数据采集作业3 102302111 海米沙
第三次作业
作业1:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
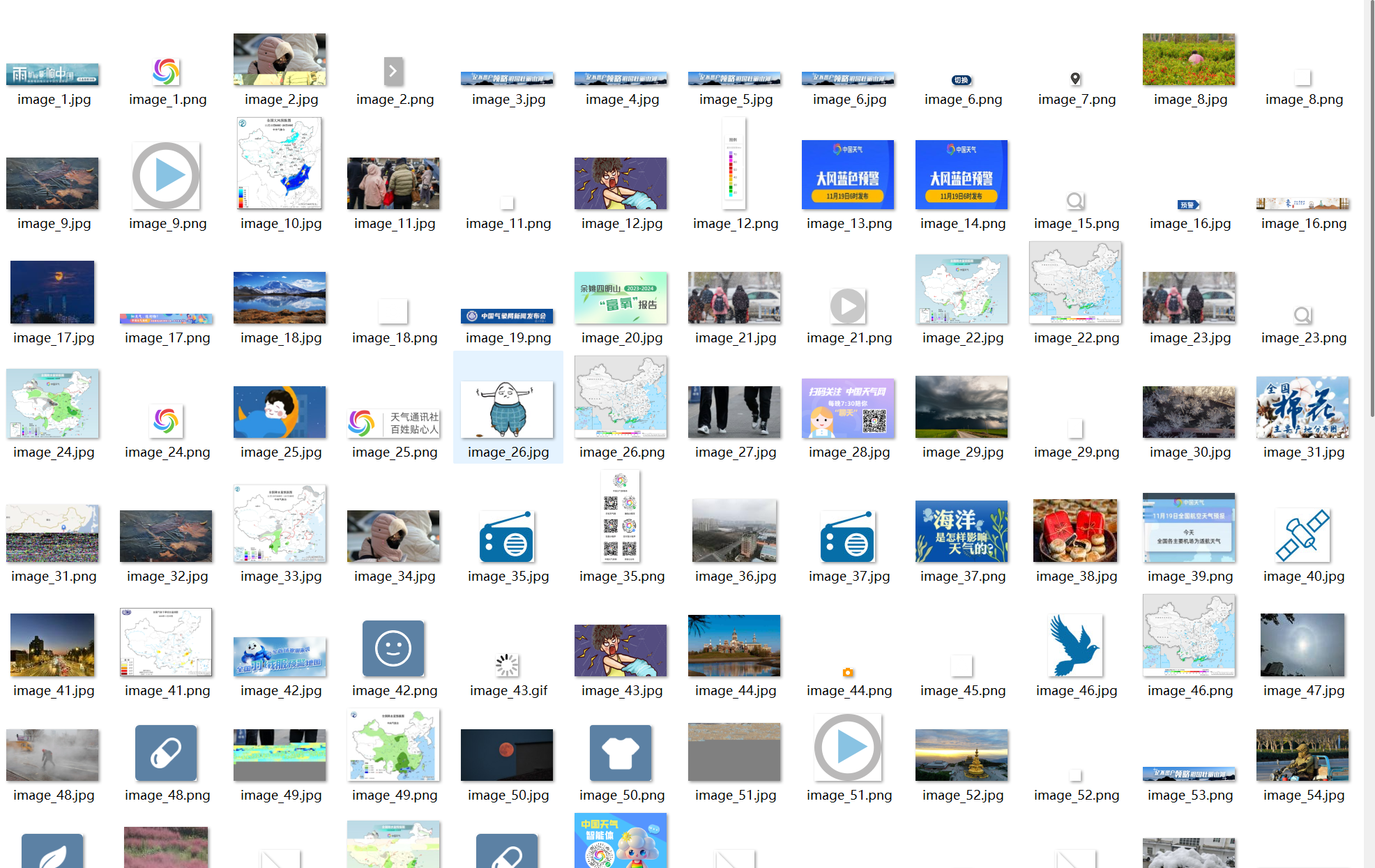
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee文件夹链接:https://gitee.com/haimisha/2025_creat_project/tree/master/作业三/第一题
代码(单线程):
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
IMAGE_DIR = r"D:\数据采集\实践课\实验作业三\images"
os.makedirs(IMAGE_DIR, exist_ok=True)
# 控制:总页数 11,总图片数 111
MAX_PAGES = 11 # 总共爬取 11 个页面
MAX_IMAGES = 111 # 总共下载 111 张图片
downloaded_count = 0
TARGET_PAGES = [
"http://www.weather.com.cn/",
"http://www.weather.com.cn/weather/101010100.shtml", # 北京
"http://www.weather.com.cn/weather/101020100.shtml", # 上海
"http://www.weather.com.cn/weather/101280101.shtml", # 广州
"http://www.weather.com.cn/weather/101270101.shtml", # 成都
"http://www.weather.com.cn/news/",
"http://www.weather.com.cn/jrxw/",
"http://www.weather.com.cn/zt/",
"http://www.weather.com.cn/satellite/",
"http://www.weather.com.cn/radar/",
"http://www.weather.com.cn/weather40d/101010100.shtml", # 北京40天
]
def download_image(img_url):
global downloaded_count
try:
resp = requests.get(img_url, stream=True, timeout=10)
if resp.status_code == 200:
ext = img_url.split('.')[-1].split('?')[0].lower()
if ext not in ['jpg', 'jpeg', 'png', 'gif', 'bmp', 'webp']:
ext = 'jpg' # 默认
filename = f"image_{downloaded_count + 1}.{ext}"
filepath = os.path.join(IMAGE_DIR, filename)
with open(filepath, 'wb') as f:
for chunk in resp.iter_content(1024):
f.write(chunk)
print(f"[下载成功] {img_url} -> {filename}")
downloaded_count += 1
return True
except Exception as e:
print(f"[下载失败] {img_url} : {e}")
return False
def scrape_images_from_page(url):
global downloaded_count
if downloaded_count >= MAX_IMAGES:
return
print(f"\n 正在访问页面: {url}")
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
resp = requests.get(url, headers=headers, timeout=10)
soup = BeautifulSoup(resp.text, 'html.parser')
imgs = soup.find_all('img')
for img in imgs:
src = img.get('src')
if not src:
continue
src = urljoin(url, src) # 补全相对链接
