Scrapy基础 --- #1
这是 DataWhale 新闻推荐系统实战的 Task3,主要任务有:
- 爬虫
- 构建画像
- 物料入库
本篇博客主要参考Fun-rec的文档,在这里。
本篇博客主要内容是 scrapy 的介绍,以及项目中新闻物料的爬取和保存。
Scrapy
说起爬虫框架,那 scrapy 必是当之无愧的一哥了。虽然我还没用 scrapy 写过爬虫,但也是仰慕已久。犹记当初刚学了一点 python,尝试的第一个项目就是写爬虫,那时候的爬虫还是用 requests 库来做的。那时候第一次接触这么花里胡哨丰富多彩的东西,心理甚是激动,熬夜学习 html、css、xpath、Beautiful Soup 等东西(虽然现在已经忘得差不多了),但是在学得半吊子的情况下,用着这几个简陋的工具,也是爬到了不少好东西(嘿嘿🤭,具体是什么就不说了)。学完爬虫后感觉自己会了不少东西,网上这么多东西都尽逃不出我手,一时之间得意的很。后来慢慢的兴趣漂移了,开始晚一些其他的东西了,直到今天,漂移到了推荐系统上,不知道以后还要飘到哪,嗨~🤨。
先看看 scrapy 的自我介绍:
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
里面提到了两个很相似的词:
- web crawling:爬取和存储一个站点上的所有数据
- web scraping:抽取一个站点上的指定内容的数据,例如淘宝网上的产品数据
可以参看下面图,来自这里

从上面的介绍,我们知道了 scrapy 有两个主要的功能:网页抓取和内容抽取。
官网的一个例子
看一下这段代码:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text::text').get(),
}
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
我们把它保存在 quotes_spider.py 这个文件里,然后在文件所在的目录下执行:scrapy runspider quotes_spider.py -o quotes.jl。看一下回车后输出的内容:
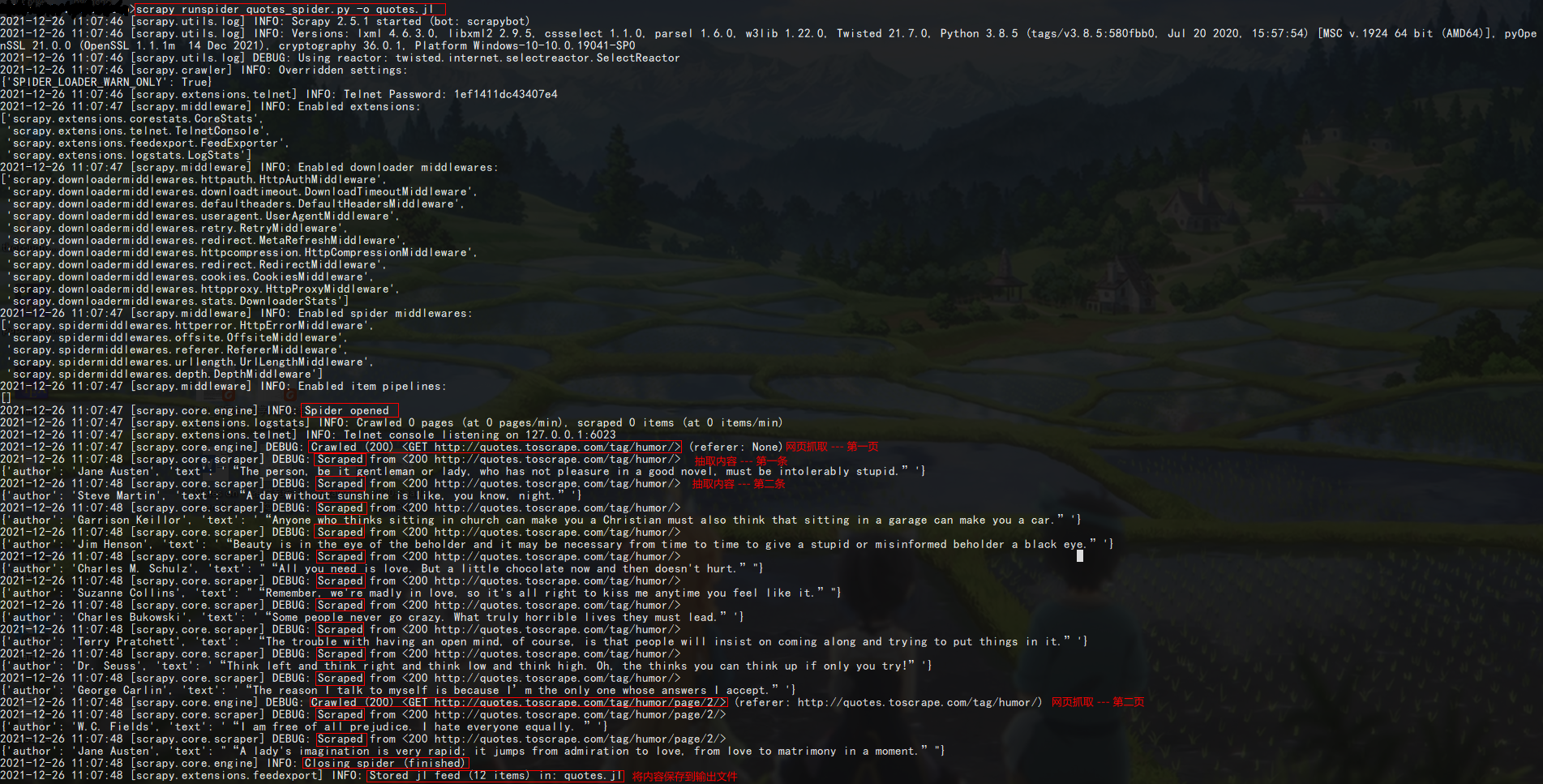
