kafka rebalance源码分析
一句话概述:
kafka重平衡机制以为了保证一个消费者组中消费环境发生变化后仍能够负载均衡的一种机制。(消费策略的转移)。
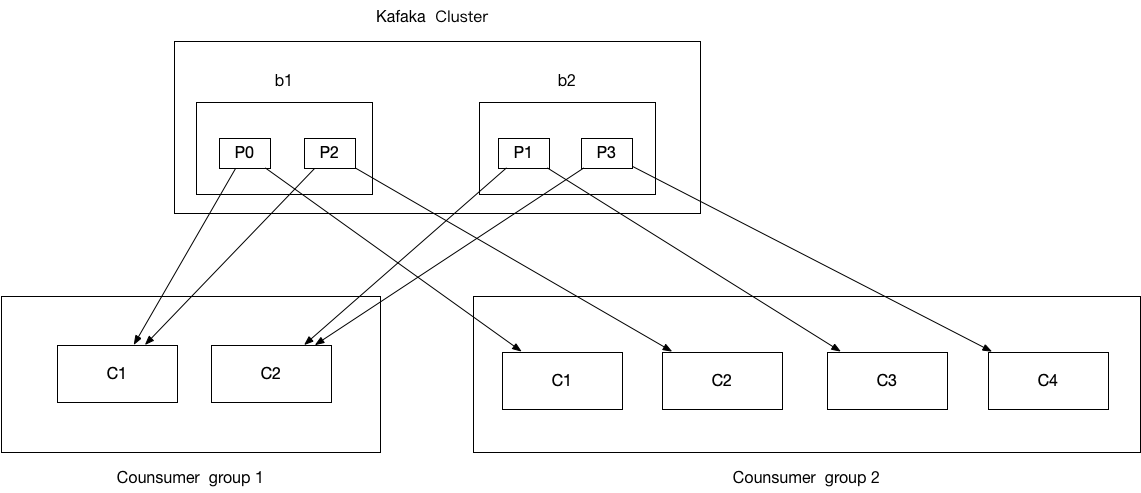
重平衡发生的几种情况:
-
有新的消费者加入Consumer Group。
-
有消费者宕机下线。消费者并不一定需要真正下线,例如遇到长时间的GC、网络延迟导致消费者长时间未向GroupCoordinator发送HeartbeatRequest时,GroupCoordinator会认为消费者下线。
-
有消费者主动退出Consumer Group(close,kill -9 pid)。
-
Consumer Group订阅的任一Topic出现分区数量的变化。
-
消费者调用unsubscrible()取消对某Topic的订阅。
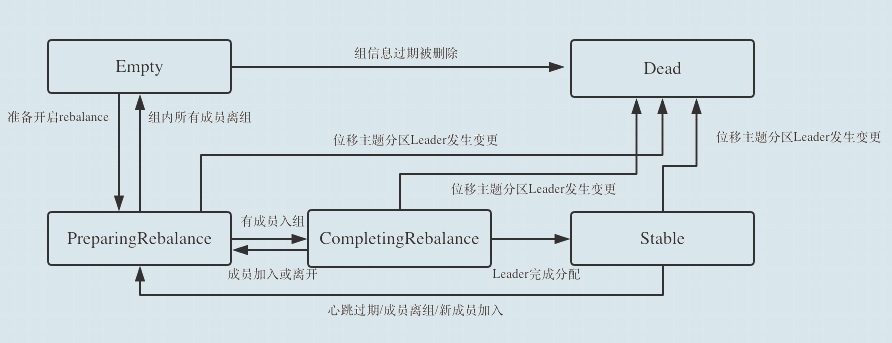
Kafka 为消费者组定义了 5 种状态,它们分别是:
-
Empty:组内无成员,但是存在未过期的已提交数据。
-
Dead:组内无成员,数据被删除。
-
PreparingRebalance:准备开始重平衡,所有成员都需要重新请求加入组。
-
CompletingRebalance:所有成员都已经加入,等待分配方案。
-
Stable:重平衡完成,组内消费者可以正常开始消费
rebalance状态流转:
rebalance过程中的请求:
让我们根据这个请求顺序图来解释一下各个状态是如何流转的:

-
Empty(Empty):当一个Group是新创建的,或者内部没有成员时,状态就是Empty。我们假设有一个新的消费组,这个消费组的第一个成员发送FIND_COORDINATOR请求的时候,也就是开启了Rebalacne的第一个阶段。
-
PreparingRebalance(JOIN):当完成FIND_COORDINATOR请求后,对应的客户端就能找到自己的coordinator节点是哪个,然后紧接着就会发送JOIN_GROUP请求,当coordinator收到这个请求后,就会把状态由Empty变更为PreparingRebalance,意味着准备要开始rebalance了。
-
CompletingRebalance(SYNC):当所有的成员都完成JOIN_GROUP请求的发送之后,或者rebalance过程超时后,对应的PreparingRebalance阶段就会结束,进而进入CompletingRebalance状态。
-
Stabe(Stable):在进入CompletingRebalance状态的时候呢,服务端会返回所有JOIN_GROUP请求对应的响应,然后客户端收到响应之后立刻就发送SYNC_GROUP请求,服务端在收到leader发送的SNYC_GROUP请求后,就会转换为Stable状态,意味着整个rebalance过程已经结束了。
group 如何选择相应的 GroupCoordinator
 ; ; ; ;要说这个,就必须介绍一下这个 __consumer_offsets topic 了,它是 Kafka 内部使用的一个 topic,专门用来存储 group 消费的情况,默认情况下有50个 partition,每个 partition 默认有三个副本,而具体的一个 group 的消费情况要存储到哪一个 partition 上,是根据 abs(GroupId.hashCode()) % NumPartitions 来计算的(其中,NumPartitions 是 __consumer_offsets 的 partition 数,默认是50个)。
 ; ; ; ;对于 consumer group 而言,是根据其 group.id 进行 hash 并计算得到其具对应的 partition 值,该 partition leader 所在 Broker 即为该 Group 所对应的 GroupCoordinator,GroupCoordinator 会存储与该 group 相关的所有的 Meta 信息。

客户端重平衡的流程:
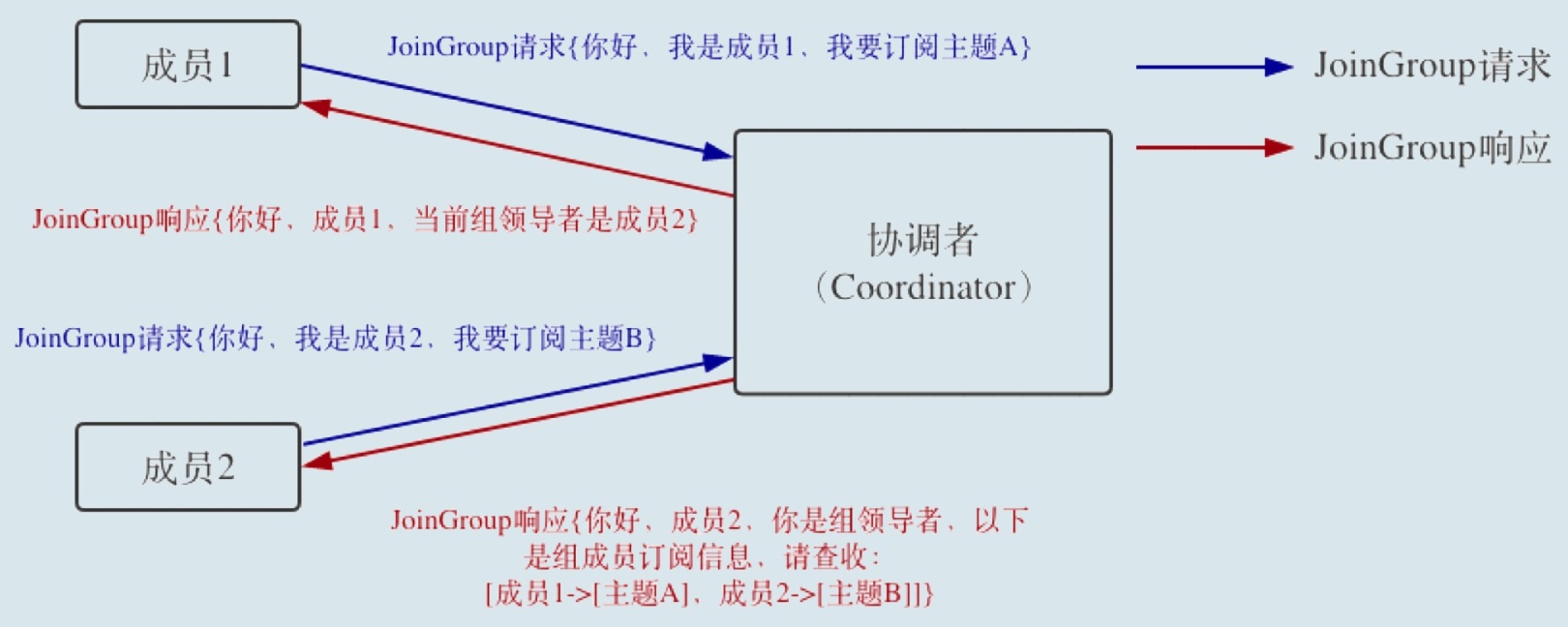
消费端重平衡分为两个步骤,对应两个请求:
JoinGroup
