
一、分词介绍
1.1 什么是分词
分词就是指将一个文本转化成一系列单词的过程,也叫文本分析,在Elasticsearch中称之为Analysis。
举例:我是中国人 --> 我/是/中国人
1.2 分词api
指定分词器进行分词
示例:
POST /_analyze { "analyzer": "standard", "text": "hello world" }
效果如下:
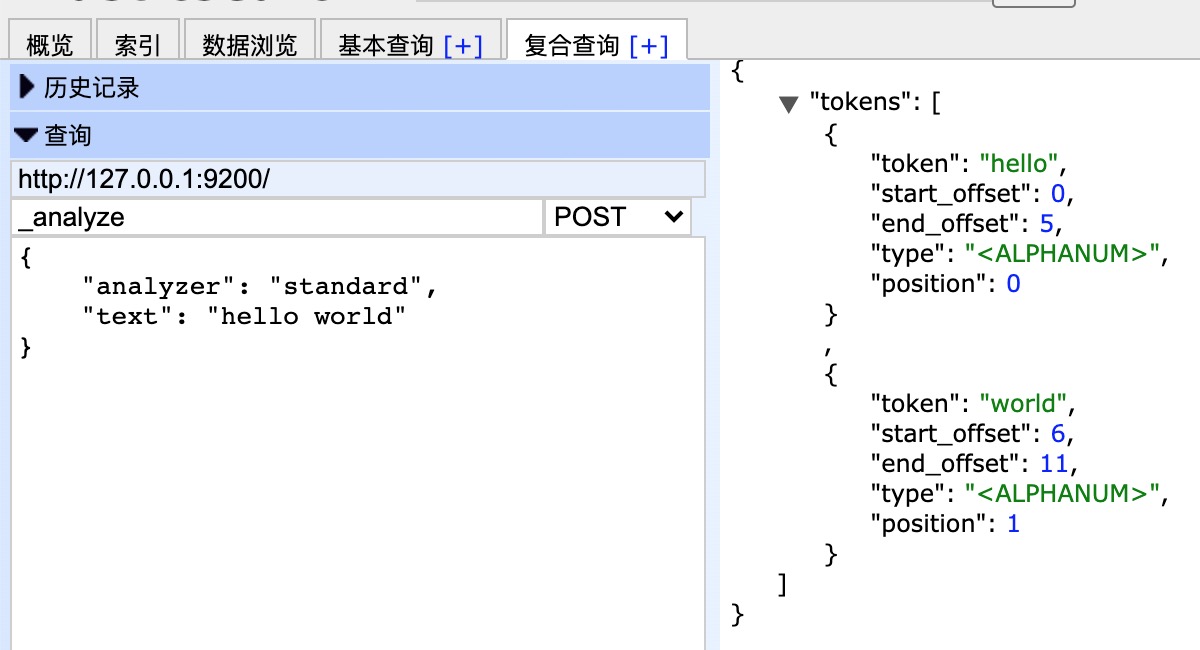
在结果中不仅可以看出分词的结果,还返回了该词在文本中的位置。
指定索引分词
示例
POST /person/_analyze { "analyzer": "standard", "field": "hobby", "text": "听音乐" }
效果如下:
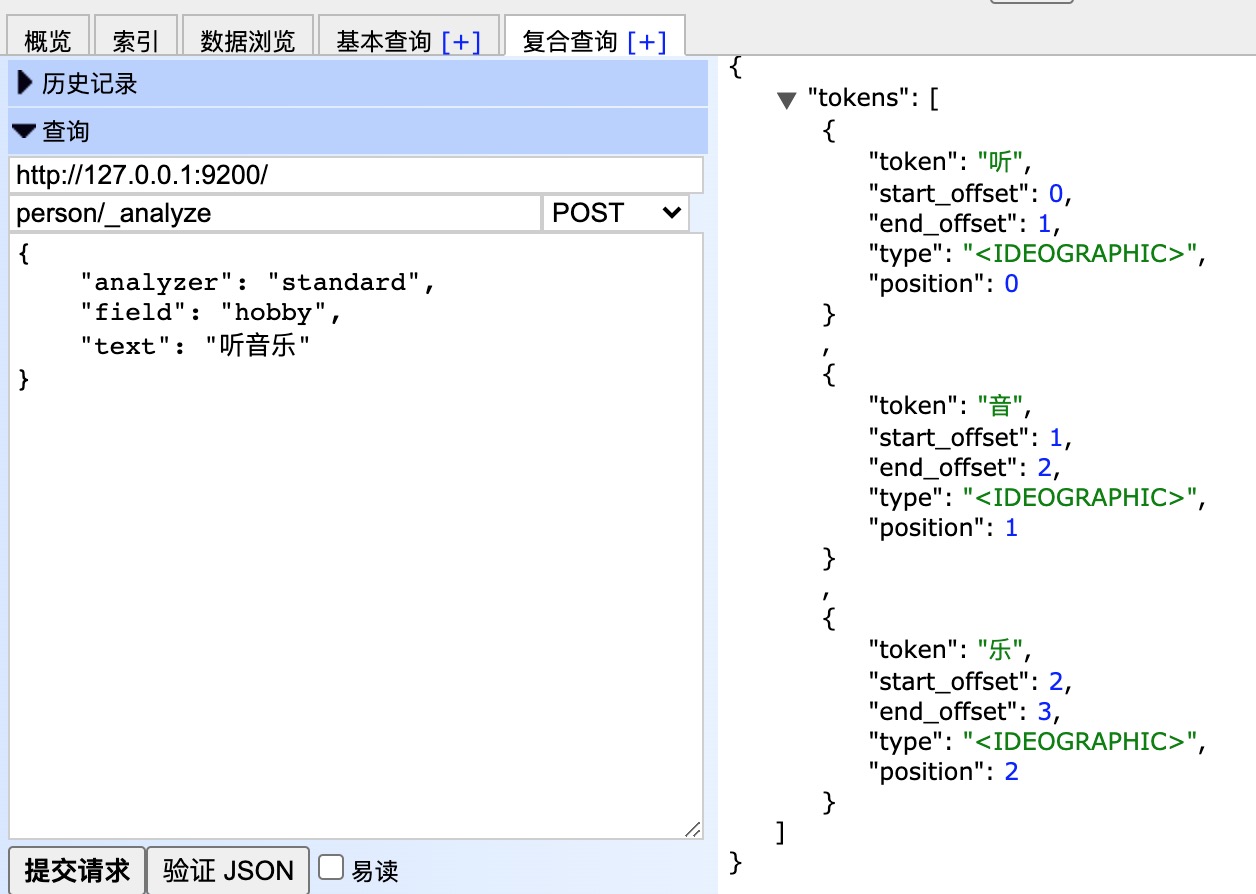
二、中文分词
中文分词的难点在于,在汉语中没有明显的词汇分界点,如在英语中,空格可以作为分隔符,如果分隔不正确就会造成歧义。
如:
- 我/爱/炒肉丝
- 我/爱/炒/肉丝
常用中文分词器,IK、jieba、THULAC等,推荐使用IK分词器。
