使用 python 把一个文件生成 C 语言中的数组并保存到头文件中 (2)
这是上一篇文件<<使用 python 把一个文件生成 C 语言中的数组并保存到头文件中>>续,
在测试的时候,突然发现了一个现象,就好像是一道光,给了我一个解决转换大文件慢的问题的灵感,这个现象是从转换率的变化率一开始很快然后开始变慢,如下:
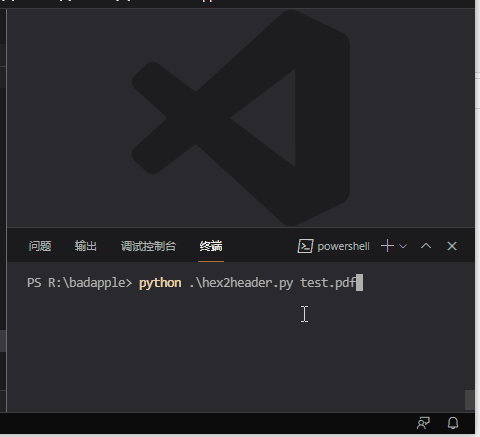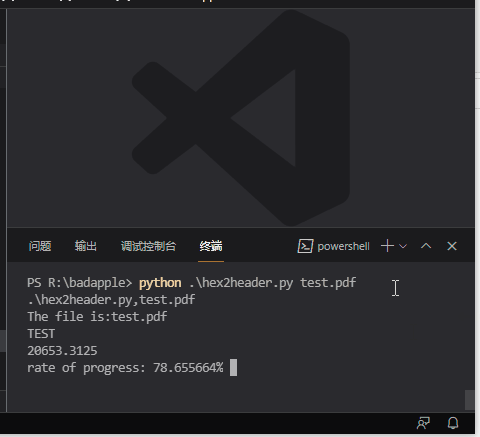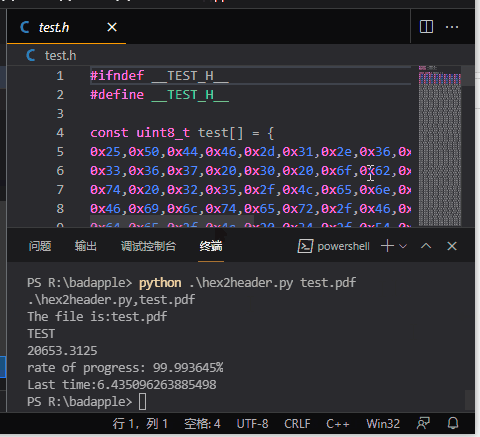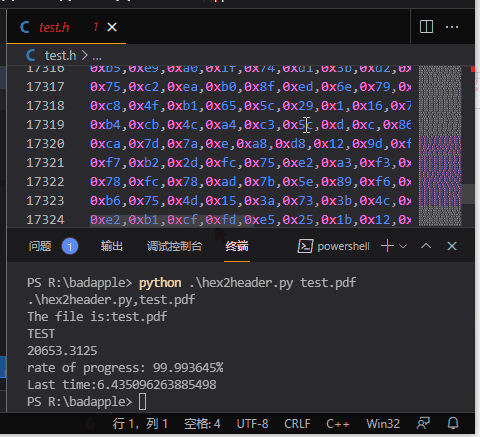
从上图看,转换到 60% 左右还很快,然后就变得很慢了。
目前得做法是,把转换出来得数据都放到一个字符串中,等转换结束后,一次性写入文件,上面看到转化率的过程,都是在读取、转换、添加到字符串,这 3 个步骤前 2 给都试过了,解决不了转换慢的问题,那会不会是在第 3 个步骤呢,
来、测试下,思路是每转换一定数量后,先保存进文件中,一直重复这 2 个步骤,直到转换完成。
首先,前面部分代码还是跟之前一样,先判断输入参数中是否包含待处理文件,及待处理文件是否存在:
if __name__ == "__main__":
if len(sys.argv) != 2:
print("argv is not 2")
exit()
print(sys.argv[0] + "," + sys.argv[1])
if os.path.exists(sys.argv[1]) is False:
print("file not exit")
exit()
start_time = time.time()
filepath = sys.argv[1]
print("The file is:" + sys.argv[1])
if "\\" in filepath:
filename = filepath.split("\\")[-1].split(".")[0]
else:
filename = filepath.split(".")[0]
filename_upper = filename.upper()
然后实现一个保存数据的函数:
def save_data2header(filename,dat):
path = filename + ".h"
file = open(path,"a+")
file.write(dat)
file.close()
因为把数据保存到文件中也是分开来的,每次写文件是往文件后面添加数据,所以打开文件时使用以 “a+” 方式打开,然后先把头文件前面部分写进文件:
header = "#ifndef __" + filename_upper + "_H__\n"
header = header + "#define __" + filename_upper + "_H__\n\n"
header = header + "const uint8_t " + filename + "[] = {\n"
save_data2header(filename,header)
然后是读取、转换、保存:
fileinfo = os.stat(filepath)
line = fileinfo.st_size / 16
target = ""
f = open(filepath, "rb")
count = 0
for l in range(int(line)):
for j in range(16):
data = f.read(1)
he = "0x" + data.hex()
target = target + he + ","
target = target + "\n"
count = count +1
if count == 1000:
save_data2header(filename,target)
count = 0
target = ""
print("\rrate of progress: %f%% " % (l *100 / line), end="")
save_data2header(filename,target)
f.close()
这里做法是没转换 1000 行就保存一次,最后添加头文件尾部、计算所花时间:
header_end = "};" + "\n#endif\n"
save_data2header(filename,header_end)
end_time = time.time()
print("\nLast time:",end="")
print(end_time - start_time)
运行结果如下:
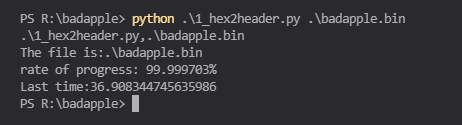
这一次居然才用了差不多 37 秒,算了下未优化前居然是这次的 825.5 倍:

实在是太让人震惊了。
这是什么原因呢?
想了下,之前的做法,时间是耗在了往 python 的字符变量添加数据上,这字符变量使用的是什么结构体,往字符变量上添加数据使用的是什么算法,也许搞懂了这些就知道原因在哪了。
本文来自博客园,作者:哈拎,转载请注明原文链接:https://www.cnblogs.com/halin/p/15013217.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号