向协调者发送加入组的请求,同时上报自己订阅的主题,这样协调者就能收集到所有成员的订阅信息。
一旦收集了全部成员的JoinGroup请求后, Coordinator 会从这些成员中选择一个担任这个消费者组的领导者。
领导者消费者的任务是收集所有成员的订阅信息,然后根据这些信息,制定具体的分区消费分配方案。
Coordinator 会把消费者组订阅信息封装进JoinGroup请求的 响应体中,然后发给领导者,由领导者统一做出分配方案后。
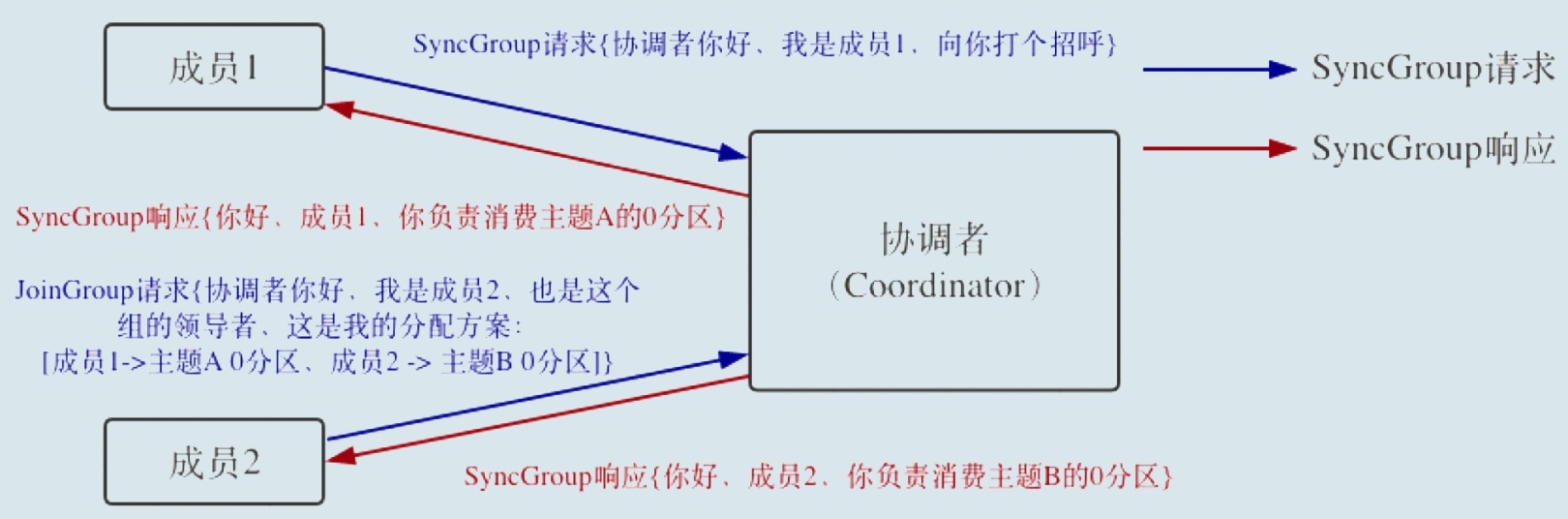
SyncGroup
领导者消费者(Leader Consumer)分配方案。领导者向 Coordinator 发送SyncGroup请求,
将刚刚做出的分配方案发给协调者。 值得注意的是,其他成员也会向 Coordinator 发送SyncGroup请求, 只不过请求体中并没有实际的内容。
这一步的主要目的是让 Coordinator 接收分配方案, 然后统一以 SyncGroup 响应的方式分发给所有成员, 这样组内所有成员就都知道自己该消费哪些分区了。
服务端重平衡源码:
kafka各种请求的入口:KafkaApis.scala
def handle(request: RequestChannel.Request) {
try {
trace(s"Handling request:${request.requestDesc(true)} from connection ${request.context.connectionId};" +
s"securityProtocol:${request.context.securityProtocol},principal:${request.context.principal}")
request.header.apiKey match {
case ApiKeys.PRODUCE => handleProduceRequest(request)
case ApiKeys.FETCH => handleFetchRequest(request)
case ApiKeys.LIST_OFFSETS => handleListOffsetRequest(request)
case ApiKeys.METADATA => handleTopicMetadataRequest(request)
case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request)
case ApiKeys.STOP_REPLICA => handleStopReplicaRequest(request)
case ApiKeys.UPDATE_METADATA => handleUpdateMetadataRequest(request)
case ApiKeys.CONTROLLED_SHUTDOWN => handleControlledShutdownRequest(request)
case ApiKeys.OFFSET_COMMIT => handleOffsetCommitRequest(request)
case ApiKeys.OFFSET_FETCH => handleOffsetFetchRequest(request)
case ApiKeys.FIND_COORDINATOR => handleFindCoordinatorRequest(request)
case ApiKeys.JOIN_GROUP => handleJoinGroupRequest(request)
case ApiKeys.HEARTBEAT => handleHeartbeatRequest(request)
case ApiKeys.LEAVE_GROUP => handleLeaveGroupRequest(request)
case ApiKeys.SYNC_GROUP => handleSyncGroupRequest(request)
case ApiKeys.DESCRIBE_GROUPS => handleDescribeGroupRequest(request)
case ApiKeys.LIST_GROUPS => handleListGroupsRequest(request)
