
java集合类之ArrayList
list实现了collections接口, Collection接口继承了Iterator接口,继承Iterator接口的类可以使用迭代器遍历元素(即Collection接口的类都可以使用,list主要有3个实现类
ArrayList, LinkedList, Vector
先看下三者的主要联系和区别
1, ArrayList和Vector底层数据存储都是使用Object数组实现的, 基于数组存储的特点, 我们知道这两个兄弟都是查询速度快,增加/删除速度慢。 二者的主要区别在于:ArrayList线程不安全, 而Vector线程安全
(扩展知识--数组存储的特点? 数组存储地址是连续的,可以随机访问,所以在查询时, 根据索引就可以快速定位到数据的位置。 但执行增加/删除操作时, 为保证连续性, 操作结束后还需要对数组进行移位, 移位是非常昂贵的操作,试想, 对于一个长度为1000的数组, 如果我们现在要删除第3个元素, 删除之后还需要对后面的997个元素前移1位)
2, Vector虽然线程安全,但安全是有代价的,Vector中大部分方法都加了同步锁(synchronized), 所以整体访问速度要慢于ArrayList
3, ArrayList可以通过val list = Collections.synchronizedList(ArrayList<String>) 方法来实现线程安全
4, LinkedList底层使用双向链表存储, 所以它相对ArrayList/Vector来说, 查询速度较慢, 但增加/删除效率高。LinkedList也是线程不安全的
