

10 期末大作业
04 RDD编程练习
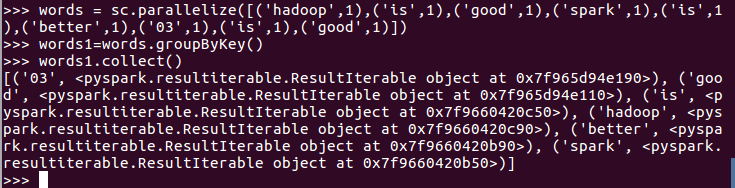
一、filter,map,flatmap练习:
1.读文本文件生成RDD lines
2.将一行一行的文本分割成单词 words
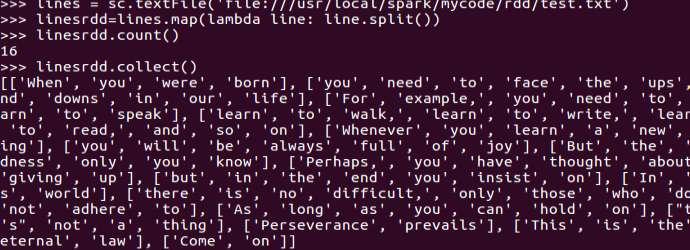
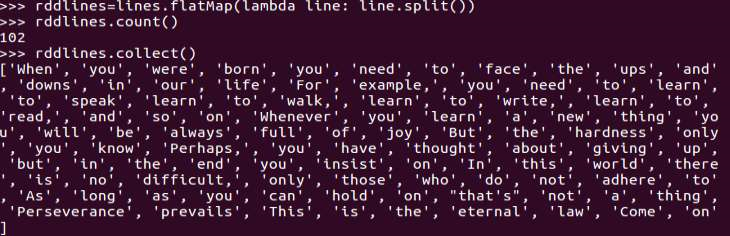
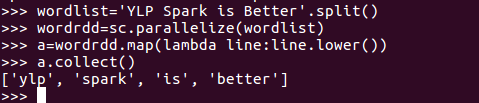
3.全部转换为小写
4.去掉长度小于3的单词

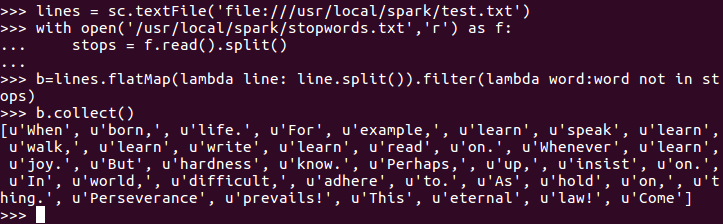
5.去掉停用词
6.练习一的生成单词键值对
05 RDD练习:词频统计,学习课程分数
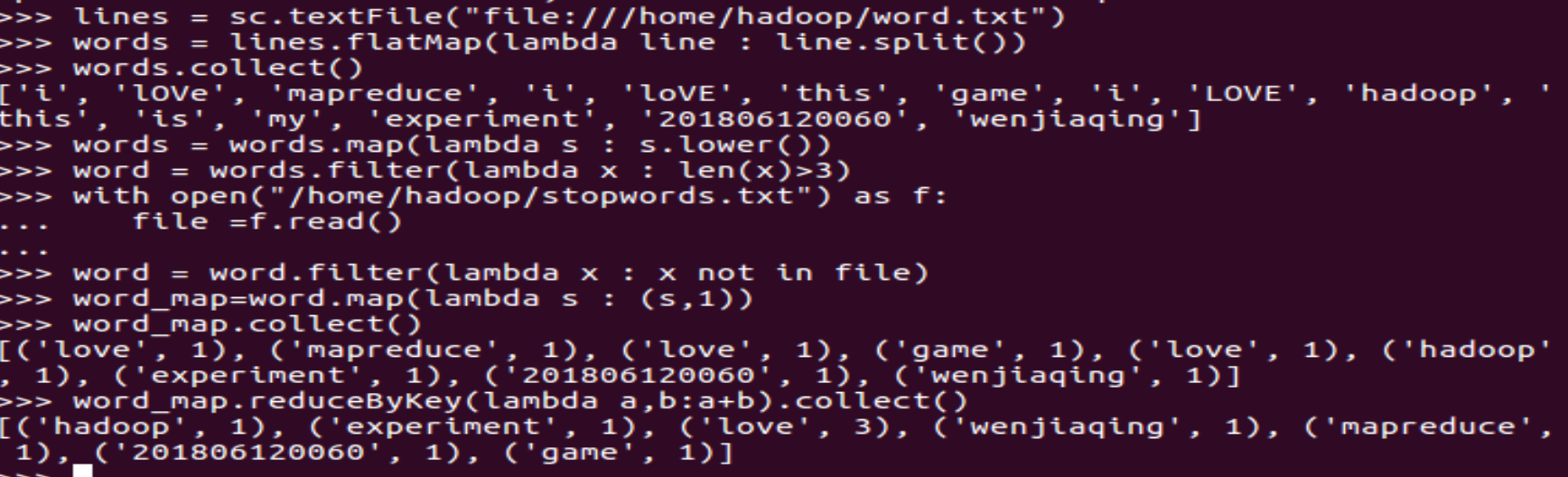
一、词频统计:
1.读文本文件生成RDD lines
2.将一行一行的文本分割成单词 words flatmap()
3.全部转换为小写 lower()
4.去掉长度小于3的单词 filter()
5.去掉停用词
6.转换成键值对 map()
7.统计词频 reduceByKey()
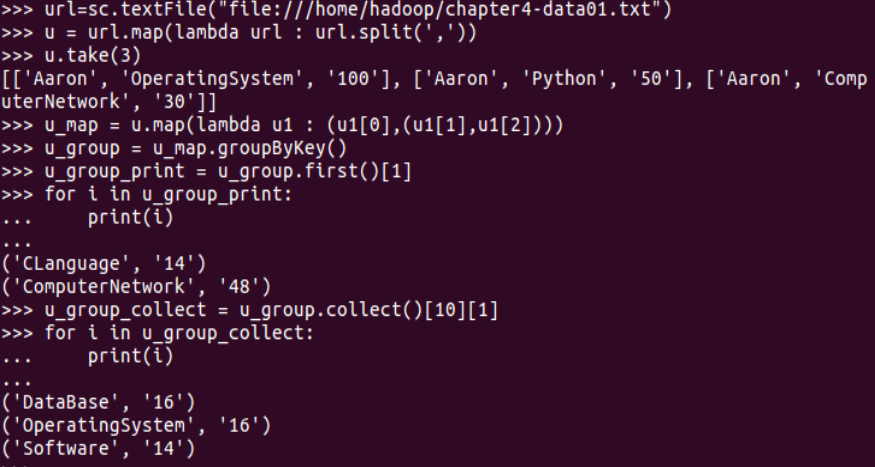
二、学生课程分数 groupByKey() -- 按课程汇总全总学生和分数
1. 分解出字段 map()
2. 生成键值对 map()
3. 按键分组 groupByKey()
4. 输出汇总结果 for i in <>:
07 从RDD创建DataFrame
1.pandas df 与 spark df的相互转换
df_s=spark.createDataFrame(df_p)
df_p=df_s.toPandas()


