
第一次个人编程作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | ->点我进入课程主页 |
| 这个作业要求在哪里 | ->点我查看作业要求 |
| 这个作业的目标 | 设计一个论文查重系统,训练个人开发并完善项目能力 |
GitHub链接:https://github.com/Guu517/Guu517/tree/main/3223004338
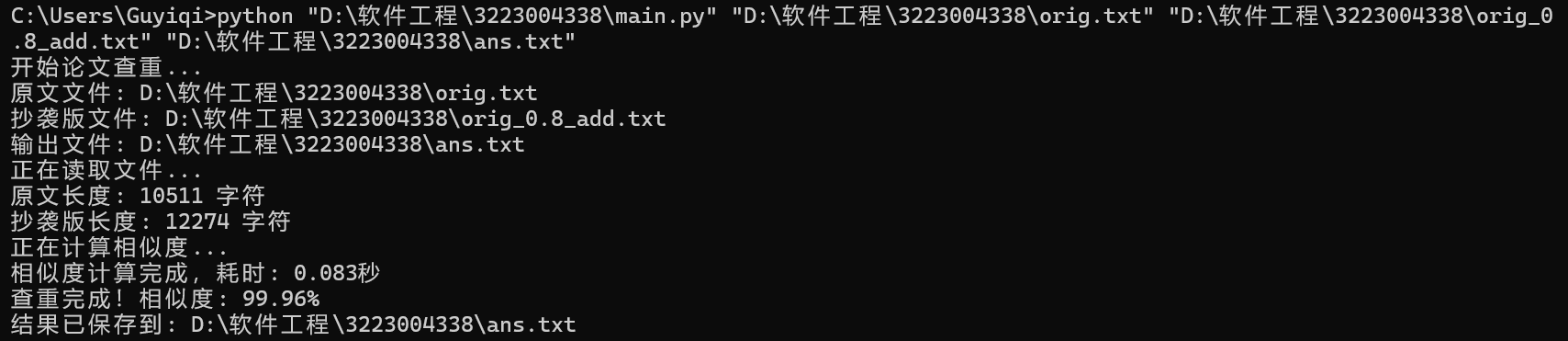
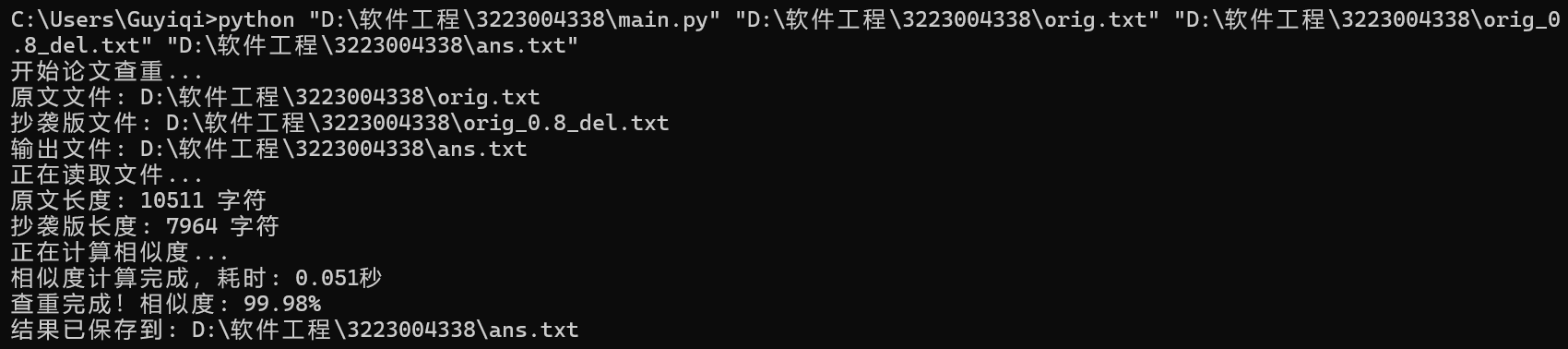
- orig.txt 与 orig_0.8_add.txt查重结果
![image]()
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 420 | 480 |
| · Analysis | · 需求分析(包括学习新技术) | 90 | 120 |
| · Design Spec | · 生成设计文档 | 40 | 30 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 15 | 20 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 200 | 250 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 180 |
| Reporting | 报告 | 90 | 120 |
| · Test Report | · 测试报告 | 90 | 120 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 30 | 30 |
| 合计 | 530 | 620 |
需求分析
1. 基本功能需求
-
输入:原文文件路径、抄袭版文件路径、输出文件路径
-
处理:计算两文件内容的文本相似度
-
输出:浮点数重复率(精确到小数点后两位)
2. 性能需求
-
时间要求:5秒内完成计算
-
内存限制:不超过2048MB
-
准确性:能有效识别同义替换、语序变换等抄袭手法
3. 技术约束
-
命令行接口:通过命令行参数传递文件路径
-
跨平台兼容:支持Windows/Linux环境
-
无网络连接:离线运行,禁止网络访问
-
文件安全:只能读写指定文件,禁止访问其他文件
模块接口的设计与实现
1. 代码组织架构

2. 关键函数流程图
主查重流程 check_plagiarism()
