

大数据技术
前情提要:个人学习所做笔记,供做自用,内容不太严谨
Hadoop安装
Hadoop是一个能够对大量数据进行分布式处理的软件框架
Hadoop可以在Window系统上运行,但其官方支持的操作系统只有Liunx,所以先要准备好虚拟机
本教程是根据自己的安装流程进行的,本人也是初学者
虚拟机准备好,可以创建一个hadoop用户,以便于今后使用
sudo useradd -m 用户名 -s /bin/bash #创建用户
sudo passwd 用户名 #设置密码,需要输入两次
sudo adduser 用户名 sudo #增加管理员权限
创建完成后,注销现用户,改用hadoop用户登录虚拟机
接下来正式安装hadoop
java安装
hadoop是由Java编写的,所以需要安装jdk
你可以先使用java -version来查看你的jdk版本,如果能显示java version信息,说明你已经安装了,跳过这一节
如果你没有安装,请遵循以下步骤
1.选择正确的JDK
首先,请选择与Hadoop版本相匹配的JDK版本,这里使用的是Hadoop3.3.6,匹配JDK1.8
tips:JDK8和JDK1.8是一个东西,原因是JDK在5版本以前都叫做1.x,后面就直接叫JDK5,JDK6了
Hadoop版本相匹配的JDK版本百度一下就知道了
2.安装java环境
在/usr/lib目录下创建jvm文件夹 ,用于存储JDK文件,命令如下
cd /usr/lib #进入lib目录
sudo mkdir jvm #此命令为创建文件夹命令
然后百度搜索JDK Download,进入oracle官网,下载名字类似于此文件的压缩包:
jdk-8u202-linux-x64.tar.gz
jdk-版本号-操作系统-系统位数.tar.gz,jdk8,liunx系统,64位,.tar.gz是压缩包的后缀名,类似于zip,rar
这里下的是JDK8,搜索JDK8 Download,oracle官网需要登录,自己注册个账号才能下载
注意,下载到你的虚拟机上,别下你的主机里
默认的下载位置是主文件夹/下载(或Download)
进入该文件夹,打开终端,使用一下命令解压压缩包
sudo tar -zxvf 你的压缩包名称 -C /usr/lib/jvm
