


Kafka—基本概念
一、Kafka(MQ) 的应用场景
1、Kafka(MQ) 之异步化、服务解耦、削峰填谷
异步化,可能就是一个非常大的请求,可能几百万上亿次的请求,那我们可以把它封装成一条一条 Message ,然后投递到 MQ ,那么具体的消息可能就是一个一个的指令。比如说发邮件,获取做一些计算,入库操作,在这里如果是单点操作的话性能可能会有瓶颈,这里采用 MQ 作为一个消息的中转,然后异步化给我们所有的 consumer,去消费一条一条的指令。从而达到优化的这么一件事情
服务解耦,在我们实际的电商还是做一些互联网的一些应用服务的话,那对于服务解耦那是不可或缺的,采用 MQ 也是一个非常明智的选择。
削峰填谷,MQ 具有天然的缓存机制,把消息去存到 MQ Broker 里面,然后我们去慢慢的去消费,然后当高峰期的时候可以去做一个削峰,在低谷期做一个填谷,使我们的处理能力相对应的更均匀一些。
2、Kafka 海量日志收集
3、Kafka 之数据同步应用
4、Kafka 之实时计算分析
二、Kafka(MQ) 之异步化实战
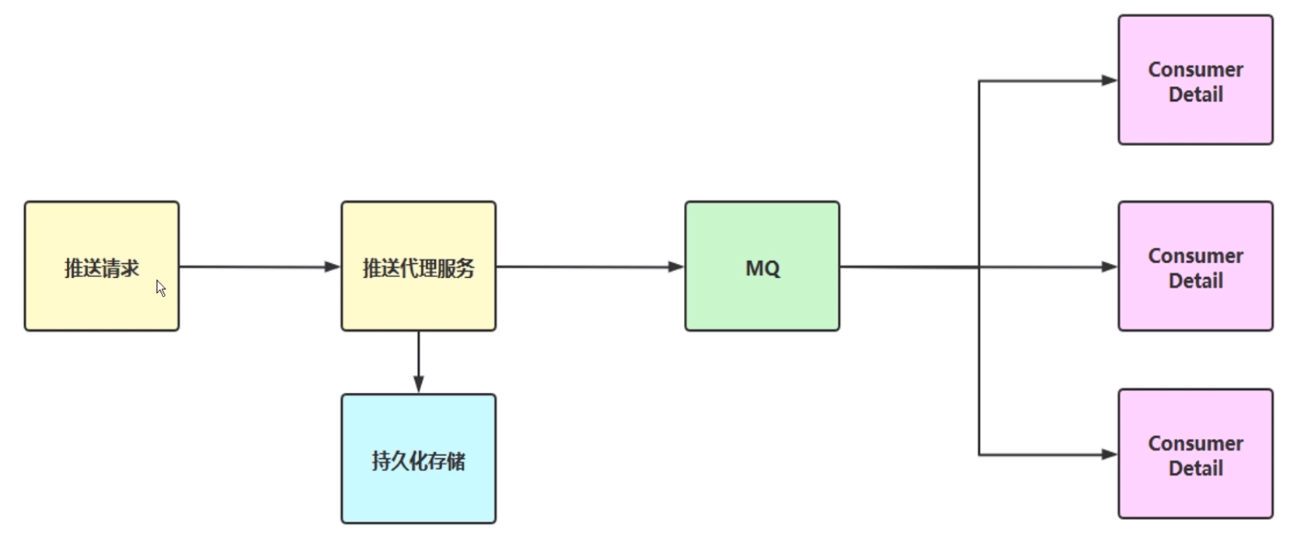
1、Kafka 海量日志收集
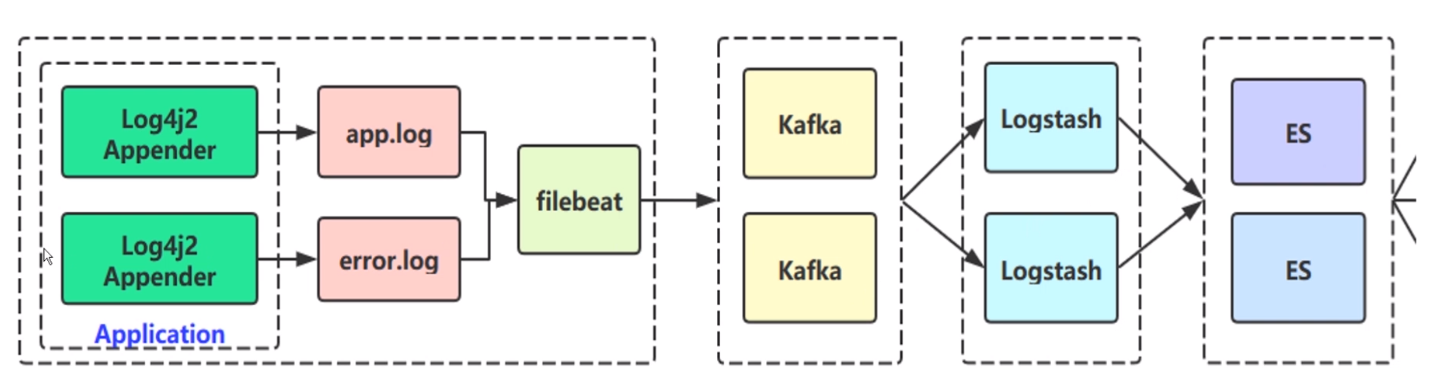
app.log 和 error.log
app.log 可能就是开发人员打的一些 info,或者一些其他级别的全量日志。error.log 就是一些错误日志。为什么要拆开呢?