可以看到,scrapy 先是启动了一些中间件(middlewares),然后找到了 Spider(即 quotes_spider.py 中继承了 scrapy.Spider 的类),然后打开了爬虫(Spider opened)。接着就是爬取网页(Crawled)(Q1.怎么知道爬取哪个网页的呢?),抓取到一个网页后就会按照代码制定的规则解析其中的内容(Scraped)。一页的内容处理完后就抓取下一页(Q2.下一页是如何获得的呢?),然后继续抽取数据,知道没有下一页了,最后关闭爬虫(Closing spider),再把内容保存到输出文件(Stored)。整理以下流程:
- 启动一些中间件;
- 启动爬虫;
- 爬取网页;
1.按照规则抽取数据;
2.是否有下一页,有则返回3; - 关闭爬虫;
- 保存数据。
在梳理过程的时候我们有两个疑问:
- 怎么知道爬取哪个网页的呢?
- 下一页是如何获得的呢?
我们在下一节寻找答案。
Scrapy 架构
先看一下官网给出的架构图:
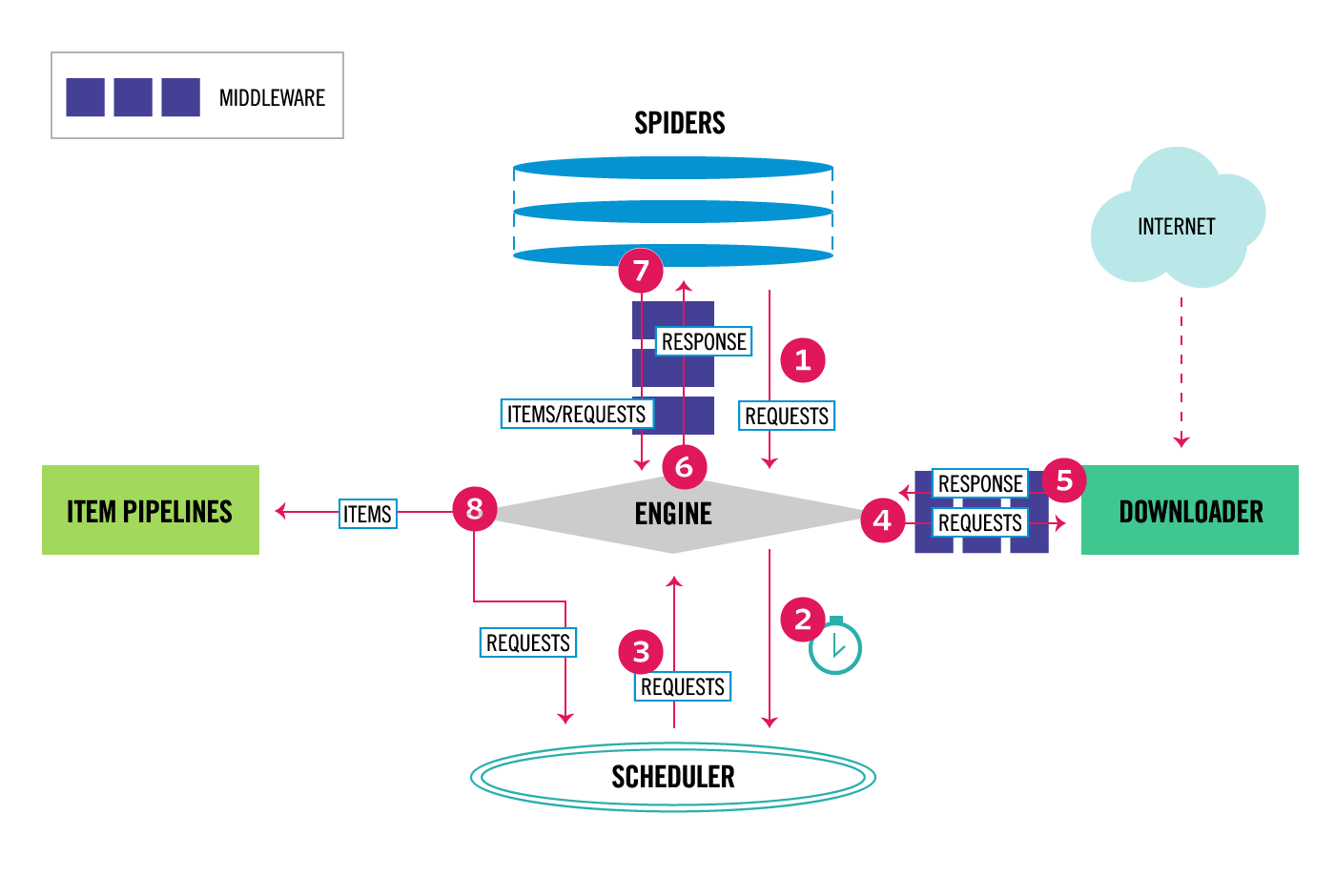
官网给出的 scrapy 工作流程:
- Engine 从 Spider 那拿到初始的爬取请求;
- Engine 在 Scheduler 安排手中拿到的请求,并请求下一个要爬取的请求;
- Scheduler 将下一个要爬取的请求返回给 Engine;
- Engine 通过下载中间件(见 process_request() )将请求发送给 Downloader;
- 完成下载后,Downloader 生成一个响应,通过下载中间件(见 process_response() )将其发送给 Engine;
- Engine 接收来自 Downloader 的响应,并通过 Spider 中间件(见 process_spider_input() )将其发送给 Spider,让 Spider 来处理响应;
- Spider 处理响应并通过 Spider 中间件把抽取到的项目和下一个要跟踪的请求传给 Engine;
- Engine 收到项目后,将其发送到 Item Pipelines,然后将处理过的请求发送给 Scheduler,并请求下一个要爬取的请求(如果有的话);
- 以上过程重复直至 Scheduler 中没有新的请求。
从上述流程我们可以找到未解答的两个问题:
- 怎么知道爬取哪个网页的呢?
从 spider 那里拿到初始的请求。回到那个例子来看,
start_urls指定了我们定义的那个爬虫从哪里开始爬取。
- 下一页是如何获得的呢?
