oracle
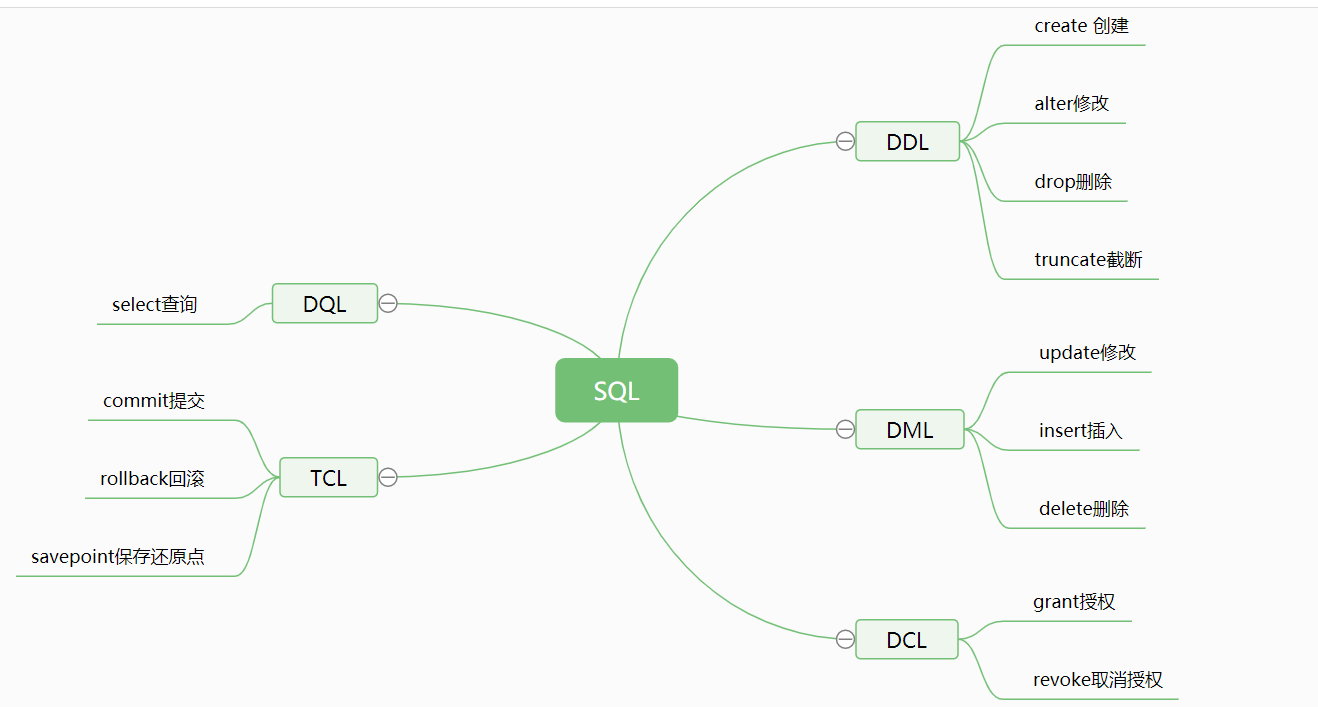
对账户的操作
--给用户加锁
alter user account scott lock;
--给用户解锁
alter user acoount scott unlock;
--创建新用户
create user han identified by etoak;
--给用户修改密码
alter user han identified by han2000113;
--给用户授权
grant dba to han;
--给用户取消授权
revoke dba from han;
--删除用户
drop user han;
--查看当前用户
show user;
--切换用户
conn 用户名/密码
常见数据类型
-
字符型
-
varchar2(20) 可变参(根据输入大小调整) 0-4000字节
-
char(20) 固定参数(长度已经固定) 0-2000字节
-
-
数值型
-
number() 默认为38位
-
number(5)
-
number(5,2)第二个为小数位
-
-
日期型
-
date
-
timestamp 包含毫秒数
-
对表进行操作
--建表后修改表名
alter table student rename to stu;
--增加列
alter table student add youxiang varchar2(50);
--修改列名
alter table student rename column youxiang to emial;
--修改数据类型
alter table student modify email varchar2(100);
--删除列
alter table student drop column emial;
--删除表(删除表结构、表数据)
drop table student;
--截断表(删除表数据、表结构)
truncate table student;
--查看表结构
desc student;
对表中的数据进行操作
-- 修改数据
update student set sal=sal+500;
--插入数据
insert into student(字段名) values(逐个赋值);
--删除数据
delete from student where...
