mmdetection训练voc数据集
📖 首先需要准备好数据集,这里有xml标签数据转voc数据集格式的说明以及免费分享的数据集:xml转voc数据集 - 一届书生 - 博客园 (cnblogs.com)
1. 准备工作目录
我们的工作目录,也就是mmdetection目录,如下所示:
.
├── configs
│ ├── _base_
│ │ ├── datasets
│ │ ├── models
│ │ ├── schedules
│ │ └── default_runtime.py
│ ├──pascal_voc
│ │ └── ......
│ └──......
├── data
│ └── VOCdevkit
│ └── VOC2007
│ ├── Annotations
│ │ ├── 003002_0.xml
│ │ ├── 003002_1.xml
│ │ └── ......
│ ├── ImageSets
│ │ └── Main
│ │ ├── test.txt
│ │ ├── train.txt
│ │ ├── trainval.txt
│ │ └── val.txt
│ └── JPEGImages
│ ├── 003002_0.jpg
│ ├── 003002_1.jpg
│ └── ......
├── mmdet
│ ├── core
│ ├── datasets
│ └── ......
├── tools
│ └── ......
└── ......
-
configs就是我们的训练所设计的配置的文件夹,我们需要进行修改符合voc格式。
-
data就是我们的数据集文件,文件目录如上。
-
mmdet是我们所需要修改的,主要是对训练的一些数据进行配置,需要修改类别数,。
-
tools是我们的mmdetection提供的工具箱,里边包含我们要用的训练和测试文件。
2. 修改mmdetection模型的配置
主要分为两部分,configs文件夹和mmdet文件夹。
2.1 修改configs文件夹
配置文件指的是 mmdetection/configs 下的文件,也就是你要训练的网络的一些配置。默认情况下,这些配置文件的使用的是 coco 格式,只有 mmdetection/pascal_voc 文件夹下的模型是使用 voc 格式,数量很少。如果要使用其他模型,则需要修改配置文件,这里以mmdetection/configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x.py 为例。
1️⃣ 我们先在目录 mmdetection/configs/pascal_voc 下创建一个 cascade_rcnn_r50_fpn_1x_voc0712.py 作为cascade使用voc数据集的配置文件。就是我们的模型,使用以下基础配置文件,如果想要修改,可以直接去基础配置文件里面改。
ascade_rcnn_r50_fpn_1x_voc0712.py 的内容如下:
_base_ = [
'../_base_/models/cascade_rcnn_r50_fpn_voc.py',
'../_base_/datasets/voc0712.py',
'../_base_/schedules/schedule_1x.py',
'../_base_/default_runtime.py',
]
runner = dict(type='EpochBasedRunner', max_epochs=7) # max_epochs就是我们要训练的总数,根据自己情况修改。
2️⃣ 我们先对 mmdetection/configs/_base_/models 目录下的创建一个 cascade_rcnn_r50_fpn_voc.py配置文件,文件的内容从同目录下 cascade_rcnn_r50_fpn.py 里面复制一下,然后进行以下修改。
在 cascade_rcnn_r50_fpn_voc.py配置文件中搜索 num_classes ,改成自己的类别数量,比如说我有一个类,我就改成1。配置文件里一共有三处。
3️⃣ 【可选】如果自己的显存比较小的话,可以修改 _base_/datasets/voc0712.py 文件里面的 img_scale 共两处,例如改成(600,400)。