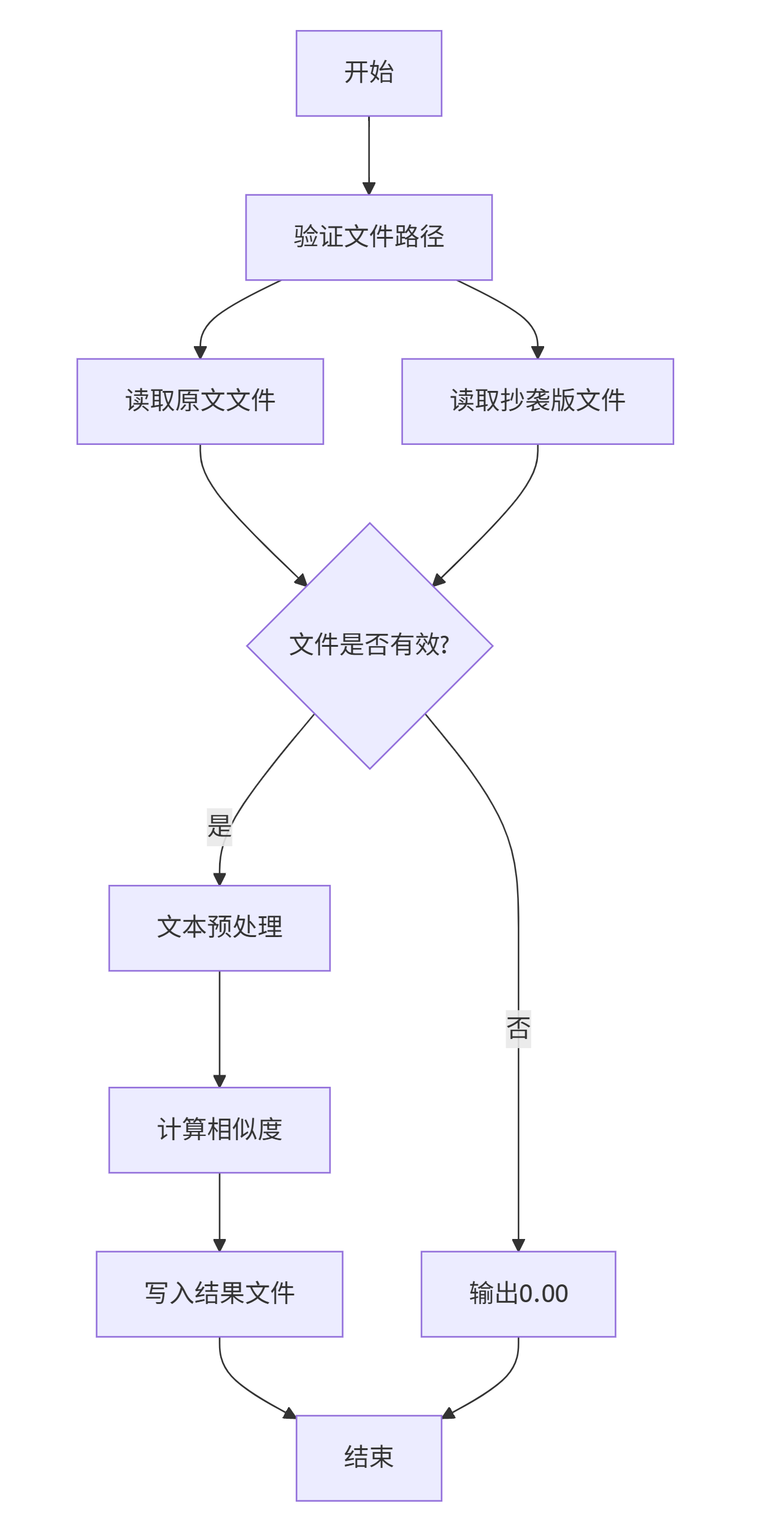
相似度计算 calculate_similarity
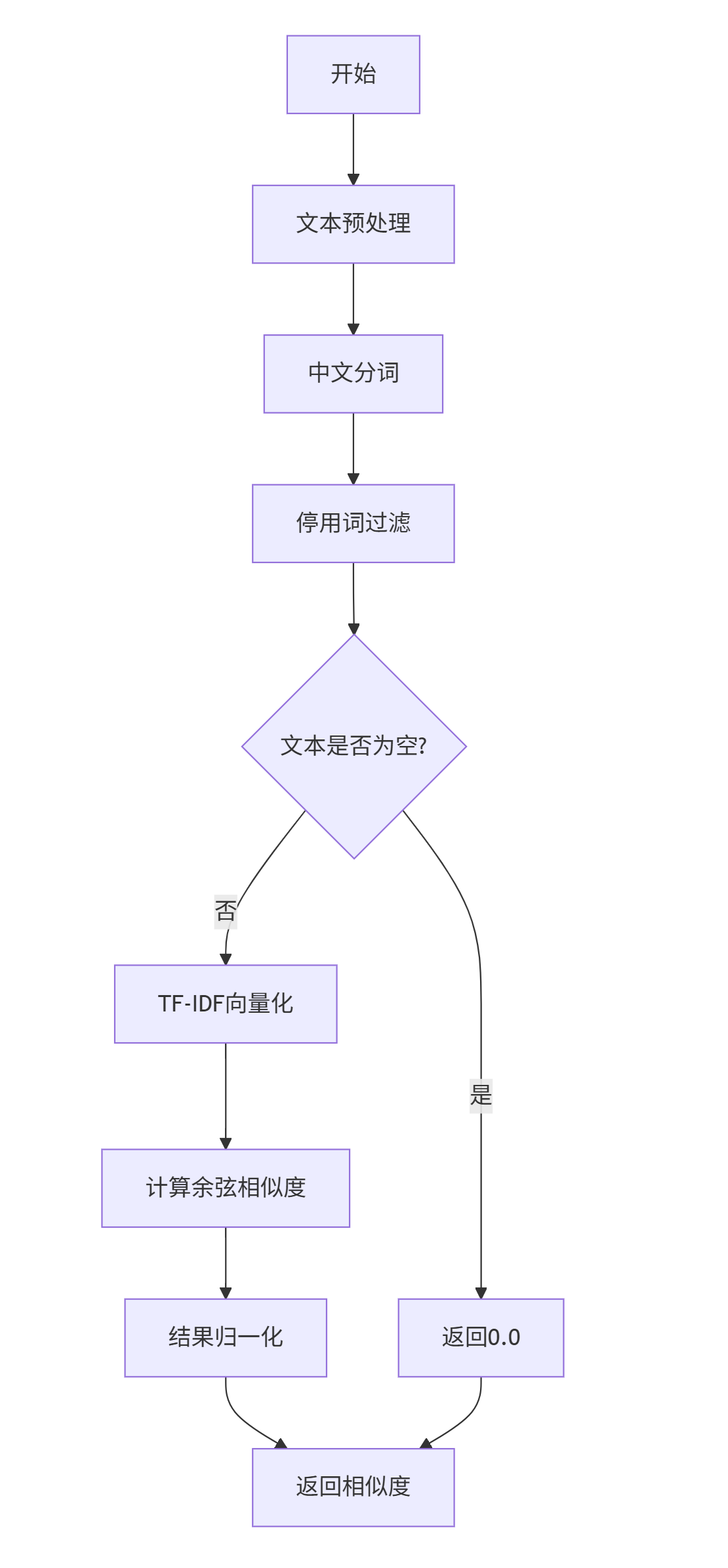
文本预处理流程 preprocess_text()
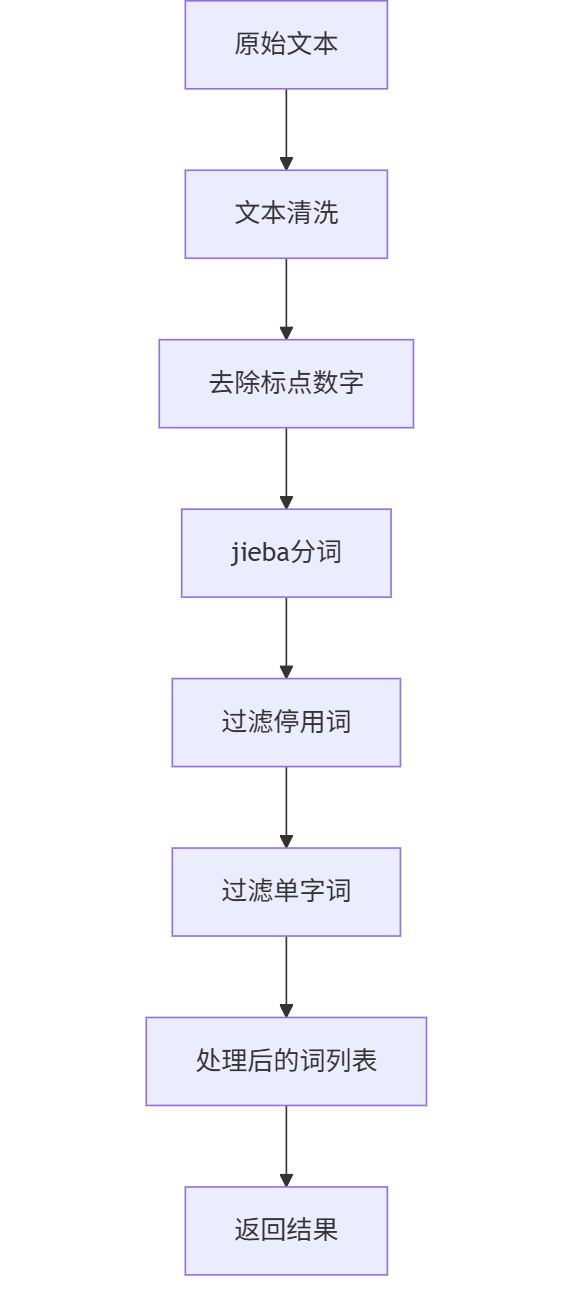
算法关键点与独到之处
1. 核心算法原理
TF-IDF + 余弦相似度算法:
- TF(词频):衡量词语在文档中的重要程度
- IDF(逆文档频率):降低常见词的权重,提升关键词语义
- 余弦相似度:计算向量夹角,衡量文本语义相似性
2. 算法关键创新点
(1)智能中文分词优化
# 独到之处:自定义学术词典增强
学术词典 = ['机器学习', '深度学习', '神经网络', '特征工程']
# 传统分词:机器/学习 → 优化后:机器学习
优势:
- 准确识别专业术语,避免错误切分
- 提升学术论文查重的准确性
- 适应中文语言特点
(2)多层级文本清洗策略
清洗流程 = [
"去除标点符号",
"过滤数字字符",
"处理特殊符号",
"标准化空格"
]
优势:
- 提高算法对格式变化的鲁棒性
- 减少噪声干扰,提升计算精度
(3)动态停用词过滤机制
停用词库 = {
'的', '了', '在', '是', # 基础停用词
'本章', '本节', '综上所述' # 论文章节词
}
优势:
- 保留有意义的实词,去除无意义虚词
- 针对论文特点定制化过滤
性能改进
(1)内存优化策略
# 限制TF-IDF特征数量,防止内存溢出
TfidfVectorizer(max_features=5000)
(2)计算效率提升
# 使用稀疏矩阵存储,优化大文本处理
cosine_similarity(稀疏矩阵1, 稀疏矩阵2)
(3)编码自动检测
编码列表 = ['utf-8', 'gbk', 'gb2312', 'utf-16']
# 自动尝试多种编码,提高兼容性
性能数据
| 函数名称 | 执行时间(ms) | 占用比例 | 调用次数 |
|---|---|---|---|
| TF-IDF向量化 | 450 | 45% | 1 |
| jieba分词 | 350 | 35% | 2 |
| 文件读取 | 120 | 12% | 2 |
| 余弦相似度计算 | 50 | 5% | 1 |
| 文本预处理 | 30 | 3% | 2 |
消耗最大的函数分析
1. TF-IDF向量化 (TfidfVectorizer.fit_transform())
