企业安全建设之路:端口扫描(上)
0×00、业务需求
由于工作关系,最近一年来都奔走在各大安全会议,无论是公开会议,例如:ISC互联网大会、freebuf互联网大会等、还是半公开的会议,例如某SRC组织的互联网金融会等。互联网安全运维人员都在谈自己企业的运维平台是如何建立的。这里我简单用思维导图总结一下:
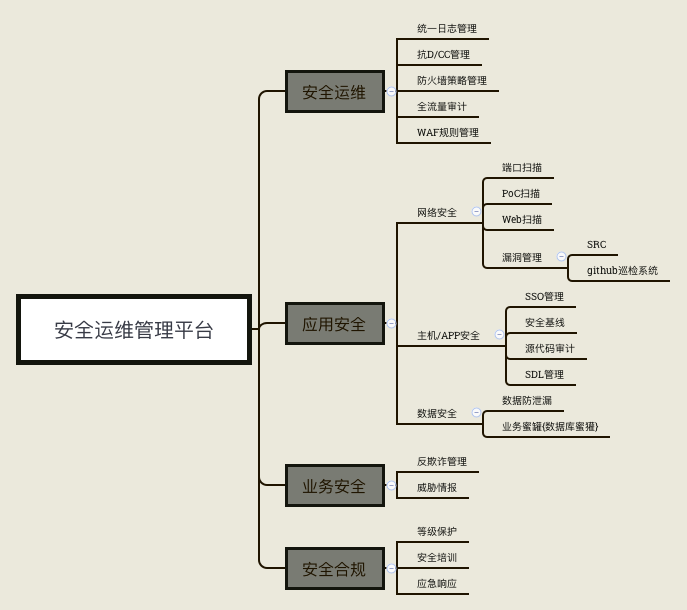
有一定研发能力的互联网安全团队都在建立自己的安全运管平台。我想这样做的目的是:
(1)半自动化或者全自动化安全运维规则,提高工作效率,降低人力成本。
(2)现有安全厂商提高的产品无法满足用户日益增长业务安全需求,业务架构变更。例如:日志管理部分,传统SIEM是无法满足 50万QPS Web日志处理能力,需要storm/spark架构处理。