4️⃣ 【可选】为了让训练过程更直观,以及节省存储空间,可以修改 _base_/default_runtime.py 里面的 interval ,一共有两个,第一个是模型权重的保存间隔,一般我们设置的比较大一点,例如20(根据你训练的总epoch而定)。第二个是日志的保存间隔,一般我们设置的比较小一点,例如1(根据你训练的总epoch而定)。
2.1 修改mmdet文件夹(修改完这里边的内容需要重新编译)
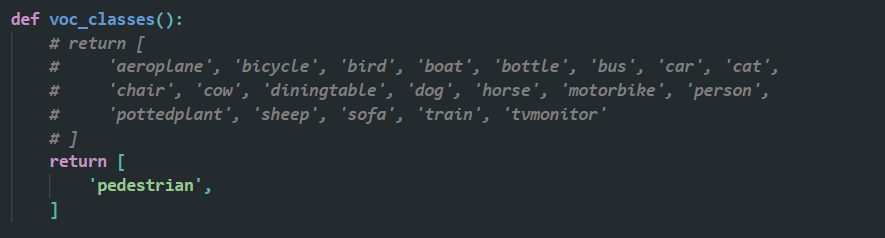
1️⃣ 修改 mmdetection/mmdet/core/evaluation/class_names.py ,把 voc_classes() 方法返回值,修改为自己的类别。例如我只有一类,我就改成下面这样,只有一类的后边加个逗号,有多类的不用加逗号。
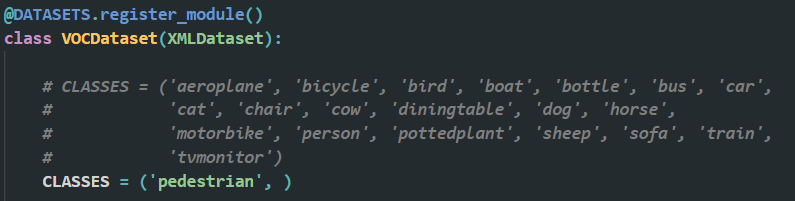
2️⃣ 修改 mmdetection/mmdet/datasets/voc.py ,把 CLASSES ,修改为自己的类别。例如我只有一类,我就改成下面这样,只有一类的后边加个逗号,有多类的不用加逗号。
⚠️⚠️⚠️ 两个文件夹都修改完后,在mmdetection文件夹下,运行命令,python setup.py install,重新编译一下,为了让所修改的内容生效。如果报错类别数量不对的话,请参考:# AssertionError: The `num_classes` (3) in Shared2FCBBoxHead of MMDataParallel does not matches the length of `CLASSES` 80) in CocoDataset - 一届书生 - 博客园 (cnblogs.com)
3. 开始训练
1️⃣ 单GPU训练
python tools/train.py configs/pascal_voc/cascade_rcnn_r50_fpn_1x_voc0712.py
2️⃣ 多GPU训练
bash tools/dist_train.sh configs/pascal_voc/cascade_rcnn_r50_fpn_1x_voc0712.py 2
- configs/pascal_voc/cascade_rcnn_r50_fpn_1x_voc0712.py 就是我们要训练模型的配置文件
- 2 是我们的GPU数目
4. 模型测试
python tools/test.py work_dirs/cascade_rcnn_r50_fpn_1x_voc0712/cascade_rcnn_r50_fpn_1x_voc0712.py work_dir s/cascade_rcnn_r50_fpn_1x_voc0712/latest.pth --show-dir work_dirs/cascade_rcnn_r50_fpn_1x_voc0712/test_show
可视化结果展示:
 |
 |
 |
同时我们的 work_dirs/mask_rcnn_r101_fpn_2x_coco/ 目录下还会有个json文件,可以可视化我们的一些评价指标的变化情况。为了方便显示,我们在 mmdetection/ 目录下新建一个 logs 文件夹,讲 json 文件拷贝到 logs 文件夹。
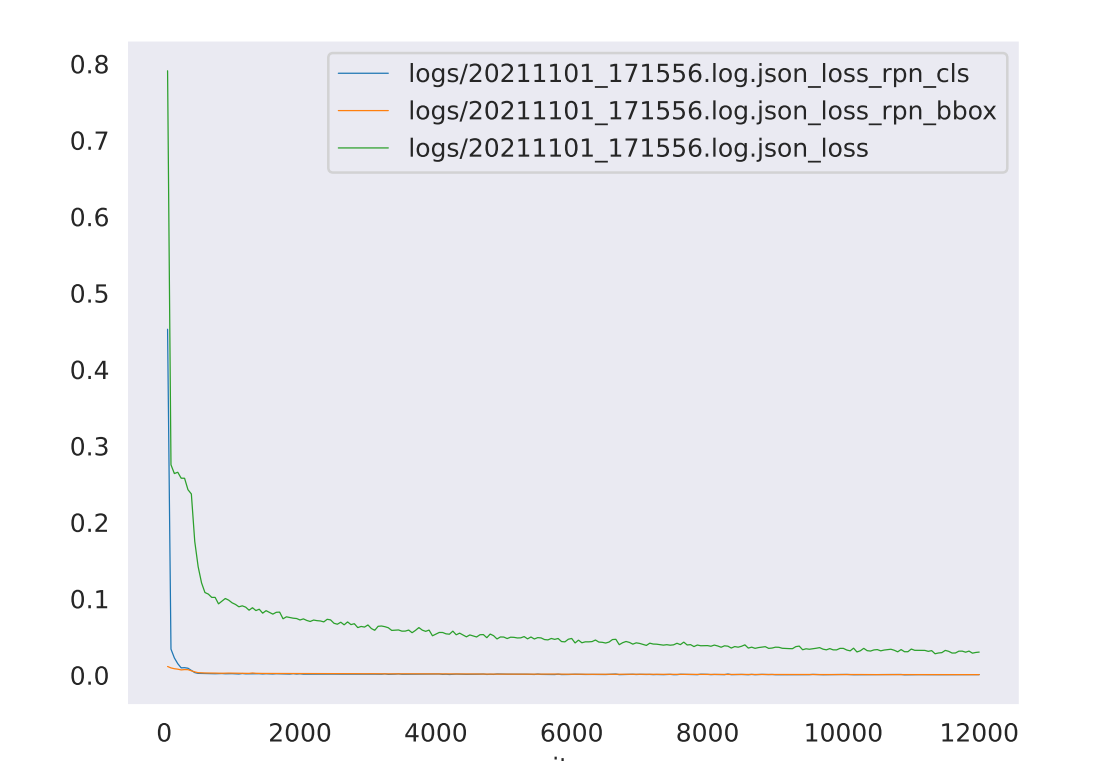
python tools/analysis_tools/analyze_logs.py plot_curve logs/20211101_171556.log.json --keys loss_rpn_cls loss_rpn_bbox loss --out out.pdf
-
plot_curve 代表画折线
-
logs/20211101_171556.log.json 换成你自己的 json 文件
-
loss_rpn_cls loss_rpn_bbox loss 你想显示的数据
-
out.pdf 你输出的文件
显示结果如下图:
⭐ 文章到此结束了,完结撒花。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号