功,则只让这一台服务器执行该批处理任务。
2、Redis
范围:适用于执行频率高的定时任务
有如下两种思路方法:
思路1:采用的是redis中list的push和pop操作。因为Redis是单线程,所有命令依次执行,所以不会出现多台服务器同时访问的情况。
方法:系统初始化时,向Redis中lpush一个list(key,1),作为标识Flag。每台服务器执行批处理之前,先去rpop该list,只有获取到该标识的服务器才能执行批处理任务,执行完毕后再lpush回一个list(key,1)。
比如:执行任务前先执行rpopRedisFlag,任务完成后执行lpushRedisFlag.
public class AutoJobActDis extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext arg0) throws JobExecutionException {
if (rpopRedisFlag("AUTO_JOB_ACTDIS")) {
this.executeJob(this);
lpushRedisFlag("AUTO_JOB_ACTDIS");
}
}
/**
* 从缓存中取得Flag,获取定时任务执行权限
*
* @param redisKey
* @return
*/
public boolean rpopRedisFlag(String redisKey) {
String redisValue = redisService.rpopRedisList(redisKey);
if (StringUtil.isEmpty(redisValue)) {
return false;
} else {
return true;
}
}
/**
* 缓存中增加Flag
*
* @param redisKey
*/
public void lpushRedisFlag(String redisKey) {
redisService.lpushRedisList(redisKey, "1");
}
}
public class RedisService {
/**
* 存储Redis队列,顺序存储
* @param key redis键名
* @param value 键值
*/
public void lpushRedisList(String key, String value) {
Jedis jedis = null;
try {
jedis = jedisClient.getClient();
jedis.lpush(key, value);
} catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {
if (jedis != null) {
jedis.close();
}
}
}
/**
* 移除并获取列表最后一个元素
* @param key
* @return
*/
public String rpopRedisList(String key) {
Jedis jedis = null;
try {
jedis = jedisClient.getClient();
return jedis.rpop(key);
} catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {
if (jedis != null) {
jedis.close();
}
}
return null;
}
}
思路2:采用的是redis中String的incr和expire操作。因为Redis是单线程,所有命令依次执行,所以不会出现多台服务器同时访问的情况。
语法:INCR key 将 key 中储存的数字值增一。
Redis Incr 命令将 key 中储存的数字值增一。
如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。
如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。
本操作的值限制在 64 位(bit)有符号数字表示之内。
EXPIRE key seconds 为给定 key 设置过期时间。
Redis Expire 命令用于设置 key 的过期时间。key 过期后将不再可用。
方法:每台服务器执行批处理之前,先去incr一个固定key,只有返回值等于1的服务器才能执行批处理任务,然后将该key值设置过期时间。
比如:
jedis = jedisTool.getJedis();
if(jedis.incr(PRE_AGAIN_REDIS+batchId)!=1) {
logger.info("其他机器已经重跑");
return ;
} else {
jedis.expire(PRE_AGAIN_REDIS+batchId, 60);//设置60s过期
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号