是因为要保证错误的日志我们能够更及时的去应用方感知,如果说我们的 app.log 有几千万条,我的 error.log 可能几十条,万一混到一起,最终可能会通过 filebeat 日志抓取插件,抓取这两个日志文件推到 kafka 集群上。Kafka 流入到 Logstash ,Logstash 就是对你的日志文件做一个具体解析,比如说 Java 里面可能会有 error 的堆栈信息,Exception 异常信息异常原因,在我们实际线上排查问题的时候是非常需要的。就是做一个日志解析操作,解析完了以后可能是一个 Json 直接传到 ES 里,让我们的 ES 引擎去做搜索,监控相关的事情
2、Kafka(MQ)之数据同步实战
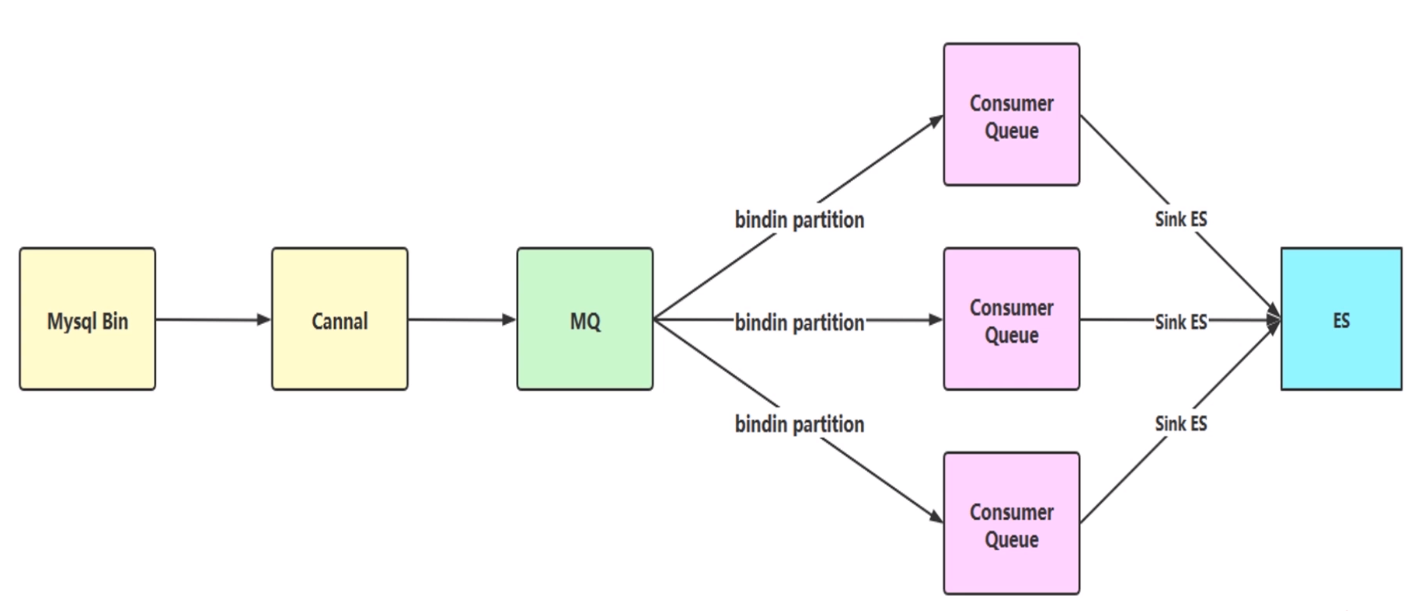
数据同步,莺应对与互联网行业或者说下订单,它的订单量肯定是非常大的。一般持久化层都是 MySQL ,那都会用一些分库分表的一些中间件,比如 sharding sphere 其实就是 shardingJDBC,Mycat 或者自己去做一些分库分表的策略,那么我们分成十个库,每个库里面100张或者是50张表。那分库分表之后我们怎么去做这种纬度的统计分析,或者是做一个查询呢,这个其实是很难的,莫非查询十个数据库,返回结果汇总?肯定不是这样的,所以我们要把这些库,这么多数据统一同步到一个地方,然后进行查询。现在目前主流的就是同步到 ES 或者同步到 MySQL 到 MySQL 或者同步到 Redis 缓存都有可能。