}
重平衡的业务处理:GroupCoordinator.scala
加入消费者组
def handleJoinGroup(groupId: String,
memberId: String,
clientId: String,
clientHost: String,
rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
protocolType: String,
protocols: List[(String, Array[Byte])],
responseCallback: JoinCallback) {
//异常情况返回错误码 1.协调者是否启动 2.组id是否非法 3.检查组协调者是否管理此组 4.GroupCoordinator是否已经加载此Consumer Group对应的 offset 分区 5.超时时常是否在合法区间
if (!isActive.get) {
responseCallback(joinError(memberId, Errors.COORDINATOR_NOT_AVAILABLE))
} else if (!validGroupId(groupId)) {
responseCallback(joinError(memberId, Errors.INVALID_GROUP_ID))
} else if (!isCoordinatorForGroup(groupId)) {
responseCallback(joinError(memberId, Errors.NOT_COORDINATOR))
} else if (isCoordinatorLoadInProgress(groupId)) {
responseCallback(joinError(memberId, Errors.COORDINATOR_LOAD_IN_PROGRESS))
} else if (sessionTimeoutMs < groupConfig.groupMinSessionTimeoutMs ||
sessionTimeoutMs > groupConfig.groupMaxSessionTimeoutMs) {
responseCallback(joinError(memberId, Errors.INVALID_SESSION_TIMEOUT))
} else {
// only try to create the group if the group is not unknown AND
// the member id is UNKNOWN, if member is specified but group does not
// exist we should reject the request
//只有在group为建立并且成员id未知的情况下接受请求并进行处理
groupManager.getGroup(groupId) match {
case None =>
if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) {
info(s"Group match none and memberId is: ${memberId}")
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID))
} else {
//创建消费者组
val group = groupManager.addGroup(new GroupMetadata(groupId, initialState = Empty))
info(s"Group match none and is a new member,GroupMetadata: ${group},next step doJoinGroup.")
//进行加入组的操作
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
//已经存在消费者组的情况下
case Some(group) =>
info(s"Group match some group,groupId is ${groupId},next step doJoinGroup.")
