1.set
set是一个无序且元素不会重复的集合
#创建
set1={1,2} or
l = [1,2,3.3]
set2= set(l)
#方法
set2.add() 添加元素
set2.clear() 清楚元素
set2.difference() 两个集合 的差集 set1.difference(set2) set1不同于set2
对称差集 print set2.symmetric_difference(set1) {3}
#上述两种方法 均会生成一个新的结果 而difference_update 和 symmetric_difference_update 会覆盖之前的内容
#移除元素 remove() discard() 元素不存在的话 remove会报错
#pop函数随机移除 并且可以获取那个参数
#求交集intersection()
#isidsjoint() 判断有无交集 有返回false
set1.isdisjoint(set2)
#union() 并集
#update() 批量更新
练习:寻找差异 # 数据库中原有 old_dict = { "#1":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 }, "#2":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 } "#3":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 } } # cmdb 新汇报的数据 new_dict = { "#1":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 800 }, "#3":{ 'hostname':c1, 'cpu_count': 2, 'mem_capicity': 80 } "#4":{ 'hostname':c2, 'cpu_count': 2, 'mem_capicity': 80 } } 需要删除:? 需要新建:? 需要更新:? 注意:无需考虑内部元素是否改变,只要原来存在,新汇报也存在,就是需要更新
old_set = set(old_dict.keys())
update_list = list(old_set.intersection(new_dict.keys()))
new_list = []
del_list = []
for i in new_dict.keys():
