数据采集作业1 102302111 海米沙
作业一
1)用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息的实验
输出信息:
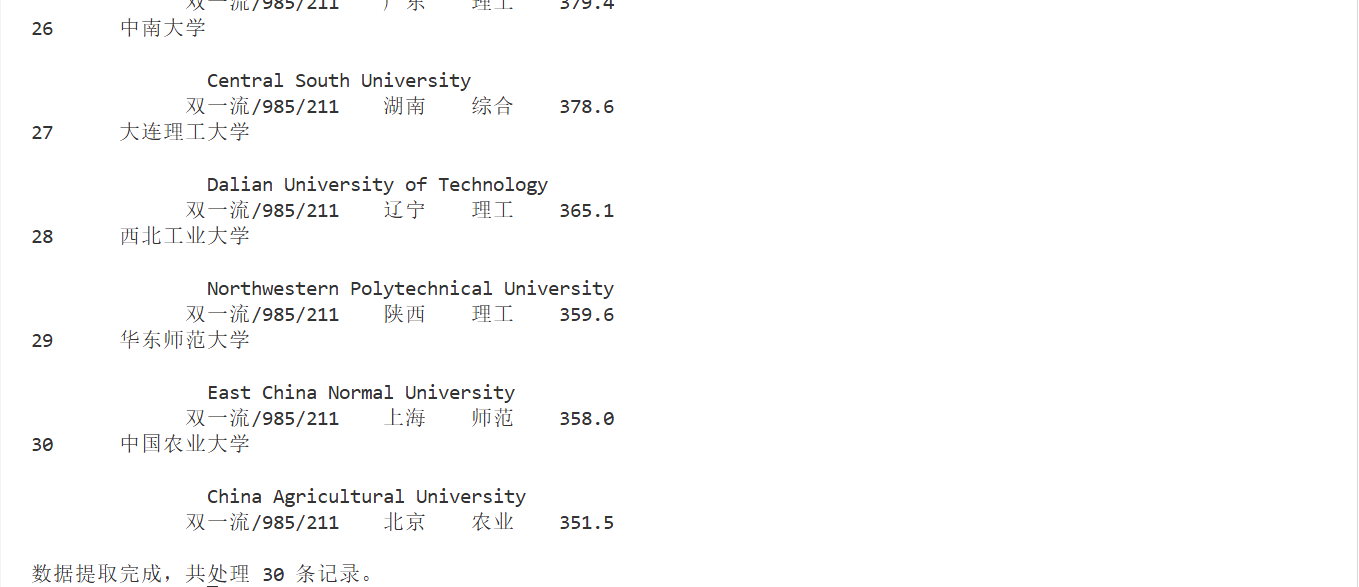
排名 学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5
2......
1.1 代码
点击查看代码
import requests
from bs4 import BeautifulSoup
def fetch_and_display_ranking():
"""
爬取软科2020年中国大学排名并格式化输出。
"""
target_url = "http://www.shanghairanking.cn/rankings/bcur/2020"
request_headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36',
}
print("开始尝试获取大学排名数据...")
# 使用 with 语句管理 session,确保资源被正确释放
with requests.Session() as session:
try:
response = session.get(target_url, headers=request_headers, timeout=(5, 10))
response.raise_for_status() # 如果状态码不是200,将抛出HTTPError异常
# 编码处理
response.encoding = response.apparent_encoding # 通常使用 apparent_encoding 即可
print("网页获取成功,解析内容中...")
