ai时代与学术不端行为
学术道德
学术道德指从事学术研究活动时必须遵循道德规范和行为准则,尤其研究者在学术研究活动中要正确处理人与自然,人与然、个人与社会、个人与国家之间关系,这些行为规范是衡量研究者道德品质的重要标准。
而遵循的学术道德规范,是针对学术活动中判断正当与否、诚信与否的权利与义务的道德规范。
科研诚信:主要指科技人员在科技活动中弘扬以追求真理、实事求是、崇尚创新、开放协作为核心的科学精神,遵守相关法律法规,恪守科学道德准则,遵循科学共同体公认的行为规范。
中国科学院杨卫院士将学术不端与学术不当行为归纳为14种:剽窃、编造、篡改、捉刀(第三方代写)、重复发表、署名不当、利益冲突、关系游说、学术独裁、引用不当、幽灵引用(引用虚假文章)、幽灵评审(编造审稿人)、不可重复、伦理失范。
具体的学术不端行为
学术不端分为科研活动过程中的学术不端、论文写作与发表过程中的学术不端以及学术评价中的学术不端。科研活动按照阶段划分,主要分为5个阶段:项目申请、项目实施、成果形成、成果评价、成果发表阶段。
项目申请阶段
项目申请阶段时不端行为主要指申请立项过程中,未真实反映项目实际情况,可能存在的不端行为有:
1、作假行为:如剽窃他人的观点,在项目申请书中提供虚假信息。
2、隐瞒行为:夸大科研项目的实用价值,隐匿项目可能存在的负面影响,在他人未同意的情况下侵犯别人的知情权和署名权。
这阶段的不端行为中的隐瞒行为需要通过规范化的流程去加以约束,比如他人未同意的情况,可以依靠必须留下申报人联系方法来避免,经过联系可以将这一隐瞒行为化解。而夸大与隐瞒负面影响的行为,夸大可以通过让研究人员自己提供证据自证,但隐瞒负面影响很多时候只能靠研究人员的实事求是了。
项目实施阶段
在科研项目实施过程中,研究团队并没有按照申报书的承诺进行科研活动,出现背离科研初衷的行为。
这一阶段的不端行为主要包括以下类型:
1、作假行为:伪造或骗取实验标本、伪造没有实施的研究活动。
2、隐瞒行为:实施主体的变更与科研经费的不当使用。
实施阶段的学术造假阶段一般只能靠更严格的规范以及自律,这一阶段涉及到的过程是实施,只有参与人才知道具体过程,外界只能看到实施后得到的结果,除非有复现手段才可能拆穿。
科研成果形成阶段
科研成果形成阶段主要指科研活动的数据收集、整理直至形成学术成果的过程,这一阶段是科研活动不端行为高发阶段,主要表现为以作假手段,提出成果。
这一阶段的不端行为为伪造实验数据与剽窃他人成果。
科研成果评价阶段
这一阶段是论文发表以及成果公布之前必备过程,通过论文同行评议和项目的专家鉴定的形式来完成。
这一阶段存在的不端行为主要有:同行评议时的偏见,同行评议中的利益冲突、对科研成果本身价值的失实的夸大。
科研成果发表阶段
这是不端行为的高发阶段,类型表现为:论文不正当署名、侵占他人科研成果;论文一稿多投、盲目追求论文数量;科研成果传播失范——证据不足时就发表结论。
人工智能定义
人工智能是“制造智能机器,特别是智能计算机程序的科学和工程”(McCarthy, 2004)。人工智能的研究包括“感知、理解、推理、决策、创造”等方面,涉及多个学科,如计算机科学、心理学、哲学等(IBM, 2022)。人工智能可以分为弱人工智能和强人工智能,前者指专注于执行特定任务的人工智能,后者指具有与人类等同或超越的智能的人工智能(AIDD Pro, 2022)。
针对多发的不端行为,这是人工智能对于这些学术不端行为所能做出的一些监督手段。
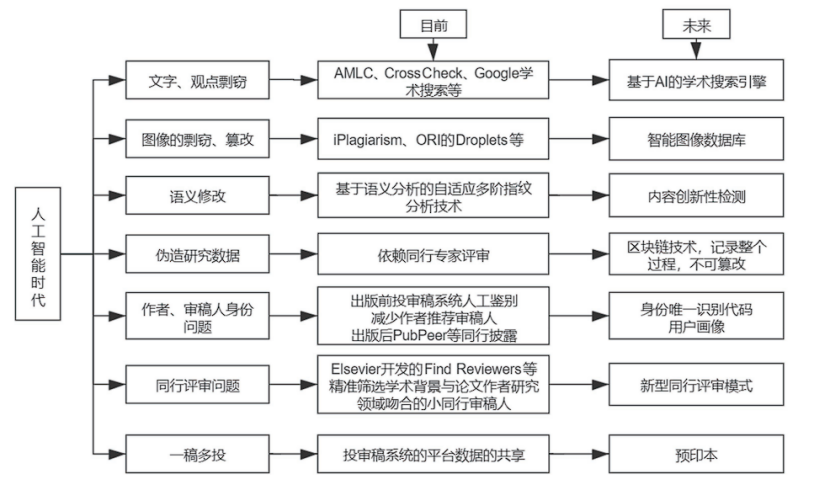
图1 AI时代学术期刊应对科研诚信问题的对策
在她的文章中提供了目前学术界对于多发的剽窃行为的目前的处理手段以及对于利用人工智能实现更智能化的检测的一些研究思路。
文字观点剽窃的检测