这里我们举一个简单的例子,这里是阿里巴巴的一个 Cannal ,它其实就是一个 MySQL 变 log 的这么一个实时同步的一个中间件,那 MySQL 变 log 怎么去解析呢?无非就是开启 MySQL 的 BinLog ,然后一行一行的去读取,这样我们就把 MySQL BinLog 读出来之后发送到 MQ 然后 由 consumer 去消费,解析同步到 ES 上。
三、Kafka 基本概念
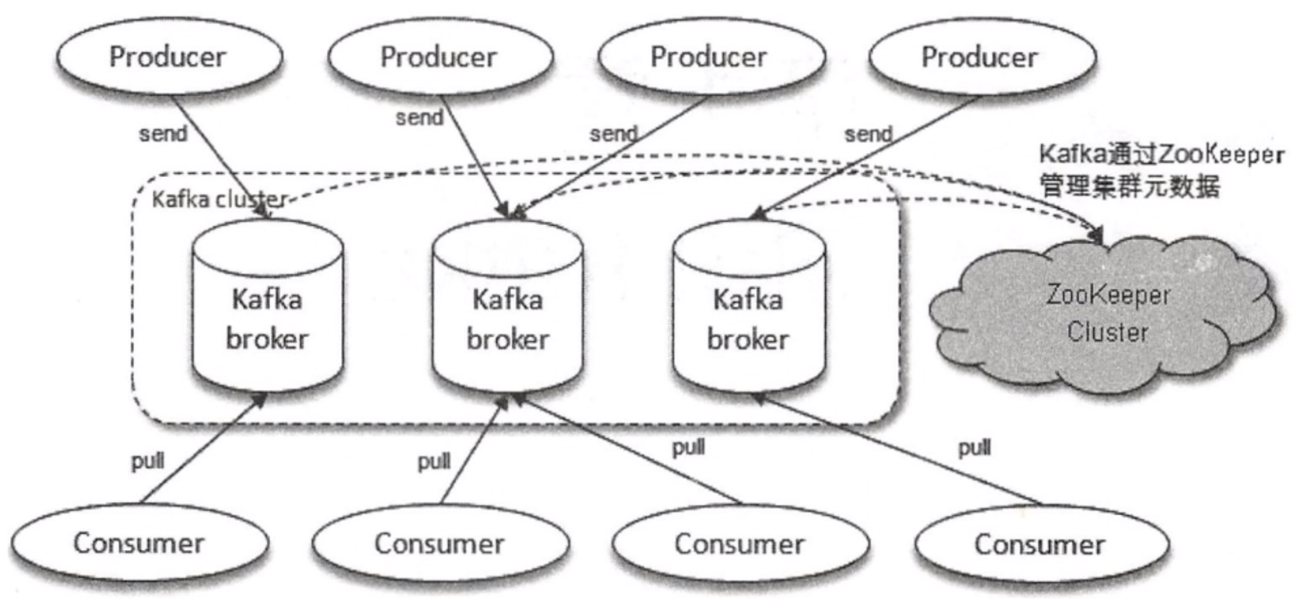
这幅图可以看到 Kafka 基本组成,中间就是 Kafka 集群,一般最少3个。Kafka 通常有这几个角色:
Producer(生产者) 消息发送到 Kafka 集群
Consumer(消费者) 一般 Kafka 选择 拉的方式,拉取到本地的节点上,然后去消费。
Zookeeper 元数据管理中心
1、Kafka Topic - Partition
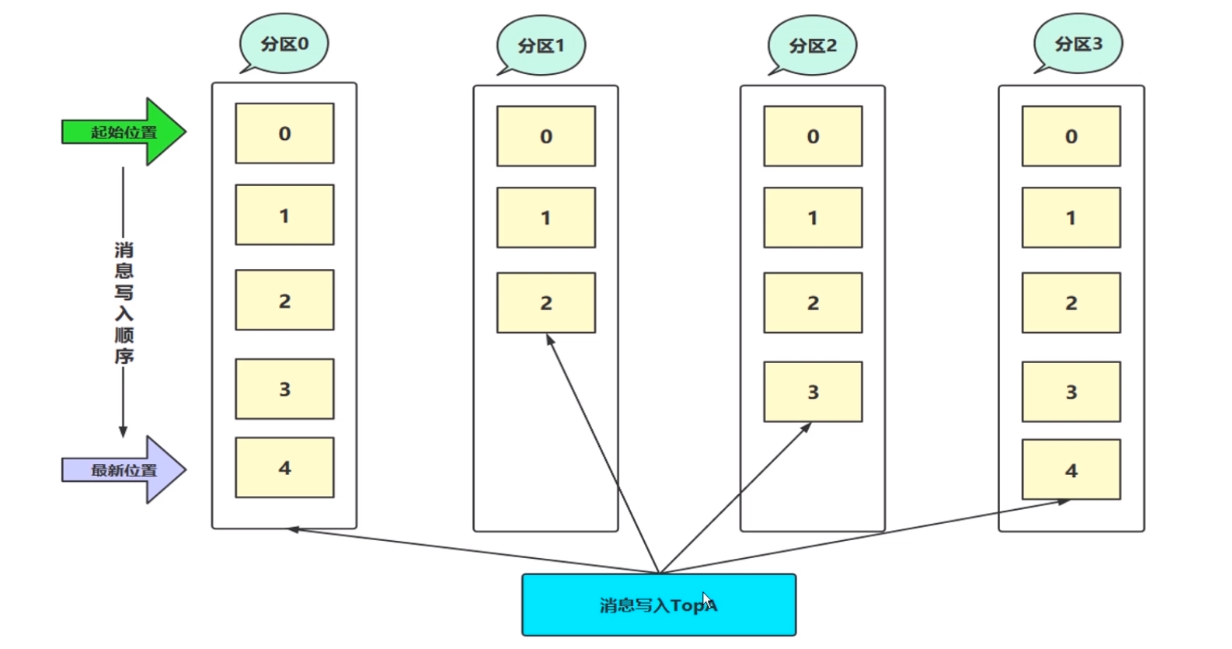
这幅图最下面有一个消息写入到 TopicA,如果了解 MQ 的话就会知道是一个主题,Kafka 是一个以消息主题为单位进行归类的,我们生产者直接把消息发送到特定的主题。比如说 TopicA 消费者肯定是通过订阅这个 TopicA 主题,进行消费消息的。主题是一个逻辑上的概念,而不是物理存储上的概念。那这个主题就是 TopicA 。还有一个概念就是 Partition ,英文就是分区的意思。
TopicA 上面有4个分区(0、1、2、3),一个分区只能属于单个主题,同一个主题下可以有不同的分区,分区里面包含不同的消息。那我们分区上其实在存储层面上可以理解为就是一个可追加的日志文件。这里我们知道,主题和分区的关系是一对多的关系。