常用函数
-
聚合函数
- AVG()
- SUM()
- MIN()
- MAX()
- COUNT()
- 会自动忽略空值,不自动忽略用NVL-》count(NVL(comm,空替换成的内容))
-
字符函数
-
upper()
-
lower()
-
initcap() 首字母大写
-
length()长度
-
substr(1,2,3)
-
1:原字符串
-
2:开始截取的位置
-
3:截取几位
-
-
replace(1,2,3)
- 1:源字符串
- 2:查找的字符
- 3:修改后的字符
-
instr(1,2,3,4)
-
1:原字符串
-
2:查找的字符
-
3:查找开始位置(默认1)
-
4:第几次出现(默认1)
-
-
lpad(原字符串,补全到多少位,用什么补全) 左补全
- rpad(原字符串,补全到多少位,用什么补全) 右补全
- trim() 去除两侧空格
- ltrim() 左侧去除空格
- rtrim() 右侧去除空格
-
-
日期函数
-
sysdate
-
add_months(d,n) 在日期d的基础上增加n个月
-
last_day(d) 取这个月的最后一天
-
extract(类型 from d)从日期中取指定内容
-
round(d,time) 日期四舍五入
-
months_between() 两个日期之间相差的月份
-
next_day() 下一个周几
-
-
通用函数
- nvl(原字符串,是空展示什么)
- nvl2(原字符串,不是空展示什么,是空展示什么)
- decode(c1,c2,c3,c4,c5.......) c1是原字符串,后面是两个一组,每组的第一个参数和c1比较,相等就匹配组内第二个元素,类似 三目
- c2==c1?c3:下一次比较
- c4==c1?c5:下一次比较
- .....如果参数个数是奇数,都没有匹配上,就返回空
- .....参数个数是偶数,前面都不满足,就返回最后一个
语句
条件取值
case(比较的值) when(符合的时候) then(就怎么处理) else(否则怎么处理) end(结束标志)
分组
group by
将一个表中一个列或者多个列相同的值划分为一组,那么一张表就可以划分多个组,分组后可用聚合函数
having
对分组后的数据进行筛选,如按部门分组后筛选部门人数符合某个条件的小组
排序
order by
按照某个字段的内容进行排序
asc默认升序
desc降序
约束constraint
注意:约束越多,表越健壮,效率也相对低
主键约束 primary key
特点:非空且唯一
主键:在一个表中能唯一定位一条数据的列,是主键列
外键约束 foreign key
外键:在一个子表中引用母表中的主键列,这个列在子表中成为外键列
特点:一个表可以有多个外键
非空约束 not null
唯一约束 unique
检查约束 check
-- 查看当前用户下的约束
select table_name,constraint_name,constraint_type from user_constraints;
-- 建表后添加约束
alter table table_name add constraint 约束名 primary key(id)
-- 删除约束
alter table table_name drop constraint 约束名
高级
复制表
-- 复制表和表结构
create table test as select * from emp;
-- 复制表结构
create table test as select * from emp where 1=2;
-- 复制指定列和数据
create table test as select empno,ename,depeno,job from emp;
-- 给新表中的列重新定义列明
create table test(emopno1,ename1) as select empno,ename from emp;
-- 一次增加多条数据
insert into test select * from emp;
连表查询
内连接 inner join on=join on
select e.* from emp e join dept d on e.deptno=d.deptno;
外连接
不仅包含有关联的数据,还包含没有关联关系的数据
左外连接 left join on
-
以左表为主,左表上的数据都显示,对应不上的右表数据不显示
-
左表关联右表的数据+关联不上的左表数据
右外连接 right join on
- 以右表为组,右表的数据都显示,对应不上的左表数据不显示
- 右表关联左表的数据+关联不上的右表的数据
全外连接 full join on
- 两张表的数据都显示
- 左右两表关联的数据+左表关联不上的数据+右表关联不上的数据
交叉连接 cross join (笛卡尔积)
- 两张表数据一一对应,交叉形成最后结果
- 假设a 表有x列,b表有y列,则最后又x*y列
自查询
select student.name,school.name from student,school where student.sid=school.id;
