Rethinking the Role of Pre-ranking in Large-scale E-Commerce Searching system
 这篇论文对粗排的角色进行了分析,讨论了粗排过度模拟精排的问题,分别从离线评估方式、样本构造、目标构造和学习框架上进行了改进。论文没有花太多篇幅在模型框架的创新上,而是在深入的分析和解决真实粗排场景中常见的问题,在各种细节上也处理的很到位,如多个正样本的list-wise损失函数的改造上。完整、仔细地读下来,对理清粗排的整个流程和挑战都很有帮助,值得学习。
这篇论文对粗排的角色进行了分析,讨论了粗排过度模拟精排的问题,分别从离线评估方式、样本构造、目标构造和学习框架上进行了改进。论文没有花太多篇幅在模型框架的创新上,而是在深入的分析和解决真实粗排场景中常见的问题,在各种细节上也处理的很到位,如多个正样本的list-wise损失函数的改造上。完整、仔细地读下来,对理清粗排的整个流程和挑战都很有帮助,值得学习。
来源:
- KDD'2023
- Taobao Search
反思粗排在大规模电商搜索系统中的角色。
由于巨大的数据量以及对系统实时反馈的要求,一个典型的工业排序系统通常由这些模块组成:召回(matching)、粗排(pre-ranking)和精排(ranking)。其中粗排通常被认为是一个迷你的精排,因为它需要对更多物品进行排序。因此,现在很多关于粗排的工作都是在模仿精排(mini-ranking),离线时也会使用和精排一样的评估方法,这就导致在评估粗排时出现了离线和线上指标不一致的问题。
这个工作中纠正了粗排的定义:粗排阶段的主要目标是输出一个最有的无序集合,而不是有序的物品列表,因为最终的物品顺序是由精排决定的。因此用精排的指标去评估粗排也是不恰当的。一味地模仿精排,粗排和精排越来越相似,短期内能够提升线上的效果,但长期来看,由于粗排过度依赖精排阶段的监督信号(例如曝光数据),有这些问题:
- 监督信号不一致,导致样本选择偏差。其实这也是一个老大难的问题,精排的监督信号比较好确定,但是粗排的目标是什么呢,毕竟粗排是一个中间阶段;
- 二者的输入样本分布不一致,粗排样本的某些有效特征可能因为在模仿精排时没有得到重用;
- 马太效应,由于以精排的目标作为监督信号,因此粗排模型偏向精排的目标。
