

Datawhale - Pandas(下)--task01 数据缺失处理
一、因为电脑不是最新版本,先更新:pip install --upgrade pandas
二、感兴趣,或者今后可能会常用的操作:
1、(b)查看缺失值的所以在行 df[df['Physics'].isna()]
(c)挑选出所有非缺失值列 【使用all就是全部非缺失值,如果是any就是至少有一个不是缺失值】
2、三种缺失符号(例子很多,文字多看几遍,才能记住,总的说,所有缺失值默认都是np.nan,一旦操作就会变类型,如True变1.0等等)
(a)np.nan
np.nan是一个麻烦的东西,首先它不等与任何东西,甚至不等于自己;在用equals函数比较时,自动略过两侧全是np.nan的单元格,因此结果不会影响;其次,它在numpy中的类型为浮点,由此导致数据集读入时,即使原来是整数的列,只要有缺失值就会变为浮点型;此外,对于布尔类型的列表,如果是np.nan填充,那么它的值会自动变为True而不是False;但当修改一个布尔列表时,会改变列表类型,而不是赋值为True;在所有的表格读取后,无论列是存放什么类型的数据,默认的缺失值全为np.nan类型;因此整型列转为浮点;而字符由于无法转化为浮点,因此只能归并为object类型('O'),原来是浮点型的则类型不变
(b)None
None比前者稍微好些,至少它会等于自身,它的布尔值为False;修改布尔列表不会改变数据类型;在传入数值类型后,会自动变为np.nan ;只有当传入object类型是保持不动,几乎可以认为,除非人工命名None,它基本不会自动出现在Pandas中;在使用equals函数时不会被略过,因此下面的情况下返回False
(c)NaT
NaT是针对时间序列的缺失值,是Pandas的内置类型,可以完全看做时序版本的np.nan,与自己不等,且使用equals是也会被跳过
3、可以看,上面的内容很麻烦,一有改动就变化很大,如果考虑不清楚,会造成莫名其妙的错误。所以1.0版本后做了改进:
Nullable类型与NA符号
这是Pandas在1.0新版本中引入的重大改变,其目的就是为了(在若干版本后)解决之前出现的混乱局面,统一缺失值处理方法。
官方鼓励用户使用新的数据类型和缺失类型pd.NA
(a)Nullable整型
对于该种类型而言,它与原来标记int上的符号区别在于首字母大写:'Int';它的好处就在于,其中前面提到的三种缺失值都会被替换为统一的NA符号,且不改变数据类型
(b)string类型
该类型是1.0的一大创新,目的之一就是为了区分开原本含糊不清的object类型,这里将简要地提及string,因为它是第7章的主题内容;此外,和object类型的一点重要区别就在于,在调用字符方法后,string类型返回的是Nullable类型,object则会根据缺失类型和数据类型而改变
4、逻辑运算:如果结果依赖NA,就还是NA,不依赖那就看其他逻辑计算(理解了也很好记)
5、尽量用新版本的类型和功能。
6、加号与乘号规则【使用加法时,缺失值为0;使用乘法时,缺失值为1;使用累计函数时,缺失值自动略过】
groupby方法中有缺失值的行,会自动忽略
7、不理解的:
(b)limit_direction表示插值方向,可选forward,backward,both,默认前向
s = pd.Series([np.nan,np.nan,1,np.nan,np.nan,np.nan,5,np.nan,np.nan,])
s.interpolate(limit_direction='backward')
0 1.0
1 1.0
2 1.0
3 2.0
4 3.0
5 4.0
6 5.0
7 NaN
8 NaN
dtype: float64
三、问题:
【问题一】 如何删除缺失值占比超过25%的列?(计算sum(缺失值)/sum(列元素)> 25%, 就删除drop?)
【问题二】 什么是Nullable类型?请谈谈为什么要引入这个设计?(1.0版本,为了解决缺失值默认都是np.nan,一旦操作就会变类型等,造成数据不一致问题)
【问题三】 对于一份有缺失值的数据,可以采取哪些策略或方法深化对它的了解?(先找出缺失数据,分析对结果的影响,考虑数据剔除或者插值)
四、练习:
1. 最好在读数据时就转换为Nullable
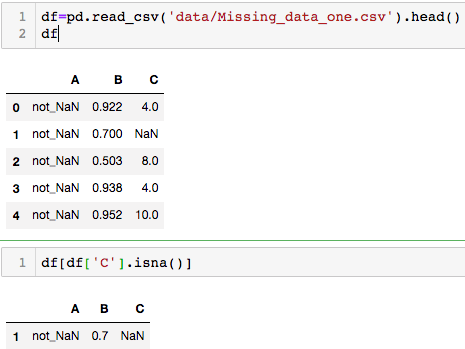
2. 题目开始不很理解,25%* B/min(B)没有想到。用zip 和 lamda 让语句更简洁
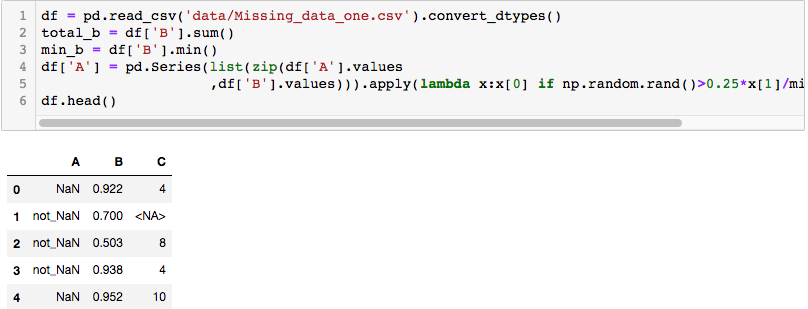
3. 缺失值占此列的比例:
df.isna().sum()/df.shape[0]
优秀的笔记:https://gitee.com/km601/joyful-pandas/tree/master/task6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号