//加入消费者组
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
}
}
//处理加入组的请求:
private def doJoinGroup(group: GroupMetadata,
memberId: String,
clientId: String,
clientHost: String,
rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
protocolType: String,
protocols: List[(String, Array[Byte])],
responseCallback: JoinCallback) {
group.inLock {
if (!group.is(Empty) && (!group.protocolType.contains(protocolType) || !group.supportsProtocols(protocols.map(_._1).toSet))) {
// if the new member does not support the group protocol, reject it
responseCallback(joinError(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL))
} else if (group.is(Empty) && (protocols.isEmpty || protocolType.isEmpty)) {
//reject if first member with empty group protocol or protocolType is empty
responseCallback(joinError(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL))
} else if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID && !group.has(memberId)) {
// if the member trying to register with a un-recognized id, send the response to let
// it reset its member id and retry
//memberid 无法被当前组识别
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID))
} else {
group.currentState match {
//根据Consumer Group的状态分类进行处理
//组内没有任何成员,且元数据已经被清除
case Dead =>
// if the group is marked as dead, it means some other thread has just removed the group
// from the coordinator metadata; this is likely that the group has migrated to some other
// coordinator OR the group is in a transient unstable phase. Let the member retry
// joining without the specified member id,
info("group.currentState is Dead.")
//直接返回错误码
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID))
//正在重平衡状态中
case PreparingRebalance =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
info(s"group.currentState is ${group.currentState},and memberId is ${memberId},next step addMember.")
//未知消费者申请加入
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
info(s"group.currentState is ${group.currentState},and memberId is ${memberId},next step updateMember.")
val member = group.get(memberId)
//已知消费者申请加入,需要更新元数据
updateMemberAndRebalance(group, member, protocols, responseCallback)
}
//消费者组下的所有成员已经加入,各个成员正在等待分配方案。
//可能会转换状态到 --> PreparingRebalance
case CompletingRebalance =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
info(s"group.currentState is ${group.currentState},and memberId is ${memberId},next step addMember.")
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
//info(s"group.currentState is ${group.currentState},and memberId is ${memberId}.")
val member = group.get(memberId)
//元数据(PartitionAssignor)不变的情况下,只需要返回当前组的信息即可
if (member.matches(protocols)) {
info(s"group.currentState is: ${group.currentState},and memberId is: ${memberId}," +
s"member.matches(protocols) is : ${member.matches(protocols)}.")
// member is joining with the same metadata (which could be because it failed to
// receive the initial JoinGroup response), so just return current group information
// for the current generation.
responseCallback(JoinGroupResult(
members = if (group.isLeader(memberId)) {
group.currentMemberMetadata
} else {
Map.empty
},
memberId = memberId,
generationId = group.generationId,
subProtocol = group.protocolOrNull,
leaderId = group.leaderOrNull,
error = Errors.NONE))
} else {
// member has changed metadata, so force a rebalance
//元数据已经改变,强制重平衡
info(s"group.currentState is: ${group.currentState},and memberId is: ${memberId}," +
s"member.matches(protocols) is : ${member.matches(protocols)},next step updateMember.")
updateMemberAndRebalance(group, member, protocols, responseCallback)
}
}
//消费者组未空或者消费者组处于稳定状态
case Empty | Stable =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// if the member id is unknown, register the member to the group
info(s"group.currentState is: ${group.currentState},and memberId is ${memberId},next step addMember.")
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
//稳定状态下怎么会发送加入组的请求呢?(兜底机制,不排除有这种可能?)
info(s"group.currentState is: ${group.currentState},and memberId is ${memberId}.")
val member = group.get(memberId)
if (group.isLeader(memberId) || !member.matches(protocols)) {
// force a rebalance if a member has changed metadata or if the leader sends JoinGroup.
// The latter allows the leader to trigger rebalances for changes affecting assignment
// which do not affect the member metadata (such as topic metadata changes for the consumer)
info(s"group.currentState is: ${group.currentState},and memberId is ${memberId}," +
s"group.isLeader(memberId): ${group.isLeader(memberId)},!member.matches(protocols) is: ${!member.matches(protocols)},next step updateMember.")
updateMemberAndRebalance(group, member, protocols, responseCallback)
} else {
info(s"group.currentState is: ${group.currentState},and memberId is ${memberId}," +
s"group.isLeader(memberId): ${group.isLeader(memberId)},!member.matches(protocols) is: ${!member.matches(protocols)},next step updateMember.")
updateMemberAndRebalance(group, member, protocols, responseCallback)
// for followers with no actual change to their metadata, just return group information
// for the current generation which will allow them to issue SyncGroup
responseCallback(JoinGroupResult(
members = Map.empty,
memberId = memberId,
generationId = group.generationId,
subProtocol = group.protocolOrNull,
leaderId = group.leaderOrNull,
error = Errors.NONE))
}
}
}
info(s"Group is PreparingRebalance? line(248):${group.is(PreparingRebalance)}")
// 尝试完成相关的DelayedJoin
if (group.is(PreparingRebalance))
joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
}
}
延时加入组的操作:DelayedJoin
private[group] class DelayedJoin(coordinator: GroupCoordinator,
group: GroupMetadata,
rebalanceTimeout: Long) extends DelayedOperation(rebalanceTimeout, Some(group.lock)) {
override def tryComplete(): Boolean = coordinator.tryCompleteJoin(group, forceComplete _)
override def onExpiration() = coordinator.onExpireJoin()
override def onComplete() = coordinator.onCompleteJoin(group)
//首先尝试下是否可以完成延时操作:
def tryCompleteJoin(group: GroupMetadata, forceComplete: () => Boolean) = {
group.inLock {
if (group.notYetRejoinedMembers.isEmpty)
forceComplete()
else false
}
}
//强制执行
def onCompleteJoin(group: GroupMetadata) {
group.inLock {
// remove any members who haven't joined the group yet
// 如果组内成员依旧没能连上,那么就删除它,接收当前JOIN阶段
group.notYetRejoinedMembers.foreach { failedMember =>
group.remove(failedMember.memberId)
info(s"Group remove failedMember memberId: ${failedMember.memberId}")
// TODO: cut the socket connection to the client
}
if (!group.is(Dead)) {
// 状态机流转 : preparingRebalancing -> CompletingRebalance
group.initNextGeneration()
if (group.is(Empty)) {
info(s"Group ${group.groupId} with generation ${group.generationId} is now empty " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
groupManager.storeGroup(group, Map.empty, error => {
if (error != Errors.NONE) {
// we failed to write the empty group metadata. If the broker fails before another rebalance,
// the previous generation written to the log will become active again (and most likely timeout).