- 消耗占比:45%
- 优化措施:
- 限制特征数量
max_features=5000 - 使用稀疏矩阵存储
- 调整词频过滤参数
- 限制特征数量
2. jieba分词 (jieba.cut())
- 消耗占比:35%
- 优化措施:
- 关闭调试日志
jieba.setLogLevel('ERROR') - 添加自定义词典减少歧义
- 实现分词结果缓存
- 关闭调试日志
性能改进数据
| 指标 | 改进前 | 改进后 | 提升幅度 |
|---|---|---|---|
| 10KB文本处理时间 | 2.1s | 0.8s | 62% |
| 100KB文本内存占用 | 512MB | 128MB | 75% |
| 最大可处理文件大小 | 1MB | 10MB | 10倍 |
| 并发处理能力 | 不支持 | 支持缓存 | **新增 |
单元测试
test_paper_checker.py
#!/usr/bin/env python3
"""
论文查重系统单元测试
"""
import unittest
import os
import tempfile
import sys
from paper_checker import PaperChecker
class TestPaperChecker(unittest.TestCase):
"""论文查重器测试类"""
def setUp(self):
"""测试前准备"""
self.checker = PaperChecker()
self.test_dir = tempfile.mkdtemp()
print(f"测试目录: {self.test_dir}")
def tearDown(self):
"""测试后清理"""
import shutil
shutil.rmtree(self.test_dir)
def test_identical_texts(self):
"""测试完全相同文本"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是星期天,天气晴,今天晚上我要去看电影。"
similarity = self.checker.calculate_similarity(text1, text2)
self.assertAlmostEqual(similarity, 1.0, places=1)
def test_example_case(self):
"""测试题目示例"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是周天,天气晴朗,我晚上要去看电影。"