(扩展知识: 链表存储的特点? 链表存储地址是不连续的, 依靠指针来指示下一个元素的位置,所以它不能随机访问, 我们在执行查询操作时,需要遍历链表来找到相应元素的位置,所以相对数组存储,时间复杂度更高。 但是在插入/删除操作时, 只需要改变相邻元素的指针,所以效率高于数组)
(CPU缓存会把一片连续的内存空间读入,因为数组结构是连续的内存地址,所以数组全部或者部分元素被连续存在CPU缓存里面,平均读取每个元素的时间只要3个CPU时钟周期。 而链表的节点是分散在堆空间里面的,这时候CPU缓存帮不上忙,只能是去读取内存,平均读取时间需要100个CPU时钟周期。这样算下来,数组访问的速度比链表快33倍! (这里只是介绍概念,具体的数字因CPU而异)。)
- ArrayList详解
我们先来看下它的构造方法
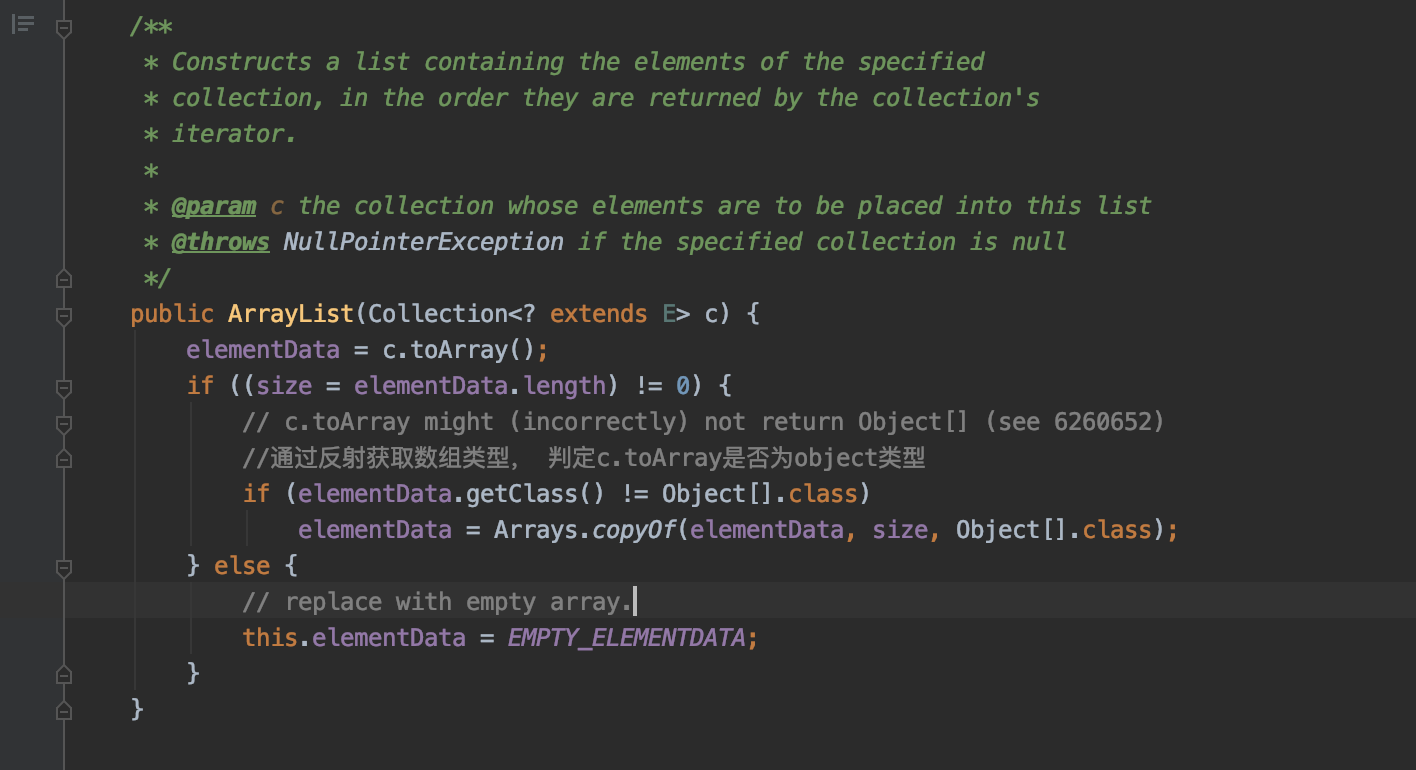
1)通过其他集合来创建arrayList
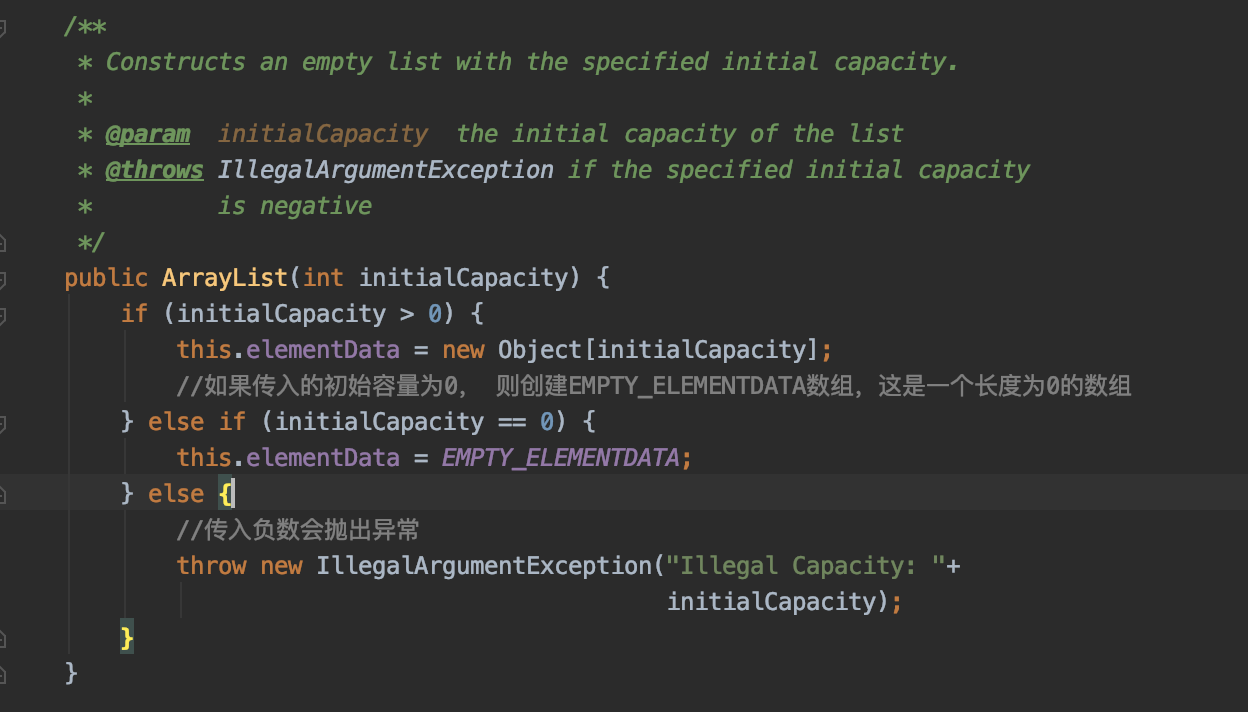
2)我们可以在构造方法中传入初始容量, 来得到一个指定初始容量的list
3)若我们不指定初始容量, 则初始容量为10
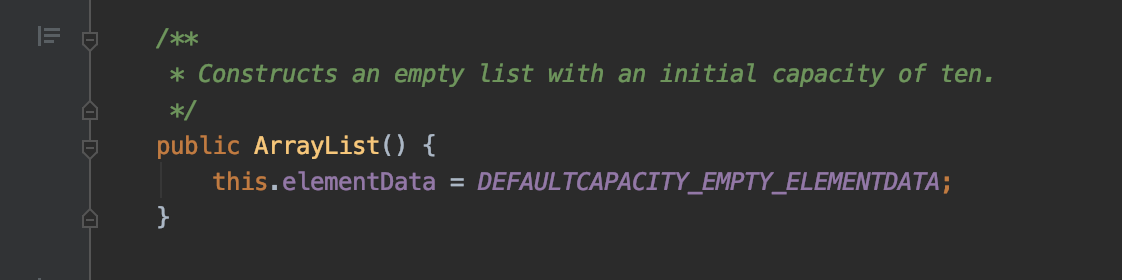
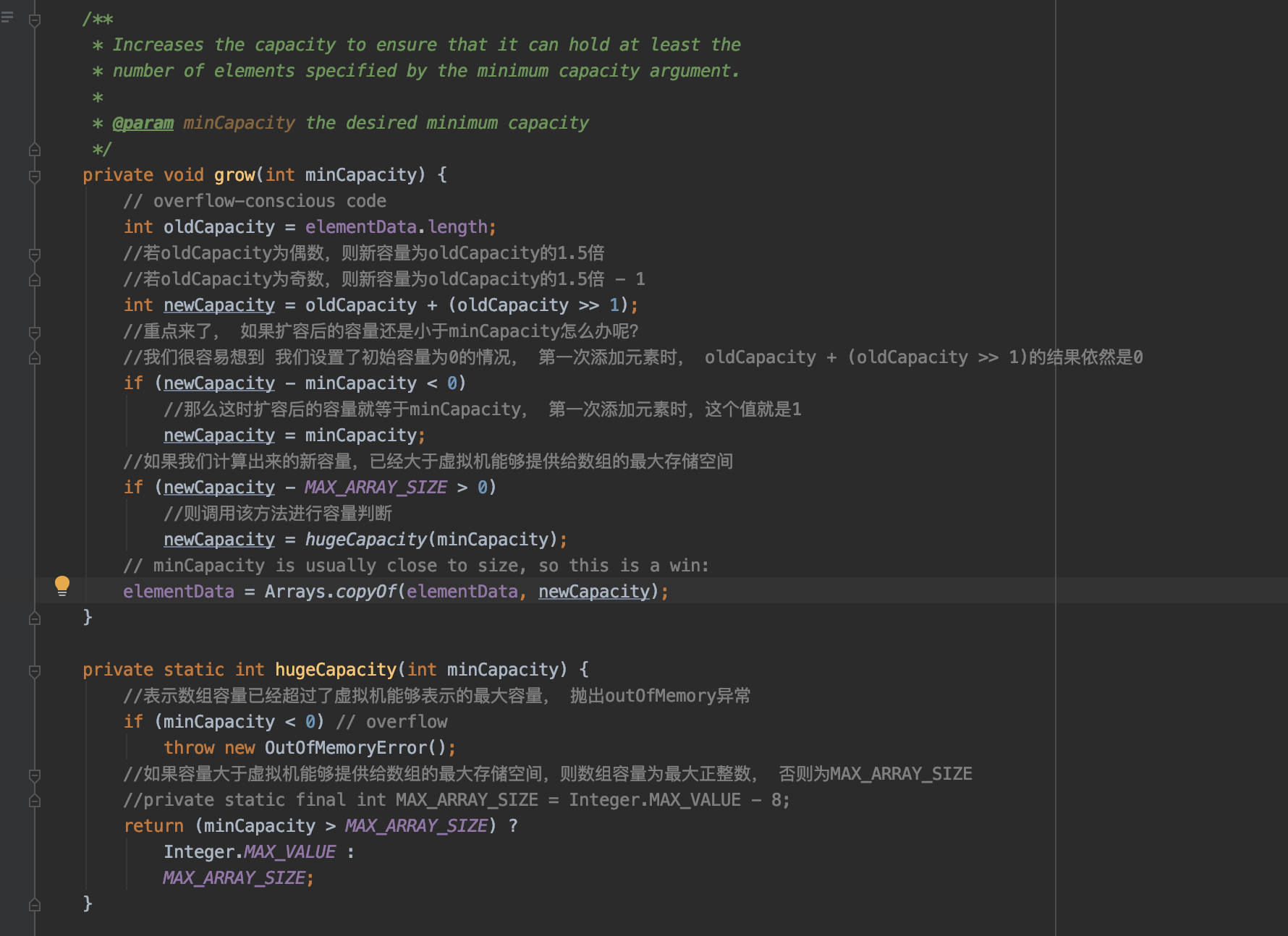
在源码中我们看到 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 和 EMPTY_ELEMENTDATA一样, 都被定义为一个空的数组, 那为什么说上面无参的构造方法会创建初始容量为10的数组呢???