分区里面一条一条的消息在这里面就是一个一个黄色的方框,一条一条的消息都会填充到这个分区里,也可以理解为填充到日志文件里。消息被追加到日志文件,都会临时分配一个偏移量(offset),offset 在这里看到的是0、1、2、3、4 。对于 offset 是一个顺序写入的一个过程,也就是说假设一共来了几条消息,那肯定是从0开始写,按顺序。理解成队列概念。offset 在分区中是一个唯一标识,通过这个 offset 定位到具体的分区才能找到这条消息。0分区和1分区里面都有 offset 的,它们互不影响。Kafka 也是通过 offset 消息在 分区内是顺序性的,其中我们怎么保证消息的有序呢?无非消费的时候一个消费者或者是线程或者进程去连接一个分区就行了。
2、Replica(副本的意思)
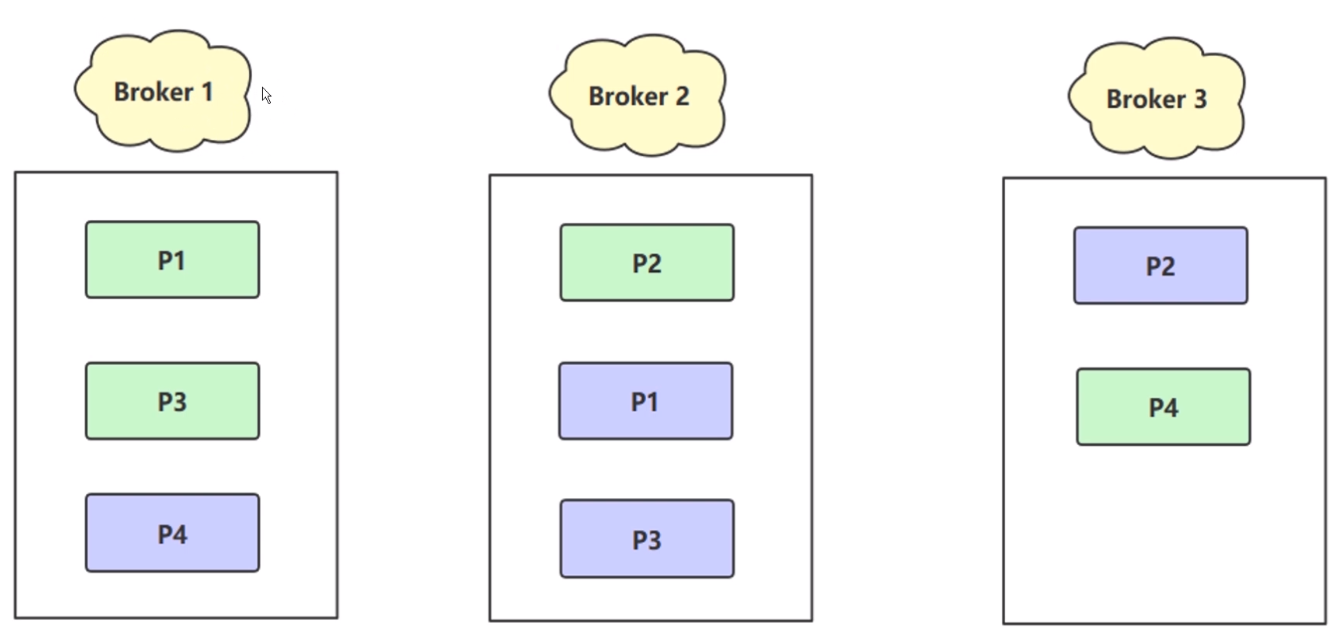
这里有3个节点,绿色的小方框表示主分片(主副本),对应的紫色的就是从副本。有副本四个什么作用呢?其实就是为了保证当我们单个 Broker 挂掉的时候,我们还有另外的一个副本可以保证数据的完整性。
在这里 P3 在 Broker1 中主副本,Broker2 也有个从副本,Broker3 P4是个主副本,在 Broker1 有一个从副本 P4。在这个集群上,整体有四个文件,P文件就是 Partition(分区) 磁盘上的 log 文件,你可以简单的认为 一个 Partition 就是一个 log 文件。现在一共有四个 Partition 文件,四个 Partition 文件数据都是不同的(P1、P2、P3、P4),但是他们的副本,绿色的 P1 和紫色的 P1是相同的,所以称之为副本的概念。