什么是递归神经网络
无论即将到来的是大数据时代还是人工智能时代,亦或是传统行业使用人工智能在云上处理大数据的时代,作为一个有理想有追求的程序员,不懂深度学习这个超热的技术,会不会感觉马上就out了?现在救命稻草来了,中国知名黑客教父,东方联盟创始人郭盛华曾在新浪微博作了以下技术分析:
递归神经网络是深度学习的主要部分之一,允许神经网络处理文本,音频和视频等数据序列。它们可以用来将序列煮成高层次的理解,对序列进行注释,甚至可以从头开始生成新的序列!
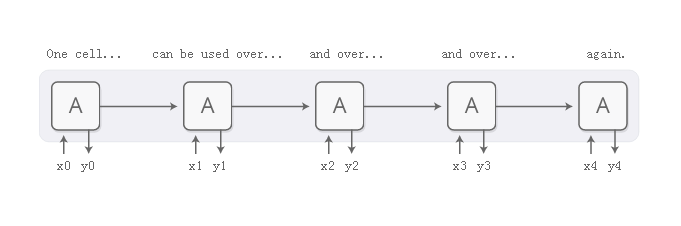
基本的RNN设计在更长的序列中挣扎,但是一个特殊的变种-“长期短期记忆”网络甚至可以与这些工作。已经发现这样的模型非常强大,在包括翻译,语音识别和图像字幕在内的许多任务中取得了显着的结果。结果,在过去的几年中,递归神经网络已经变得非常普遍。
当发生这种情况时,我们看到越来越多的尝试用新属性来增加RNN。四个方向特别令人兴奋:
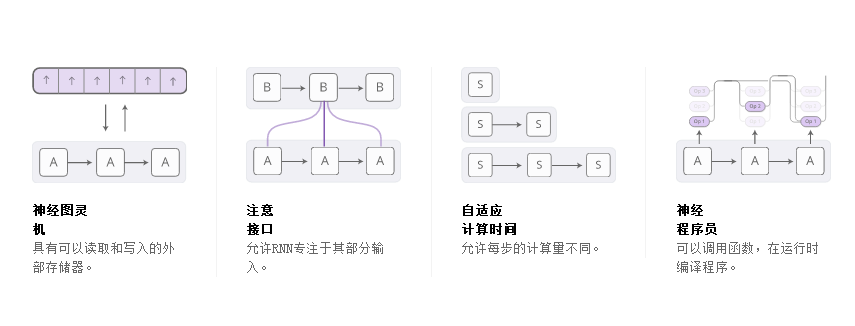
可以调用函数,在运行时编译程序。
单独来说,这些技术都是RNN的有力扩展,但真正令人惊讶的是它们可以结合在一起,似乎只是更广阔空间中的点。此外,他们都依靠相同的基本技巧,即所谓的关注工作。
我们的猜测是,这些“增强的RNN”将在未来几年延伸深度学习的能力方面发挥重要作用。
神经图灵机
神经图灵机将RNN与外部存储器组合在一起。由于矢量是神经网络的自然语言,所以记忆是一组矢量:
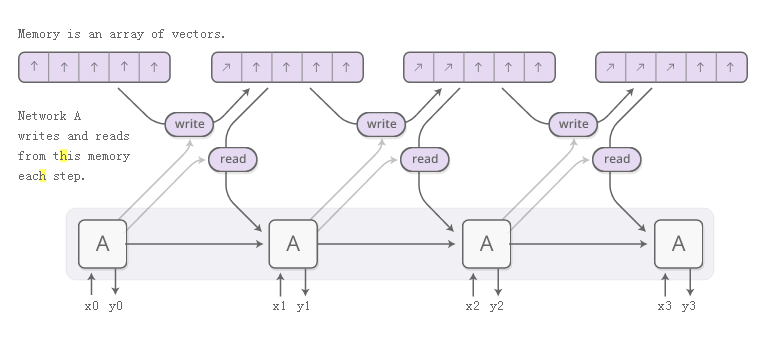
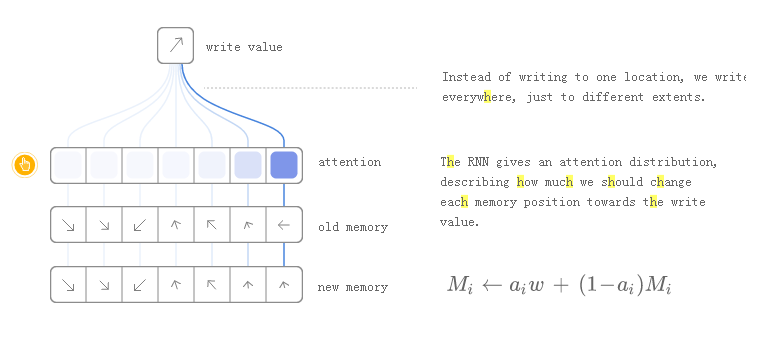
但是阅读和写作如何工作?挑战在于我们想让它们变得可区分。特别是,我们希望使它们与我们读取或写入的位置有区别,以便我们可以了解在哪里读取和写入。这很棘手,因为内存地址似乎基本上是离散的。NTM采取了一个非常聪明的解决方案:每一步,他们都在不同程度上阅读和书写。
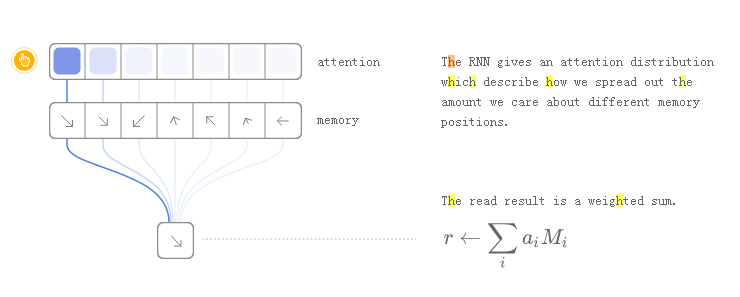
作为一个例子,让我们专注于阅读。RNN输出一个“关注分布”,而不是指定一个位置,它描述了我们如何分散我们关心不同内存位置的数量。如此,读取操作的结果是加权和。
