
深入浅出Kafka(四)之Kafka Broker
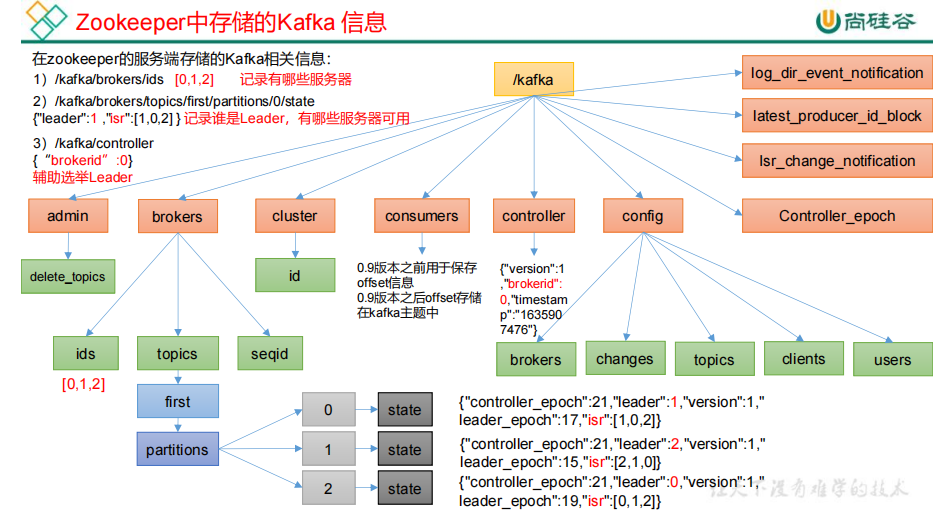
1.1Zookeeper 存储的 Kafka 信息
1.如何查看
(1)启动 Zookeeper 客户端。 [atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh (2)通过 ls 命令可以查看 kafka 相关信息。
2.在zookeeper的服务端存储的Kafka相关信息
admin,里面维护着删除的topic信息 brokers,维护着kafkabroker相关的节点信息,包括topic、topic中的分区信息等 cluster,集群元信息 consumers,0.9版本之前用于保存offset信息,0.9版本之后offset存储在kafka主题中 controller,维护着集群中leader信息 config,存储集群配置相关的信息
1.2 Broker 重要参数
1.replica.lag.time.max.ms: ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。
2.auto.leader.rebalance.enable 默认是 true。 自动 Leader Partition 平衡。
3.leader.imbalance.per.broker.percentage 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。
4.leader.imbalance.check.interval.seconds 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。
5.log.segment.bytes: Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。
6.log.index.interval.bytes:默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。
7.log.retention.hour Kafka 中数据保存的时间,默认 7 天。
2.Kafka 副本
2.1 副本基本信息
1)Kafka 副本作用:提高数据可靠性。
2.2Leader 选举流程
2.2.1Kafka核心总控制器Controller
1.在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态,同时负责管理集群broker 的上下线,所有 topic 的分区副本分配和 Leader 选举等工作
2.当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
2.2.1Kafka核心总控制器Controller选举机制
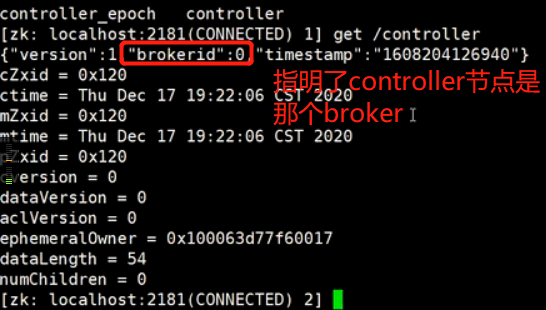
1.在kafka集群启动的时候,会自动选举一台broker作为controller来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个 /controller 临时节点.zookeeper会保证有且仅有一个broker能创建成功,这个broker就会成为集群的总控器controller
2.当这个controller角色的broker宕机了,此时zookeeper临时节点会消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点,就是我们上面说的选举机制,zookeeper又会保证有一个broker成为新的controller。
3.具备控制器身份的broker需要比其他普通的broker多一份职责,例如下:
2.2.3 副本Leader 选举流程
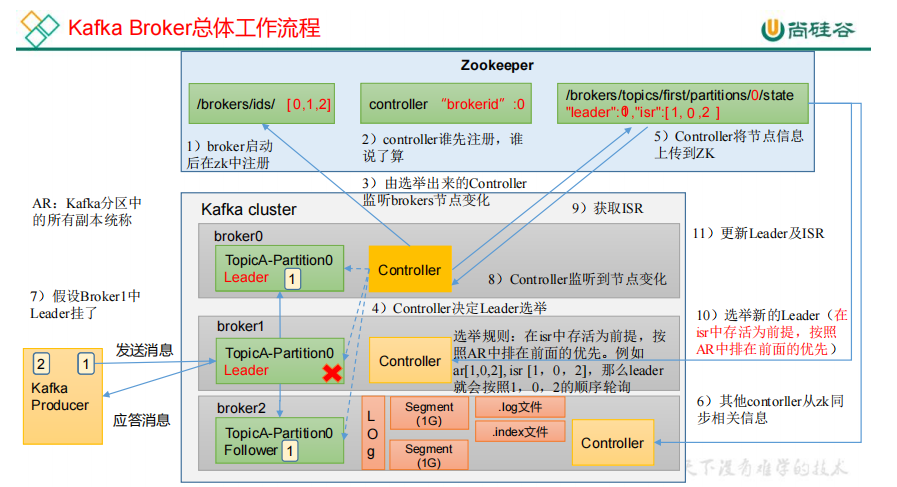
1)核心总控制器Controller选举成功之后,开始选择Leader副本
2)由选举出来的Controller监听brokers节点变化 ->(/kafka/brokers/ids [0,1,2]),同时决定Leader的选举.