if any(ext in src.lower() for ext in ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp']):
if download_image(src):
if downloaded_count >= MAX_IMAGES:
print("已达到目标图片数量 111,停止下载。")
return
except Exception as e:
print(f"[页面出错] {url} : {e}")
def main():
for i, page_url in enumerate(TARGET_PAGES):
if downloaded_count >= MAX_IMAGES:
break
print(f"\n正在处理第 {i+1}/{MAX_PAGES} 个页面")
scrape_images_from_page(page_url)
print(f"\n共下载了 {downloaded_count} 张图片,保存在 {IMAGE_DIR}")
if __name__ == '__main__':
main()
运行结果:
代码(多线程):
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, as_completed
IMAGE_DIR = r"D:\数据采集\实践课\实验作业三\images"
os.makedirs(IMAGE_DIR, exist_ok=True)
# 爬取限制
MAX_PAGES = 11 # 总共爬取 11 个页面
MAX_IMAGES = 111 # 总共下载 111 张图片
downloaded_count = 0
TARGET_PAGES = [
"http://www.weather.com.cn/", # 首页
"http://www.weather.com.cn/weather/101010100.shtml", # 北京
"http://www.weather.com.cn/weather/101020100.shtml", # 上海
"http://www.weather.com.cn/weather/101280101.shtml", # 广州
"http://www.weather.com.cn/weather/101270101.shtml", # 成都
"http://www.weather.com.cn/news/", # 天气新闻
"http://www.weather.com.cn/jrxw/", # 气象新闻
"http://www.weather.com.cn/zt/", # 专题
"http://www.weather.com.cn/satellite/", # 卫星云图(可能有图)
"http://www.weather.com.cn/radar/", # 雷达图
"http://www.weather.com.cn/weather40d/101010100.shtml", # 北京40天预报
]
def download_image(img_url):
global downloaded_count
if downloaded_count >= MAX_IMAGES:
return None
try:
headers = {'User-Agent': 'Mozilla/5.0'}
resp = requests.get(img_url, stream=True, headers=headers, timeout=10)
if resp.status_code == 200:
# 判断图片格式
ext = img_url.split('.')[-1].split('?')[0].lower()
if ext not in ['jpg', 'jpeg', 'png', 'gif', 'bmp', 'webp']:
ext = 'jpg' # 默认
filename = f"image_{downloaded_count + 1}.{ext}"
filepath = os.path.join(IMAGE_DIR, filename)
with open(filepath, 'wb') as f:
for chunk in resp.iter_content(1024):
f.write(chunk)
print(f"[多线程下载成功] {img_url} -> {filename}")
downloaded_count += 1
return img_url
except Exception as e:
print(f"[多线程下载失败] {img_url}: {e}")
return None
def extract_and_queue_images_from_page(page_url):
global downloaded_count
if downloaded_count >= MAX_IMAGES:
return []
print(f"\n [多线程] 正在访问页面: {page_url}")
try:
headers = {'User-Agent': 'Mozilla/5.0'}
resp = requests.get(page_url, headers=headers, timeout=10)
soup = BeautifulSoup(resp.text, 'html.parser')
img_tags = soup.find_all('img')
urls = []
for img in img_tags:
src = img.get('src')
if not src:
continue
full_url = urljoin(page_url, src)
if any(ext in full_url.lower() for ext in ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp']):
urls.append(full_url)
return urls
except Exception as e:
print(f"[多线程页面错误] {page_url}: {e}")
return []
def main():
global downloaded_count
all_image_urls = []
# Step 1: 从 11 个页面提取所有图片 URL
for page_url in TARGET_PAGES:
if downloaded_count >= MAX_IMAGES:
break
print(f"\n [多线程] 正在处理第 {TARGET_PAGES.index(page_url)+1}/{MAX_PAGES} 个页面: {page_url}")
urls = extract_and_queue_images_from_page(page_url)
all_image_urls.extend(urls)
# Step 2: 去重
all_image_urls = list(set(all_image_urls)) # 去重
print(f"总共提取到 {len(all_image_urls)} 张候选图片,准备下载...")
# Step 3: 多线程下载(最多下载 MAX_IMAGES 张)
with ThreadPoolExecutor(max_workers=10) as executor:
futures = []
for url in all_image_urls:
if downloaded_count >= MAX_IMAGES:
break
futures.append(executor.submit(download_image, url))
# 等待所有任务完成(可选,用于调试)
for future in as_completed(futures):
future.result() # 可拿到返回值,这里只为了等待
print(f"\n[多线程] 下载完成!总共下载了 {downloaded_count} 张图片,保存在:{IMAGE_DIR}")
if __name__ == '__main__':
main()
运行结果:

作业2:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
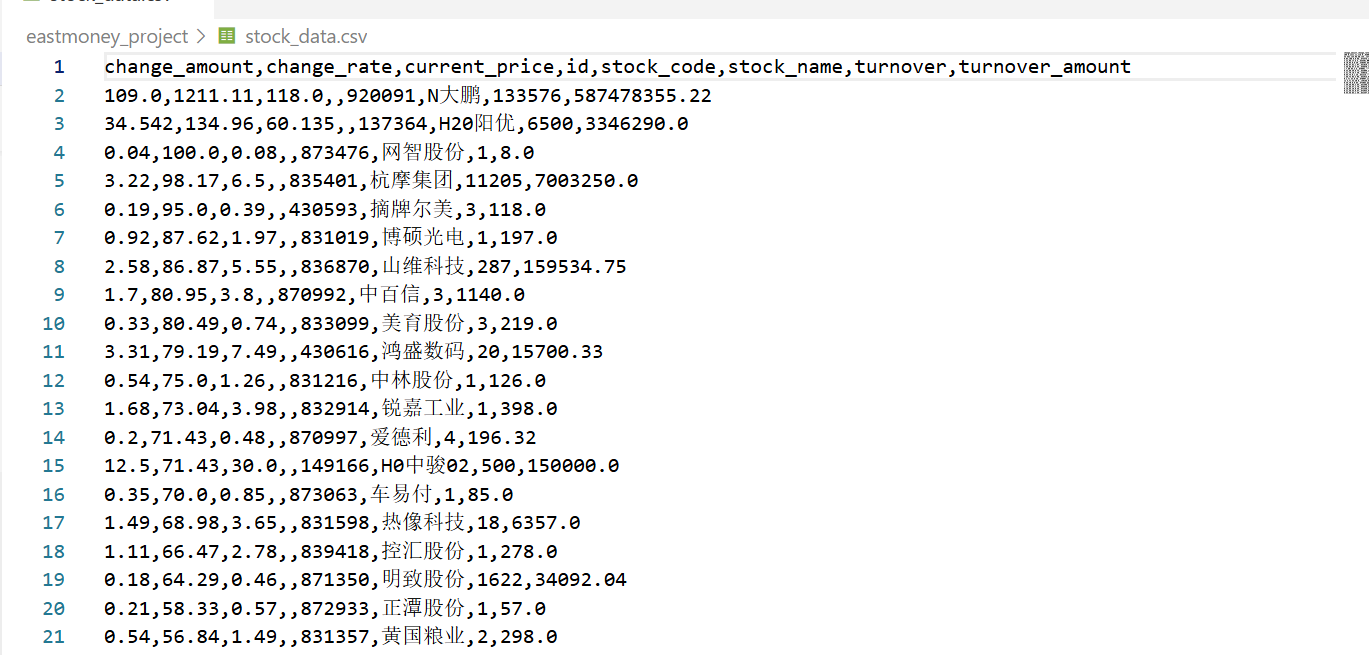
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
Gitee文件夹链接:https://gitee.com/haimisha/2025_creat_project/tree/master/作业三/第一题
代码:
items.py
点击查看代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class EastmoneyProjectItem(scrapy.Item):
id = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
current_price = scrapy.Field() # 当前价
change_amount = scrapy.Field() # 涨跌额