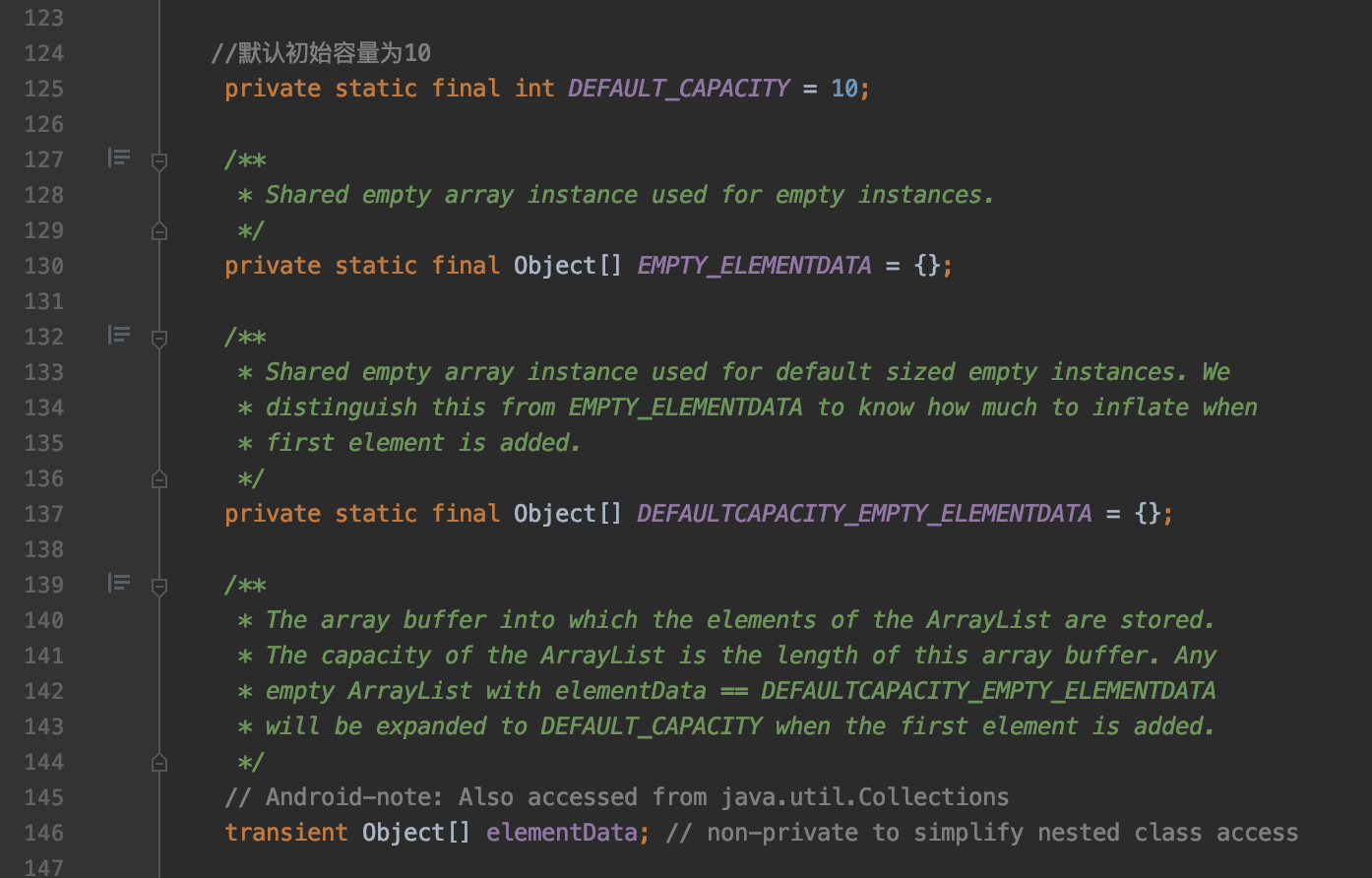
我们看elementDatad的注释:
Any empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA will be expanded to DEFAULT_CAPACITY when the first element is added
就是说当我们添加第一个元素时, 如果elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA, 那么数组就会被扩容为DEFAULT_CAPACITY, 也就是10
通过上面的代码我们可以知道:
a, 我们可以通过构造方法来创建一个arrayList对象
b, 使用无参构造方法创建对象时会生成一个空的数组, 当我们put第一个元素时, 会将数组扩容为10。这也是懒加载的一种体现。