if i not in update_list:
new_list.append(i)
for i in old_dict.keys():
if i not in update_list:
del_list.append(i)
print update_list,new_list,del_list
2.collection系列
http://www.cnblogs.com/wupeiqi/articles/4911365.html
3.深浅拷贝
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
对于其它的数据类型:
a.赋值
只是创建一个变量 该变量指向原来的内存地址
b.浅拷贝
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n3 = copy.copy(n1)
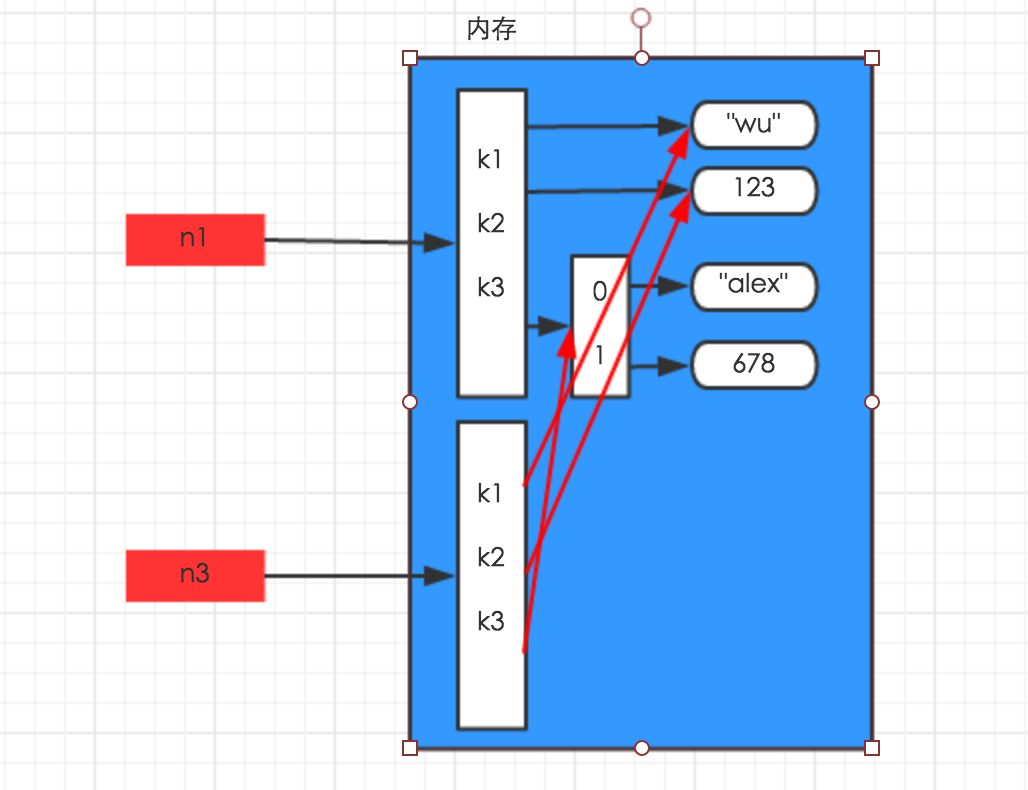
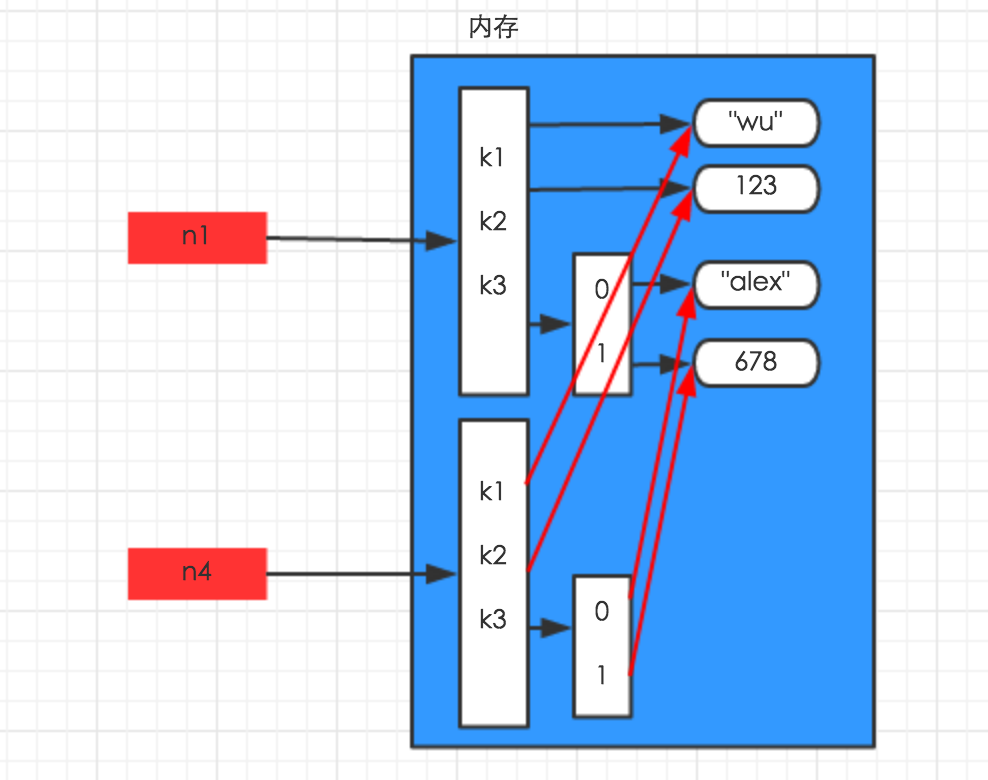
c.深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n4 = copy.deepcopy(n1)
4.内置函数

官网:https://docs.python.org/3/library/functions.html
chr() 数字转为ASCII码
ord() 字符转化为数字
enumerate() for循环前面加数字
format( ) 字符串格式化
5.参数
普通参数
默认参数
动态参数
func(*args) func(**kwargs) func(*args,**kwargs)
6.文件操作
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
- r ,只读模式【默认】
- w,只写模式【不可读;不存在则创建;存在则清空内容;】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f:
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 及以后,with又支持同时对多个文件的上下文进行管理,即:
with open('log1') as obj1, open('log2') as obj2:
pass
 浙公网安备 33010602011771号
浙公网安备 33010602011771号