change_rate = scrapy.Field() # 涨跌幅(%)
turnover = scrapy.Field() # 成交量
turnover_amount = scrapy.Field() # 成交额
stockquote.py
点击查看代码
import scrapy
from eastmoney_project.items import EastmoneyProjectItem
import json
class StockquoteSpider(scrapy.Spider):
name = 'stockquote'
allowed_domains = ['push2.eastmoney.com', 'quote.eastmoney.com']
def start_requests(self):
base_url = "http://push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1', # 页码
'pz': '20', # 每页数量
'po': '1',
'np': '1',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f12,f14' # 指定要返回的字段
}
# 将参数拼接成URL
url = base_url + '?' + '&'.join([f'{k}={v}' for k, v in params.items()])
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 解析API返回的JSON数据
data = json.loads(response.text)
# 从JSON数据中提取股票列表,具体路径需要根据实际返回结构分析
stock_list = data['data']['diff']
for stock in stock_list:
item = EastmoneyProjectItem()
# 将JSON字段映射到我们自定义的Item字段
item['stock_code'] = stock.get('f12') # 例如f12对应代码
item['stock_name'] = stock.get('f14') # 例如f14对应名称
item['current_price'] = stock.get('f2') # 当前价
item['change_rate'] = stock.get('f3') # 涨跌幅
item['change_amount'] = stock.get('f4') # 涨跌额
item['turnover'] = stock.get('f5') # 成交量
item['turnover_amount'] = stock.get('f6') # 成交额
# ... 其他字段映射
yield item
pipelines.py
点击查看代码
import pymysql
class EastmoneyProjectPipeline:
def __init__(self):
self.conn = None
self.cursor = None
def open_spider(self, spider):
# 爬虫启动时建立数据库连接
self.conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
database='eastmoney',
charset='utf8mb4'
)
self.cursor = self.conn.cursor()
def close_spider(self, spider):
# 爬虫关闭时关闭数据库连接
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
def process_item(self, item, spider):
# 处理每一个Item,将其插入数据库
sql = """
INSERT INTO stock_data (stock_code, stock_name, current_price, change_amount, change_rate, turnover, turnover_amount)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
values = (
item['stock_code'],
item['stock_name'],
item['current_price'],
item['change_amount'],
