MYSQL 性能优化 EXPLAIN 命令解析
一、Explain 介绍
EXPLAIN 命令是数据库系统中的一个查询优化工具,它提供了有关查询执行计划的详细。这些信息来自于查询优化器,它负责确定最佳的查询执行策略。
二、详细说明
2.1 举例所用表说明
忘记从哪里找的sql了,如果发现源出处,烦请留言,谢谢😁
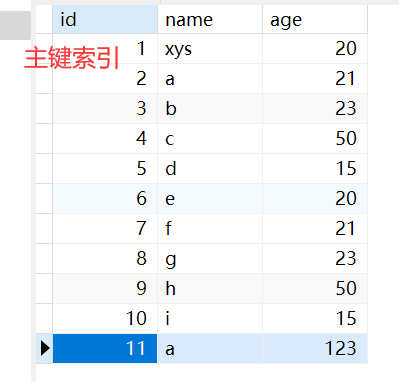
1. user_info表
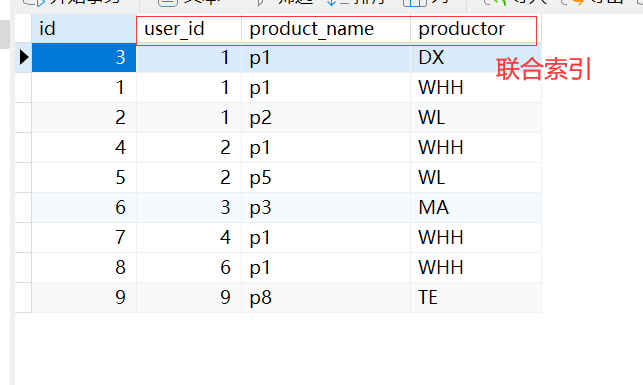
DROP TABLE IF EXISTS `order_info`;
CREATE TABLE `order_info` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` bigint NULL DEFAULT NULL,
`product_name` varchar(50) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL DEFAULT '',
`productor` varchar(30) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `user_product_detail_index`(`user_id` ASC, `product_name` ASC, `productor` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 10 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `order_info` VALUES (3, 1, 'p1', 'DX');
INSERT INTO `order_info` VALUES (1, 1, 'p1', 'WHH');
INSERT INTO `order_info` VALUES (2, 1, 'p2', 'WL');
INSERT INTO `order_info` VALUES (4, 2, 'p1', 'WHH');
INSERT INTO `order_info` VALUES (5, 2, 'p5', 'WL');
INSERT INTO `order_info` VALUES (6, 3, 'p3', 'MA');
INSERT INTO `order_info` VALUES (7, 4, 'p1', 'WHH');
INSERT INTO `order_info` VALUES (8, 6, 'p1', 'WHH');
INSERT INTO `order_info` VALUES (9, 9, 'p8', 'TE');
2. order_info表
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL DEFAULT '',
`age` int NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `name_index`(`name` ASC) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 12 CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `user_info` VALUES (1, 'xys', 20);
INSERT INTO `user_info` VALUES (2, 'a', 21);
INSERT INTO `user_info` VALUES (3, 'b', 23);
INSERT INTO `user_info` VALUES (4, 'c', 50);
INSERT INTO `user_info` VALUES (5, 'd', 15);
INSERT INTO `user_info` VALUES (6, 'e', 20);
INSERT INTO `user_info` VALUES (7, 'f', 21);
INSERT INTO `user_info` VALUES (8, 'g', 23);
INSERT INTO `user_info` VALUES (9, 'h', 50);
INSERT INTO `user_info` VALUES (10, 'i', 15);
INSERT INTO `user_info` VALUES (11, 'a', 123);
2.2 EXPLAIN 命令使用
我们只需要在自己的 sql 命令前添加 EXPLAIN 关键字

2.3 字段介绍
-
id:标识sql语句的一个优先级顺序,id 相同表示这些查询部分是同时执行的。

为什么上面明显IN查询先执行,id确是一样的呢?SQL优化器会进行优化,俩个SQL优化成一条语句进行执行。
-
select_type: 先跳过
-
table: 表示查询表的表名,可能存在临时表的情况