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算 法的中文分词组件。新版本的IK Analyzer 3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提 供了对Lucene的默认优化实现。
采用了特有的“正向迭代最细粒度切分算法“,具有80万字/秒的高速处理能力 采用了多子处理器分析模式,支 持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇 (姓名、地名处理)等分词处理。 优化的词典存储,更小的内存占用。
IK分词器 Elasticsearch插件地址:https://github.com/medcl/elasticsearch-analysis-ik
IK分词器有两种分词方式,ik_smart 为最少切分,ik_max_word为最细粒度划分
2.1 安装IK分词器
1、从官网下载IK分词器,注意版本问题,与ES保持一致即可(本例ES版本7.6.1,IK版本7.6.1)
2、在es目录中的plugins目录,新建目录ik
命令:mkdir plugins/ik
3、介绍ik分词器下载包,到plugins/ik目录
命令:unzip -d /data/soft/elasticsearch-7.6.1/plugins/ik elasticsearch-analysis-ik-7.6.1.zip
4、重新es
查看java进程:jps
关闭es:kill (pid)
后台启动es:./bin/elasticsearch -d
2.2 测试IK分词器
示例:
POST /_analyze { "analyzer": "standard", "text": "我是中国人" } POST /_analyze { "analyzer": "ik_smart", "text": "我是中国人" } POST /_analyze { "analyzer": "ik_max_word", "text": "我是中国人" }
效果如下:
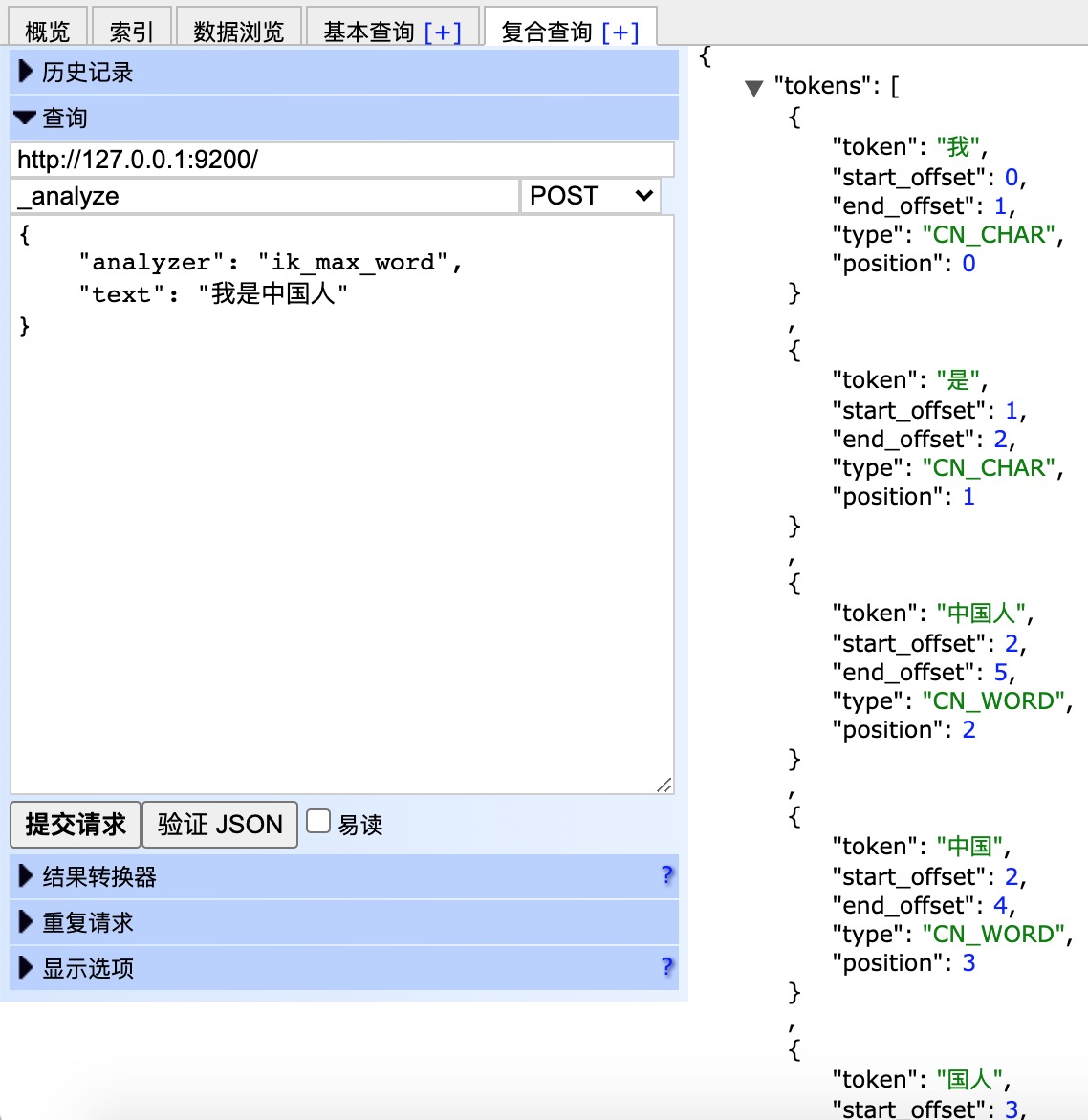
可以看到,已经对中文进行了分词。
2.3 修改ES默认分词器
ES的默认分词设置是standard,修改默认分词方法(这里修改person索引的默认分词为:ik_max_word):
PUT /person { "settings" : { "index" : { "analysis.analyzer.default.type": "ik_max_word" } } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号