soup_doc = BeautifulSoup(response.text, 'html.parser')
# 查找排名表格
ranking_table = soup_doc.find('table', class_='rk-table')
if ranking_table is None:
print("提示:未找到特定类别的表格,将尝试查找页面中的第一个表格。")
all_tables = soup_doc.find_all('table')
if not all_tables:
print("页面中未找到任何表格数据,请确认页面结构或网址是否正确。")
return None
ranking_table = all_tables[0]
print("已使用页面中的第一个表格。")
# 提取所有行
table_rows = ranking_table.find_all('tr')
if len(table_rows) <= 1: # 如果只有表头或无数据行
print("表格中未找到有效的数据行。")
return None
# 处理表头
header_row = table_rows[0]
headers = [th.get_text().strip() for th in header_row.find_all(['th', 'td'])]
if headers:
print("\t".join(headers))
else:
# 如果没有显式的表头,使用我们预设的
print("排名\t学校名称\t省市\t学校类型\t总分")
# 遍历数据行(从第二行开始)
data_count = 0
for row in table_rows[1:]:
columns = row.find_all('td')
# 确保有足够的列数,并且第一列是数字(排名)
if len(columns) >= 5 and columns[0].get_text().strip().isdigit():
try:
rank_num = columns[0].get_text().strip()
uni_name = columns[1].get_text().strip()
uni_location = columns[2].get_text().strip()
uni_category = columns[3].get_text().strip()
total_score = columns[4].get_text().strip()
print(f"{rank_num}\t{uni_name}\t{uni_location}\t{uni_category}\t{total_score}")
data_count += 1
except IndexError as e:
print(f"解析行数据时出现错误,跳过该行: {e}")
continue
print(f"\n数据提取完成,共处理 {data_count} 条记录。")
return data_count
except requests.exceptions.Timeout:
print("网络请求超时,请检查网络连接或稍后重试。")
return None
except requests.exceptions.ConnectionError:
print("网络连接错误,请检查网址是否正确或网络是否通畅。")
return None
except requests.exceptions.RequestException as err:
print(f"网络请求发生异常:{err}")
return None
# 主程序入口
if __name__ == "__main__":
fetch_and_display_ranking()
1.2 结果


2)心得体会