(3)降低人员变动带来的业务安全的稳定性
当然这种安全投入是巨大的,而且需要持续发展才能摊平成本。
0×01、端口扫描需求分析
1、竞品获得需求:
| 传统扫描器 | 云扫描器 | 企业内网端口扫描器 | |
|---|---|---|---|
| 检查模式 | 并发 | 分布式/并发 | 并发 |
| IP端口资产管理 | 不支持 | 支持 | 支持 |
| IP端口资产变更告警 | 不支持 | 支持 | 支持 |
| 检查是否开放违规端口 | 不支持 | 支持 | 支持 |
2、安全经验获得需求
| 操作系统分布 | windows操作系统版本分布 |
|---|---|
| web容器分布 | IIS版本分布 |
| 数据库端口对外开放 | mysql数据库版本分布 |
| 暴力破解协议分布 | OpenSSH版本分布 |
3、简单数据挖掘分析获得需求
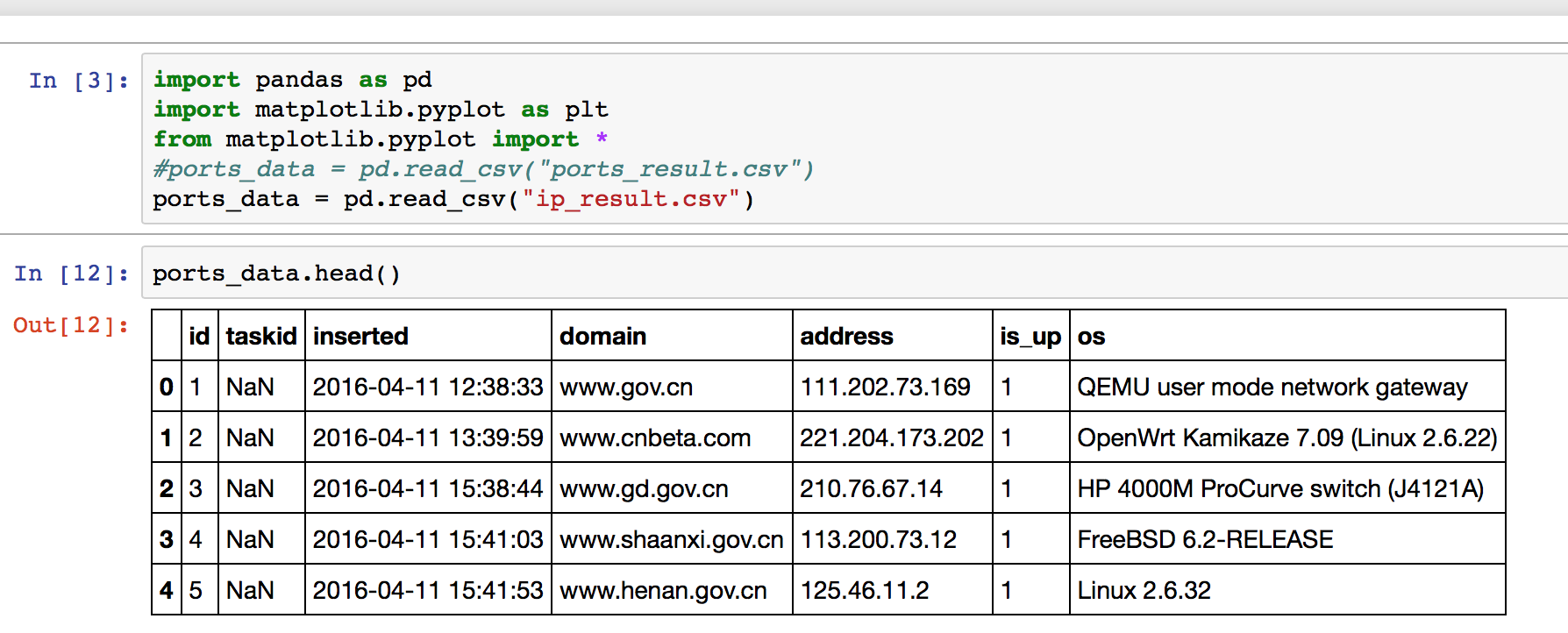
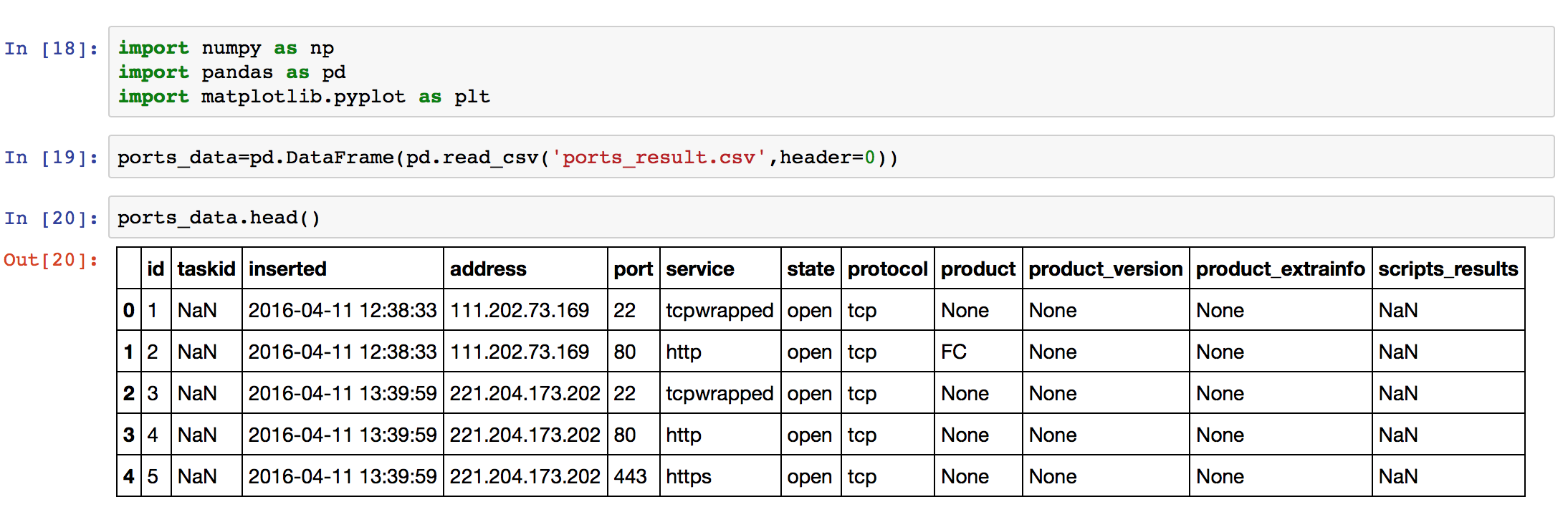
在此之前做了一部分数据采集工作,表一ip_result.csv主要记录主机IP、域名、是否存活和操作系统类型,表二ports_result.csv主要记录了地址、端口、服务、服务详细描述等,通过对本测试数据集的分析,找到我们的业务需求。首先要了解数据全貌,可以多个维度去分析数据,包括:可视化分析(pandas)、SQL方式分析、excel分析等。
(1)Pandas分析法:
在这之前想说一下为什么要可视化分析,因为,通过图形人们可以判断出趋势,举个小例子:
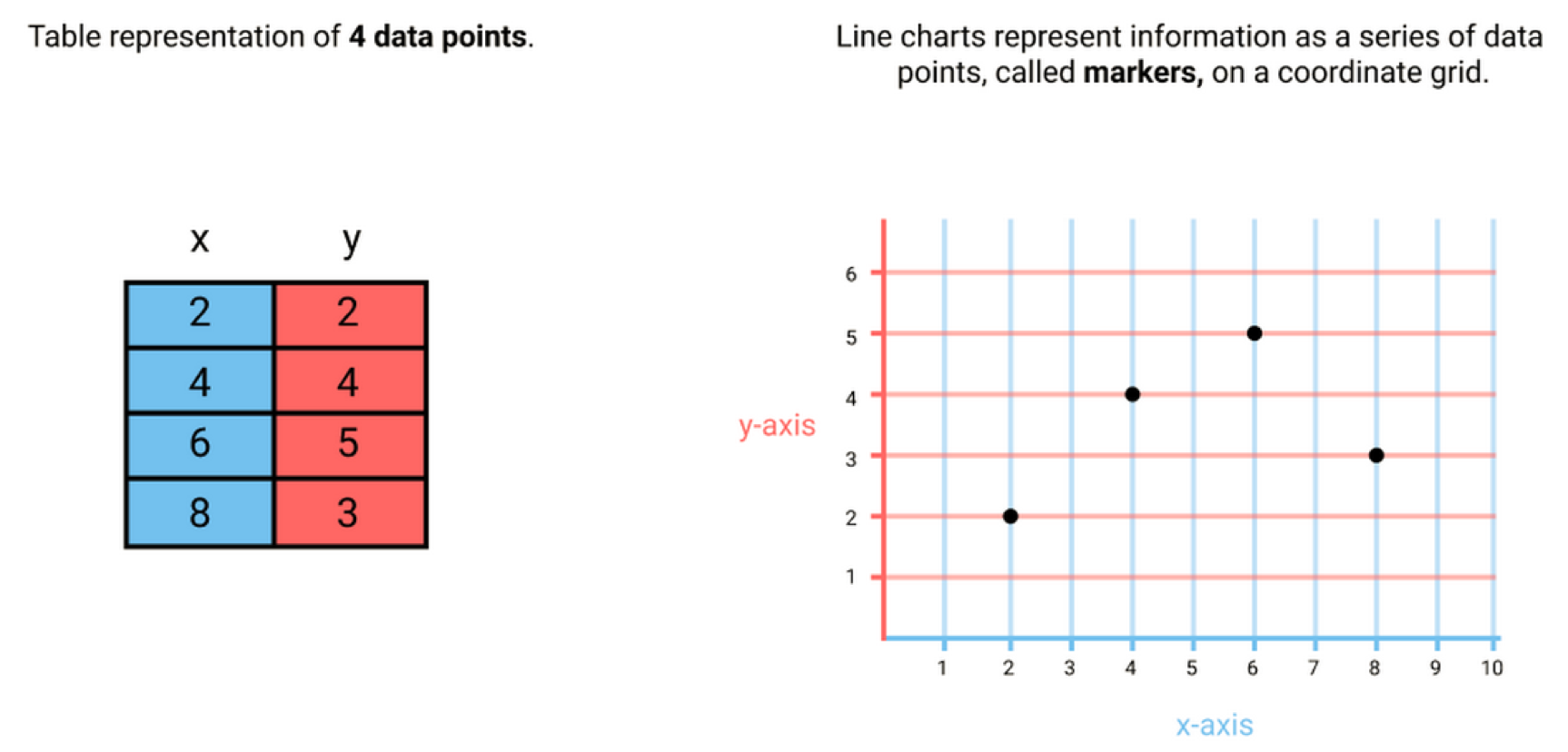
单纯的几组数字是看不出什么规律和趋势的,但是如果以矩阵的形式可视化后,大家对下一个点的出现就有趋势的判断了。
我们先了解一下我们的数据内容是什么,分别对两张表的数据导入到pandas中。
然后对各个有意思的字段或者字段组合聚类分析,
ip表:os
port表:port、service、product&product_version、scripts_results(address字段由于是公网数据暂时忽略)



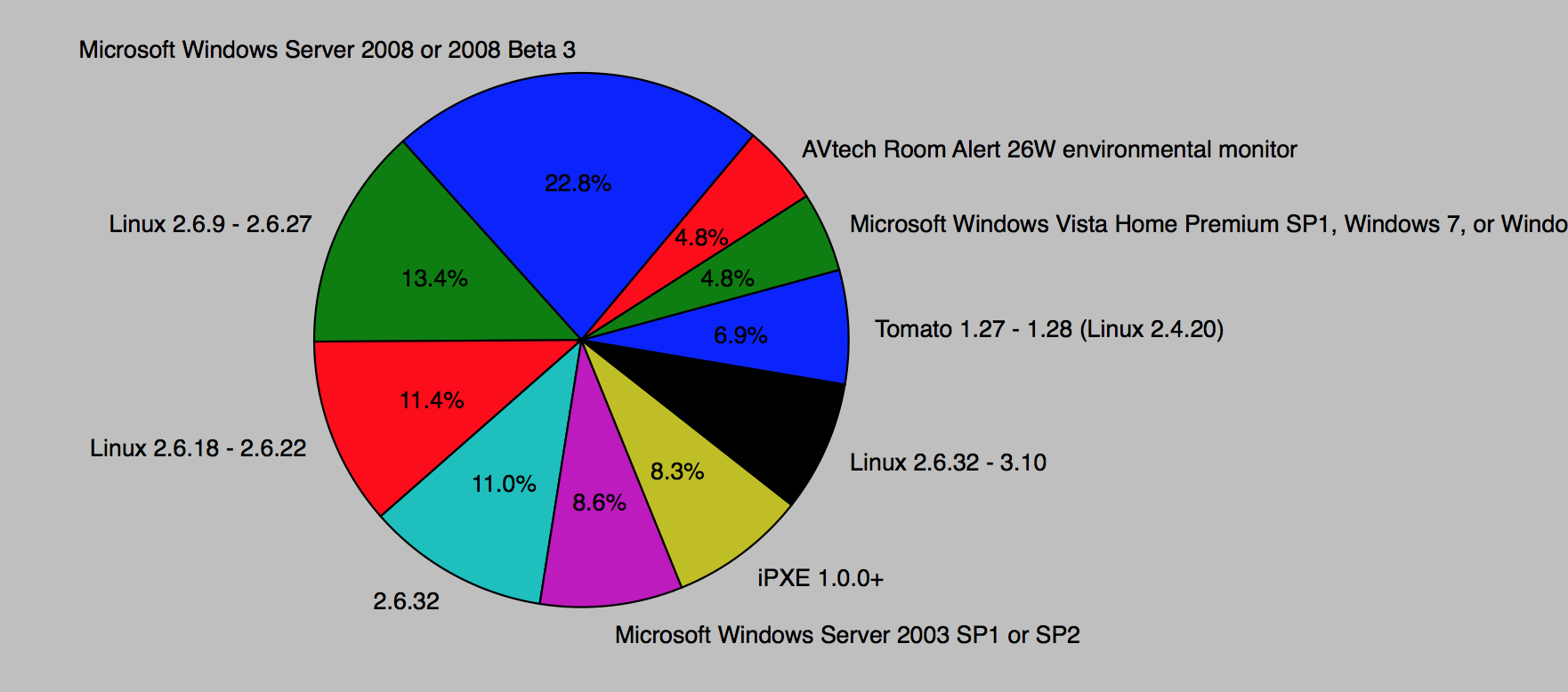

pandas分析方法,多字段之间Group by比较麻烦,所以建议使用SQL分析法。
(2)SQL分析法:
把csv数据导入到postgresql数据库,执行:
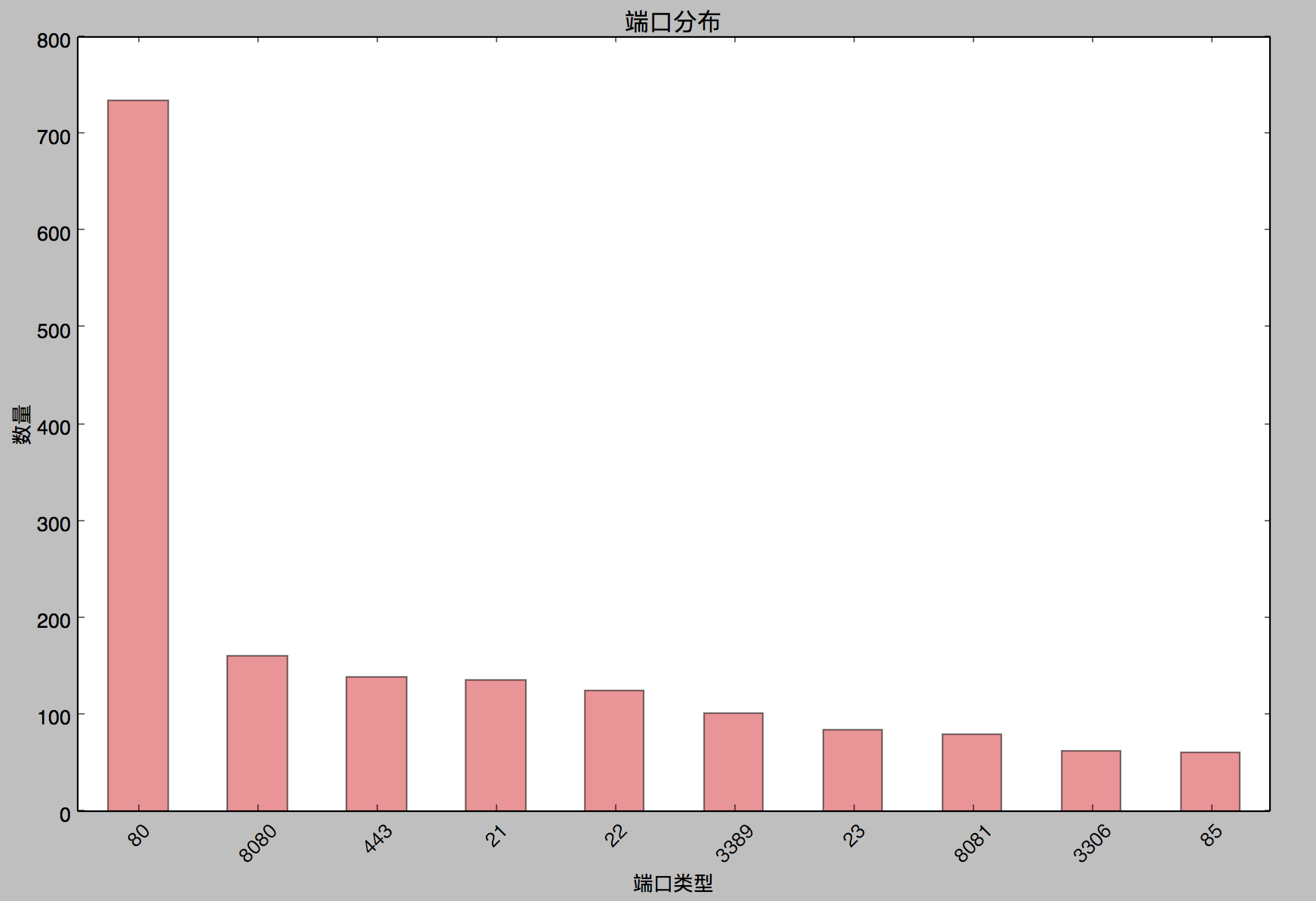
SELECT port,count(*) as hit from ports_resultGROUP BY port ORDER BY hit DESC
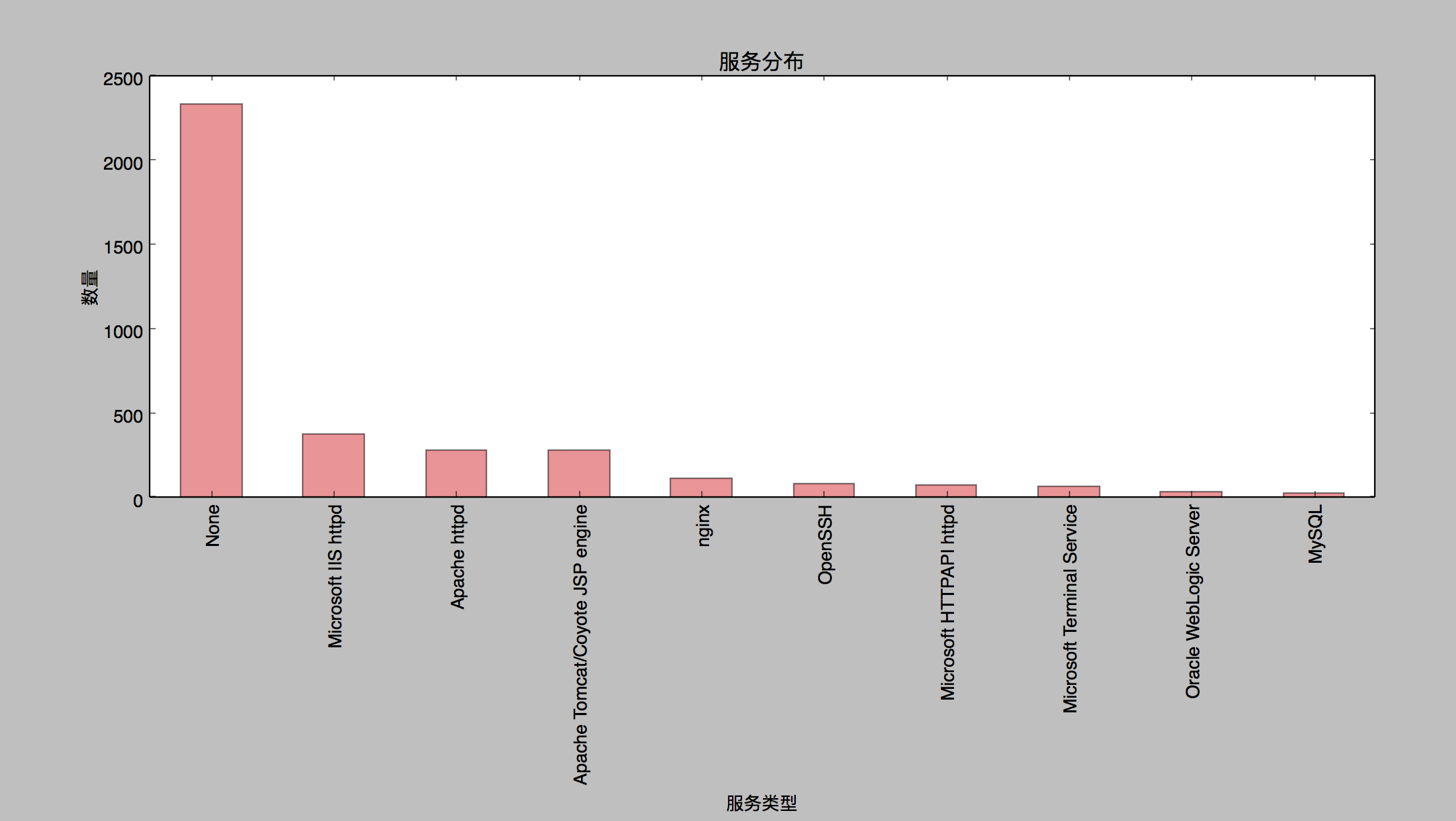
SELECT service,count(*)as hit from ports_resultGROUP BY serviceORDER BY hit DESC
SELECT product,product_version,count(*) as hit from ports_resultGROUP BY product,product_version ORDER BY hit DESC
