



数据探索性分析案例实现
一、数据描述
对diamonds数据集进行描述,该数据集总共由8个部分十个字段组成。
1.color:色彩字段,分为了7个层级,从D到J来表示钻石颜色层级。
2.clarity:钻石的纯度,主要是表示钻石内的杂质以及钻石含量。
3.carat:钻石的重量单位克拉。
4.cut:钻石的切割质量。
5.depth:钻石的全深比。
6.table:钻石的台面。
7.price:钻石的价格。
8.钻石的大小数据,包括三个方位数据,x:长,单位mm,y:宽,单位mm,z:高,单位mm。
二、问题提出
1.既然要处理数据,我们怎么导入数据?
2.导入数据后如何查看数据?
3.数据可视化如何实现?
4.钻石的各个属性之间有没有什么关联性?
三、数据预处理
1.数据导入
import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib.cm as sns get_ipython().run_line_magic('matplotlib', 'inline') df=pd.read_csv(r'diamonds.csv')
2.数据集查看
print("输出数据集:") print(df.head())
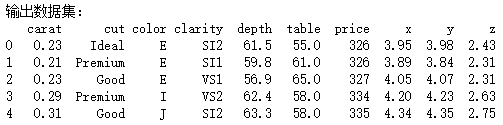
3.数据统计
print("数据统计信息:") print(df.describe())
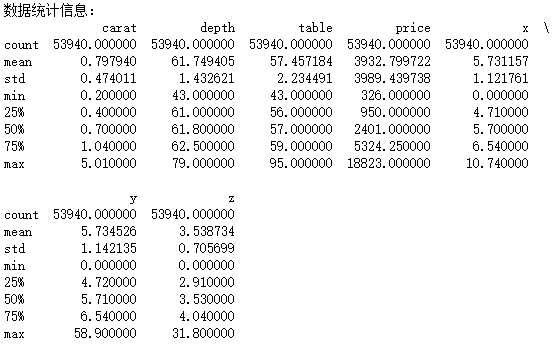
四、数据清洗
1.缺失值
df.isnull().sum()
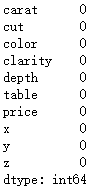
2.数据类型统计
print("数据类型统计:") print(df.info())