c, 对于指定初始容量的构造方法, 创建对象时会生成一个指定长度的数组, 如果制定容量为0, 则创建EMPTY_ELEMENTDATA数组,长度也是0. 那么当我们put第一个元素时, 它也会将数组扩容为10吗? 带着这个问题, 我们来看下add方法
ArrayList的add方法有两种:
add(E e) 在数组末尾添加元素
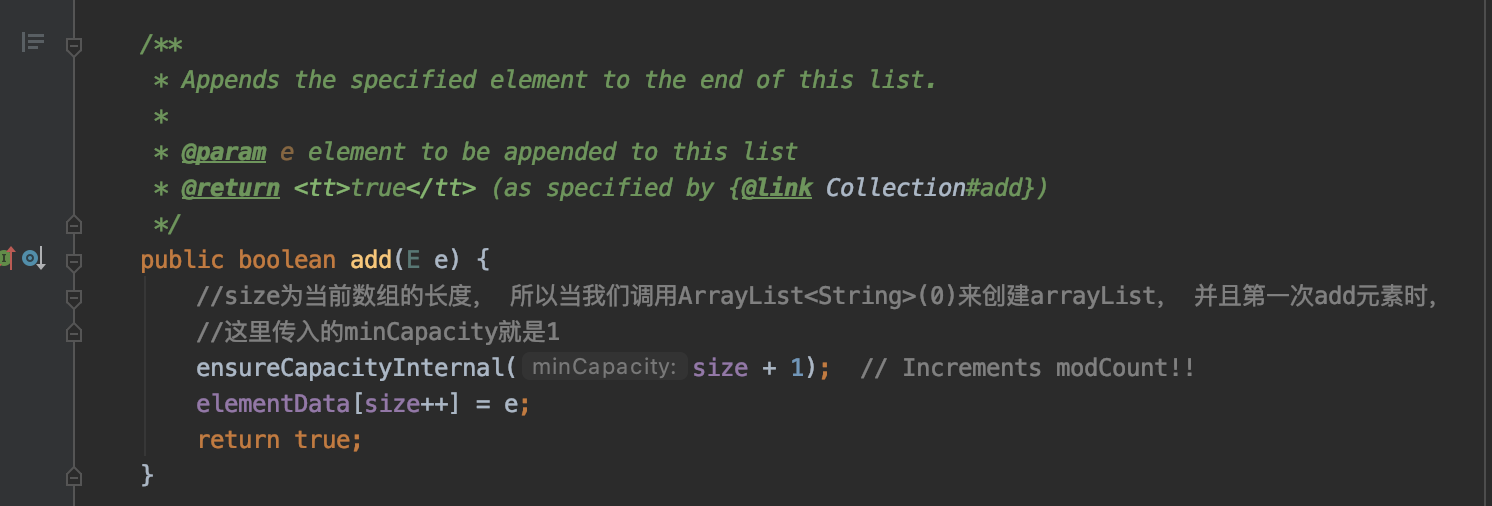

add(int index, E element) 在数组的指定位置添加元素
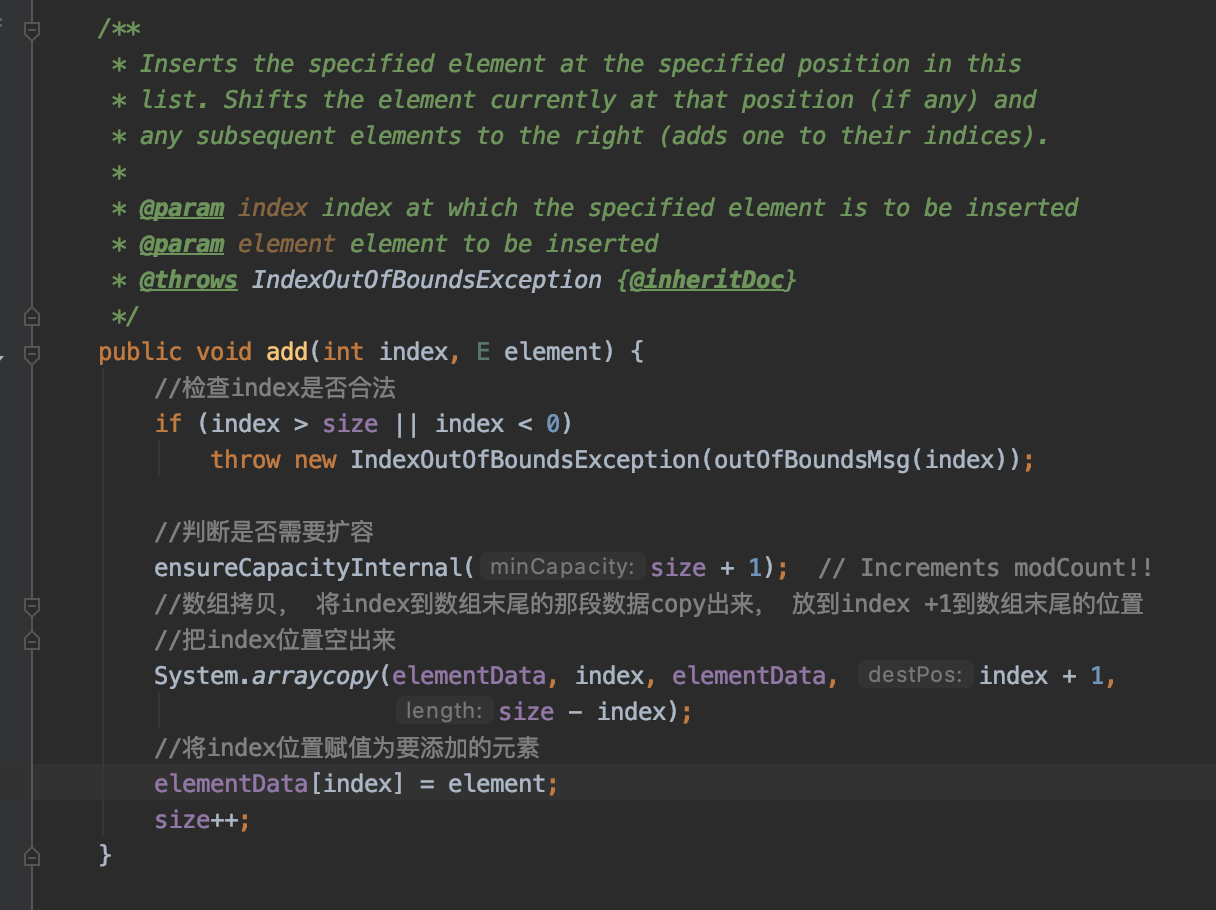
相对于上个方法直接在数组末尾添加元素, 这里多了一步操作就是移位, 这也是数组存储增加元素时时间复杂度高于链表的原因
ArrayList的remove方法也有两种:
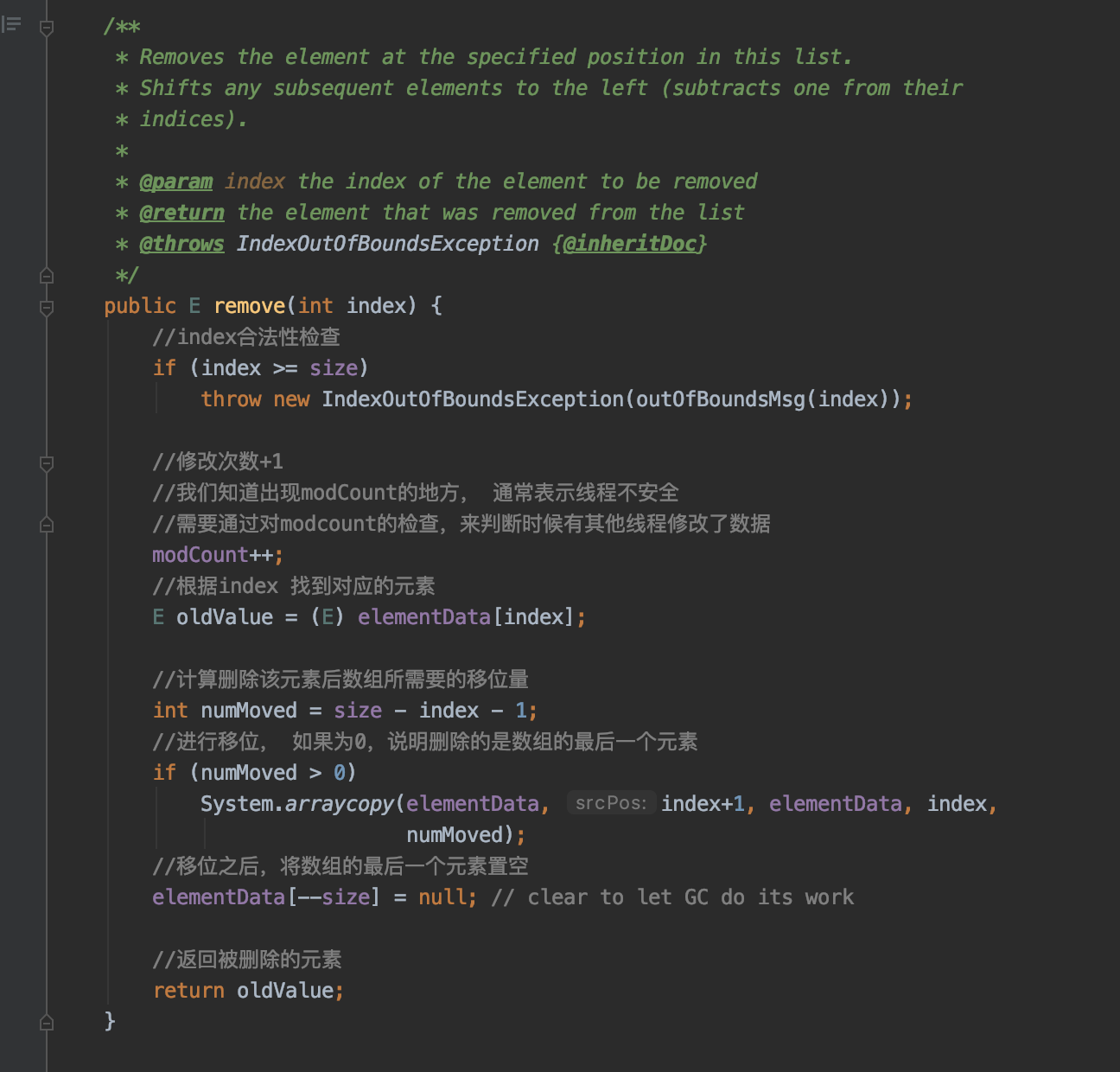
public E remove(int index)删除指定位置的元素
public boolean remove(Object o)删除数组中第一个指定元素
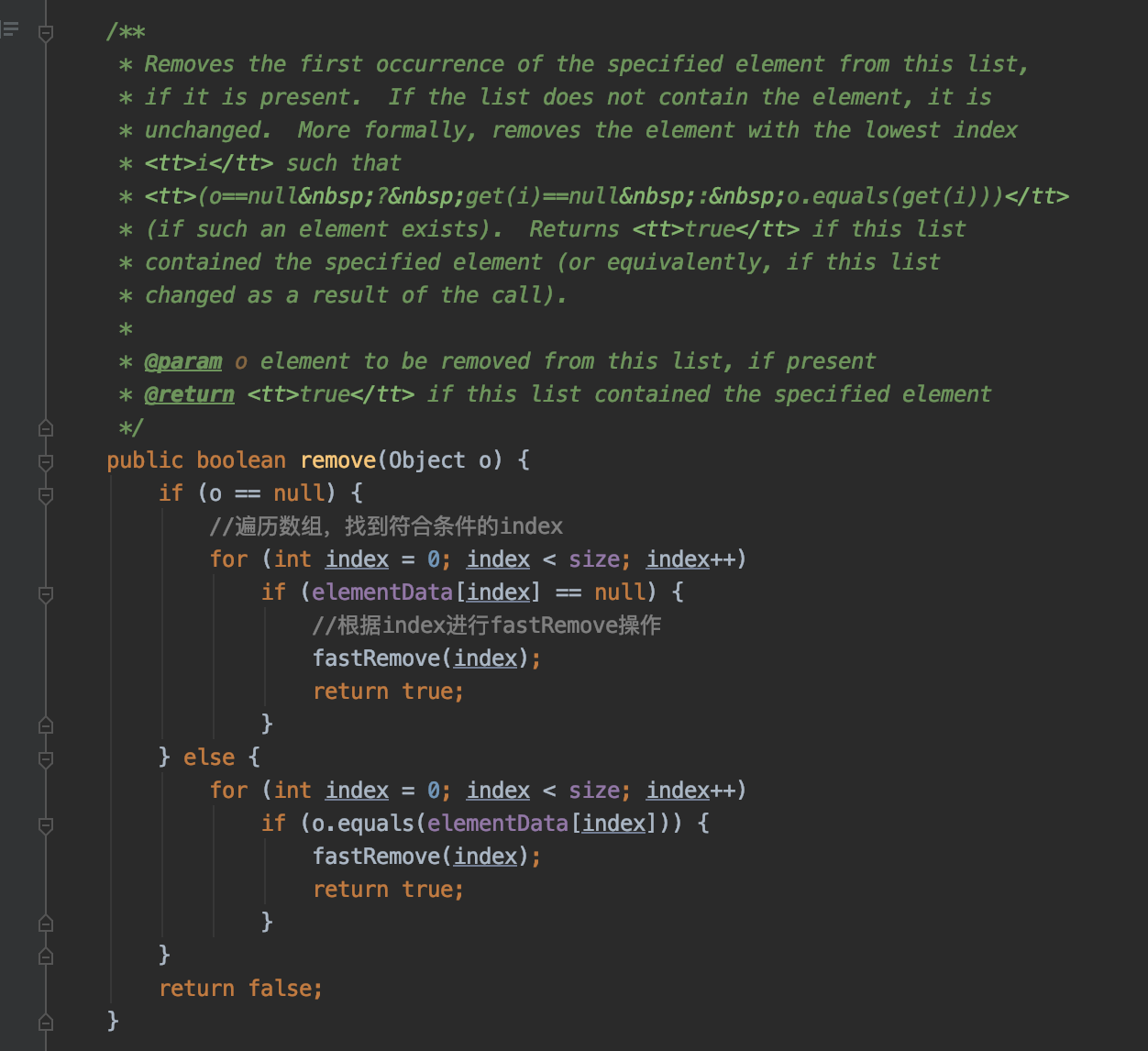
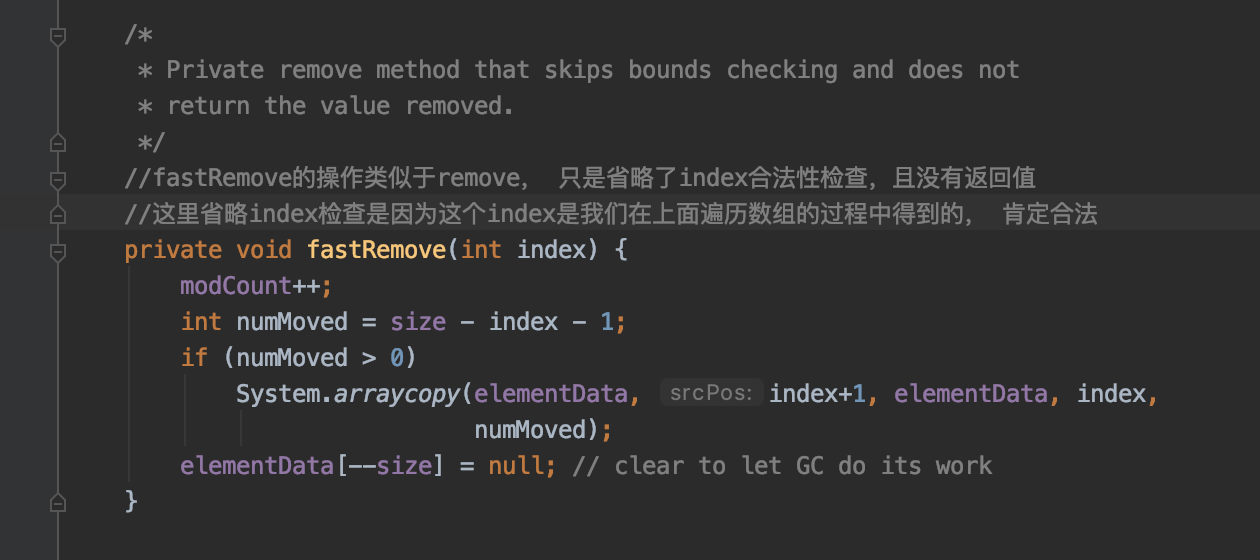
通过上面的代码我们可以知道:
remove( object)是比remove (index)更耗时的操作, 是因为它多了遍历数组的过程
remove(object) 分了object为null和不为null两种情况, 这说明arrayList是允许对象为null的
若数组中有多个相同的元素, 则每次只会remove第一个
ArrayList的其他方法:
public void clear() 删除数组中的全部元素, 可以看到也用到了遍历,逐个置空
trimToSize() 修改list的容量为当前的实际size
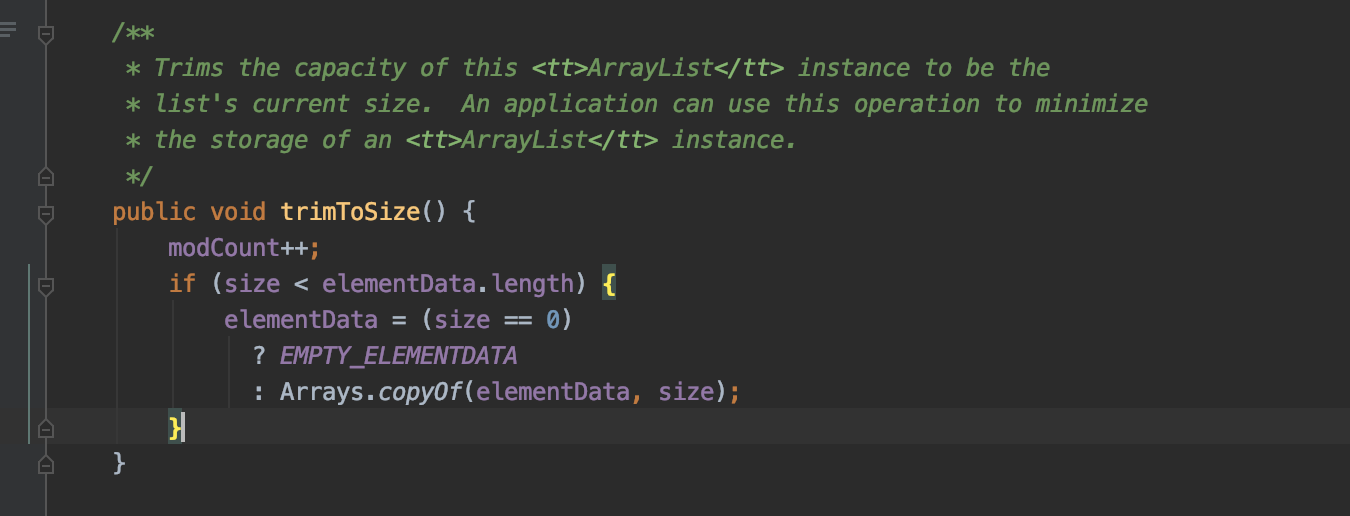
该方法的主要作用是, 当数组的初始容量被创建过大时, 我们可以调用该方法减少存储空间
public boolean contains(Object o)当前数组中是否包含某个object
public int indexOf(Object o)获取指定对象bject在数组中的第一个位置(如果相同对象在数组中出现多次的话)
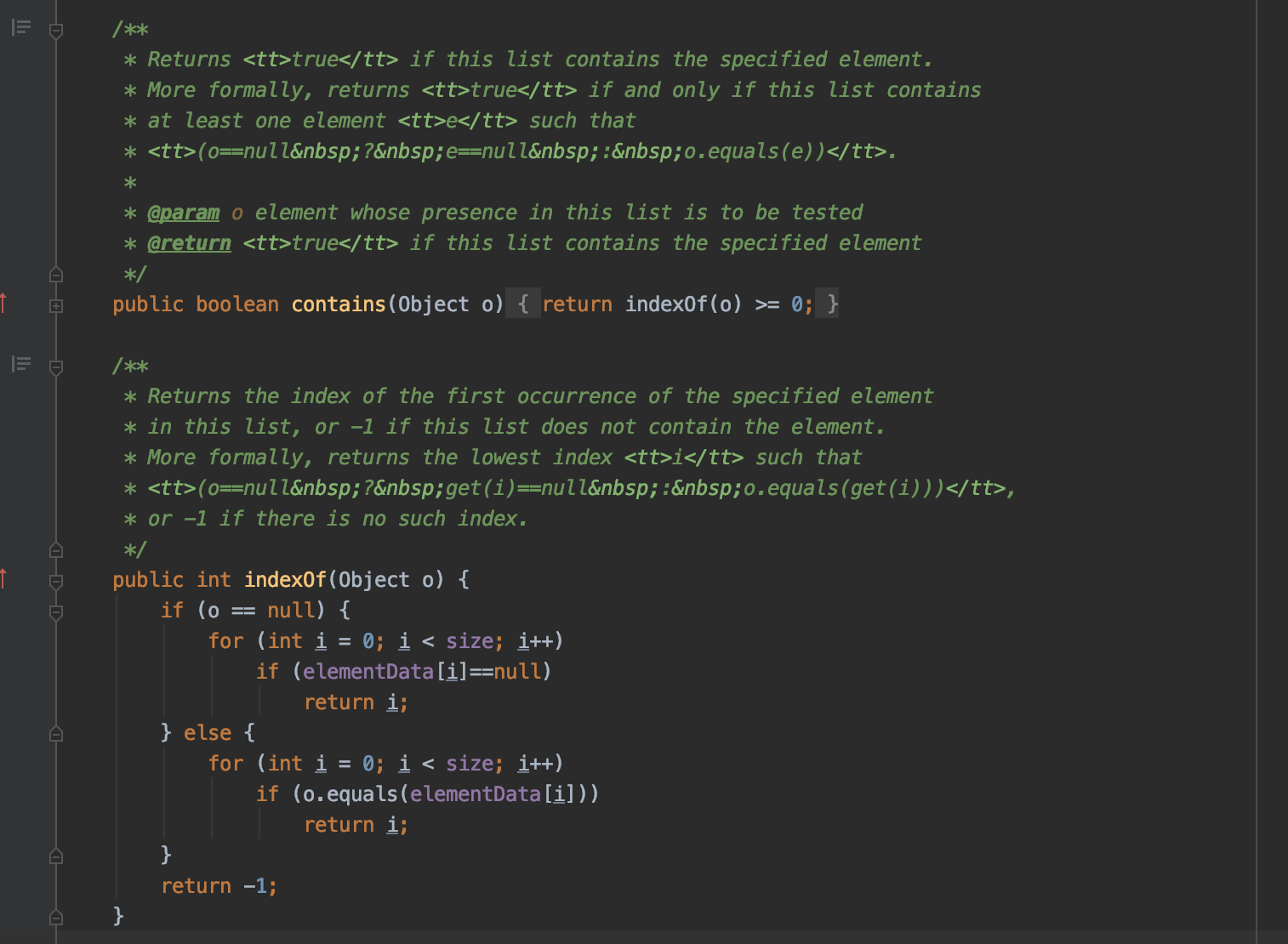
public int lastIndexOf(Object o)