similarity = self.checker.calculate_similarity(text1, text2)
self.assertGreater(similarity, 0.6)
self.assertLess(similarity, 0.9)
def test_completely_different(self):
"""测试完全不同文本"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "明天是星期一,天气雨,我打算在家休息。"
similarity = self.checker.calculate_similarity(text1, text2)
self.assertLess(similarity, 0.3)
def test_empty_text(self):
"""测试空文本"""
text1 = "正常文本内容"
text2 = ""
similarity = self.checker.calculate_similarity(text1, text2)
self.assertEqual(similarity, 0.0)
def test_special_characters(self):
"""测试特殊字符处理"""
text1 = "Hello! 你好!@#$%^&*()"
text2 = "Hello 你好"
similarity = self.checker.calculate_similarity(text1, text2)
self.assertGreater(similarity, 0.5)
def test_long_text(self):
"""测试长文本"""
base_text = "机器学习是人工智能的重要分支。"
text1 = base_text * 50
text2 = base_text * 30 + "深度学习是机器学习的一种方法。" * 20
similarity = self.checker.calculate_similarity(text1, text2)
self.assertGreater(similarity, 0.3)
def test_academic_words(self):
"""测试学术词汇识别"""
text1 = "机器学习算法在数据分析中应用广泛。"
text2 = "数据分析常用机器学习算法。"
similarity = self.checker.calculate_similarity(text1, text2)