item['change_rate'],
item['turnover'],
item['turnover_amount']
)
try:
self.cursor.execute(sql, values)
self.conn.commit() # 提交事务
except Exception as e:
self.conn.rollback() # 发生错误时回滚
print(f"数据库插入错误: {e}")
return item
点击查看代码
# Scrapy settings for eastmoney_project project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "eastmoney_project"
SPIDER_MODULES = ["eastmoney_project.spiders"]
NEWSPIDER_MODULE = "eastmoney_project.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "eastmoney_project (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "eastmoney_project.middlewares.EastmoneyProjectSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "eastmoney_project.middlewares.EastmoneyProjectDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"eastmoney_project.pipelines.EastmoneyProjectPipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
运行结果:
作业3:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
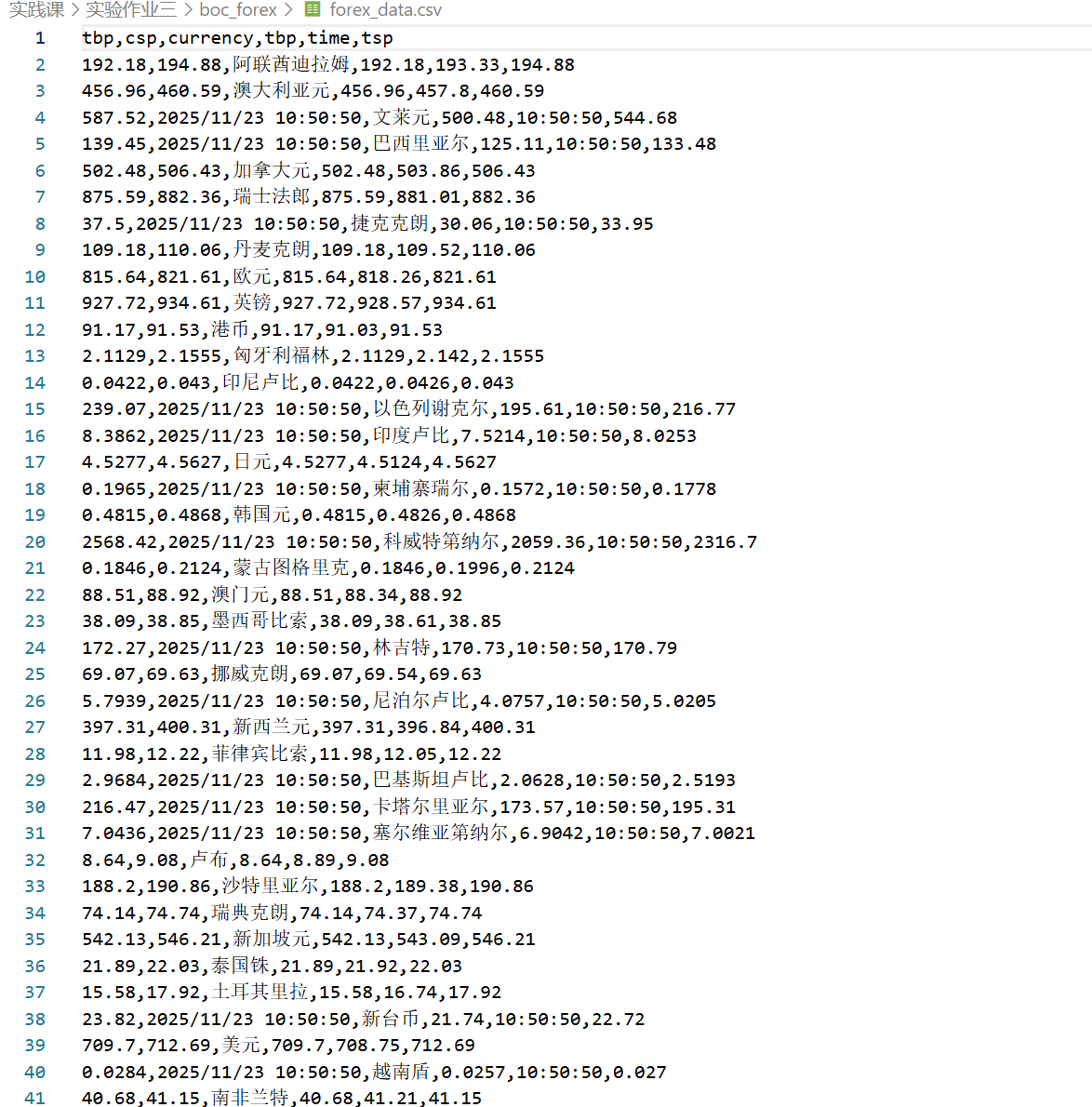
输出信息:
Gitee文件夹链接:https://gitee.com/haimisha/2025_creat_project/tree/master/作业三/第三题
代码内容:
items.py
点击查看代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BocForexItem(scrapy.Item):
currency = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价
cbp = scrapy.Field() # 现钞买入价
tsp = scrapy.Field() # 现汇卖出价
csp = scrapy.Field() # 现钞卖出价
time = scrapy.Field() # 发布时间
forex.spider.py
点击查看代码
import scrapy
from boc_forex.items import BocForexItem
class ForexSpiderSpider(scrapy.Spider):
name = 'forex_spider'
allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
self.logger.info(f"开始解析页面: {response.url}")
# 使用更精确的 XPath 定位表格行(已验证可正常工作)
rows = response.xpath('//div[@class="publish"]//table//tr')
self.logger.info(f"找到 {len(rows)} 行数据")
# 跳过表头(第一行),遍历其余数据行
for i, row in enumerate(rows[1:]):
try:
# 提取当前行所有单元格的文本内容
cells = row.xpath('./td//text()').getall()
# 清理文本:去除空字符串和前后空格
cells = [cell.strip() for cell in cells if cell.strip()]
self.logger.info(f"第 {i+1} 行数据: {cells}")
# 确保提取到足够的列数据(至少 6 列)
if len(cells) >= 6:
item = BocForexItem()