那么 Kafka 为分区引入了 Replica 副本的机制,通过增加副本的数量可以提升集群的容灾能力。当任意一个节点挂掉的时候,我们还会有其他 Broker 上找到另外的 副本的数据,还可以继续对外提供副本的能力。
同一个分区不同的副本,数据是相同的,在同一时刻在副本之间并非完全一直的,他们之间存在一个主从概念。为什么同一时刻主副本和从副本的数据不一致呢?他们之间存在数据同步的过程,消息写入 Broker1 P1 的分片,然后要把 P1 追加的的新数据同步到 Broker2 上的 P1,那么它们才能保证数据上的一致性。它们的数据同步是有延迟的。其中主副本负责处理我们真正的读写请求,紫色的付副本,只负责和主副本数据的同步,P1 紫色的副本实时的拉取主副本的新数据同步。
当主副本 P1 或者整个的 Broker1 挂掉的时候,我们还有从副本的存在,还能够继续提供服务。Kafka 通过 Replica 副本的方式,从而实现了集群故障自动转移的功能。整个副本的概念无论是 ES 集群等等分布式存储领域都是这个一个多副本的概念,利用空间换取数据的高可用、可靠性、稳定性。
3、In Sync Replicas
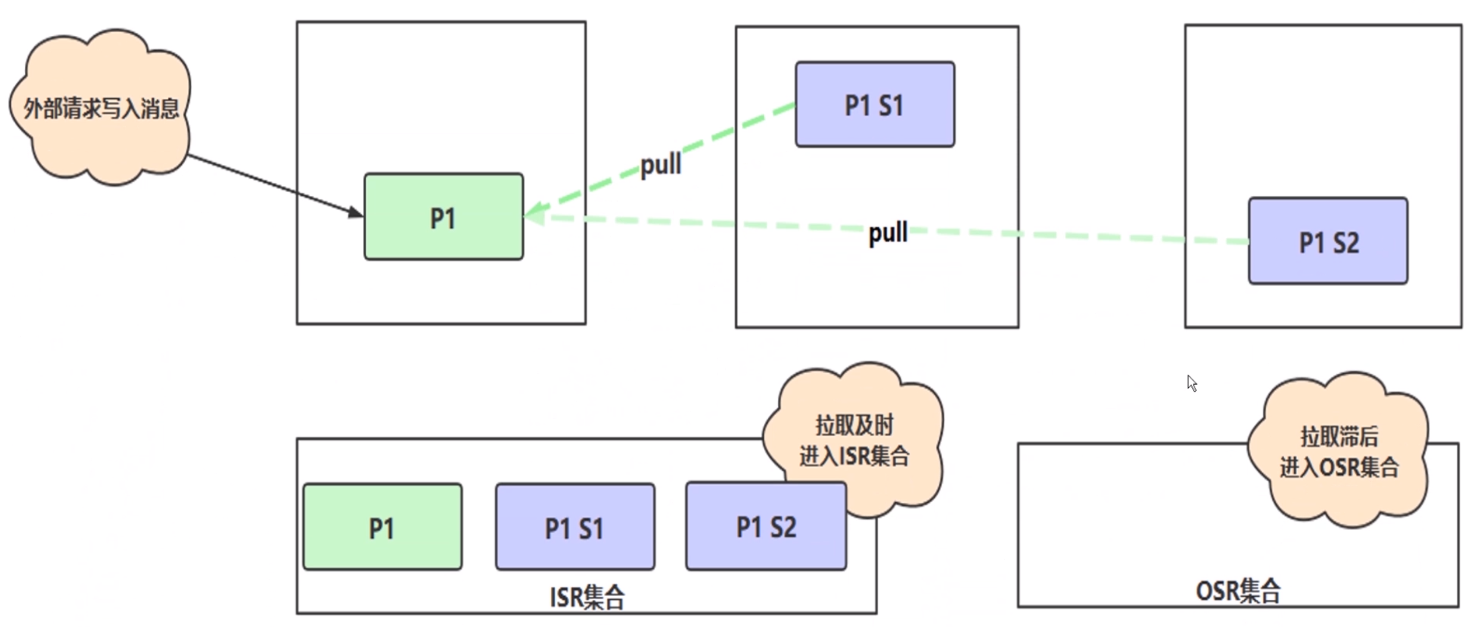
这幅图,外部请求写入信息,上面这三个框可以认为是 Kafka 的集群,绿色 P1 表示主副本,另外两个紫色的 P1 表示从副本,整个集群中有一个主副本,和两个付副本。当主副本 P1 写入完数据后,还要把写入的数据同步到 S1 和 S2上。这样就组成一个副本集,之前说的集群之间数据并非完全一致的,副本之间是一个一主多从的关系。Kafka 怎么去保证付从副本和主副本数据的一致性呢?这里就要引入 In Sync Replicas 的概念。