SELECT scripts_results,count(*)as hit from ports_resultGROUP BY scripts_resultsORDER BY hit DESC
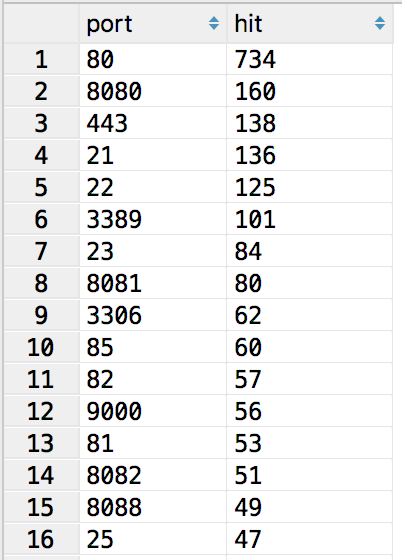
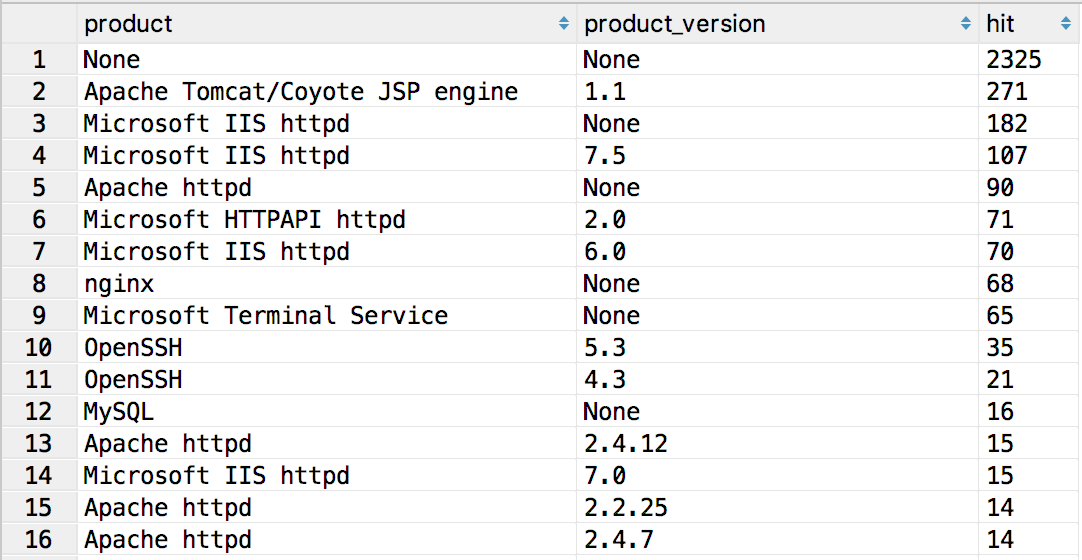
然后通过正则表达式过滤掉一些无用数据,就可以得到我们想要的数据,那么,通过以上数据的简单的分析,我们对已有的安全经验和竞品数据有更深入的了解数据的本质。
(3)机器学习分析
当然可以用更高级的数据挖掘手段去分析,比如:聚类、分类、回归、降维、时间序列、文本挖掘。首先要确定我们挖掘的目的,是确定我们安全报表的需求,也就是聚类的问题,那么如何实现呢?