-
partitions:展示命中分区信息,一般会展示NULL,现在公司普遍使用的是分库分表。
-
type: 先跳过
-
possible_keys:可能会用到的索引
-
key:实际使用的索引
-
key_len:索引长度,原则越短越好
-
ref:当使用索引等值查询时,与索引作比较的列或常量
-
rows:估算要找到记录所需要查找的行
-
filtered:存储引擎返回的数据,经过过滤的有效占比(越高越好)
-
Extra:先跳过
三、详细说说跳过的
为什么要跳过?重要,先学简单的,然后再学这3个重要的。
SQL调优 99.5% 参考这三个字段。(数据是我编的)
3.1 select_type
SIMPLE: 简单表,不用表连接或子查询
PRIMARY: 如果查询语句中包含子查询或者其他,最外层部分为PRIMARY
SUBQUERY: 子查询
DERIVED: 在 FROM 中出现的子查询将被标记为 DERIVED。
UNION: 在 UNION 语句中,UNION 之后出现的 SELECT
UNION_RESULT: UNION 查询的结果。
3.2 type
system:表中只有一行记录
const:使用主键索引、唯一索引定位到一条记录
eq_ref:连表查询,前一张表的行在当前表中只有一行与之对应,一般使用主键、唯一索引作为连表条件
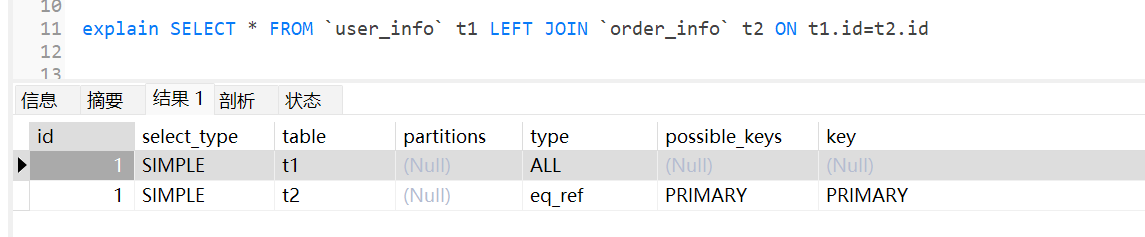
ref:使用普通索引作为查询条件,结果中有多个符合的行
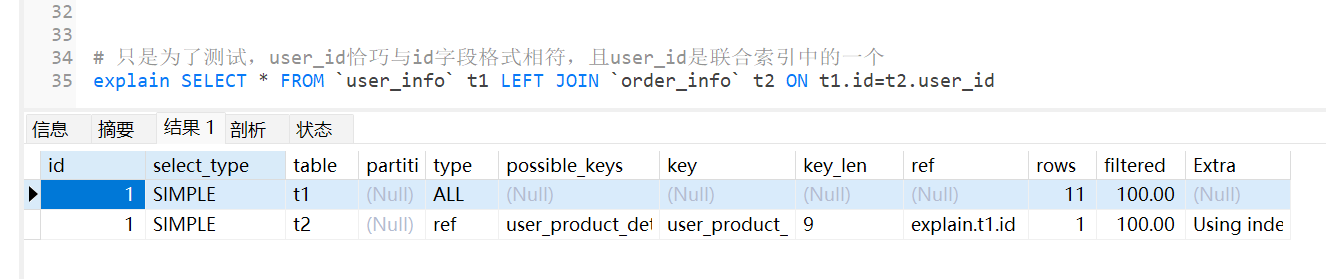
index_merge: 查询条件使用多个索引
range:使用索引进行范围查询
index: 使用索引进行全表查询
这里思考一下最左匹配原则


ALL:全表扫描
3.3 Extra
Using filesort:用了外部排序,没用表内索引排序

id 为主键索引,age 无索引
Using temporary:MySQL 需要创建临时表来存储查询的结果,常见于 ORDER BY 和 GROUP BY。
Using index:表明查询使用了覆盖索引,不用回表,查询效率非常高。
Using index condition:表示查询优化器选择使用了索引条件下推这个特性。
Using where:表明查询使用了 WHERE 子句进行条件过滤。一般在没有使用到索引的时候会出现。
Using join buffer (Block Nested Loop):连表查询的方式,表示当被驱动表的没有使用索引的时候,MySQL 会先将驱动表读出来放到 join buffer 中,再遍历被驱动表与驱动表进行查询。
四、说了这么多,那我们怎么进行SQL编写?或者怎么编写性能好的SQL呢?
上面最重要的也就三列,type、key、Extra,然后顺便看一眼 filtered 字段。
在 type 列中,system>const>eq_ref>ref>index_merge>range>index>ALL
在 Extra 列包含 Using filesort 或 Using temporary 时,MySQL 的性能可能会存在问题,需要尽可能避免。
可以参考possible_keys,使用索引提高性能
本文来自博客园,作者:帅气的涛啊,转载请注明原文链接:https://www.cnblogs.com/handsometaoa/p/17525330.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号