所有与主副本保持一定联系程度的数据副本包括主副本在类组成了 In Sync Replicas 集合,P1 里面有三条数据,然后 S1 和 S2 正常来讲 S1 和 S2 分别也有同样的三条数据,这样的话数据同步肯定会花费时间,比如说 S1 从 P1 拉取数据花了 50ms 、S2 拉取数据花了 250ms。假设我设置允许最大同步超时时间 1s ,那么无论 S1 同步还是 S2 其实是在一个同步容忍范围内的,就是说同步的时间都是很快的。这样的话 Kafka 会把这样的副本收入到 ISR 集合,如果这两个从副本拉取信息及时的话,那么我会把这两个从副本和主副本放到一个叫做 ISR 集合里。在这里又有另外一个概念 OSR(out of sync replicas) 集合,拉取滞后的集合。假设说 S1 同步的数据非常快5ms,S2同步时间非常慢,同步的时间花了1.5s。这个同步就很慢了,已经超过我的最大容忍范围了,我认为你应该在 1s 范围内就应该把数据同步好,结果花了1.5s超时了。那么我会把 S2 扔到 OSR 集合里,这就是 Kafka ISR 和 OSR 的概念。
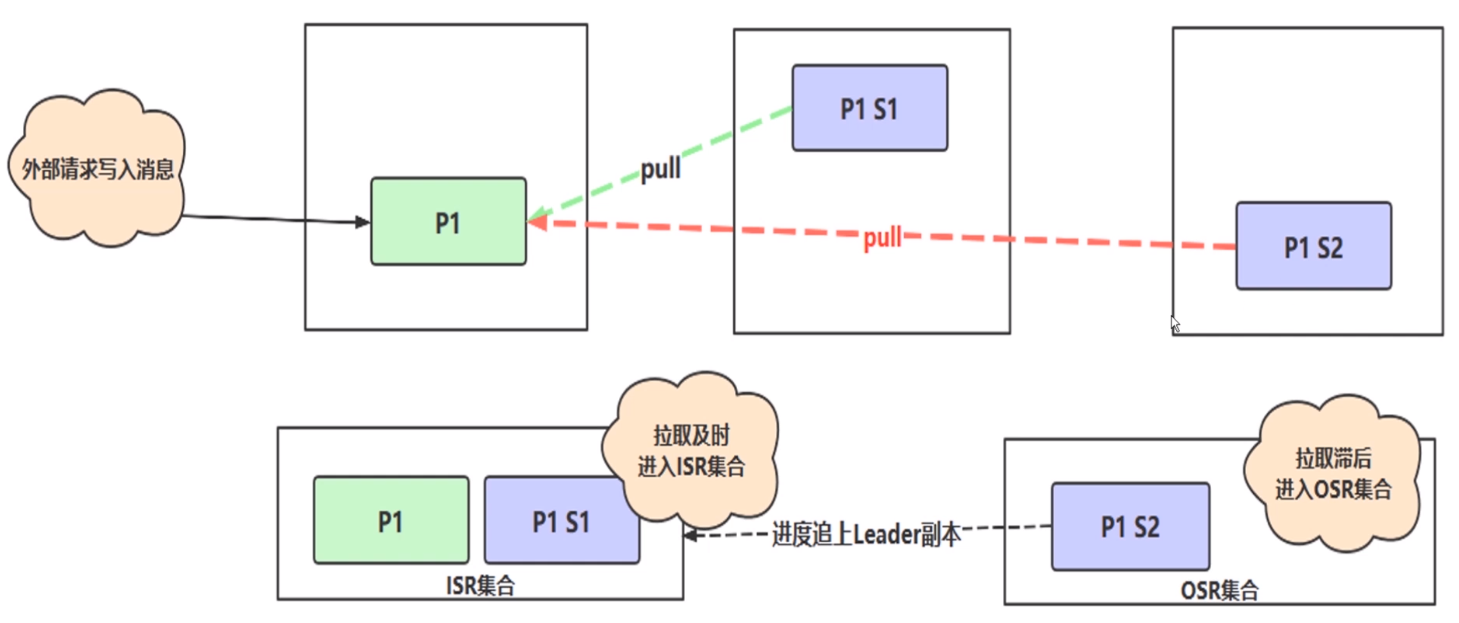
主副本主要做什么事呢?主副本主要维护和跟踪 ISR 集合里面所有的从副本的滞后状态,就相当于监控从副本拉取数据时间,如果你超时了,就把你扔到 OSR 集合里。但是第四条消息进来了,发现 S2 同步是时间跟上了,在 OSR 的从副本追上了同步时间,那么主副本也会监听到,会把它写入到 ISR 集合中,这是一个动态的。