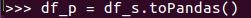
2. Spark与Pandas中DataFrame对比
http://www.lining0806.com/spark%E4%B8%8Epandas%E4%B8%ADdataframe%E5%AF%B9%E6%AF%94/
3.1 利用反射机制推断RDD模式
sc创建RDD
转换成Row元素,列名=值
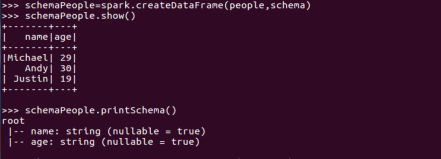
spark.createDataFrame生成df
df.show(), df.printSchema()



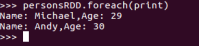
3.2 使用编程方式定义RDD模式
生成“表头”fields = [StructField(field_name, StringType(), True) ,...]
- schema = StructType(fields)


- 生成“表中的记录”
- 创建RDD转换成Row元素,
- 列名=值

- 把“表头”和“表中的记录”拼装在一起
- =spark.createDataFrame(RDD, schema)
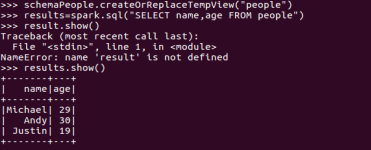
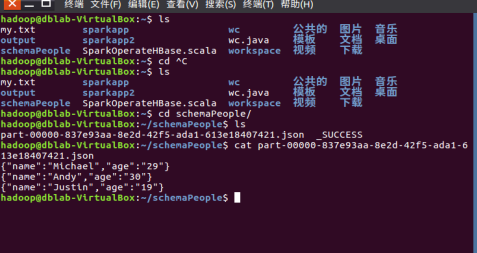
4. DataFrame保存为文件
df.write.json(dir)


大作业:
1.选择使用什么数据,有哪些字段,多大数据量。
数据:疫情数据
字段:省份、确诊人数、死亡人数、治愈人数、新增人数
2.准备分析哪些问题,可视化方式?(8个以上)
(1)中国现有感染人数情况, 地图
(2) 中国现有感染人数情况, 柱状图
(3)北上广深现有感染人数情况,条形图
(4)感染分布,地图
(5)日新增人数前五的省份,漏斗图
(6)日新增感染人数前五的省份,散点图
(7)中国疫情情况,饼图
(8)现有感染人数前五的省份, 象型图
3.当前进展。
获取了数据表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号