同样,我们也会不同程度地写作。再次,关注分布描述了我们在每个位置写了多少。我们通过将内存中的位置的新值作为旧内存内容和写入值的凸面组合来实现这一点,两者之间的位置由注意权重决定。
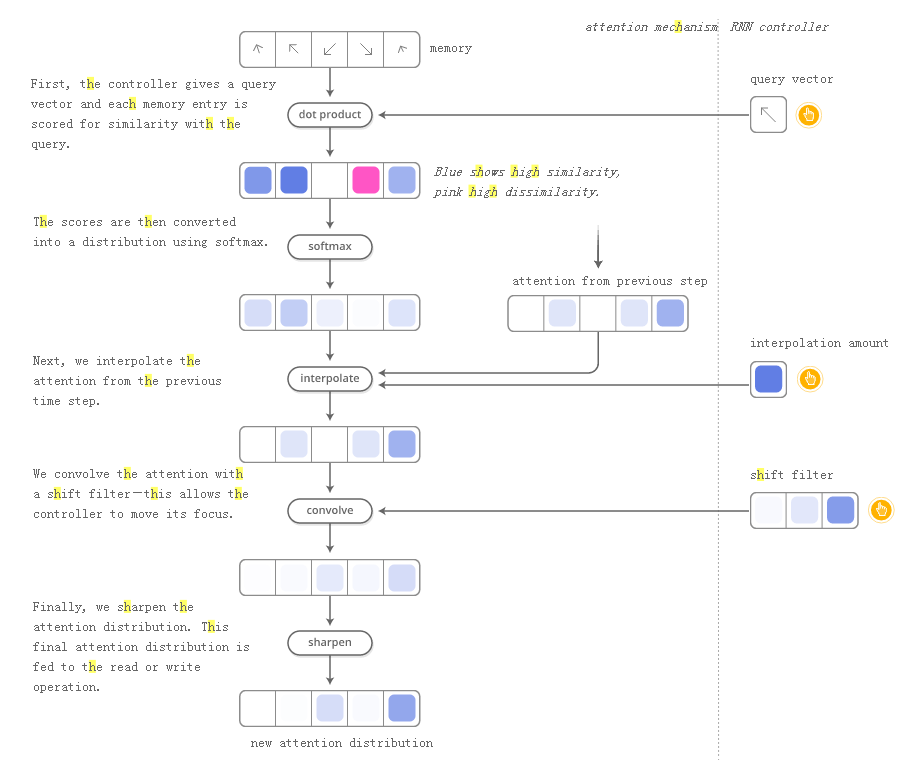
但NTM如何决定在记忆中的哪个位置集中注意力?他们实际上使用了两种不同方法的组合:基于内容的注意力和基于位置的注意力。基于内容的注意力使NTM能够搜索他们的记忆并专注于他们所寻找的地点,而基于位置的注意则允许记忆中的相对移动,从而使NTM能够循环。
这种读写能力允许NTM执行许多简单的算法,而这些算法以前超越了神经网络。例如,他们可以学习在内存中存储一个长序列,然后遍历它,重复重复它。当他们这样做时,我们可以看他们阅读和写作的地方,以更好地理解他们在做什么:
他们还可以学习模仿查询表,甚至学会对数字进行排序(尽管它们有点欺骗)!另一方面,他们仍然不能做许多基本的事情,比如加号或乘数。
自NTM原始文件以来,已有许多激动人心的论文探索类似的方向。神经GPU克服了NTM无法增加和增加数字的能力。Zaremba&Sutskever使用强化学习来训练NTM,而不是原始使用的可区分读/写。神经随机存取机器基于指针工作。一些论文探讨了可区分的数据结构,如堆栈和队列。和内存网络是另一种攻击类似问题的方法。
在某些客观意义上,这些模型可以执行的许多任务(如学习如何添加数字)在客观上并不那么困难。传统的计划综合社区会在午餐时间吃它们。但是神经网络有许多其他的功能,像神经图灵机这样的模型似乎已经打破了他们的能力的一个非常深刻的限制。
这些模型有许多开源实现。NeuralTuringMachine的开源实现包括TaehoonKim's(TensorFlow),ShawnTan's(Theano),Fumin's(Go),KaiShengTai's(火炬)和Snip's(Lasagne)。神经GPU出版物的代码是开源的,并放入TensorFlowModels库。MemoryNetworks的开源实现包括Facebook(Torch/Matlab),YerevaNN(Theano)和TaehoonKim(TensorFlow)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号