// This should be safe since there are no active members in an empty generation, so we just warn.
warn(s"Failed to write empty metadata for group ${group.groupId}: ${error.message}")
}
})
} else {
// JOIN阶段标志结束日志
info(s"Stabilized group ${group.groupId} generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// trigger the awaiting join group response callback for all the members after rebalancing
for (member <- group.allMemberMetadata) {
assert(member.awaitingJoinCallback != null)
val joinResult = JoinGroupResult(
// 如果是leader 就返回member列表及其元数据信息
members = if (group.isLeader(member.memberId)) {
group.currentMemberMetadata
} else {
Map.empty
},
memberId = member.memberId,
generationId = group.generationId,
subProtocol = group.protocolOrNull,
leaderId = group.leaderOrNull,
error = Errors.NONE)
member.awaitingJoinCallback(joinResult)
member.awaitingJoinCallback = null
completeAndScheduleNextHeartbeatExpiration(group, member)
}
}
}
}
}
prepareRebalance
 ; ; ; ;协调者处理不同消费者的“加入组请求”,由于不能立即返回“加入组响应”给每个消费者,它会创建一个“延迟操作”,表示协调者会延迟发送“加入组响应”给消费者。但协调者不会为每个消费者的“ 加入组请求”都创建一个“ 延迟操作”,而是仅当消费组状态从“稳定”转变为“准备再平衡”,才创建一个“延迟操作”对象。
private def prepareRebalance(group: GroupMetadata) {
// if any members are awaiting sync, cancel their request and have them rejoin
if (group.is(CompletingRebalance))
resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS)
//如果不是Empty就创建一个DelayedJoin 5min;如果是Empty就创建一个InitialDelayedJoin延时任务,超时时间是3s
val delayedRebalance = if (group.is(Empty))
new InitialDelayedJoin(this,
joinPurgatory,
group,
groupConfig.groupInitialRebalanceDelayMs,// 默认3000ms,即3s
groupConfig.groupInitialRebalanceDelayMs,
max(group.rebalanceTimeoutMs - groupConfig.groupInitialRebalanceDelayMs, 0))
else
new DelayedJoin(this, group, group.rebalanceTimeoutMs)// 这里这个超时时间是客户端的poll间隔,默认5分钟
//状态转换为preparingrebalance
group.transitionTo(PreparingRebalance)
info(s"Preparing to rebalance group ${group.groupId} with old generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// 尝试完成操作
val groupKey = GroupKey(group.groupId)
joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey))
}
doSyncGroup:
//处理同步请求:
private def doSyncGroup(group: GroupMetadata,
generationId: Int,
memberId: String,
groupAssignment: Map[String, Array[Byte]],
responseCallback: SyncCallback) {
group.inLock {
if (!group.has(memberId)) {
responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID)
} else if (generationId != group.generationId) {
responseCallback(Array.empty, Errors.ILLEGAL_GENERATION)
} else {
group.currentState match {
case Empty | Dead =>
responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID)
// 只有group处于compeletingRebalance状态下才会被处理
// 其余状态都是错误的状态
case PreparingRebalance =>
responseCallback(Array.empty, Errors.REBALANCE_IN_PROGRESS)
case CompletingRebalance =>
// 给当前member设置回调,之后就啥也不干,也不返回
// 等到leader的分区方案就绪后,才会被返回。
group.get(memberId).awaitingSyncCallback = responseCallback
// if this is the leader, then we can attempt to persist state and transition to stable
//只有收到leader的SYNC才会被处理,并进行状态机流转
if (group.isLeader(memberId)) {
info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId} memberId is ${memberId}.")
// fill any missing members with an empty assignment
val missing = group.allMembers -- groupAssignment.keySet
val assignment = groupAssignment ++ missing.map(_ -> Array.empty[Byte]).toMap
groupManager.storeGroup(group, assignment, (error: Errors) => {
group.inLock {
// another member may have joined the group while we were awaiting this callback,
// so we must ensure we are still in the CompletingRebalance state and the same generation
// when it gets invoked. if we have transitioned to another state, then do nothing
if (group.is(CompletingRebalance) && generationId == group.generationId) {
if (error != Errors.NONE) {
resetAndPropagateAssignmentError(group, error)
maybePrepareRebalance(group)
} else {
//给每个member分配方案
setAndPropagateAssignment(group, assignment)
// 状态机流转:CompletingRebalance -> Stable
group.transitionTo(Stable)
}
}
}
})
}
case Stable =>
// 如果已经处于stable状态,说明leader已经把分区分配方案传上来了
// 那么直接从group的元数据里面返回对应的方案就好了
// if the group is stable, we just return the current assignment
val memberMetadata = group.get(memberId)
responseCallback(memberMetadata.assignment, Errors.NONE)
// 开启心跳检测
completeAndScheduleNextHeartbeatExpiration(group, group.get(memberId))
}
}
}
}
心跳源码:
AbstractCoordinator.scala:
if (coordinatorUnknown()) {
if (findCoordinatorFuture != null || lookupCoordinator().failed())
// the immediate future check ensures that we backoff properly in the case that no
// brokers are available to connect to.