# tar为压缩包命令 -zxvf表示解压.tar.gz后缀的压缩包 , -C和目录,表示解压到该目录下,这里直接解压到jvm目录下,你手动移动也可以
然后添加环境变量,打开~/下的.bashrc文件,用VIM也可以,用文本编辑器也可以,添加以下变量
export JAVA_HOME=/usr/lib/jvm/你的jdk文件夹名
export JRE_HOME=S{JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${PATH}
保存,退出,使用以下命令刷新配置
source ~/.bashrc
然后输入java -version,查看是否出现java版本,出现成功
Hadoop下载
Apache Hadoop←Hadoop官网
进去,点击Download
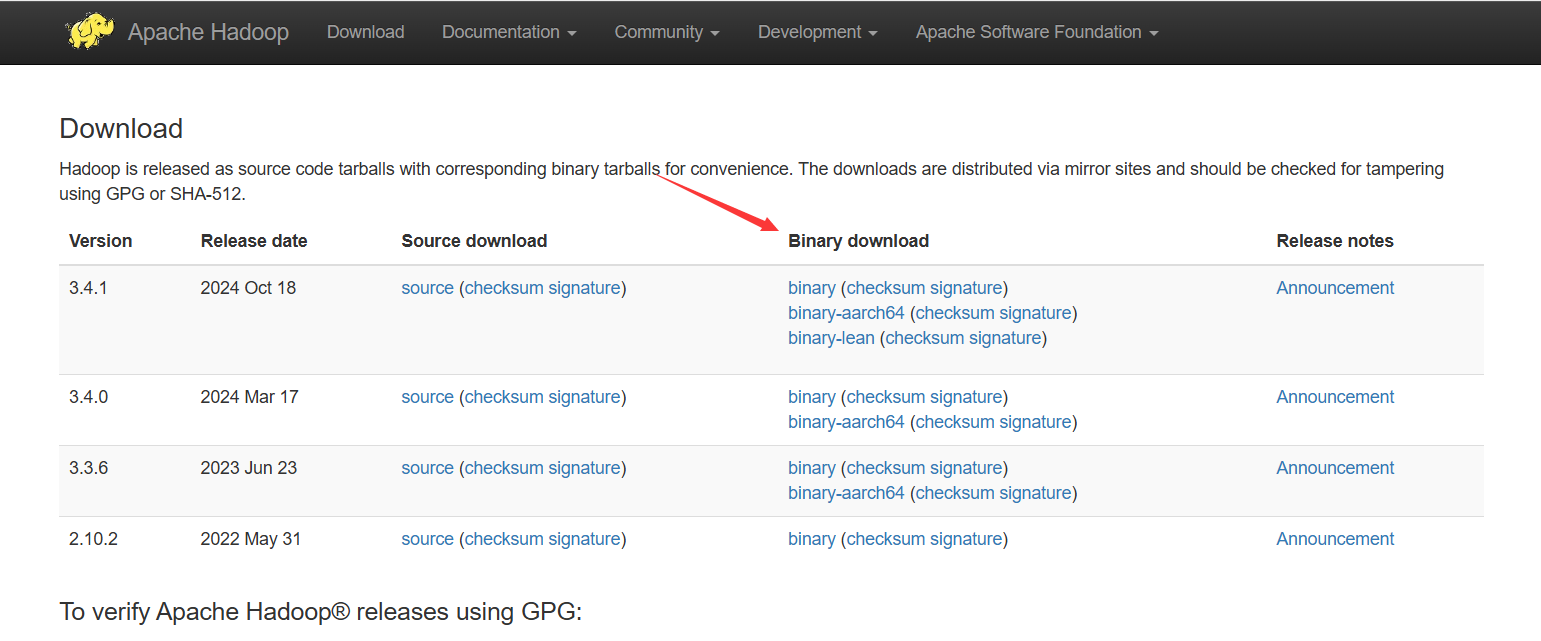
选择你要下载的版本,点BinaryDownload那栏的binary,进去后,点击最上面的带有.tar.gz后缀的连接,下载Hadoop压缩包
下载完成后,解压到/usr/local/目录下,解压命令为 tar -zxvf 压缩包名,上面解压JDK说过了
如果你下载的对的话,解压后的Hadoop文件夹应该是这样的
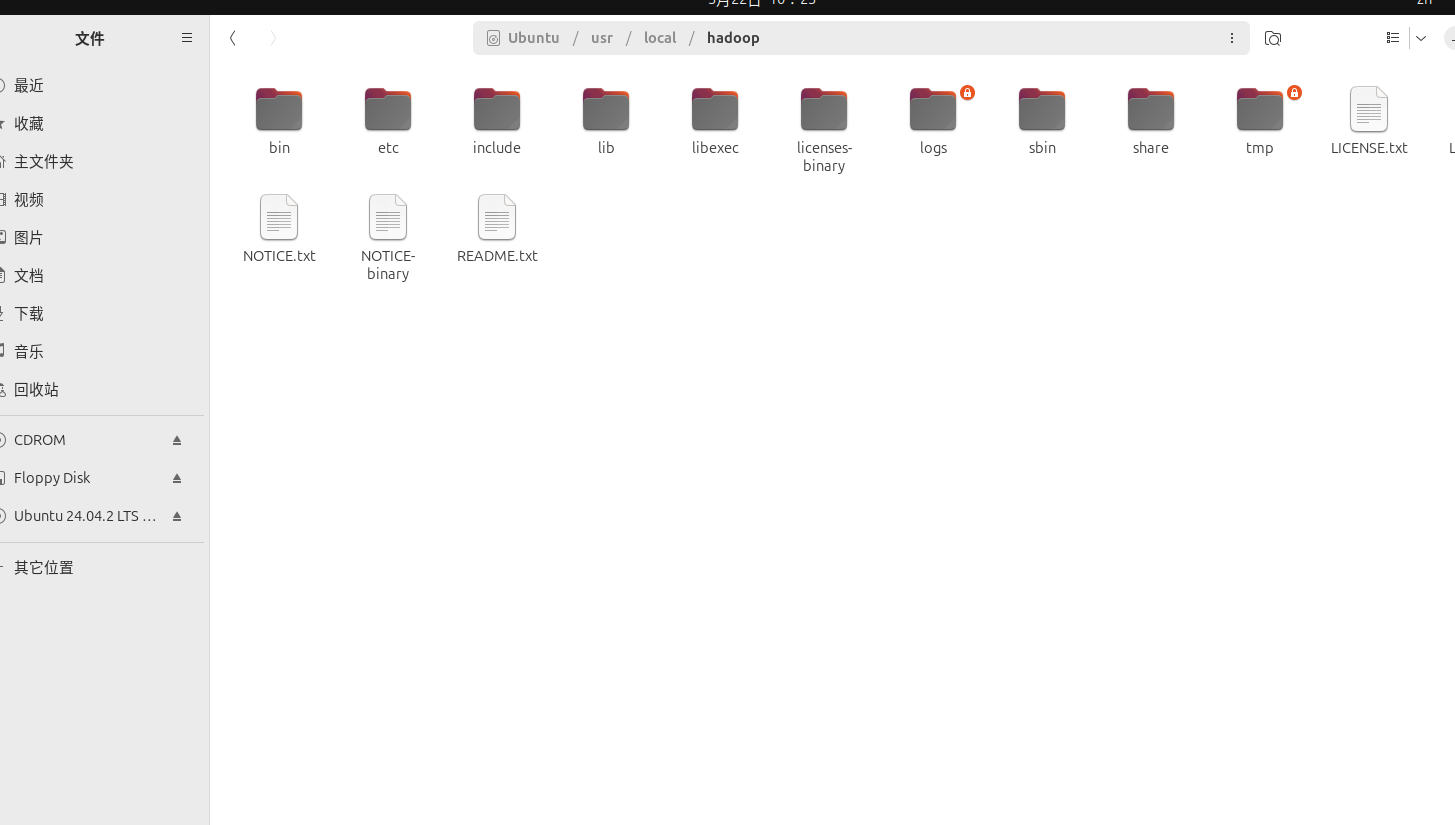
解压完成后,在/usr/local/目录下打开终端,输入以下命令
sudo mv ./你的hadoop文件夹名 ./hadoop #将你的hadoop文件夹名修改为hadoop
sudo chown -R hadoop ./hadoop #修改目录权限
然后再去~/.bashrc文件下添加环境变量
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
#将path修改为下面的
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${PATH}
记得刷新配置
输入hadoop version,查看hadoop版本,如果出现,成功
伪分布式安装
Hadoop对数据存储使用的是HDFS,在实际生产环境下是采用完全分布式模式的,HDFS在不同的机器上有不同的节点
对于初学者使用伪分布式即可,即HDFS只有一个节点,也就是你的虚拟机
无论哪种方式,都需要修改配置文件来对各组件的合作进行配置。伪分布式安装需要我们配置core-site.xml和hdfs-site.xml两个文件
