
爬虫_初步(爬取豆瓣图片)
引用python库
from urllib.request import urlopen import urllib.request,urllib.error import re
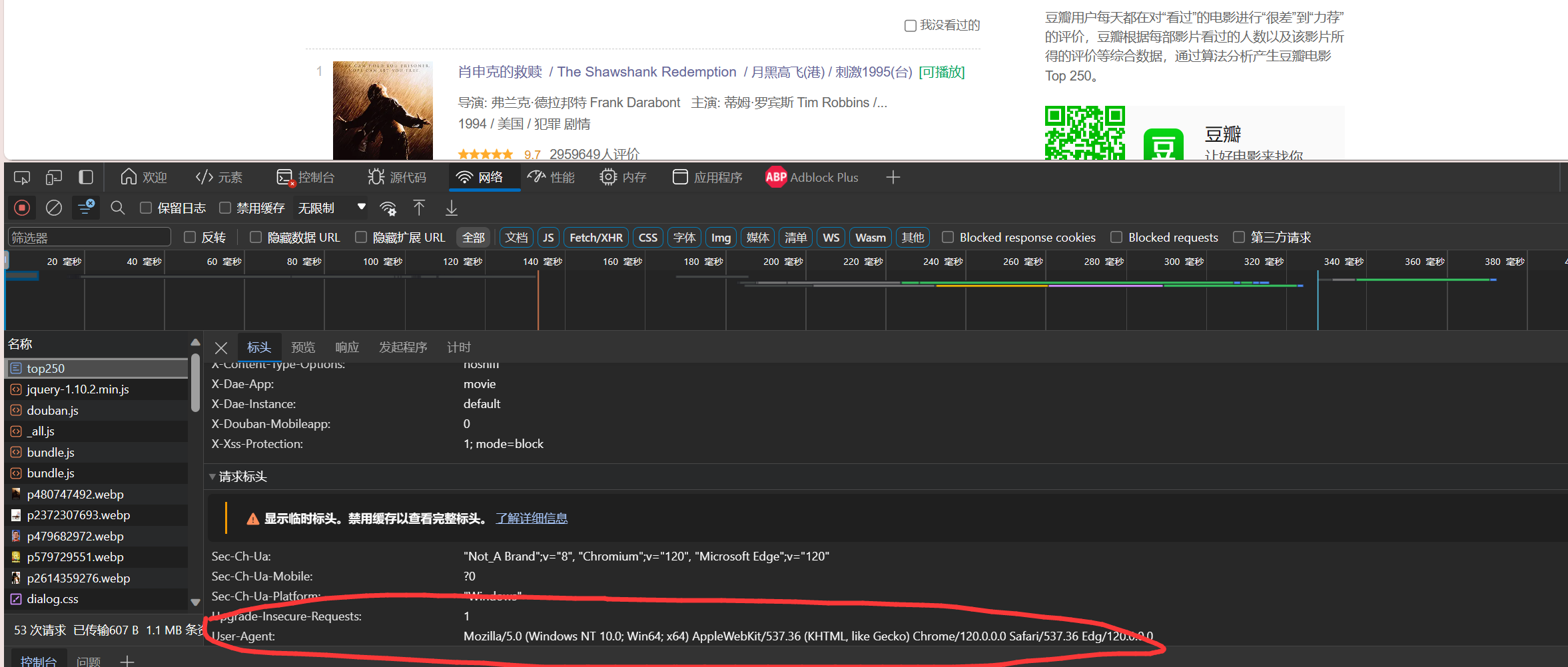
找到本机的headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'}
url = 'https://movie.douban.com/top250'
request = urllib.request.Request(url, headers=headers)#发送请求
response = urllib.request.urlopen(request)
get_1 = response.read().decode('utf-8')
get_1
imginfo = re.findall(r'<img width="100" alt="(.*?)" src="(.*?)" class="">',get_1)
imginfo
for i in range(0,20):
imgurl = imginfo[i]
imginfo[0]
imgreq = urlopen(imgurl[1])
imgc = imgreq.read()
imgf = open(r'D:\\A-lesson work\\CCUT\\img2\\'+ imgurl[0]+'.jpg','wb')
imgf.write(imgc)
imgf.close()
比较重要的正则提取关键字 Python---re.findall的用法_python中re.findall用法-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号