item['currency'] = cells[0] # 货币名称
item['tbp'] = cells[1] # 现汇买入价
item['cbp'] = cells[2] # 现钞买入价
item['tsp'] = cells[3] # 现汇卖出价
item['csp'] = cells[4] # 现钞卖出价
item['time'] = cells[5] # 发布时间
yield item
else:
self.logger.warning(f"第 {i+1} 行数据不完整(仅 {len(cells)} 列),已跳过")
except Exception as e:
self.logger.error(f"解析第 {i+1} 行时出错: {str(e)}", exc_info=True)
pipelines.py
点击查看代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
class BocForexPipeline:
def __init__(self):
self.conn = None
self.cursor = None
def open_spider(self, spider):
# 数据库连接配置
self.conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
database='boc_forex',
charset='utf8mb4'
)
self.cursor = self.conn.cursor()
def close_spider(self, spider):
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
def process_item(self, item, spider):
sql = """
INSERT INTO forex_data (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
values = (
item.get('currency'),
item.get('tbp'),
item.get('cbp'),
item.get('tsp'),
item.get('csp'),
item.get('time')
)
try:
self.cursor.execute(sql, values)
self.conn.commit()
except Exception as e:
self.conn.rollback()
print(f"数据库插入错误: {e}")
return item
点击查看代码
# Scrapy settings for boc_forex project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "boc_forex"
SPIDER_MODULES = ["boc_forex.spiders"]
NEWSPIDER_MODULE = "boc_forex.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "boc_forex (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "boc_forex.middlewares.BocForexSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "boc_forex.middlewares.BocForexDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"boc_forex.pipelines.BocForexPipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
运行结果:
心得体会:数据提取环节,我深刻体会到XPath选择器的重要性。最初,我写的XPath路径经常无法准确定位到目标数据,通过浏览器开发者工具反复调试和测试,才最终找到了稳定的定位方式。特别是在处理中国银行外汇牌价表格时,需要仔细分析HTML结构,跳过表头行,才能准确提取每条外汇记录的货币名称、买入价、卖出价等字段这次数据采集实践作业让我深刻体会到理论知识与实际应用之间的距离,以及跨越这段距离带来的成长。Scrapy框架的强大功能与MySQL数据库的稳定存储相结合,为数据处理提供了完整的解决方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号