冒泡插入选择
冒泡,插入
问题:时间复杂度都是O(n2),为社么插入比冒泡更受欢迎?
需要考虑到的情况
1.最好情况、最坏情况、平均情况时间复杂度
2.同阶考虑系数,常数,低阶
时间复杂度的系数、常数 、低阶我们知道,时间复杂度反映的是数据规模 n 很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。
但是实际的软件开发中,我们排序的可能是 10 个、100 个、1000 个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。
3.比较次数和交换(或移动)次数
这一节和下一节讲的都是基于比较的排序算法。
基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换或移动。
所以,如果我们在分析排序算法的执行效率的时候,应该把比较次数和交换(或移动)次数也考虑进去。
ps:原地排序算法,就是特指空间复杂度是 O(1) 的排序算法。
4、稳定性
我通过一个例子来解释一下。比如我们有一组数据 2,9,3,4,8,3,按照大小排序之后就是 2,3,3,4,8,9。这组数据里有两个 3。
经过某种排序算法排序之后,如果两个 3 的前后顺序没有改变,那我们就把这种排序算法叫作稳定的排序算法;
如果前后顺序发生变化,那对应的排序算法就叫作不稳定的排序算法。
你可能要问了,两个 3 哪个在前,哪个在后有什么关系啊,稳不稳定又有什么关系呢?为什么要考察排序算法的稳定性呢?
很多数据结构和算法课程,在讲排序的时候,都是用整数来举例,但在真正软件开发中,我们要排序的往往不是单纯的整数,而是一组对象,我们需要按照对象的某个 key 来排序。
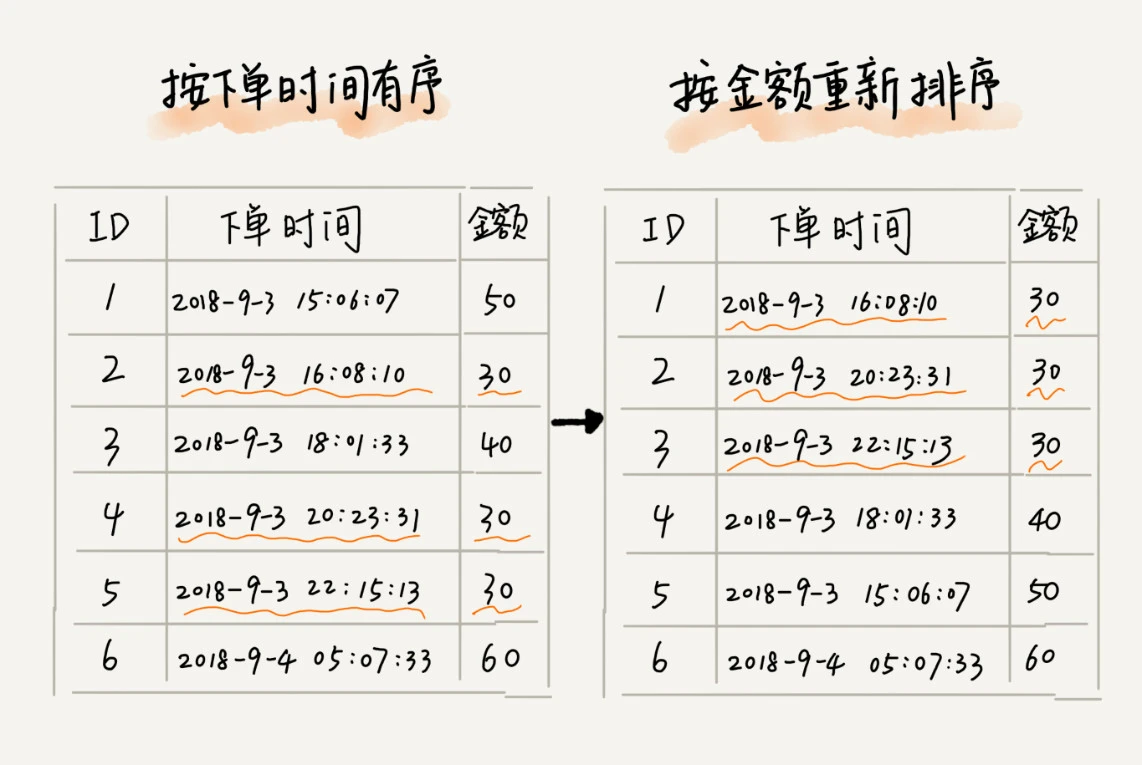
比如说,我们现在要给电商交易系统中的“订单”排序。
订单有两个属性,一个是下单时间,另一个是订单金额。
如果我们现在有 10 万条订单数据,我们希望按照金额从小到大对订单数据排序。对于金额相同的订单,我们希望按照下单时间从早到晚有序。
对于这样一个排序需求,我们怎么来做呢?