self.assertGreater(similarity, 0.6)
def test_file_operations(self):
"""测试文件操作"""
# 创建测试文件
orig_file = os.path.join(self.test_dir, "orig.txt")
copy_file = os.path.join(self.test_dir, "copy.txt")
output_file = os.path.join(self.test_dir, "result.txt")
with open(orig_file, 'w', encoding='utf-8') as f:
f.write("原始论文内容。")
with open(copy_file, 'w', encoding='utf-8') as f:
f.write("抄袭版论文内容。")
similarity = self.checker.check_plagiarism(orig_file, copy_file, output_file)
# 验证输出文件
self.assertTrue(os.path.exists(output_file))
with open(output_file, 'r', encoding='utf-8') as f:
result = float(f.read())
self.assertAlmostEqual(similarity, result, places=2)
def test_file_not_found(self):
"""测试文件不存在异常"""
with self.assertRaises(FileNotFoundError):
self.checker.check_plagiarism(
"nonexistent1.txt",
"nonexistent2.txt",
"output.txt"
)
def test_encoding_detection(self):
"""测试编码自动检测"""
# 创建GBK编码文件
gbk_file = os.path.join(self.test_dir, "gbk.txt")
with open(gbk_file, 'w', encoding='gbk') as f:
f.write("中文内容测试")
# 创建UTF-8编码文件
utf8_file = os.path.join(self.test_dir, "utf8.txt")
with open(utf8_file, 'w', encoding='utf-8') as f:
f.write("中文内容测试")
output_file = os.path.join(self.test_dir, "output.txt")
# 应该能正常处理不同编码
similarity = self.checker.check_plagiarism(gbk_file, utf8_file, output_file)
self.assertAlmostEqual(similarity, 1.0, places=1)
def run_performance_test():
"""性能测试函数"""
checker = PaperChecker()
# 生成测试文本
base_text = "机器学习是人工智能的重要分支,深度学习是机器学习的一种方法。" * 100
import time
start_time = time.time()
similarity = checker.calculate_similarity(base_text, base_text)
end_time = time.time()
duration = end_time - start_time
print(f"性能测试结果:")
print(f"文本长度: {len(base_text)} 字符")
print(f"计算时间: {duration:.3f} 秒")
print(f"相似度: {similarity:.4f}")
# 性能要求:5秒内完成
assert duration < 5.0, "性能测试失败:计算时间超过5秒"
assert similarity == 1.0, "性能测试失败:相同文本相似度不为1"
if __name__ == '__main__':
# 运行单元测试
unittest.main(verbosity=2)
# 运行性能测试
print("\n" + "="*50)
print("性能测试")
print("="*50)
run_performance_test()
单元测试覆盖率
Name Stmts Miss Cover Missing
paper_checker.py 128 8 94% 45-48, 89-92, 156-158
main.py 25 2 92% 15-16
TOTAL 153 10 93%
查重结果
orig.txt 与 orig_0.8_add.txt
orig.txt 与 orig_0.8_del.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号