获取指定对象bject在数组中的最后一个位置(如果相同对象在数组中出现多次的话),可以看到, 它是通过从后往前遍历去实现的
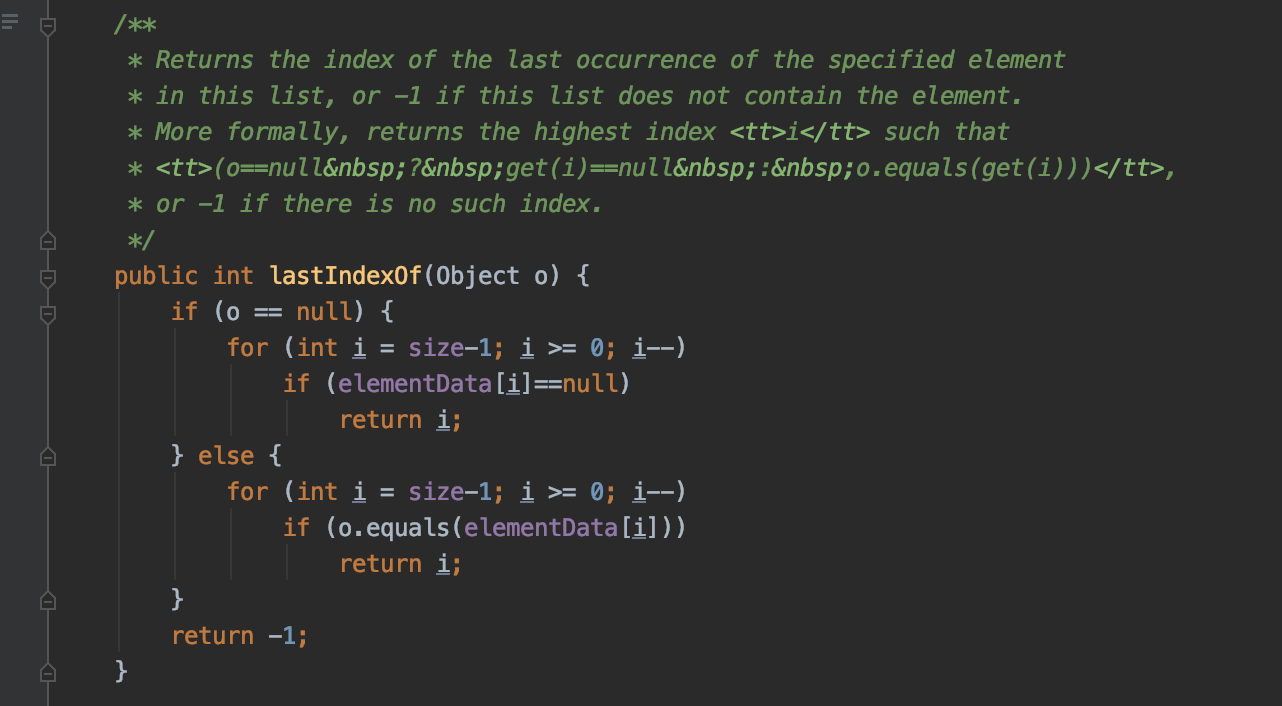
public void sort(Comparator<? super E> c) 对数组按指定规则进行排序
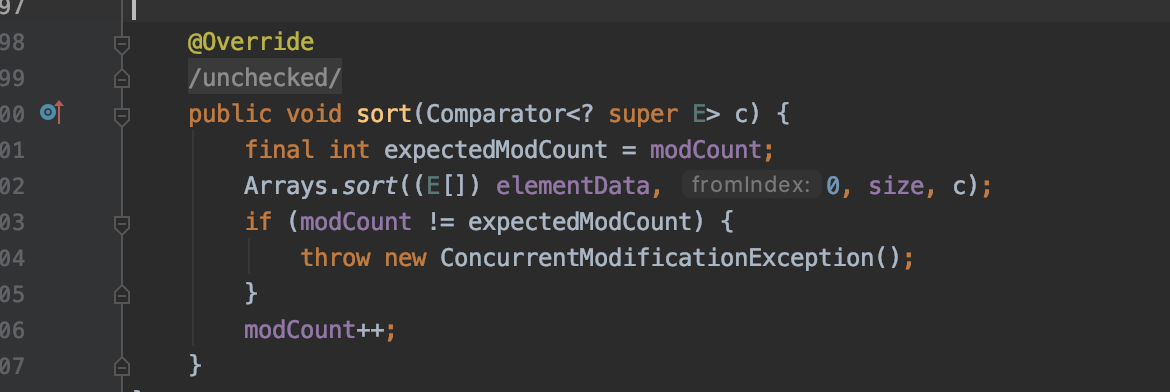
我们看到这里有override标签, 它其实是重写了clolections的sort方法。
public E set(int index, E element)将指定位置index的元素替换为新的元素
看到这个方法,我们忍不住会想它和add方法的区别, 我们知道add(E element)是在数组末尾添加元素, 比如一个size为3的数组, add会在index=3的位置添加元素
那么我们能不能set(3, object)呢?