最先想到的方法是:我们先按照金额对订单数据进行排序,然后,再遍历排序之后的订单数据,对于每个金额相同的小区间再按照下单时间排序。这种排序思路理解起来不难,但是实现起来会很复杂。
借助稳定排序算法,这个问题可以非常简洁地解决。解决思路是这样的:
我们先按照下单时间给订单排序,注意是按照下单时间,不是金额。排序完成之后,我们用稳定排序算法,按照订单金额重新排序。
两遍排序之后,我们得到的订单数据就是按照金额从小到大排序,金额相同的订单按照下单时间从早到晚排序的.
冒泡排序

第一,冒泡排序是原地排序算法吗?
冒泡的过程只涉及相邻数据的交换操作,只需要常量级的临时空间,所以它的空间复杂度为 O(1),是一个原地排序算法。
第二,冒泡排序是稳定的排序算法吗?
在冒泡排序中,只有交换才可以改变两个元素的前后顺序。为了保证冒泡排序算法的稳定性,当有相邻的两个元素大小相等的时候,我们不做交换,相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。
第三,冒泡排序的时间复杂度是多少?
有序对
通过“有序度”和“逆序度”这两个概念来进行分析。有序度是数组中具有有序关系的元素对的个数。有序元素对用数学表达式表示就是这样:
有序元素对:a[i] <= a[j], 如果i < j。
 同理,对于一个倒序排列的数组,比如 6,5,4,3,2,1,有序度是 0;
对于一个完全有序的数组,比如 1,2,3,4,5,6,有序度就是 n*(n-1)/2,也就是 15。我们把这种完全有序的数组的有序度叫作满有序度。
同理,对于一个倒序排列的数组,比如 6,5,4,3,2,1,有序度是 0;
对于一个完全有序的数组,比如 1,2,3,4,5,6,有序度就是 n*(n-1)/2,也就是 15。我们把这种完全有序的数组的有序度叫作满有序度。
逆序对
逆序度的定义正好跟有序度相反(默认从小到大为有序)。
逆序元素对:a[i] > a[j], 如果i < j。
关于这三个概念,我们还可以得到一个公式:
逆序度 = 满有序度 - 有序度。
我们排序的过程就是一种增加有序度,减少逆序度的过程,最后达到满有序度,就说明排序完成了。
比较和交换。每交换一次,有序度就加 1。
不管算法怎么改进,交换次数总是确定的,即为逆序度,也就是n*(n-1)/2–初始有序度。此例中就是 15–3=12,要进行 12 次交换操作。

基于比较的排序算法中,逆序度 = 需要交换的次数,因此大致估算逆序度可以得到排序过程大致的平均时间复杂度
算法复杂度取决于:
比较与交换操作的复杂度叠加
比较最低也要O(n),交换最小O(1)。
比较最多O(n2),交换也是。
(1+2+......+n)/n = O(n)