我深刻体会到结构化数据爬取中BeautifulSoup解析库的强大优势。在代码实现过程中,我最初遇到了表格定位不准确的问题,通过添加备用查找逻辑(先按特定class查找,失败后使用第一个表格),增强了程序的鲁棒性。使用with requests.Session()管理会话确保了网络资源的正确释放,这是从爬虫最佳实践中学习到的重要技巧。在数据提取环节,我注意到网页数据结构化程度高,但需要精细处理标签嵌套和文本清理。通过条件判断columns[0].get_text().strip().isdigit()确保只处理有效数据行,避免了空行或无效数据的干扰。异常处理机制的完善(超时、连接错误等)使得程序在网络不稳定环境下仍能优雅降级,这对生产环境应用至关重要。
这次实践让我认识到爬虫不仅是技术实现,更需要对数据源的尊重和合规使用。我在代码中设置了合理的请求头模拟浏览器行为,避免了给目标服务器带来过大压力,这符合爬虫伦理要求。
作业二
1)用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格的实验
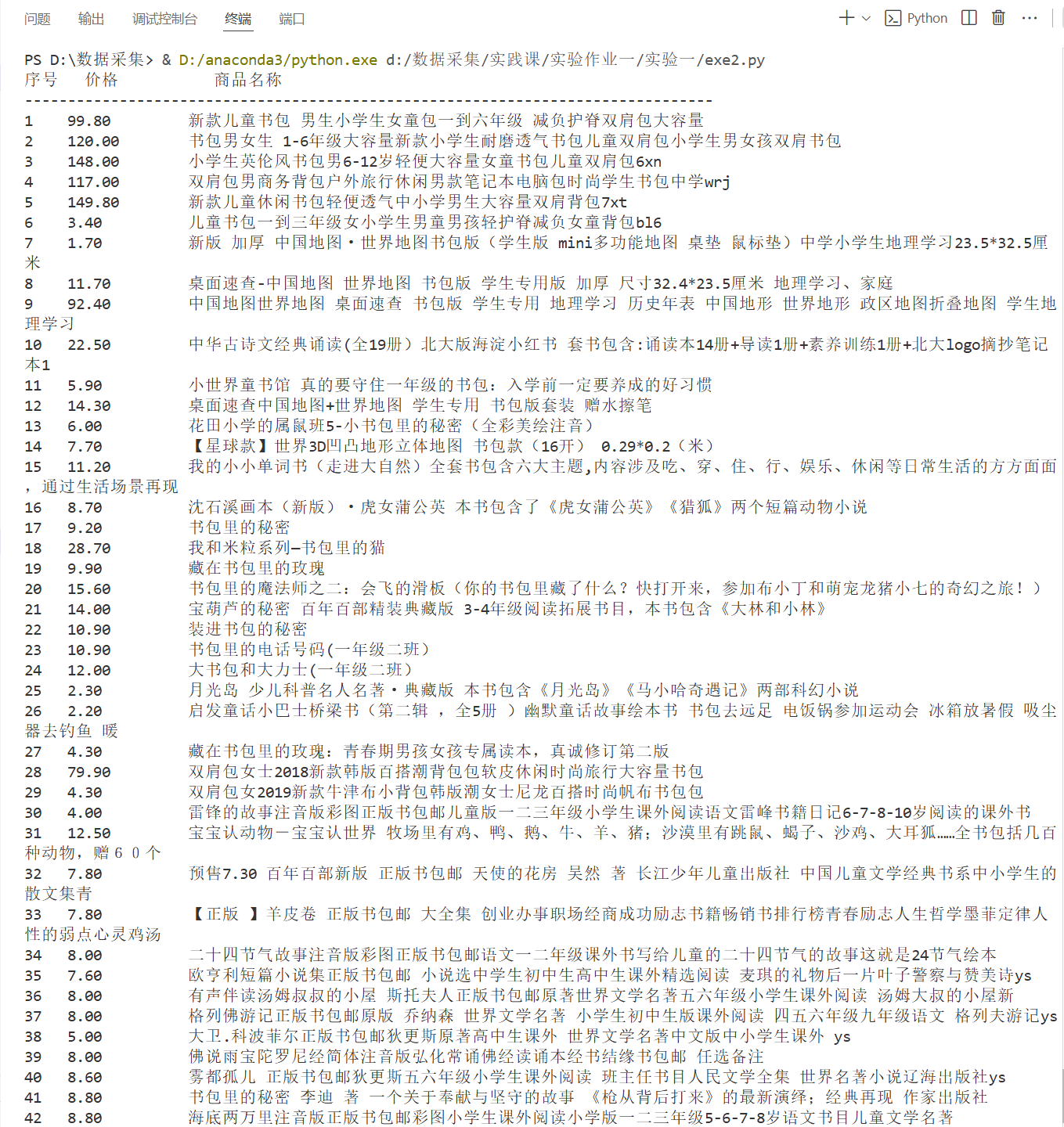
输出信息:
序号 价格 商品名
1 65.00 xxx
2......
2.1 代码
点击查看代码
import requests
import re
import chardet # 用于自动检测编码
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
# 使用更简单的URL
url = "http://search.dangdang.com/?key=书包"
try:
response = requests.get(url, headers=headers, timeout=10)
# 自动检测编码
encoding = chardet.detect(response.content)['encoding']
if encoding:
response.encoding = encoding
else:
# 如果检测失败,尝试常见编码
for enc in ['gbk', 'gb2312', 'utf-8', 'gb18030']:
try:
response.content.decode(enc)
response.encoding = enc
break
except:
continue
html = response.text
# 保存HTML到文件以便查看
with open('debug.html', 'w', encoding='utf-8') as f:
f.write(html)
# 方法1:直接匹配商品信息
pattern1 = r'<a\s+name="itemlist-title".*?title="([^"]+)".*?<span class="search_now_price">\s*¥\s*([\d.]+)\s*</span>'
products = re.findall(pattern1, html, re.DOTALL)
# 方法2:如果失败,尝试更宽松的匹配
if not products:
products = re.findall(r'title="([^"]+)".*?¥\s*([\d.]+)', html, re.DOTALL)
# 过滤掉明显不是商品的信息
products = [(name, price) for name, price in products if len(name) > 5 and '书包' in name]
# 输出结果
if products:
print(f"{'序号':<4} {'价格':<12} {'商品名称'}")
print("-" * 80)
for i, (name, price) in enumerate(products[:60], 1): # 限制前60个商品
print(f"{i:<4} {price:<12} {name}")
print(f"\n成功提取 {len(products)} 个商品")
else:
print("未找到商品信息,可能是页面结构已变化")
print("已保存HTML到debug.html文件,可用于分析页面结构")
except Exception as e:
print(f"发生错误: {e}")
if __name__ == "__main__":
main()
2.2 结果
2)心得体会
实验让我体验到正则表达式在非结构化数据提取中的灵活性与复杂性。面对商城页面动态加载元素和复杂HTML结构,我用了多种匹配模式组合的策略。初始严格模式(pattern1)针对特定标签结构,备用宽松模式作为降级方案,这种分层处理方法有效提升了数据捕获率。编码检测环节(使用chardet库)解决了中文字符乱码问题,这是爬虫开发中的常见挑战。通过保存HTML到本地文件进行调试,我得以分析实际页面结构与预期差异,这种问题定位方法在复杂爬虫任务中极为实用
正则表达式维护成本高的缺点也凸显出来。页面结构微小变动就可能导致匹配失败,相比BeautifulSoup的DOM解析方式,正则表达式更脆弱。未来项目中,我会优先考虑使用XPath或CSS选择器进行主要内容提取,正则表达式仅作辅助数据清洗。本次实践还让我认识到反爬虫机制的普遍性。商城网站可能采用动态加载、验证码等技术限制爬取,需要更高级技术如Selenium或模拟登录来解决。
作业三
1)爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件的实验
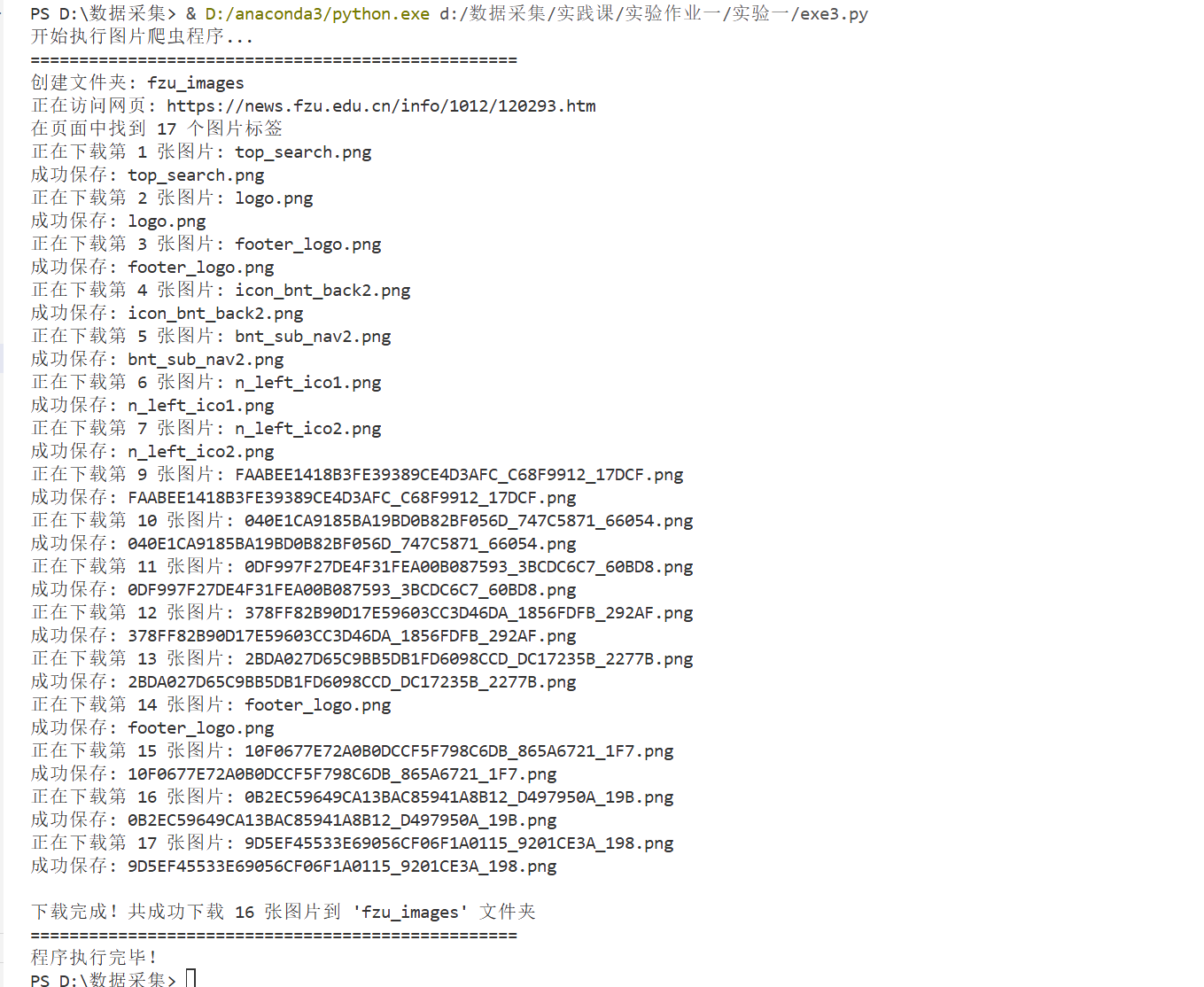
输出信息:将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
3.1 代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
from urllib.parse import urljoin, urlparse
import time
def download_images_from_url(target_url, save_folder='downloaded_images'):
"""
从指定URL下载所有JPEG、JPG、PNG格式的图片
参数:
target_url (str): 要爬取的目标网页URL
save_folder (str): 图片保存的文件夹路径
"""
# 创建保存图片的文件夹
if not os.path.exists(save_folder):
os.makedirs(save_folder)
print(f"创建文件夹: {save_folder}")
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
# 发送HTTP请求获取网页内容
print(f"正在访问网页: {target_url}")
response = requests.get(target_url, headers=headers, timeout=10)
response.raise_for_status() # 检查请求是否成功
response.encoding = 'utf-8' # 设置编码格式
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有的图片标签
img_tags = soup.find_all('img')
print(f"在页面中找到 {len(img_tags)} 个图片标签")
# 支持的图片格式
supported_formats = ('.jpg', '.jpeg', '.png', '.JPG', '.JPEG', '.PNG')
downloaded_count = 0
# 遍历所有图片标签并下载图片
for i, img_tag in enumerate(img_tags):
try:
# 获取图片的src属性
img_src = img_tag.get('src')