in、exists、some/any
*:因为in的效率低,所以用exists代替
exists:存在
not exists:不存在
select id from school where exists (select sid from student where student.sid = school.id);
select id from school where id in (select sid from student);
some/any:用法和in相同
some/any用在有符号的情况下,in用在无符号的情况下
select id from school where id < any (select sid from student);
select id from school where id = some (select sid from student);
all:比所有值都大,或者比所有值都小
select id from school where id > all (select sid from student);
***:
any >min 表示只要比条件当中的任意一个大则为真,即为大于最小值;
<any <max 表示只要比条件当中的任意一个小则为真,即小于最大值。
all >max
<all <min
联合关键字
union:结果唯一
union all:结果不唯一
select id,name from school where name like '山东%'
union
select id,name from school where name like '%大学';
select id,name from school where name like '山东%'
union all
select id,name from school where name like '%大学';
--intersect:求交集
select id,name from school where name like '山东%'
--intersect
select id,name from school where name like '%大学';
--minus:从第一个查询结果中减去第二个查询结果中重复的数据
select id,name from school where name like '山东%'
--minus
select id,name from school where name like '%大学';
视图
--多分组查询
select deptno,job,sum(sal) from EMP group by deptno,job order by deptno;
--select中的分组函数中没有deptno,这时deptno需要包含才group by语句中,因为count是一条记录,deptno是多条,没办法共存
select deptno,count(ename) from EMP;
--where后面不能使用组函数,因为sql执行顺序是from->where->select ,分组是在select中使用的,但是分组后可以在having后面使用
--having是先分组,再过滤,where是先过滤再分组,having比较耗时,推荐使用where
--group by增强
select deptno,job,sum(sal) from EMP group by rollup(deptno,job);
--想用的名字只显示一次,不同的跳过两行
break on deptno skip 2
--多表查询加条件是为了避免比卡尔全集
等值连接:多表连接条件里面用的是=号
不等值连接:判断一个表的字段内容在另一个表的范围内
外连接:把不满足条件的记录也显示出来
自连接:需要两个自我表需完成的操作,如查员工的老板
n张表的自连接操作出现的笛卡尔积是表记录的n次方,所以自连接不适合操作大表(加入有1亿条记录,产生的笛卡尔积不可想象)
解决:层次查询
select *
from emp
connect by prior empno =mgr
start with mgr is null;
多表查询不一定好于子查询,这取决于表内笛卡尔积的大小,某些情况下很有可能子查询效率高于多表查询
oracle 实现limit操作
oracle里面没有limit,需要通过rownum来进行操作
- rownum 不能和order by一起使用,因为rownum是在select中完成命名后,order by会打乱顺序
- rownum选取前几名时,只能用<=和< ,不能用>,>=
- 如何实现,用排好序的表,再重新进行添加rownum
- 不能使用表明.rownum的写法
select rownum,t.* from (select * from emp order by sal) t;
--选取前几名
select rownum,t.* from (select * from emp order by sal) t where rownum<=3;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号