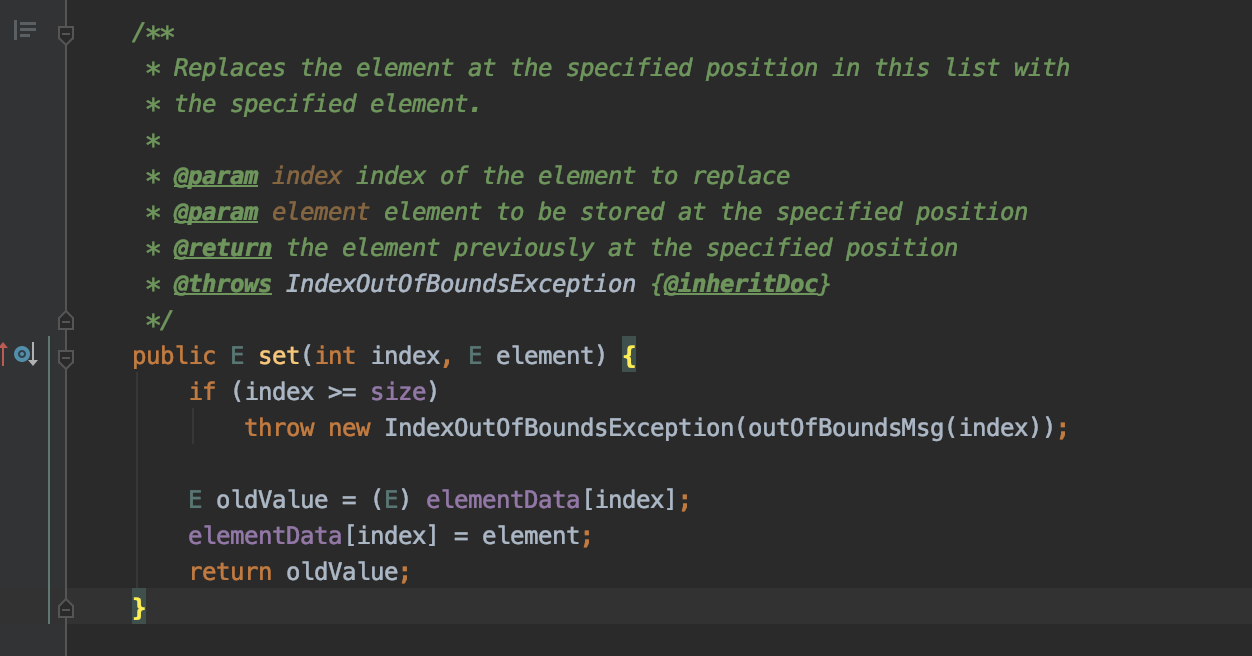
看到源码, 我们知道不可以, 因为set方法用于替换元素, 首先会进行index合法性检查, 如果index>=size, 就会抛出数组越界异常
fast-fail机制
在ArrayList源码中, 我们看到了大量的modCount++
我们知道这个变量的存在是为了快速失败, 那么具体在哪里做检查呢?
搜素源码发现, 在迭代器执行next(), add(), remove(), set(), writeObject()等方法时, 都会判断
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
我们知道ArrayList是线程不安全的, 那么怎么能实现线程安全呢?
1) Collections.synchronizedList(ArrayList<String>) 但是因为这个方法会给整个list加锁, 所以效率比较低
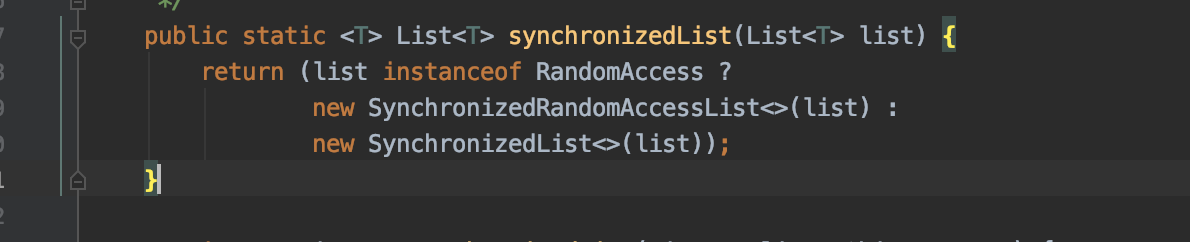
2) 使用CopyOnWriteArrayList来替换ArrayList (比较推荐)
它的功能和ArrayList相似,区别是它应用了读写分离的思想,读不加锁。对所有的可变操作(add, remove等)都加了synchronized(lock){}同步锁,所以是线程安全的
而且操作时会先复制数组,然后在复制的数组上进行修改,这样就不会影响到远数组中的数据, 修改完成后,改变原有数据的引用即可。
但是,因为要复制一份底层数组,所以对内存的占用比较多
所以, 它适用于并发情况下读多写少的应用场景
3) 使用古老的Vector
-------------------------------------------------------------------LinkedList--------------------------------------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号