if not img_src:
continue
# 将相对URL转换为绝对URL
img_url = urljoin(target_url, img_src)
# 检查图片格式是否符合要求
if not img_url.lower().endswith(supported_formats):
continue
# 从URL中提取图片文件名
parsed_url = urlparse(img_url)
img_filename = os.path.basename(parsed_url.path)
# 如果文件名无效,生成一个基于索引的文件名
if not img_filename or '.' not in img_filename:
img_filename = f"image_{i+1}.jpg"
# 图片的完整保存路径
save_path = os.path.join(save_folder, img_filename)
# 下载图片
print(f"正在下载第 {i+1} 张图片: {img_filename}")
img_response = requests.get(img_url, headers=headers, timeout=10)
img_response.raise_for_status()
# 保存图片到本地
with open(save_path, 'wb') as f:
f.write(img_response.content)
downloaded_count += 1
print(f"成功保存: {img_filename}")
# 添加短暂延迟,避免请求过快
time.sleep(0.5)
except Exception as e:
print(f"下载第 {i+1} 张图片时出错: {e}")
continue
print(f"\n下载完成!共成功下载 {downloaded_count} 张图片到 '{save_folder}' 文件夹")
except requests.exceptions.RequestException as e:
print(f"网络请求错误: {e}")
except Exception as e:
print(f"程序执行错误: {e}")
def main():
"""
主函数:程序入口点
"""
# 目标网址 - 福州大学新闻网
target_url = "https://news.fzu.edu.cn/info/1012/120293.htm"
# 图片保存文件夹名称
save_folder = "fzu_images"
print("开始执行图片爬虫程序...")
print("=" * 50)
# 调用图片下载函数
download_images_from_url(target_url, save_folder)
print("=" * 50)
print("程序执行完毕!")
# 程序入口
if __name__ == "__main__":
main()
3.2 结果
2)心得体会
实验实现了网络资源的批量下载与本地化管理,让我对多媒体内容爬取有了深入认识。通过urljoin处理相对URL转换为绝对URL,解决了资源定位的核心问题。创建专用文件夹存储图片并自动处理文件名冲突,体现了文件管理的规范性。在实现过程中,我添加了请求间隔延迟(time.sleep(0.5)),这是遵守爬虫道德的重要实践,避免了短时间内高频请求对服务器造成压力。支持多种图片格式(JPEG、JPG、PNG)并统一处理大小写变体,增强了程序兼容性。异常处理的完整性是本项目的亮点。网络请求超时、图片下载失败等错误都被捕获并记录,而不中断整体流程,这种容错设计确保了批量操作的顺利完成。同时,我也意识到在实际应用中需要进一步考虑图片版权问题,仅将技术用于合法合规的个人学习目的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号