kafka集群搭建及结合springboot使用
1.场景描述
因kafka以前用的不多,只往topic中写入和读取过数据,这次刚好又要用到,记录下kafka集群搭建及结合springboot使用。
2. 解决方案
2.1 简单介绍
(一)关于kafka,网上的介绍有很多,简单说就是消息中间件,大数据项目中经常使用,我们项目是用于接收日志流水数据。
(二)关于消息中间件,主要有四个:
(1)ActiveMQ:历史悠久,以前项目中使用多,现在更新慢,性能相对不高。
(2)RabbitMQ:可靠性高、安全,模式比较多,java使用比较多,每秒十万级别
(3)Kafka:分布式、高性能、跨语言,性能超高,每秒百万级别,模式简单。
(4)RocketMQ:阿里开源的消息中间件,纯Java实现,有商业版,收费,导致推广一般。
(三)kafka与其他三个相比,优势在于:
(1)性能高,每秒百万级别;
(2)分布式,高可用,水平扩展。
(四) kafka官网图
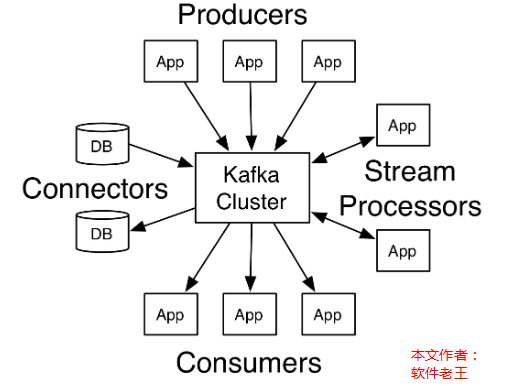
有中文官网,可以详细看看。
地址:http://kafka.apachecn.org/intro.html

2.2 软件下载
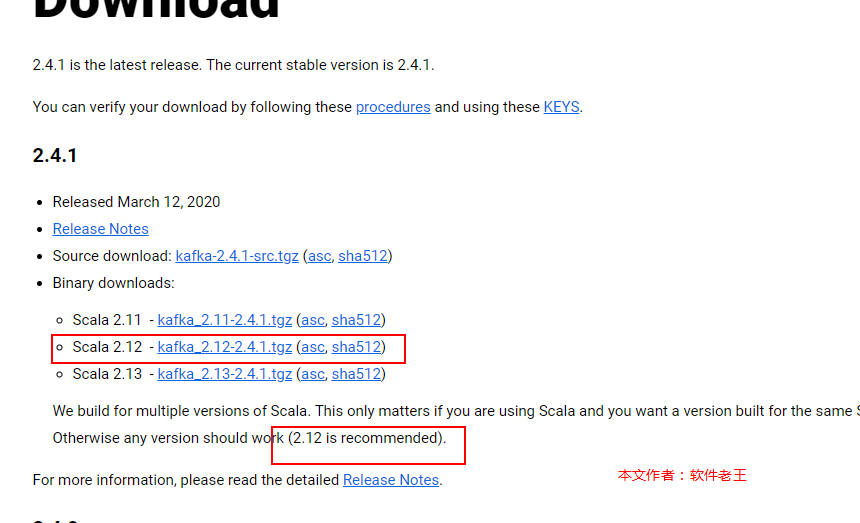
2.2.1 kakfa下载
地址:http://kafka.apache.org/downloads,下载最新的2.4.1。
2.2.2 zookeeper下载
(1)因为kafka要依赖于zookeeper做调度,kafka中实际自带的有kafka,但是一般建议使用独立的zookeeper,方便后续升级及公用。
(2)下载地址:
http://zookeeper.apache.org/,最新的是3.6.0,不过发布不久,建议先跟kafka内置zookeeper保持一致,使用3.5.7版本。

2.2.3 下载说明
文件都不大,zk是9m多,kafka是50多兆

2.3 kafka单机部署及集群部署
说明:软件老王本地弄了三台虚拟机,ip分别为:
192.168.85.158
192.168.85.168
192.168.85.178
2.3.1 单机部署
(1)上传jar包,就不再新建用户了,直接在root账户下执行,将kafka和zookeeper的tar包上传到/root/tools目录下。
(2)解压
[root@ruanjianlaowang158 tools]# tar -zxvf kafka_2.12-2.4.1.tgz
[root@ruanjianlaowang158 tools]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
(3)配置zookeeper及启动
[root@ruanjianlaowang158 apache-zookeeper-3.5.7-bin]# cd /root/tools/apache-zookeeper-3.5.7-bin
#软件老王,首先创建个空文件夹,在接下来的配置文件中配置
[root@ruanjianlaowang158 apache-zookeeper-3.5.7-bin]# mkdir data
[root@ruanjianlaowang158 conf]# cd /root/tools/apache-zookeeper-3.5.7-bin/conf
[root@ruanjianlaowang158 conf]# cp zoo_sample.cfg zoo.cfg
[root@ruanjianlaowang158 conf]# vi zoo.cfg
#单机只改一个值,保存退出。
#dataDir=/tmp/zookeeper
dataDir=/root/tools/apache-zookeeper-3.5.7-bin/data
#启动zookeeper
[root@ruanjianlaowang158 bin]# cd /root/tools/apache-zookeeper-3.5.7-bin/bin
[root@ruanjianlaowang158 bin]# ./zkServer.sh start
(4)配置kafka及启动
[root@ruanjianlaowang158 kafka_2.12-2.4.1]# cd /root/tools/kafka_2.12-2.4.1
#软件老王,新建个空文件夹
[root@ruanjianlaowang158 kafka_2.12-2.4.1]# mkdir data
#软件老王,更改配置文件
[root@ruanjianlaowang158 config]# cd /root/tools/kafka_2.12-2.4.1/config
[root@ruanjianlaowang158 config]# vi server.properties
#需要改3个值
#log.dirs=/tmp/kafka-logs
log.dirs=/root/tools/kafka_2.12-2.4.1/data
#listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.85.158:9092