论文中提出了一个新的评估指标评估粗排,All-Scenario Hitrate(ASH),力求对粗排的评估能在线上和线下取得一致。另外,也提出了All-Scenario-based Multi-Object Learning framework(ASMOL),一个基于全场景的多目标粗排学习框架。
ASH
目前评估粗排时,常用hitrate@k:
其中\(p_i\)表示物品,\(T\)表示目标集,一般是用户点击过的物品,\(k\)则是对粗排输出的截取数量,一般不会对粗排的整个输出进行评估,而是选择前k个进行评估。k的选择是一个不平凡的难题,如何选择才能体现模型的能力呢?理想的\(k\)是使其等于粗排输出集 R$的大小。但是从整体流程来看,用户点击过的物品是精排的输出,但是精排的输入又是粗排的输出,因此这会使得hitrate@R一定是等于1的。实际中一般k是远小于|R|的,这不能反映粗排的整体能力的。
为了反映粗排模型真实的能力,论文将其他场景中的正样本也引入,即对\(T\)进行扩充。具体的扩充策略见论文。
ASMOL
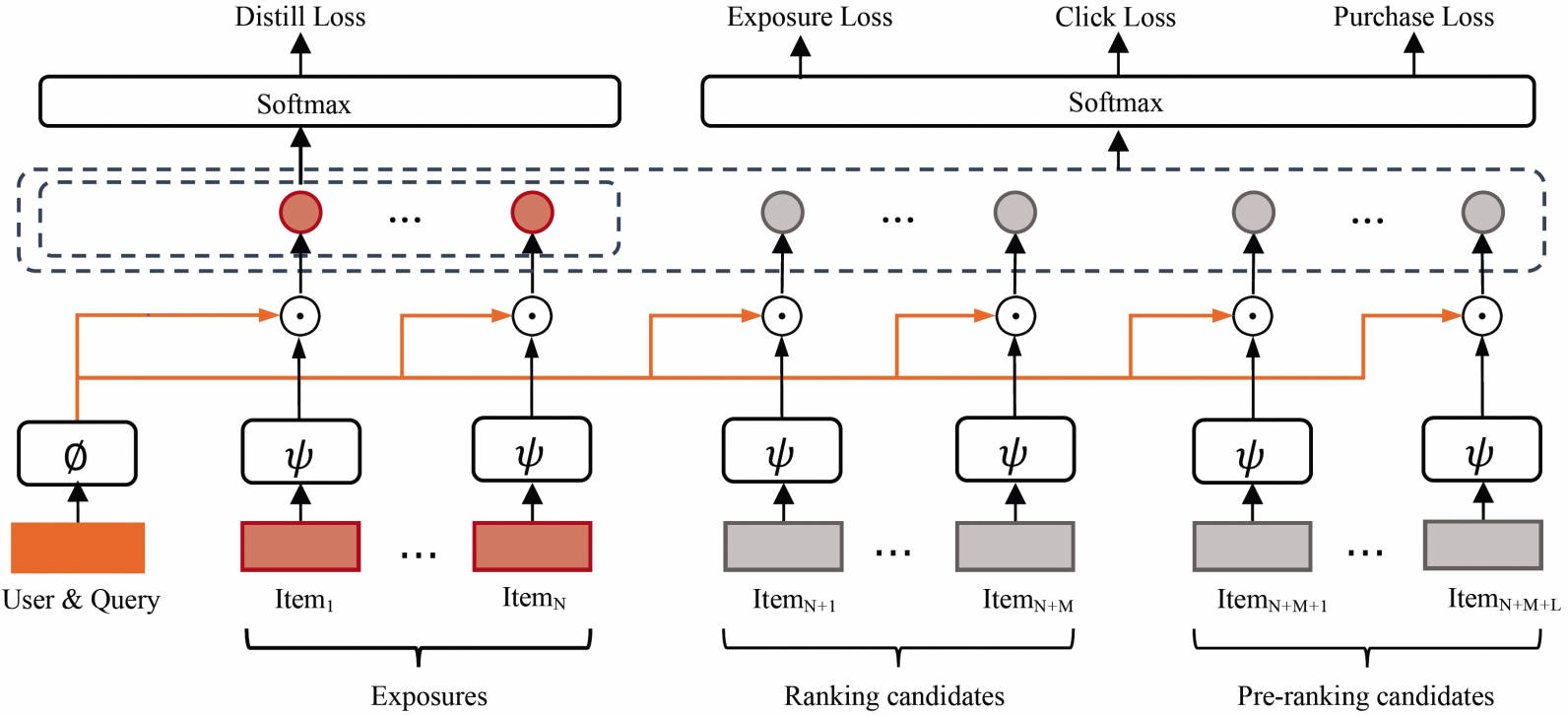
愚见,ASMOL并没有在模型结构上进行较大的改动,更多的是训练样本和训练目标上的改进。ASMOL的整体框架如上图所示。从输入上来看,因为场景是淘宝搜索,所以每个训练样本是针对某个用户的某个query而言的。每个训练样本的输入包含了:用户特征、query特征以及一个物品列表。训练目标则包含了:曝光、点击和购买。并且用现有的精排模型对粗排模型进行蒸馏。
训练样本
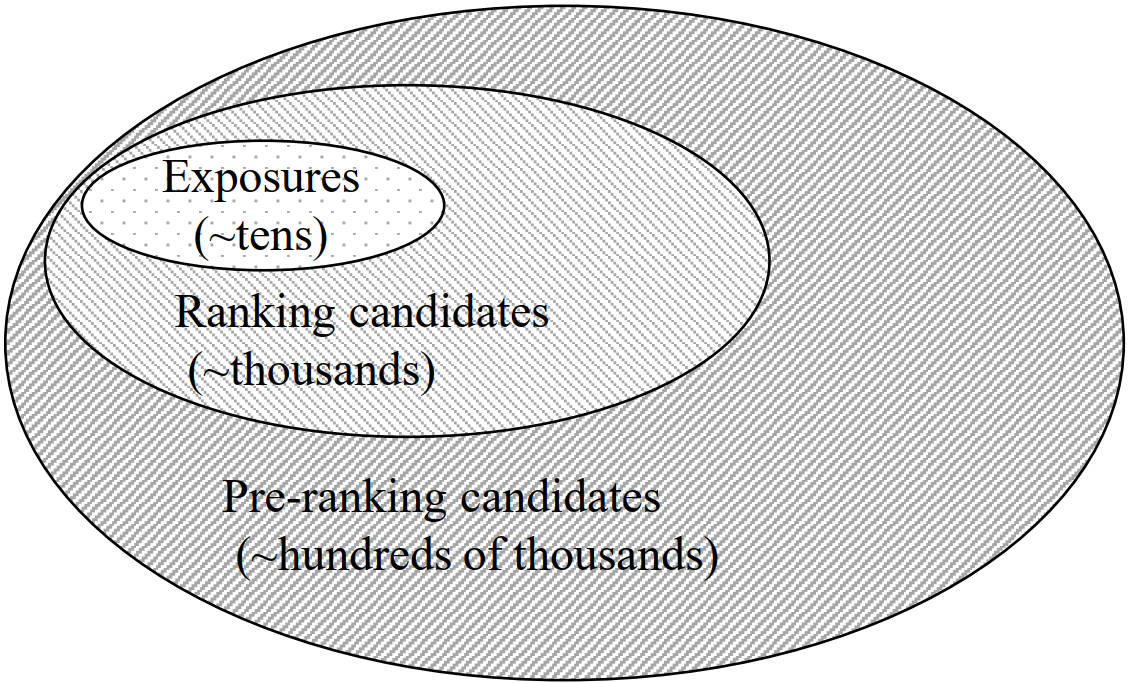
刚刚已经提到,一个训练样本的输入中包含了一个物品列表,列表里的物品分成三类:
- 曝光样本(Exposures,Ex):在一个请求中曝光的N个物品,包含了点击或者购买的物品;
- 精排样本(Ranking Candidates,RC):粗排模块送给精排模块且未能曝光的物品,一般是几千个,从中采样M个;
- 粗排样本(Pre-Ranking Candidates,PRC):召回模块送给粗排且未能进入精排阶段的物品,一般是几十万个,从中采样L个。
以上三者的对应关系如上图所示,每种物品都是不相交的。
为什么要在输入中输入这些样本呢?在传统的粗排模型训练过程中,输入的物品一般只是精排的输入(即本文中的Ex+RC),因此监督信号一般也与精排相似,这也导致了前文中提到的一些问题,其中一个很明显的就是样本选择偏差(SSB)——粗排模型只见过经过筛选后的物品,但是线上服务时又是以召回的输出为输入。