也是来自 spider。回到那个例子,下一个要爬取的请求是通过
next_page = response.css('li.next a::attr("href")').get()得到的,然后通过yield response.follow(next_page, self.parse)将下一个请求发送给了 Engine。
通过架构图和工作流程,我们也看出来了 scrapy 中有一些重要的角色,比如处于 c 位的 Engine 和 Scheduler,当然每一个成功的系统都离不开每一颗螺丝的付出。
Components
-
Engine
Engine 负责控制数据(如请求、抽取的内容等)在 scrapy 组件间的流动,并且当一些特定的动作出现后触发相应的事件。 -
Scheduler
Scheduler 从 Engine 接收请求,并将它们放入队列中,等 Engine 请求它们的时候将其发送给 Engine; -
Downloader
Downloader 负责把网页从被爬取的站点抓取下来,然后发送给 Engine; -
Spiders
Spider 是由用户自定义的爬虫类(需要继承 scrapy.Spider),负责解析响应,从中抽取项目,或者需要额外跟踪的请求(例如下一页); -
Item Pipeline
Item Pipeline 负责处理被 Spiders 抽取的项目。Item Pipelines 典型的工作内容包括清洗、验证及持久化保存。 -
Downloader middlewares
Downloader middlewares 是位于 Engine 和 Scheduler 间的狗子钩子(hook),当有请求从 Engine 传递给 Downloader 时,Downloader middlewares 就会先处理这些请求,同理,当响应被传递给 Engine 时也会被其处理。 -
Spider middlewares
Spider middlewares 是位于 Engine 和 Spiders 之间的钩子,能够处理 spider 的输入(响应)和输出(items 和请求)。 -
Event-driven networking
Scrapy 是构建在 Twisted 的基础上的,Twisted 是一个流行的事件驱动的网络框架。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号