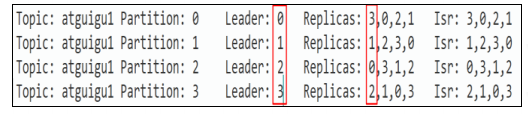
3)选举规则:在isr中存活为前提,按照AR中排在前面的优先。例如ar[1,0,2],isr [1,0,2],那么leader就会按照1,0,2的顺序轮询.
4)Controller将节点副本的Leader和Follower信息上传到ZK->(/brokers/topics/first/partitions/0/state"leader"1: ,"isr":[1,0,2 ])
5)其他contorller从zk同步Leader和Follower等相关信息
6)假设Broker1中Leader挂了,这时由选举出来的Controller监听brokers节点变化.同时拉取ISR存活节点副本数
7)重新选举新的Leader,并且更新Leader及ISR
2.3Leader 和 Follower 故障处理细节
2.3.1HW与LEO
1.LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1
2.HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW,也就是所有副本中最小的LEO.保证消费者消费数据的一致性。
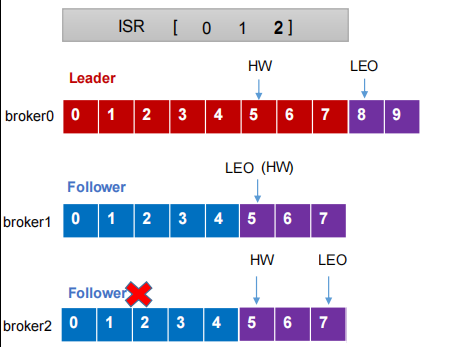
3.consumer最多只能消费到HW所在的位置
4.每个replica都有HW,leader和follower各自负责更新自己的HW的状态;
5.leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费
6.这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broker的读取请求,没有HW的限制
2.3.2ISR以及HW和LEO的流转过程
1.Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。
2.而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率.
