

大数据之路【第十篇】:kafka消息系统
一、简介
1、简介
简 介
• Kafka是Linkedin于2010年12月份开源的消息系统
• 一种分布式的、基于发布/订阅的消息系统
2、特点
– 消息持久化:通过O(1)的磁盘数据结构提供数据的持久化
– 高吞吐量:每秒百万级的消息读写
– 分布式:扩展能力强
– 多客户端支持:java、php、python、c++ ……
– 实时性:生产者生产的message立即被消费者可见
3、基本组件
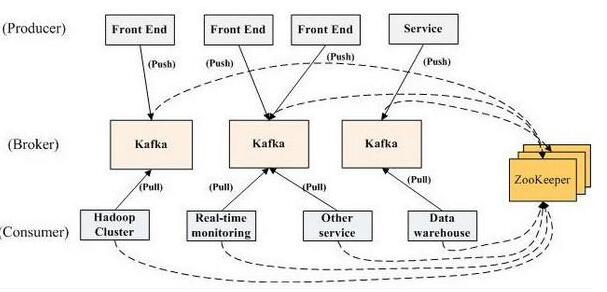
• Broker:每一台机器叫一个Broker
• Producer:日志消息生产者,用来写数据
• Consumer:消息的消费者,用来读数据
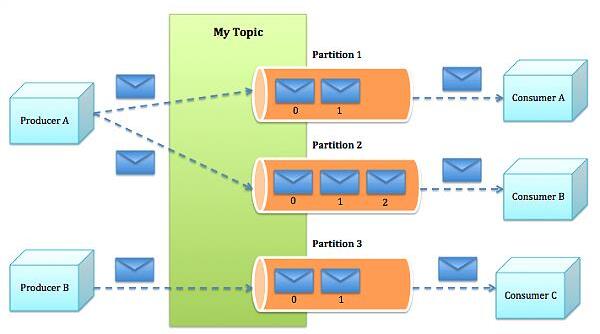
• Topic:不同消费者去指定的Topic中读,不同的生产者往不同的Topic中写
• Partition:新版本才支持Partition,在Topic基础上做了进一步区分分层
好处二:动态导入模块(基于反射当前模块成员)
注意:
• Kafka内部是分布式的、一个Kafka集群通常包括多个Broker
• 负载均衡:将Topic分成多个分区,每个Broker存储一个或多个Partition
• 多个Producer和Consumer同时生产和消费消息
4、Topic
• 一个Topic是一个用于发布消息的分类或feed名,kafka集群使用分区的日志,每个分区都是有顺序且不变的消息序列。
• commit的log可以不断追加。消息在每个分区中都分配了一个叫offset的id序列来唯一识别分区中的消息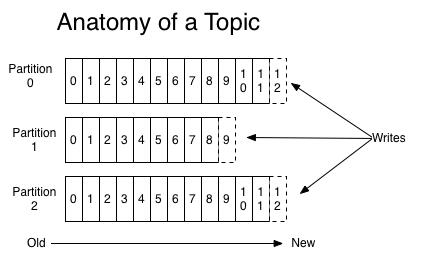
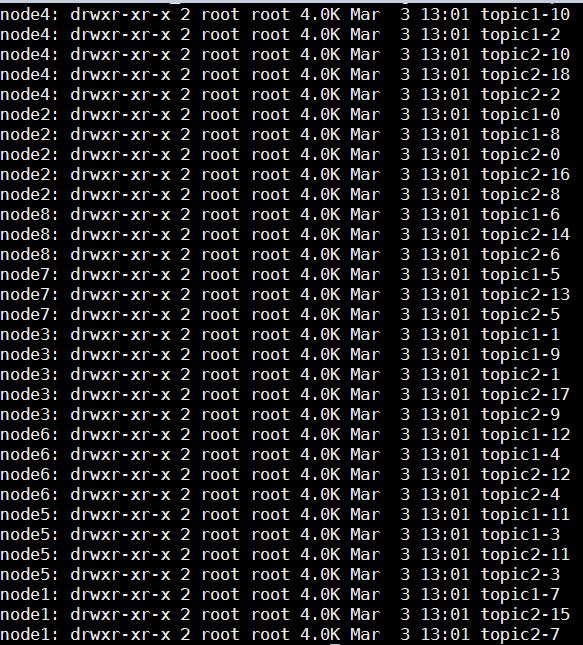
• 举例:若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个文件夹
注意:
• 无论发布的消息是否被消费,kafka都会持久化一定时间(可配置)。
• 在每个消费者都持久化这个offset在日志中。通常消费者读消息时会使offset值线性的增长,但实际上其位置是由消费者控制,它可以按任意顺序来消费消息。
比如复位到老的offset来重新处理。
• 每个分区代表一个并行单元。
5、Message
• message(消息)是通信的基本单位,每个producer可以向一个topic(主题) 发布一些消息。如果consumer订阅了这个主题,那么新发布的消息就会广播给 这些consumer。 • message format: – message length : 4 bytes (value: 1+4+n) – "magic" value : 1 byte – crc : 4 bytes – payload : n bytes
6、Producer
• 生产者可以发布数据到它指定的topic中,并可以指定在topic里哪些消息分配到哪些分区(比如简单的轮流分发各个分区或通过指定分区语义分配key到对应分
区)
• 生产者直接把消息发送给对应分区的broker,而不需要任何路由层。
• 批处理发送,当message积累到一定数量或等待一定时间后进行发送。
7、Consumer
• 一种更抽象的消费方式:消费组(consumer group)
• 该方式包含了传统的queue和发布订阅方式
– 首先消费者标记自己一个消费组名。消息将投递到每个消费组中的某一个消费者实例上。
– 如果所有的消费者实例都有相同的消费组,这样就像传统的queue方式。
– 如果所有的消费者实例都有不同的消费组,这样就像传统的发布订阅方式。
– 消费组就好比是个逻辑的订阅者,每个订阅者由许多消费者实例构成(用于扩展或容错)。
• 相对于传统的消息系统,kafka拥有更强壮的顺序保证。
• 由于topic采用了分区,可在多Consumer进程操作时保证顺序性和负载均衡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号