当我们理解了 ISR 概念后,副本为了保证集群的容灾,当某一个集群节点挂掉的时候,还有其他副本是可用的。假设 P1 主副本挂了,那肯定会从 S1 和 S2 两个从副本中选出主副本,那么依据就是你的 ISR 和 OSR 。当主副本挂掉,只有在 ISR 集合里的副本才有资格被选举成为一个新的主副本,而 OSR 永远没有机会,这个原则就是 Kafka 默认的原则,也是保证数据一致性的基本准则,当然这个准则是可以通过 Kafka 的配置去改变。
(1、HW:High Watermark,高水位线,消费者只能最多拉取到高水位线的消息。
(2、LEO:Log End Offset,日志文件的最后一条记录的 Offset(偏移量)
ISR集合和HW和LEO直接存在着密不可分的关系
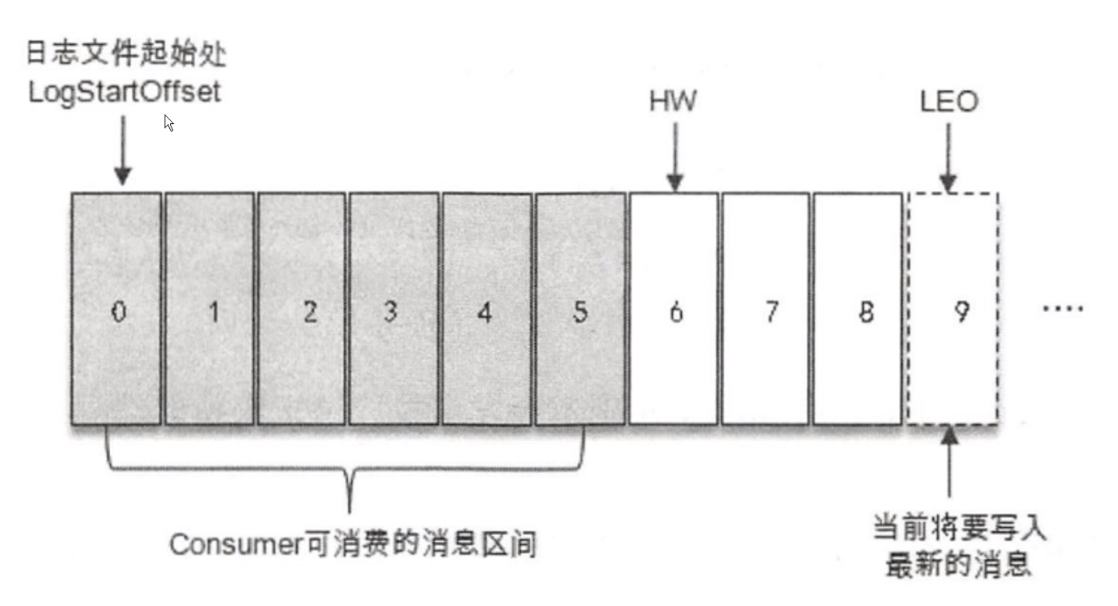
只是我们的一个日志文件,可以认为是一个 Log 或者是 Partition(分区),假设 LogStartOffset 从 0 开始的,HW 高水位线是 6,消费者在消费消息的时候能够处理的消息是高水位线之前的,不包含高水位线 0 ~ 5。而我们真正的日志文件可能写到 9 了,LEO 可能到 9 了。
通过这幅图,什么情况下高水位线在 6 ,LEO 在 9 了呢?只能消费 0 ~ 5 的消息,不能消费 6 ~ 8 呢?因为 9 是即将写入的,这就跟 ISR 或者 Kafka 副本进行 主从同步的一致性有关了。