3.流转过程
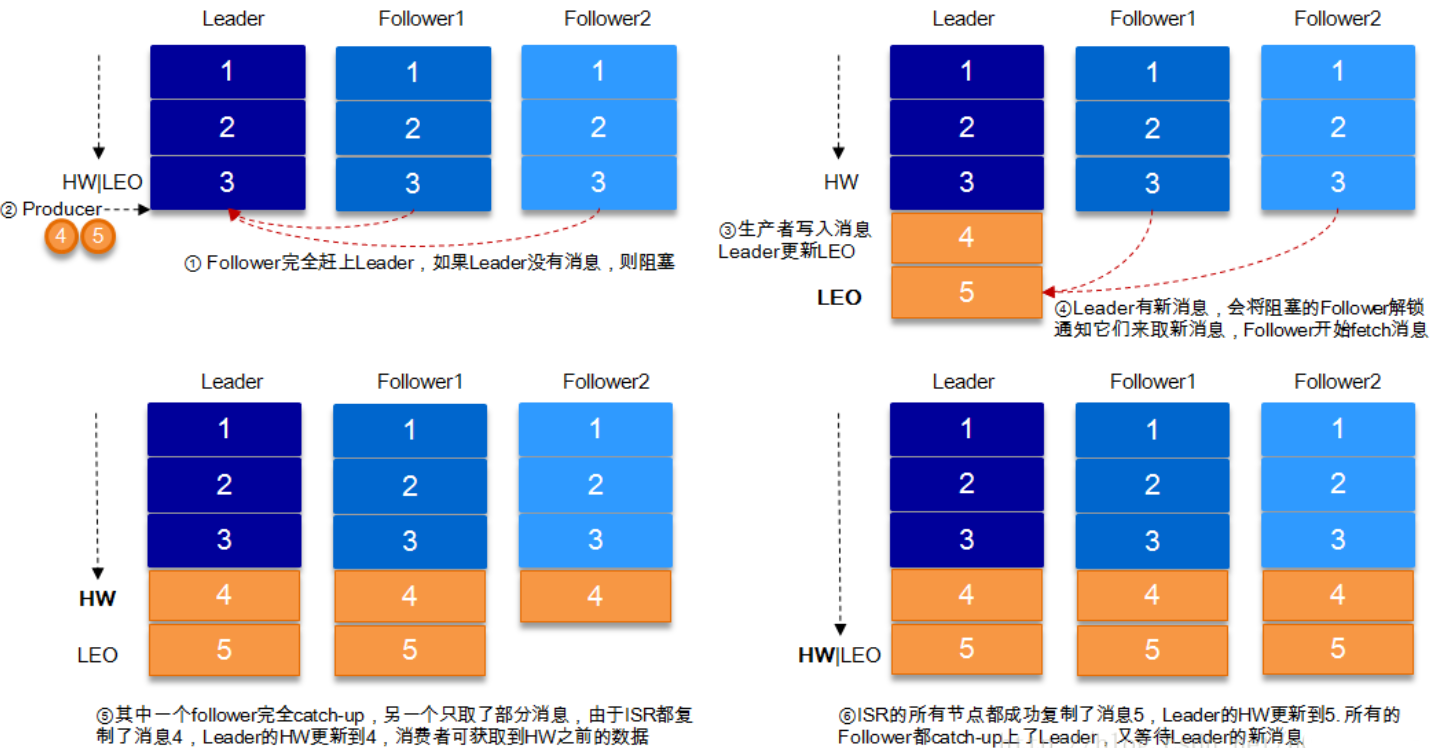
4.结合HW和LEO看下 acks=1的情况
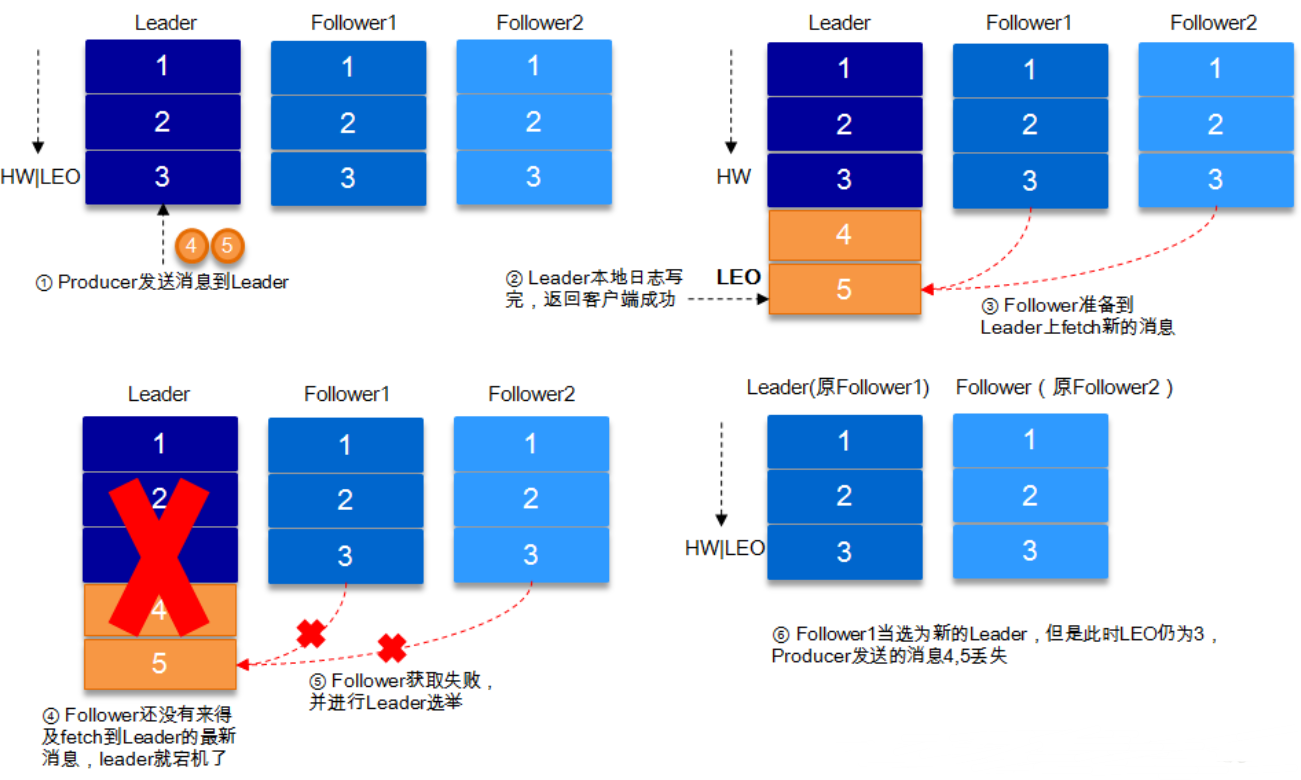
2.3.3Leader 和 Follower 故障处理细节
1.Follower故障
2.Follower故障说明:
(1) Follower发生故障后会被临时踢出ISR, 这个期间Leader和其他的Follower继续接收数据
(2)待该Follower恢复后,Follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向Leader进行同步。
(3)等该Follower的LEO大于等于该Partition的HW,即该Follower追上Leader之后,就可以重新加入ISR了。
3.Leader故障
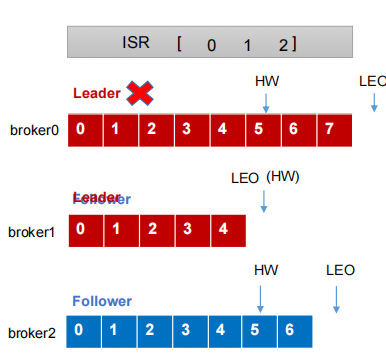
4.Leader故障说明
(1) Leader发生故障之后,会从ISR中选出一个新的Leader
(2)为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的部分截掉,然后从新的Leader同步数据。
2. 3. 生产经验——Leader Partition 负载平衡