同理
(n+......+n2)/n2 = O(n2)
插入排序(Insertion Sort)
思想:
将区域分为已排序区域与未排序区域,操作是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。
 对于不同的查找插入点方法(从头到尾、从尾到头),元素的比较次数是有区别的。但对于一个给定的初始序列,移动操作的次数总是固定的,就等于逆序度。
对于不同的查找插入点方法(从头到尾、从尾到头),元素的比较次数是有区别的。但对于一个给定的初始序列,移动操作的次数总是固定的,就等于逆序度。
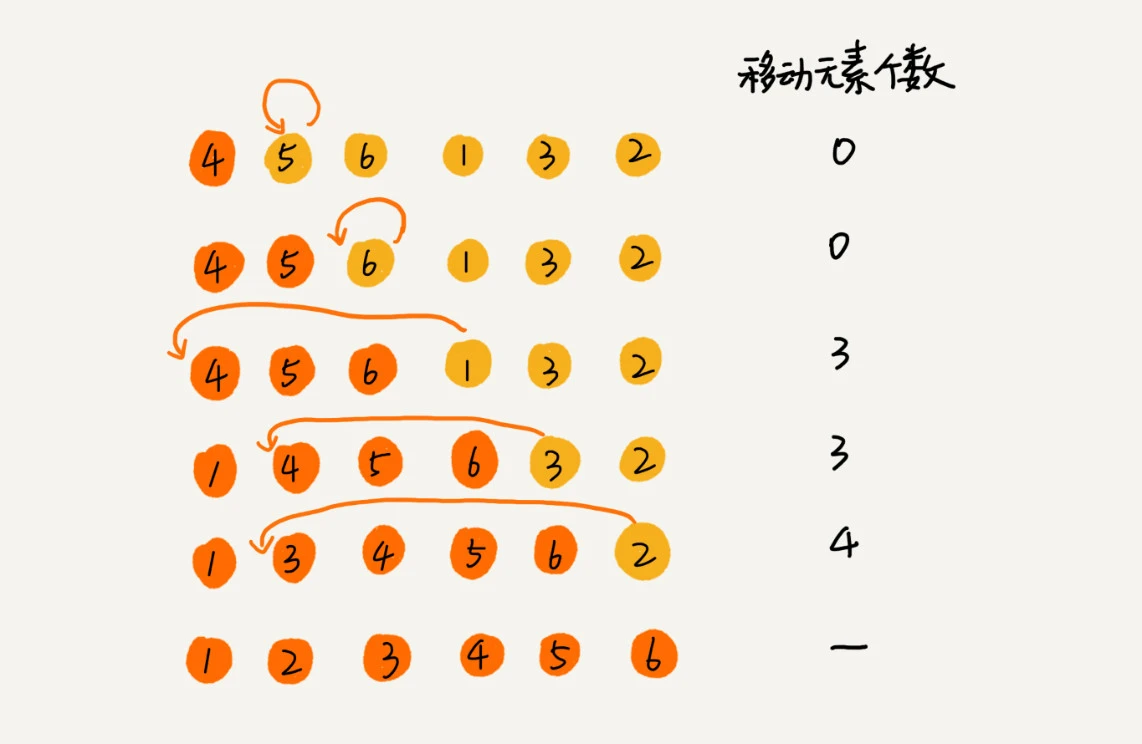
为什么说移动次数就等于逆序度呢?我拿刚才的例子画了一个图表,你一看就明白了。满有序度是 n*(n-1)/2=15,初始序列的有序度是 5,所以逆序度是 10。插入排序中,数据移动的个数总和也等于 10=3+3+4。
第一,插入排序是原地排序算法吗?
从实现过程可以很明显地看出,插入排序算法的运行并不需要额外的存储空间,所以空间复杂度是 O(1),也就是说,这是一个原地排序算法。
第二,插入排序是稳定的排序算法吗?
在插入排序中,对于值相同的元素,我们可以选择将后面出现的元素,插入到前面出现元素的后面,这样就可以保持原有的前后顺序不变,所以插入排序是稳定的排序算法。
第三,插入排序的时间复杂度是多少?
插入排序,是找到插入点之后,原本插入点及其之后的元素后移; 然后再赋值。
选择排序,是找到插入点之后,待插入的最小元素与原本插入点位置的元素做交换。
选择排序
基本的知识都讲完了,我们来看开篇的问题:冒泡排序和插入排序的时间复杂度都是 O(n2),都是原地排序算法,为什么插入排序要比冒泡排序更受欢迎呢?我们前面分析冒泡排序和插入排序的时候讲到,冒泡排序不管怎么优化,元素交换的次数是一个固定值,是原始数据的逆序度。插入排序是同样的,不管怎么优化,元素移动的次数也等于原始数据的逆序度。但是,从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个。
冒泡排序中数据的交换操作:
if (a[j] > a[j+1]) { // 交换
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
flag = true;
}
插入排序中数据的移动操作:
if (a[j] > value) {
a[j+1] = a[j]; // 数据移动
} else {
break;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号