这两个文件里默认是只有一些注释的,在文件的末尾添加以下配置
core-site.xml:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<!--配置HDFS的地址和端口号-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,回到你的hadoop文件夹,执行以下命令
cd /usr/local/hadoop #回到hadoop文件夹
./bin/hdfs namenode -format
这一步是初始化HDFS,如果出现successfully formatted成功
错误情况
如果在初始化时出现ERROR:Unable to wirte in /usr/local/hadoop/logs. Aborting.,说明权限不够,有两种情况:
1.用户权限不够
2.文件权限不够
解决方案如下:
在命令前添加sudo前缀,使用root用户
不过一般权限不对应该是你前面配置有些错误,使用了sudo执行后你就不是以hadoop用户而是用root用户登陆了。对于初学者应该没有影响,但对实际生产root用户的权限敏感性可能导致某些错误
设置SSH免密登录
Hadoop没有提供输入密码形式的SSH登录,所以要设置SSH免密登录
首先安装SSH,ubuntu默认安装了客户端,所以这里只需要安装服务器端
sudo apt-get install openssh-server
安装后,使用下命令登录本机
ssh localhost
执行改命令后会让你输入密码,就是你用户的密码
登录成功后,输入exit退出,打开/etc/ssh/sshd_config,修改一下配置文件
#将以下三个属性修改为yes,可以用ctrl+f查找
PubkeyAuthentication yes
PasswordAuthentication yes
PermitRootLogin yes
修改完后,输入以下命令来设置免密
cd ~/.ssh #进入ssh文件夹
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys
执行ssh localhost登录本机,如果不需要密码就登陆成功了,说明免密登录成功
root用户设置免密
如果你前面没出现过权限问题,这一步请跳过