1. 正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡
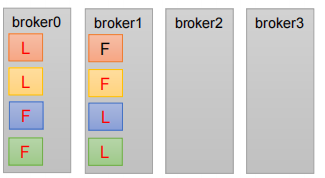
3.参数:
1.auto.leader.rebalance.enable,默认是true。 自动Leader Partition 平衡,生产建议关闭或者允许的不平衡的leader的比率设置大一些, 否则会消耗大量服务器的性能
3. 文件存储机制
3.1Topic 数据的存储机制
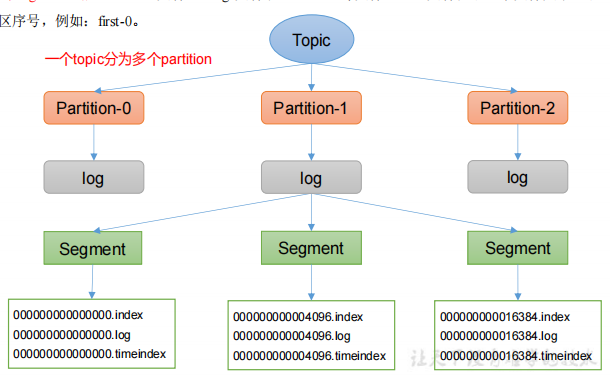
1.Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据。
2.Producer生产的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment
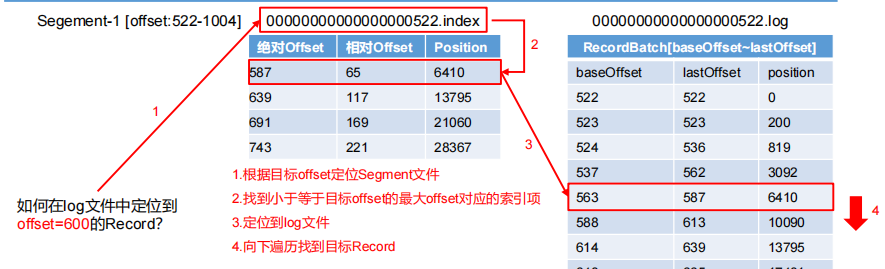
3.2数据的查找过程
3.3日志存储参数配置
1.log.segment.bytes:Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分成块的大小,默认值 1G。
3.4文件清理策略
1.Kafka 中默认的日志保存时间为 7 天.