AMLC、CrossCheck、谷歌学术搜索等都是一些检测论文中文本和观点剽窃的工具,它们的原理是通过比较论文中的内容和其他已发表的文献,找出相似度高的部分,判断是否有剽窃行为。
检测图像的剽窃、篡改的IOlaglarism和OR的Droplets的原理
IOlaglarism是一种基于图像的特征提取方法,它可以通过计算图像中不同区域的变换值来判断是否有复制粘贴或拼接组合的篡改操作。变换值是根据不同的数学变换规则得到的,比如离散余弦变换、小波变换等。如果两个区域的变换值相似,就说明可能是被复制粘贴或拼接组合的篡改区域。
OR的Droplets是一种基于卷积神经网络的篡改检测方法,它可以通过学习图像中的局部和全局特征来判断是否有修复、拼接或copy-move伪造的篡改操作。卷积神经网络是一种深度学习模型,它可以自动提取图像中有用的信息,比如边缘、纹理、颜色等。如果一个区域的特征与其他区域不一致,就说明可能是被修复、拼接或copy-move伪造的篡改区域。
简单来说,IOlaglarism是通过计算图像中不同区域之间的差异来检测篡改,而OR的Droplets是通过学习图像中不同区域之间的相似性来检测篡改。
样本不足。这些技术可能没有收录所有的图像来源,比如一些专业的图像数据库、个人的图像作品、网络上的图像资源等,导致检测结果不完整或不准确。样本不足。虽然这些工具都有自己的数据库,收录了大量的文献,但是仍然无法涵盖所有的学术领域和来源。有些新出版的或者小众的文献可能没有被收录,导致检测结果不完整或不准确1。
样本不足。虽然这些工具都有自己的数据库,收录了大量的文献,但是仍然无法涵盖所有的学术领域和来源。有些新出版的或者小众的文献可能没有被收录,导致检测结果不完整或不准确。
基于语义分析的自适应多阶指纹分析技术是一种检测语义修改的技术,其原理是将文本中的每个词语用一个多维向量表示,然后根据词语之间的语义关系,构建一个多阶的指纹向量,用来表示文本的语义特征。通过比较不同文本的指纹向量,可以判断它们是否有语义上的相似性或差异性。
这种技术的优点是可以有效地检测出一些细微的语义修改,比如同义词替换、句子重组、意思曲解等,而不仅仅是基于词频或句法的相似度。这种技术的缺点是需要大量的标注数据和语义知识来训练和优化模型,而且对于一些隐含或歧义的语义修改,可能还需要人工的判断和分析。
区块链技术是一种利用密码学和分布式共识机制,保证数据的完整性和可追溯性的技术。区块链技术可以用来检测伪造数据的原理是,通过将数据分成多个区块,每个区块都包含上一个区块的哈希值(数据指纹),形成一个不可篡改的链条。如果有人想要修改或伪造某个区块中的数据,就会导致后续所有区块的哈希值发生变化,从而被其他节点发现并拒绝接受。
为了使用区块链技术记录研究数据的整个过程,不可篡改,需要进行数据上链防篡改。数据上链防篡改的方法有以下几个步骤:
1、将研究数据进行数字签名,生成一个唯一的哈希值,作为数据的身份标识。
2、将哈希值和其他相关信息(如时间戳、作者、来源等)打包成一个交易,发送到区块链网络中。
3、区块链网络中的节点通过共识算法,验证交易的有效性,并将其打包到一个新的区块中。
4、新的区块被添加到区块链上,形成一个不可逆的记录,任何人都可以查看和验证。
这样,就可以利用区块链技术,为研究数据提供一个可信、透明、不可篡改的存储和追溯平台,防止数据被伪造或篡改。
关于作者审稿人身份问题可以使用对其身份生成唯一识别码,关联到学校邮箱以及他个人邮箱。当作者投稿后记录并生成用户画像,通过一些简单判断,如短期大量投稿、一起投稿的用户画像可疑后,系统将用户标为可疑画像,在编辑审稿时去辅助编辑判断。
新型同行评审模式
在公开平台去评审,并保持可追溯。建立一个系统,收集专家的资料,去匹配符合要求且关系看似不密切(无合作)的评审员。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号