#zookeeper.connect=localhost:2181
zookeeper.connect=192.168.85.158:2181
#启动kafka
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./zookeeper-server-start.sh ../config/server.properties &
启动完毕,单机验证就不验证了,直接在集群中进行验证。
2.3.2 集群部署
(1)集群方式,首先把上面的单机模式,再在192.168.85.168和192.168.85.178服务器上先解压配置一遍。
(2)zookeeper是还是更改zoo.cfg
158,168,178三台服务器一样:
[root@ruanjianlaowang158 conf]# cd /root/tools/apache-zookeeper-3.5.7-bin/conf
[root@ruanjianlaowang158 conf]# vi zoo.cfg
#其他不变,最后面新加,三行,三台服务器配置一样,软件老王
server.1=192.168.85.158:2888:3888
server.2=192.168.85.168:2888:3888
server.3=192.168.85.178:2888:3888
158服务器执行:
echo "1" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
168服务器执行:
echo "2" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
178服务器执行:
echo "3" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
(3)kafka集群配置
[root@ruanjianlaowang158 config]# cd /root/tools/kafka_2.12-2.4.1/config
[root@ruanjianlaowang158 config]# vi server.properties
#broker.id 三台服务器不一样,158服务器设置为1,168服务器设置为2,178服务器设置为3
broker.id=1
#三个服务器配置一样
zookeeper.connect=192.168.85.158:2181,192.168.85.168:2181,192.168.85.178:2181
Kafka常用Broker配置说明:
| 配置项 | 默认值/示例值 | 说明 |
|---|---|---|
| broker.id | 0 | Broker唯一标识 |
| listeners | PLAINTEXT://192.168.85.158:9092 | 监听信息,PLAINTEXT表示明文传输 |
| log.dirs | /root/tools/apache-zookeeper-3.5.7-bin/data | kafka数据存放地址,可以填写多个。用","间隔 |
| message.max.bytes | message.max.bytes | 单个消息长度限制,单位是字节 |
| num.partitions | 1 | 默认分区数 |
| log.flush.interval.messages | Long.MaxValue | 在数据被写入到硬盘和消费者可用前最大累积的消息的数量 |
| log.flush.interval.ms | Long.MaxValue | 在数据被写入到硬盘前的最大时间 |
| log.flush.scheduler.interval.ms | Long.MaxValue | 检查数据是否要写入到硬盘的时间间隔。 |
| log.retention.hours | 24 | 控制一个log保留时间,单位:小时 |
| zookeeper.connect | 192.168.85.158:2181, 192.168.85.168:2181, 192.168.85.178:2181 |
ZooKeeper服务器地址,多台用","间隔 |
(4)集群启动
启动方式跟单机一样:
#启动zookeeper
[root@ruanjianlaowang158 bin]# cd /root/tools/apache-zookeeper-3.5.7-bin/bin
[root@ruanjianlaowang158 bin]# ./zkServer.sh start
#启动kafka
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./zookeeper-server-start.sh ../config/server.properties &
(5)注意点
集群启动的时候,单机那台服务器(158)可能会报:Kafka:Configured broker.id 2 doesn't match stored broker.id 0 in meta.properties.