在这里我们引入sklearn这个机器学习python库,它为我们选择机器学习算法提供了优化的路径:

我们port表中大约有10000多条数据,根据算法选择可以看出,
1、样本数据>50条,不需要获取更多的数据
2、如果是分类的问题,数据是否标记,对于我们的数据来说是没有的,那就进入clustering象限
3、分类类型是已知还是未知的呢?对于我们的数据当然是未知的,因为我们不知道如何分类,这需要算法告诉我们。
4、那么我们的数据样本>1w条,建议使用Kmeans。
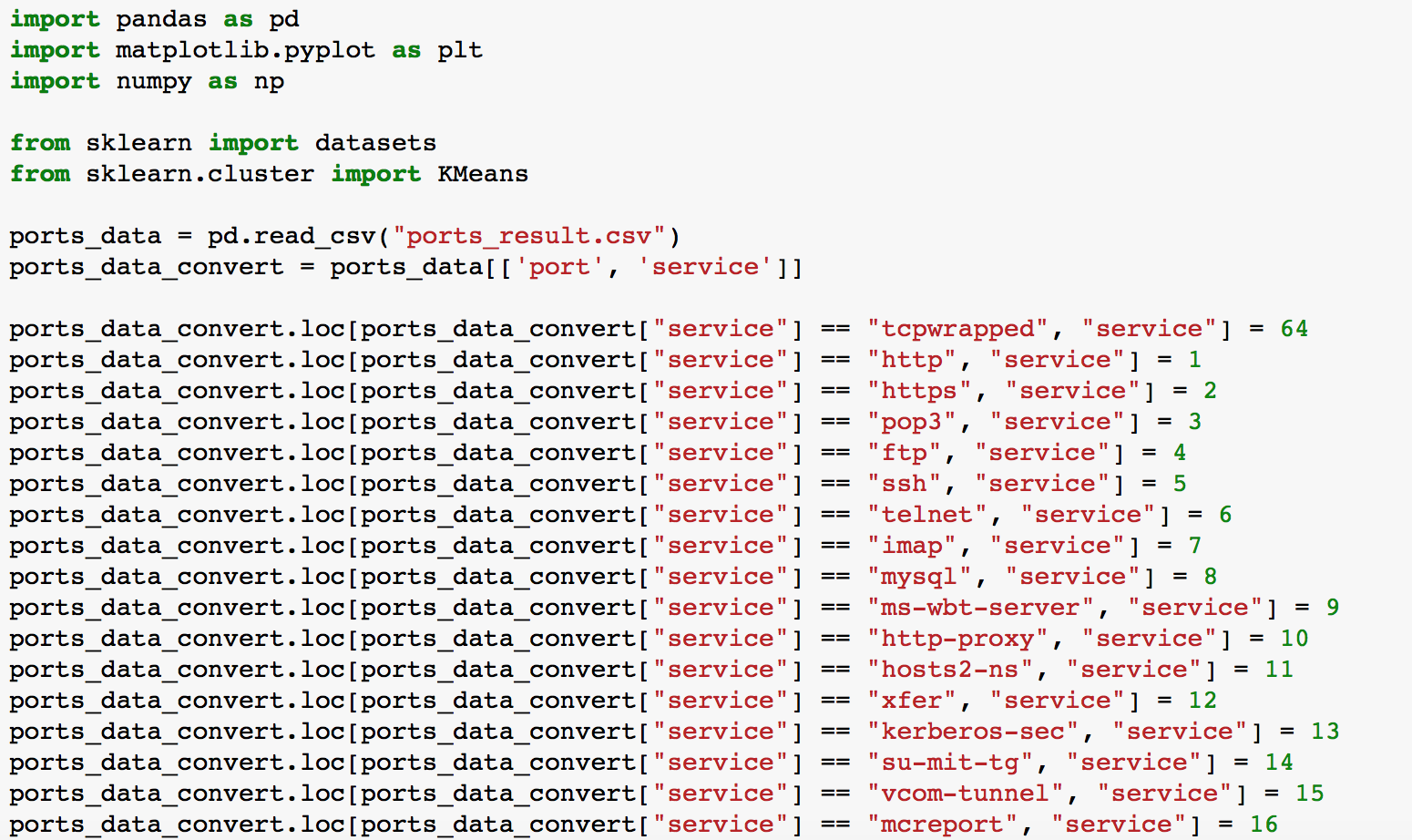
我们需要使用的算法已经确定,下一步就是把数据经过清洗后导入算法库运算。这里要注意几个问题:
1、数据要做预处理,去除掉空值
2、把有意义的string项转化成数字类型,方便机器学习算法处理
多说无用,上代码:
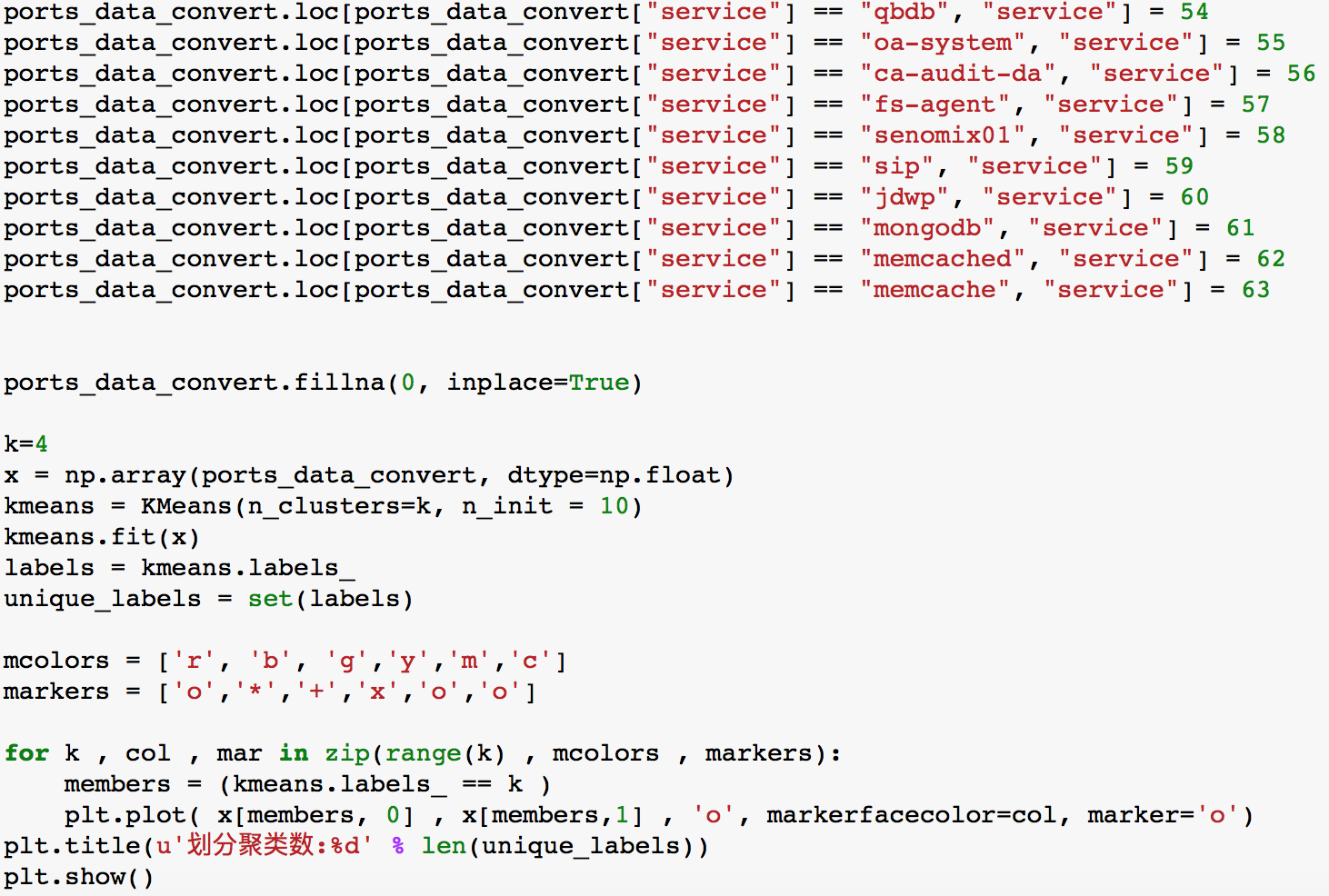
最终机器学习分析的图:

经过对k值的调整,发现分4类是最靠谱的。也就是说,对服务的分析做4类足够,http、https、ssh、rdp。
0×02、功能设计
1、设计目的:
| 版本规划 | 设计功能 |
|---|---|
| V1.0 | 通过端口扫描模块获得内网IP端口资产,资产变更告警,违规告警规则设置 实现内网扫描、外网扫描、行业扫描 |
| V1.1 | 增加端口资产拓扑图 |
备注:当前版本只上线V1.0功能。
2、用户场景
| 用户场景 | 对应功能 |
|---|---|