2.Kafka 中提供的日志清理策略有 delete 和 compact 两种。
3.4.1清理策略的参数配置
3.4.2文件清理策略之delete
1.delete 日志删除:将过期数据删除 ;
2.基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳;
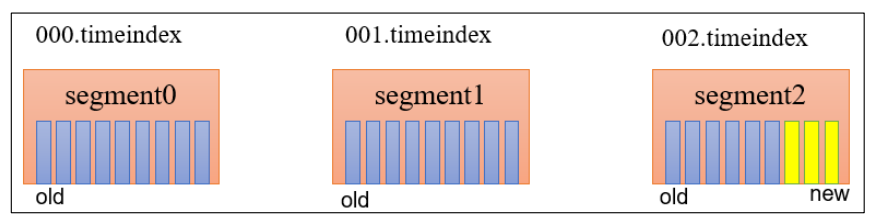
4.问题1:如果一个 segment 中有一部分数据过期,一部分没有过期,怎么处理?
5.问题1解决方案:数据过期的就等着,等着日志文件中,最大的时间戳对应数据过期后一起删除。
3.4.2文件清理策略之compact
1.compact日志压缩:对于相同key的不同value值,只保留最后一个版本
2.这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料
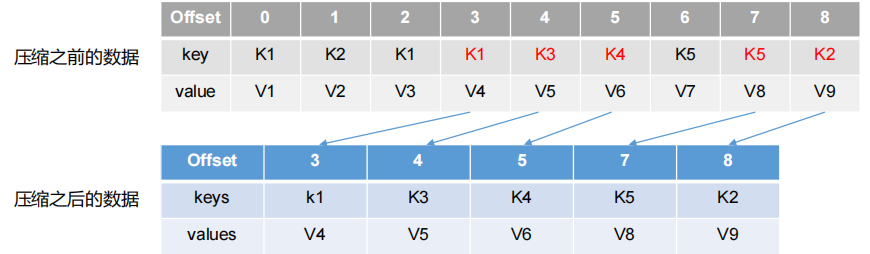
3.压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费
3.5高效读写数据
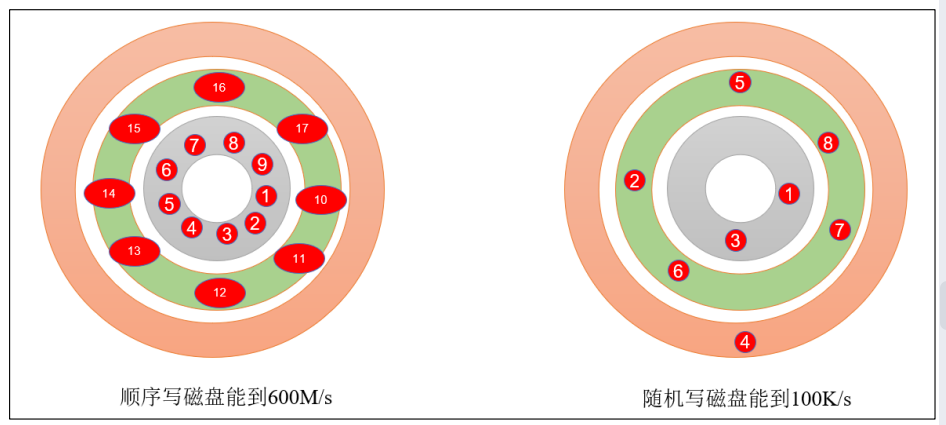
3.5.1顺序写磁盘
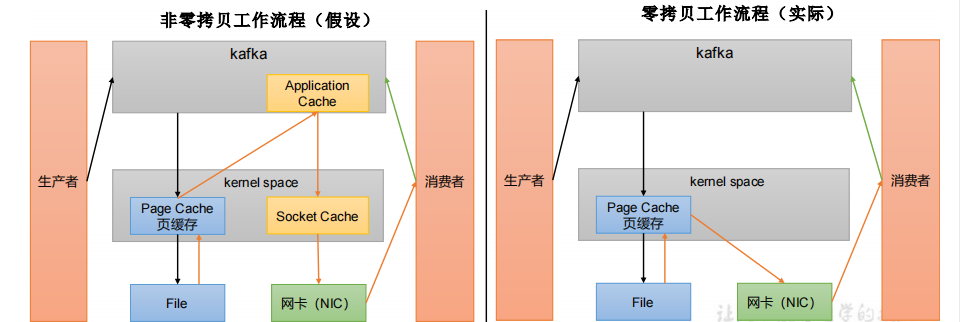
3.5.2页缓存 + 零拷贝技术
1.零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用走应用层,传输效率高
3.5.3参数配置
1.log.flush.interval.messages:强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号