方案:在158服务器data中有个文件:meta.properties,文件中的broker.id也需要修改成与server.properties中的broker.id一样,所以造成了这个问题。
(6)创建个topic,后面springboot项目测试使用。
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./kafka-topics.sh --create --zookeeper 192.168.85.158:2181,192.168.85.168:2181,192.168.85.178:2181 --replication-factor 3 --partitions 5 --topic aaaa
2.4 结合springboot项目
2.4.1 pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.itany</groupId>
<artifactId>kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
说明:
主要就两个gav,一个是spring-boot-starter-web,启动web服务使用;一个是spring-kafka,这个是springboot集成额kafka核心包。
2.4.2 application.yml
spring:
kafka:
# 软件老王,kafka集群服务器地址
bootstrap-servers: 192.168.85.158:9092,192.168.85.168:9092,192.168.85.178:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: test
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
2.4.3 producer(消息生产者)
@RestController
public class KafkaProducer {
@Autowired
private KafkaTemplate template;
//软件老王,topic使用上测试创建的aaaa
@RequestMapping("/sendMsg")
public String sendMsg(String topic, String message){
template.send(topic,message);
return "success";
}
}
2.3.4 consumer(消费者)
@Component
public class KafkaConsumer {
//软件老王,这里是监控aaaa这个topic,直接打印到idea中,软件老王
@KafkaListener(topics = {"aaaa"})
public void listen(ConsumerRecord record){
System.out.println(record.topic()+":"+record.value());
}
}
2.4.5 验证结果
(1)浏览器上输入
http://localhost:8080/sendMsg?topic=aaaa&message=bbbb
(2)控制台打印信息
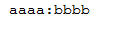
Kafka为什么依赖Zookeeper?
基本概述
ZooKeeper是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务
数据结构
ZooKeeper的数据存储也同样是基于节点,这种节点叫做Znode。每一个Znode里包含了数据、子节点引用、访问权限等.
data即Znode里面的数据
ACL为权限规则,它规定了哪些用户或哪些IP才有权限访问此Znode
stat记录了Znode相关的元数据,比如事务ID、版本号、时间戳、大小
child为当前节点的子节点引用,类似于二叉树的左孩子右孩子
ZooKeeper有个限制,就是每个Znode的数据大小不会超过1M。
节点类型
持久节点:在节点创建后,就一直存在,直到有删除操作来主动清除这个节点——不会因为创建该节点的客户端会话失效而消失。
持久顺序节点:(节点会自动加上编号):额外的特性是,在ZK中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序.
临时节点:临时节点的生命周期会和客户端会话绑定,即如果客户端会话失效(不是连接端口),那么这个节点就会自动被清除掉。另外,在临时节点下面无法创建子节点。
临时顺序节点:此节点是属于临时节点,不过带有顺序,客户端会话结束节点就消失。
集群角色
ZooKeeper集群中有一个leader,多个follower角色,其中leader提供写服务,follower提供读服务。
Leader的选举机制
Leader作为整个ZooKeeper集群的主节点,负责响应所有对ZooKeeper状态变更的请求。
Leader选举:集群初始化阶段,一台服务器server是完成选举的,两台之间能够互相通信,每台机器试图找到一个Leader。由此进入选举机制。
投票基于Sid(服务器id)和ZXid(事务id),优先查找ZXid,以数据最新的作为Leader。如果ZXid一样大,就比较Sid,这里有个过半的概念,大于集群机器数量的一半,即大于或等于(n/2+1)
zookeeper监听机制
当客户端关注的节点发生变化(数据改变、节点删除、子目录节点增加删除),zk会通知客户端,监听机制保证zk保存的任何的数据的任何改变都能快速的响应到监听了该节点的应用程序
总结
Znode系统,存储一些关键数据,类似于unix文件系统
watch监听机制,可以让客户端有能力实时感知zookeeper代为保管的数据的变化,从而进行相应处理。
那么kafka为什么依赖zookeeper呢?
ZooKeeper 作为给分布式系统提供协调服务的工具被 kafka 所依赖。在分布式系统中,消费者需要知道有哪些生产者是可用的,而如果每次消费者都需要和生产者建立连接并测试是否成功连接,那效率也太低了,显然是不可取的。而通过使用 ZooKeeper 协调服务,Kafka 就能将 Producer,Consumer,Broker 等结合在一起,同时借助 ZooKeeper,Kafka 就能够将所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现负载均衡
1.Brork管理
在Kafka的设计中,选择了使用Zookeeper来进行所有Broker的管理,体现在zookeeper上会有一个专门用来进行Broker服务器列表记录的点,节点路径为/brokers/ids
Zookeeper用一个专门节点保存Broker服务列表,也就是 /brokers/ids。
broker启动时,向Zookeeper发送注册请求,Zookeeper会在/brokers/ids下创建这个broker节点,如/brokers/ids/[0...N],并保存broker的IP地址和端口,Broker 创建的是临时节点,在连接断开时节点就会自动删除,所以在 ZooKeeper 上就可以通过 Broker 中节点的变化来得到 Broker 的可用性。
2、负载均衡
broker向Zookeeper进行注册后,生产者根据broker节点来感知broker服务列表变化,这样可以实现动态负载均衡。
3、Topic 信息
在 Kafka 中可以定义很多个 Topic,每个 Topic 又被分为很多个 Partition。一般情况下,每个 Partition 独立在存在一个 Broker 上,所有的这些 Topic 和 Broker 的对应关系都由 ZooKeeper 进行维护。
4、Controller 选举

 浙公网安备 33010602011771号
浙公网安备 33010602011771号