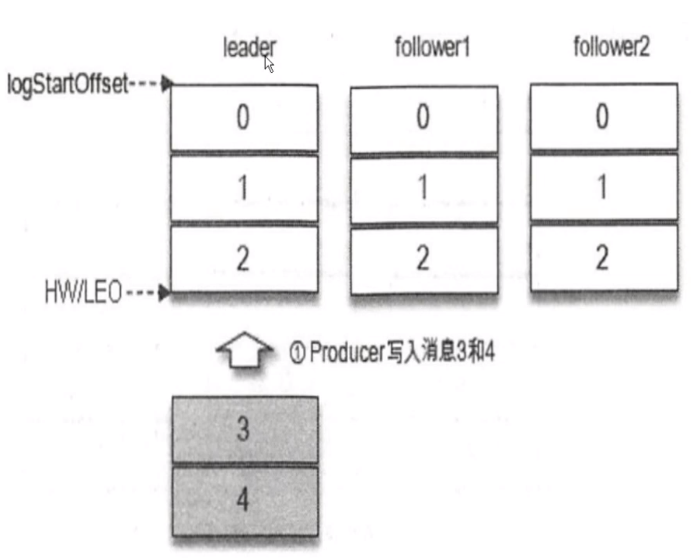
我们现在要往 3 个节点或者说一个 Partition 里有 3 个副本,主副本和两个从副本。我一条消息要写入 3、4 ,Producer 有两条消息(3、4),当前我认为 Partition 分区里面 LogStartOffset 都是 0,HW(高水位线) 和 LEO(最后文件位置) 都是 2,这种情况处于正常良好的情况,假设我现在即将写入 3、4 两条消息。
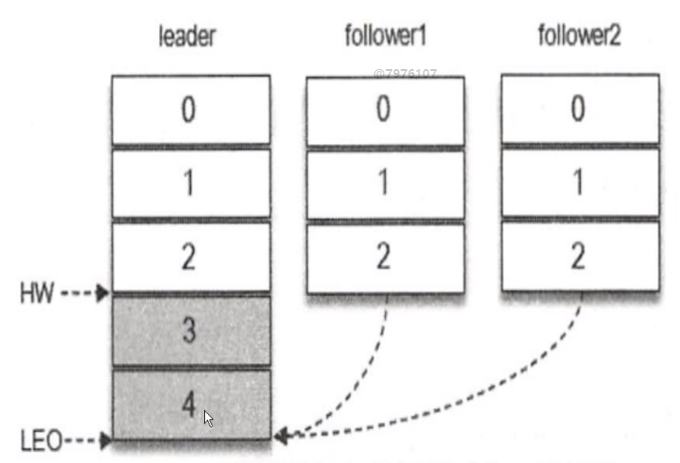
我的消息肯定是先发送到主副本上,然后从 3、4 写入成功之后,HW 不变, 从副本还没有同步数据,所以我认为你这条消息是不能消费的,还没有完全的去做数据同步成功,这个时候 主副本写完了 3、4 后,然后 从副本同时去监听拉取主副本中新的 3、4 两条消息。
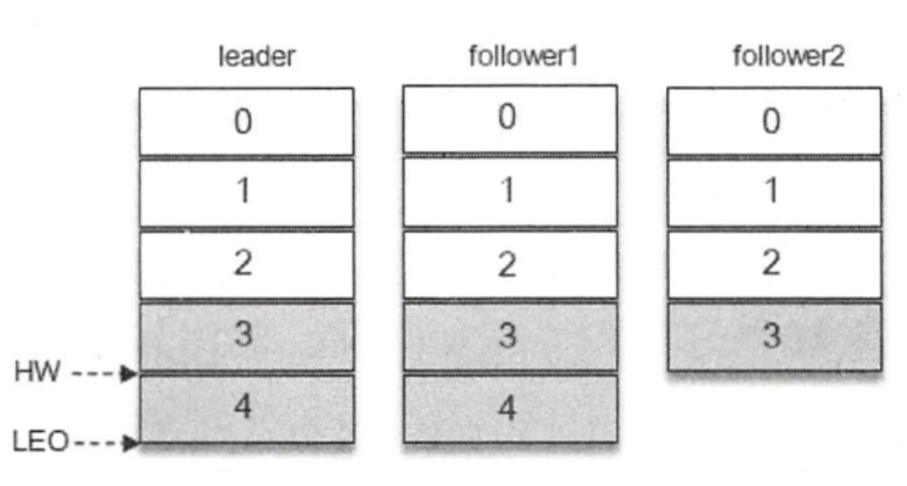
follower1 同步数据比较快,可能花了几十毫秒就搞定了,但是 follower2 可能同步 3 的时候快一点,但是同步 4 的时候非常慢,这个时候 HW 高水位线就在 3 这个位置上,因为所有的副本都同步成功了,这个时候 leader、follower1 有 4 但是 follower2 还没有同步成功,所以高水位线就卡在这里了,消费者只能消费 3 ,不能消费 4 ,因为 4 还没有同步完成。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号