| 用户通过网络层面了解企业内部网络存在的资产 | 内网IP资产和端口扫描 (1)对存活主机探测 l 主机扫描范围设置 l 主机扫描结果存储 (2) 对存活主机端口探测 l 对主机扫描端口范围设置 l 端口扫描结果存储 (3)IP端口资产变更告警 l 提供周期性扫描设置 l Email报警 (4) 违规告警规则设置 l 内置数据库对外服务检查报警 (5) report l 操作系统类型分布 l 对外服务类型分布 l web服务器类型分布 l 远程访问服务类型分布 |
| 用户通过网络层面了解企业对外网络资产 | 外网IP资产和端口扫描 (1)对外网存活主机探测 l 主机扫描范围设置 l 主机扫描结果存储 (2) 对外网存活主机端口探测 l 对主机扫描端口范围设置 l 端口扫描结果存储 (3)IP端口资产变更告警 l 提供周期性扫描设置 l Email报警 (4) 违规告警规则设置 l 内置数据库对外读物检查报警 (5) report l操作系统类型分布 l 对外服务类型分布 lWEB服务类型分布 l 远程访问服务类型分布 |
| 用户想了解一下自己在所在行业安全指数 | 对行业IP资产和端口扫描 (1)行业资产录入 (2) 行业报告 操作系统类型分布 web服务类型分布 远程访问服务类型分布 |
0×03、总结
本节先简单说到这里,后面会详细描述:详细设计、交互设计、前端实现、后端实现、测试联调、安装部署等环节。本节重点讲述的是如果在需求分析阶段加入数据分析,帮助产品人员更好的设计产品。有不足之处还请各位大佬指教。
* 本文原创作者:bt0sea,本文属FreeBuf原创奖励计划,未经许可禁止转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号