3.处理缺失值
df.dropna(inplace=True) df.dropna(thresh=2) df.dropna(how='all') df.dropna(axis='columns')
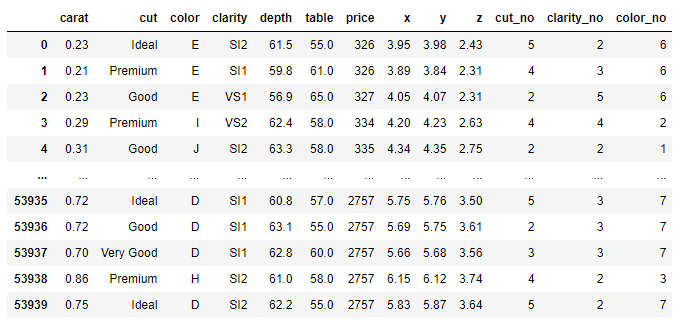
五、数据可视化
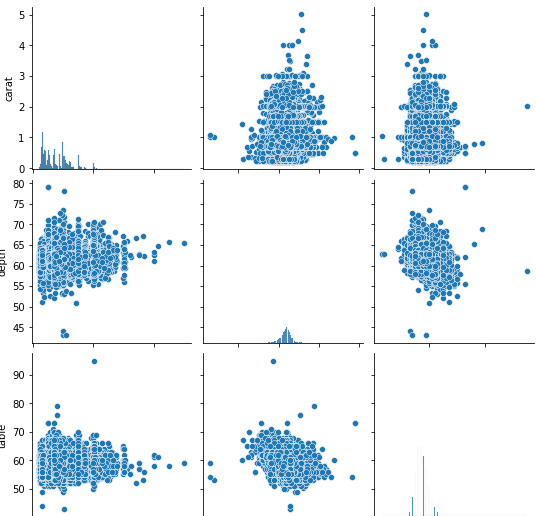
1.查看整体多对关系
import seaborn as sns sns.pairplot(df) plt.show()
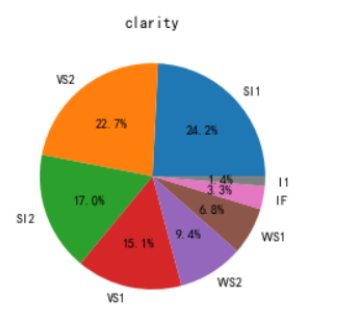
2.扇形图
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] plt.pie(x=df['clarity'].value_counts(),labels=df['clarity'].value_counts().index,autopct='%.1f%%',) plt.title(u'clarity') plt. show()
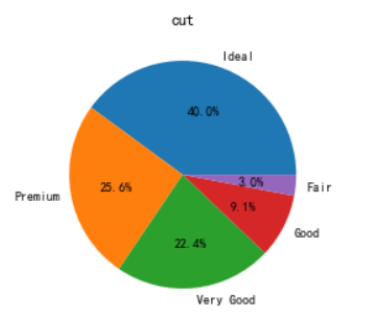
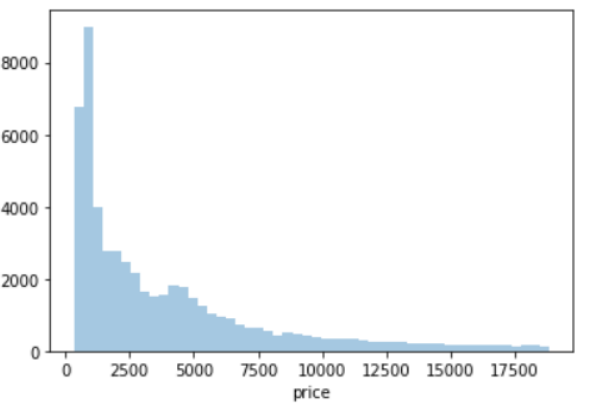
3.直方图
sns.distplot(df['price'],kde=False)
4.折线图
sns.boxplot(data=df['z']) plt.show()
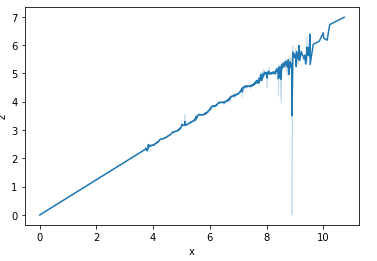
5.散点图
sns.jointplot(x="x", y="y", data=df,color='blue', kind='scatter'); plt.show()

6.箱型图查看异常值
sns.boxplot(data=df['z']) plt.show() r=[x for i,x in enumerate(df.index) if df.z[i]>10] print('Remvove row: ',r) df.drop(r,axis=0,inplace=True) sns.boxplot(data=df['z']) plt.show()
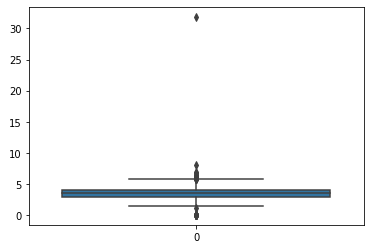
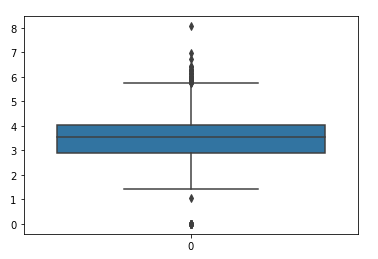
六、总结
1.切割质量越好,钻石的价格越高。
2.价格与钻石的长宽深有很强的相关性,而且基本都是正相关。
3.透明度越好的钻石的单价越高。
4.颜色越好的钻石的单价越高。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号