训练目标
论文中通过三个目标来对模型进行优化,三个目标的标签分别为:
- 全场景购买标签(All-Scenario Purchase Label,ASPL):用户在任一场景中购买了物品,则该物品的标签为1;
- 全场景点击标签(All-Scenario Click Label,ASCL):用户在任一场景点击了物品,则该物品的标签为1。由于用户在购买一个物品前必须点击之,因此一个物品的ASPL标签为1则其ASCL也为1;
- 曝光标签(Adaptive Exposure Label,AEL):物品是搜索场景中曝光的物品,则该物品的标签为1,由于被点击的物品必先被曝光,因此一个物品的ASCL为1则其AEL也为1。
很显然,以上三个物品是一个逐步包含的关系,即:
联系输入的训练样本中的物品列表,很显然Ex对应的物品在三个目标中一定都是正样本,而RC和PRC由于根本就没有被曝光,因此也不会被购买或者点击,因此RC和PRC都是负样本。并且,PRC是简单的负样本,而RC是难一些的负样本。
这三个目标的损失加权相加得到:
对于每个任务,计算list-wise形式的损失:
其中,\(\mathcal{D}\)表示对应任务的正样本集合,\(\mathcal{S}\)表示每个训练样本中的物品集合,\(z\)表示模型输出的每个样本的分数。以上的这个list-wise的损失适用于列表中只有一个正样本的情况,并不适用于多个正样本的情况(参考论文Improved Deep Metric Learning with Multi-class N-pair Loss Objective),论文的附录中也对list-wise的损失进行了修正。
蒸馏精排
除了以上三个目标外,论文中还用精排模型的CTR和CTCVR指导粗排模型的学习,其中主要涉及到样本选择的问题,即在哪些样本上进行蒸馏。
总结
这篇论文对粗排的角色进行了分析,讨论了粗排过度模拟精排的问题,分别从离线评估方式、样本构造、目标构造和学习框架上进行了改进。论文没有花太多篇幅在模型框架的创新上,而是在深入的分析和解决真实粗排场景中常见的问题,在各种细节上也处理的很到位,如多个正样本的list-wise损失函数的改造上。完整、仔细地读下来,对理清粗排的整个流程和挑战都很有帮助,值得学习。
欣赏一下北京的夜景😀


 浙公网安备 33010602011771号
浙公网安备 33010602011771号