AbstractCoordinator.this.wait(retryBackoffMs);
} else if (heartbeat.sessionTimeoutExpired(now)) {//将上次成功获取响应的时间与当前时间做对比,超过时间则认为协调者不健康,相协调者标记为unknown
//心跳超时超过sessiontime,
// the session timeout has expired without seeing a successful heartbeat, so we should
// probably make sure the coordinator is still healthy.
log.info("HeartbeatThread: sessionTimeoutExpired.");
markCoordinatorUnknown();
} else if (heartbeat.pollTimeoutExpired(now)) {
//在两次poll的时间超过设置值,则向协调者发送离开组的请求。
// the poll timeout has expired, which means that the foreground thread has stalled
// in between calls to poll(), so we explicitly leave the group.
log.info("HeartbeatThread: pollTimeoutExpired.");
maybeLeaveGroup();
} else if (!heartbeat.shouldHeartbeat(now)) {
// poll again after waiting for the retry backoff in case the heartbeat failed or the
// coordinator disconnected
AbstractCoordinator.this.wait(retryBackoffMs);
} else {
heartbeat.sentHeartbeat(now);
服务端的对心跳的检测:
private def completeAndScheduleNextHeartbeatExpiration(group: GroupMetadata, member: MemberMetadata) {
// complete current heartbeat expectation
member.latestHeartbeat = time.milliseconds()
val memberKey = MemberKey(member.groupId, member.memberId)
heartbeatPurgatory.checkAndComplete(memberKey)
// reschedule the next heartbeat expiration deadline
val newHeartbeatDeadline = member.latestHeartbeat + member.sessionTimeoutMs
//创建 DelayedHeartbeat 对象用于超时检查,
val delayedHeartbeat = new DelayedHeartbeat(this, group, member, newHeartbeatDeadline, member.sessionTimeoutMs)
heartbeatPurgatory.tryCompleteElseWatch(delayedHeartbeat, Seq(memberKey))
}
//延时心跳检查对象
private[group] class DelayedHeartbeat(coordinator: GroupCoordinator,
group: GroupMetadata,
member: MemberMetadata,
heartbeatDeadline: Long,
sessionTimeout: Long)
extends DelayedOperation(sessionTimeout, Some(group.lock)) {
override def tryComplete(): Boolean = coordinator.tryCompleteHeartbeat(group, member, heartbeatDeadline, forceComplete _)
override def onExpiration() = coordinator.onExpireHeartbeat(group, member, heartbeatDeadline)
override def onComplete() = coordinator.onCompleteHeartbeat()
}
//心跳超时
def onExpireHeartbeat(group: GroupMetadata, member: MemberMetadata, heartbeatDeadline: Long) {
group.inLock {
if (!shouldKeepMemberAlive(member, heartbeatDeadline)) {
info(s"Member ${member.memberId} in group ${group.groupId} has failed, removing it from the group")
//超时后将从组中移除
removeMemberAndUpdateGroup(group, member)
}
}
}
几个影响重平衡的参数:
-
maxpollinterval:两次poll之间的时间间隔。
-
session.timeout.ms:表示 consumer 向 broker 发送心跳的超时时间。默认10s。
-
heartbeat.interval.ms:表示 consumer 每次向 broker 发送心跳的时间间隔。默认3s,(session.timeout.ms>=3heartbeat.interval.ms)。
![]()
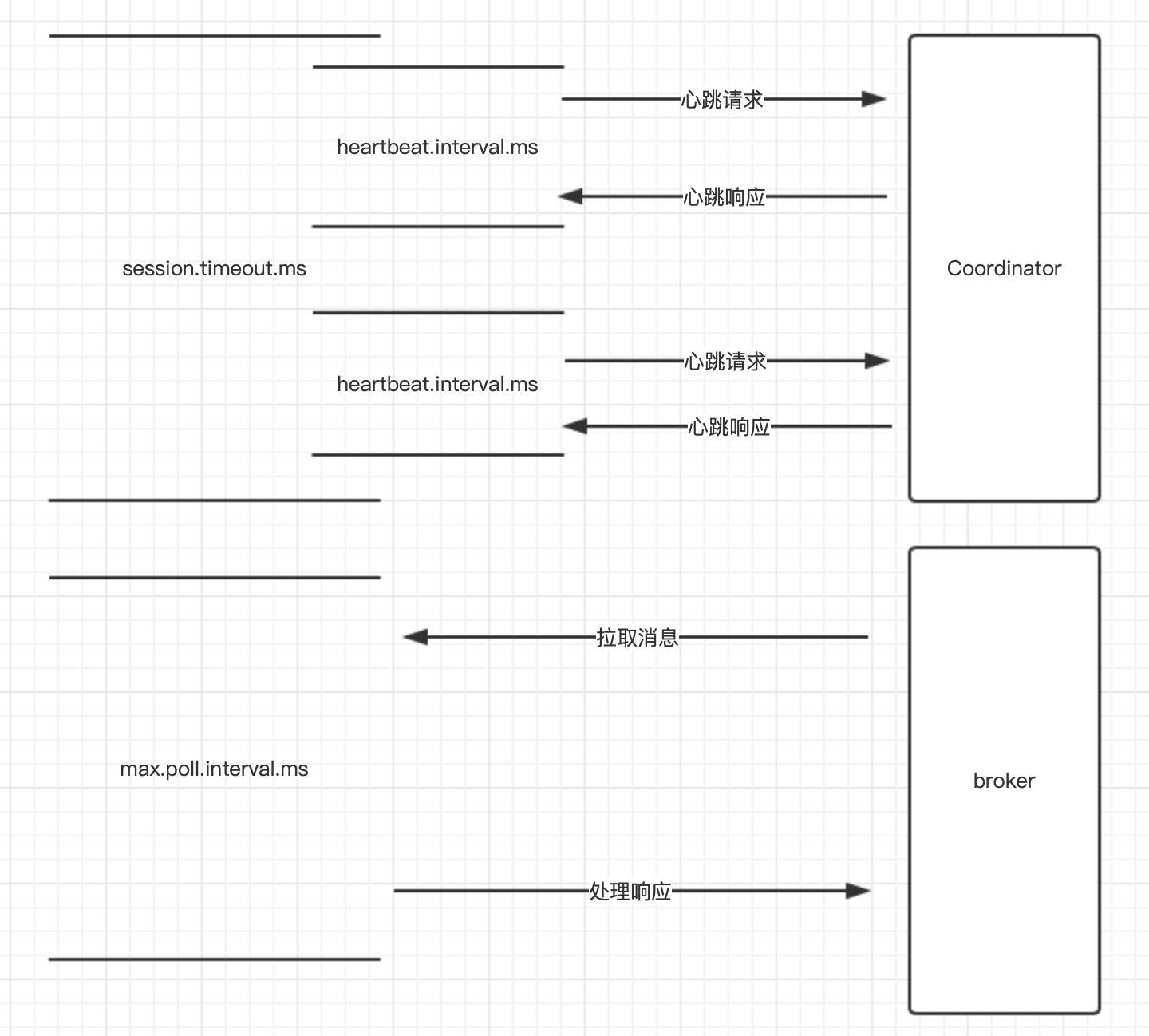
几种场景的重平衡测试:
1.新加入组:
server:
//开始新的重平衡
[2021-12-19 21:21:50,010] INFO [GroupCoordinator 0]: Preparing to rebalance group group-1 with old generation 4 (__consumer_offsets-49) (kafka.coordinator.group.GroupCoordinator)
//所有消费者均加入组
[2021-12-19 21:21:52,727] INFO [GroupCoordinator 0]: Stabilized group group-1 generation 5 (__consumer_offsets-49) (kafka.coordinator.group.GroupCoordinator)
//收到leader的分配方案
[2021-12-19 21:21:52,732] INFO [GroupCoordinator 0]: Assignment received from leader for group group-1 for generation 5 (kafka.coordinator.group.GroupCoordinator)
client:
//寻找协调者
[2022-01-21 11:01:52,692] INFO Discovered coordinator 10.56.40.142:9092 (id: 2147483647 rack: null) for group g1. (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
//放弃原来的分区策略,原来的分配分区为:[]
[2022-01-21 11:01:52,696] INFO Revoking previously assigned partitions [] for group g1 (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
//发送加入组的请求
[2022-01-21 11:01:52,696] INFO (Re-)joining group g1 (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
//成功加入组
[2022-01-21 11:01:53,812] INFO Successfully joined group g1 with generation 1 (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
//设置新的消费分区
[2022-01-21 11:01:53,815] INFO Setting newly assigned partitions [test11-0, test11-1, test11-2] for group g1 (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
2.业务逻辑过重,业务处理的时间超过maxpollinterval
client:
[2022-01-24 15:26:26,598] WARN Auto-commit of offsets {test11-2=OffsetAndMetadata{offset=126, metadata=''}} failed for group g1:
Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member.
This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms,
which typically implies that the poll loop is spending too much time message processing.
You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
(org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
server:
[2022-01-24 15:26:26,611] DEBUG [GroupCoordinator 0]: Member consumer22-0b748f59-4fbc-48f1-98e7-102e78b158e3 in group g1 has left, removing it from the group (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:26,611] INFO [GroupCoordinator 0]: Preparing to rebalance group g1 with old generation 6 (__consumer_offsets-42) (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:26,636] INFO [KafkaApi-0] Handle join group request for correlation id 49 to client consumer22. (kafka.server.KafkaApis)
[2022-01-24 15:26:26,637] INFO [GroupCoordinator 0]: Group match some group,groupId is g1,next step doJoinGroup. (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:26,638] INFO [GroupCoordinator 0]: group.currentState is PreparingRebalance,and memberId is ,next step addMember. (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:26,638] INFO [GroupCoordinator 0]: Group is PreparingRebalance? line(248):true (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:27,193] INFO [KafkaApi-0] Handle join group request for correlation id 791 to client consumer0. (kafka.server.KafkaApis)
[2022-01-24 15:26:27,193] INFO [GroupCoordinator 0]: Group match some group,groupId is g1,next step doJoinGroup. (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:27,193] INFO [GroupCoordinator 0]: group.currentState is PreparingRebalance,and memberId is consumer0-d45edb18-451e-429d-ab04-1102a95b2f1d,next step updateMember. (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:27,193] INFO [GroupCoordinator 0]: Group is PreparingRebalance? line(248):true (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:27,194] INFO [GroupCoordinator 0]: Stabilized group g1 generation 7 (__consumer_offsets-42) (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:26:27,194] INFO [KafkaApi-0] Sending join group response JoinGroupResponse(throttleTimeMs=0, error=NONE, generationId=7, groupProtocol=range, memberId=consumer22-3126c929-6c89-47d4-8391-1854486f321e, leaderId=consumer0-d45edb18-451e-429d-ab04-1102a95b2f1d, members=) for correlation id 49 to client consumer22. (kafka.server.KafkaApis)
[2022-01-24 15:26:27,194] INFO [KafkaApi-0] Sending join group response JoinGroupResponse(throttleTimeMs=0, error=NONE, generationId=7, groupProtocol=range, memberId=consumer0-d45edb18-451e-429d-ab04-1102a95b2f1d, leaderId=consumer0-d45edb18-451e-429d-ab04-1102a95b2f1d, members=consumer22-3126c929-6c89-47d4-8391-1854486f321e,consumer0-d45edb18-451e-429d-ab04-1102a95b2f1d) for correlation id 791 to client consumer0. (kafka.server.KafkaApis)
[2022-01-24 15:26:27,196] INFO [GroupCoordinator 0]: Assignment received from leader for group g1 for generation 7 memberId is consumer0-d45edb18-451e-429d-ab04-1102a95b2f1d. (kafka.coordinator.group.GroupCoordinator)
[2022-01-24 15:29:00,213] INFO [GroupMetadataManager brokerId=0] Removed 0 expired offsets in 8 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
3.心跳超时:
修改源码模拟超时的情况
synchronized RequestFuture<Void> sendHeartbeatRequest() {
try {
log.info("Test heartbeat thread block,sleep 10s");
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("Sending Heartbeat request to coordinator {}", coordinator);
HeartbeatRequest.Builder requestBuilder =
new HeartbeatRequest.Builder(this.groupId, this.generation.generationId, this.generation.memberId);
return client.send(coordinator, requestBuilder)
.compose(new HeartbeatResponseHandler());
}
server:
[2021-12-20 21:48:47,685] INFO [GroupCoordinator 0]: Member consumer2-dd4a191e-c537-4e3d-b5b9-81c17c5f3136 in group g1 has failed, removing it from the group (kafka.coordinator.group.GroupCoordinator)
[2021-12-20 21:48:47,685] INFO [GroupCoordinator 0]: Preparing to rebalance group g1 with old generation 190 (__consumer_offsets-42) (kafka.coordinator.group.GroupCoordinator)
client:
[2021-12-20 21:48:38,681] INFO [Consumer clientId=consumer2, groupId=g1] This is consumer2: sleep 10s (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
4.客户端主动调用unsubscribe
时间相差了10s,说明还是通过心跳机制触发的重平衡。
server:
[2021-12-19 21:59:06,636] INFO [GroupCoordinator 0]: Member consumer-1-1b50470e-f950-4c37-bf95-3156321a8cbb in group group-1 has failed, removing it from the group (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 21:59:06,636] INFO [GroupCoordinator 0]: Preparing to rebalance group group-1 with old generation 15 (__consumer_offsets-49) (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 21:59:08,641] INFO [GroupCoordinator 0]: Stabilized group group-1 generation 16 (__consumer_offsets-49) (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 21:59:08,642] INFO [GroupCoordinator 0]: Assignment received from leader for group group-1 for generation 16 (kafka.coordinator.group.GroupCoordinator)
client:
2021-12-19 21:58:57: unsubscribe
if (state != MemberState.STABLE) {
log.info("MemberState.STABLE: "+MemberState.STABLE.toString());
// the group is not stable (perhaps because we left the group or because the coordinator
// kicked us out), so disable heartbeats and wait for the main thread to rejoin.
//禁用心跳线程
disable();
continue;
}
5.客户端主动调用close:
close最终会调用:maybeLeaveGroup发送离开组的请求,所以从日志上看,close与发生冲平衡几乎是同一时间,重平衡是通过leave group请求触发的。
//源码:
public synchronized void maybeLeaveGroup() {
if (!this.coordinatorUnknown() && this.state != AbstractCoordinator.MemberState.UNJOINED && this.generation != AbstractCoordinator.Generation.NO_GENERATION) {
this.log.debug("Sending LeaveGroup request to coordinator {}", this.coordinator);
org.apache.kafka.common.requests.LeaveGroupRequest.Builder request = new org.apache.kafka.common.requests.LeaveGroupRequest.Builder(this.groupId, this.generation.memberId);
this.client.send(this.coordinator, request).compose(new AbstractCoordinator.LeaveGroupResponseHandler());
this.client.pollNoWakeup();
}
this.resetGeneration();
}
server:
[2022-01-25 10:38:47,274] DEBUG[GroupCoordinator 0]: Member consumer22-d183389d-9c9d-4f76-9da3-2162f0144923 in group g1 has left, removing it from the group (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 22:02:33,080] INFO [GroupCoordinator 0]: Preparing to rebalance group group-1 with old generation 17 (__consumer_offsets-49) (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 22:02:33,272] INFO [GroupCoordinator 0]: Stabilized group group-1 generation 18 (__consumer_offsets-49) (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 22:02:33,274] INFO [GroupCoordinator 0]: Assignment received from leader for group group-1 for generation 18 (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 22:02:45,544] INFO [GroupMetadataManager brokerId=0] Removed 0 expired offsets in 8 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
client:
2021-12-19 22:02:33: close
从源码看 close与unsubscribe都会调用maybeLeaveGroup 向服务端发送离开组的请求,但实际上只有close走的才是handleLeaveGroup处理逻辑,unsubscribe 后心跳线程也会停止,导致最终是由心跳触发重平衡。
6.客户端进程异常退出:
client:
[2021-12-19 21:25:38,412] INFO [GroupCoordinator 0]: Member consumer-1-3903ffdf-b59a-4e33-bb7b-5287afd4812c in group group-1 has failed, removing it from the group (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 21:25:38,412] INFO [GroupCoordinator 0]: Preparing to rebalance group group-1 with old generation 5 (__consumer_offsets-49) (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 21:25:40,868] INFO [GroupCoordinator 0]: Stabilized group group-1 generation 6 (__consumer_offsets-49) (kafka.coordinator.group.GroupCoordinator)
[2021-12-19 21:25:40,869] INFO [GroupCoordinator 0]: Assignment received from leader for group group-1 for generation 6 (kafka.coordinator.group.GroupCoordinator)
server:
[2021-12-19 21:25:40,867] INFO Revoking previously assigned partitions [test6-1] for group group-1 (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
[2021-12-19 21:25:40,867] INFO (Re-)joining group group-1 (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
[2021-12-19 21:25:40,870] INFO Successfully joined group group-1 with generation 6 (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
将会多消费一个分区
[2021-12-19 21:25:40,871] INFO Setting newly assigned partitions [test6-1, test6-0] for group group-1 (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator)
小结:
重平衡期间会无法消费,应尽量减少重平衡的次数和时间;
- 应避免业务逻辑处理时间过长。
- 网络波动较大的环境可以增加session.timeout.ms或者减少heartbeat.interval.ms,增加心跳检查的次数。
- 减少客户端的重启。
排查问题时服务端日志若无明显的错误提示可能是以下三种情况,有成员新加入组、客户端主动调用close、业务处理超时;业务处理超时会重平衡时间会劣化为maxpollinterval。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号