但如果你用了sudo才能正常走下去,这一步可以设置,只是换为root用户进行操作而不是你创建的hadoop用户了
一般是不需要sudo也能正常执行的,我第一次安装也必须要用sudo,但严格跟着教程走一遍后确实不需要的
root用户设置免密和普通用户一样,只是进入root用户下在进行上面的免密操作即可
sudo su #进入root用户
同样的使用ssh localhost来测试在root用户下是否可以免密成功
启动HDFS
进入/usr/local/hadoop执行以下命令
./sbin/start.dfs.sh #启动sbin目录下的start.dfs.sh脚本,用于启动hdfs

启动后如这样形式,输入jps后存在datenode和Namenode,代表HDFS启动成功
可以通过访问localhost:9870来验证并查看Hadoop的信息
如果问题实在解决不了,创建一个新的虚拟机,从头做一遍
HDFS
HDFS(Hadoop Distributed File System,Hadoop的分布式文件管理系统),是Hadoop的两大核心之一,用于管理数据和文件
分布式文件系统
分布式文件系统是一种通过网络实现将文件在多台主机上进行分布式存储的系统
传统的文件系统,将磁盘空间分成了大小固定的磁盘块,作为文件读写的最小单位,文件系统每次读写的数据量必须为磁盘块大小的整数倍
分布式文件管理系统采用同样的概念,但磁盘块的大小要大得多(Windows,Linux一般512B一组,HDFS默认的数据块大小为128MB)
不同的是,文件的大小如果小于数据块的大小,不会占用整个数据块
计算机集群
分布式文件系统中,存储文件的多台设备构成一个计算机集群。为了降低成本,这些设备一般都是由普通硬件所构成
计算机集群中将硬件分为几组机架,每个机架大约存放8~64个节点,同一个机架中可以网络互联,不同机架之间通过另一级网络或交换机互联
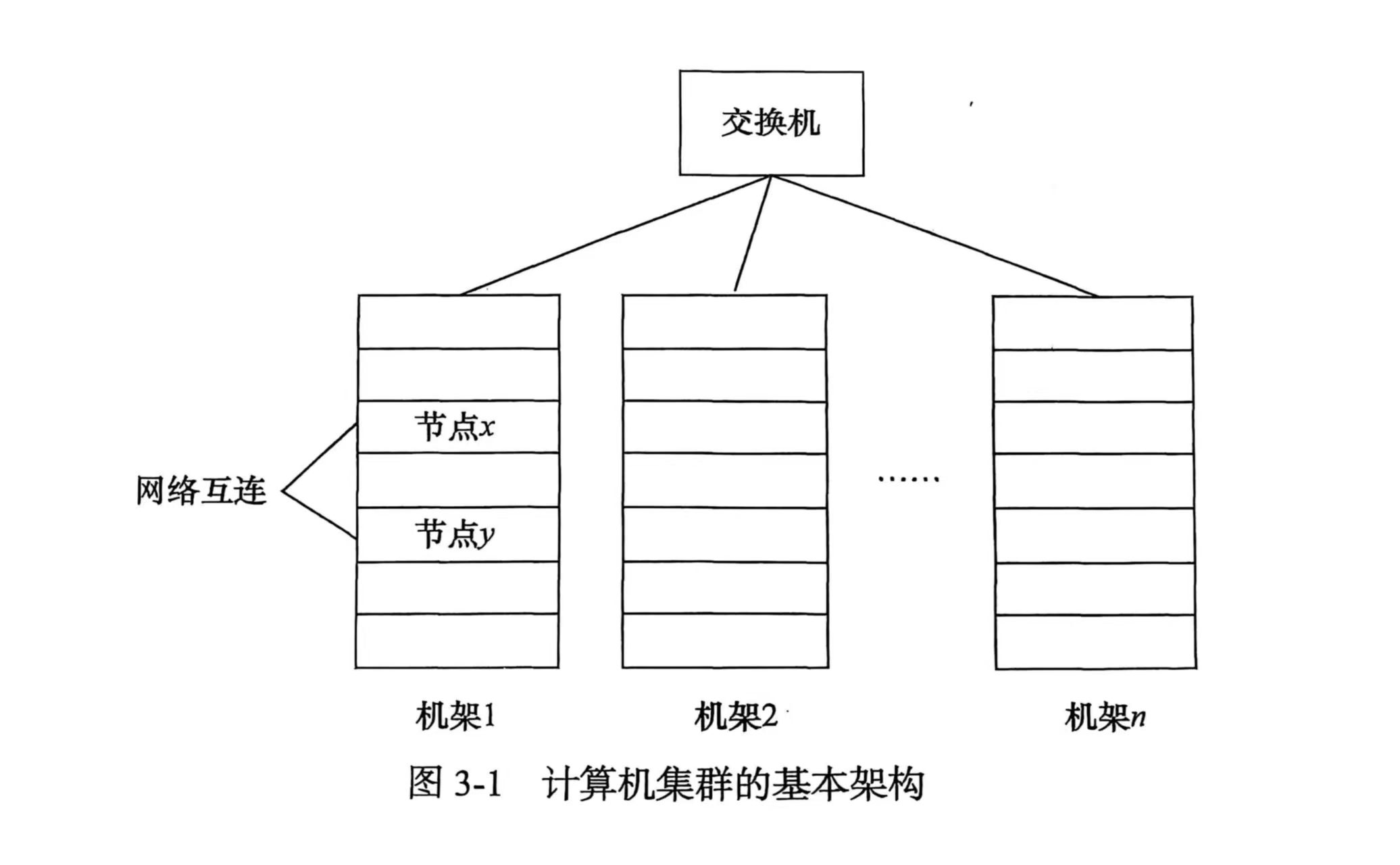
结构
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,节点分为两类
- 主节点(MasterNode),也叫名称节点(NameNode)
负责文件和目录的管理(创建,删除,重命名等),管理数据节点和数据块的映射关系
- 从节点(SlaveNode),也叫数据节点(DataNode)
负责数据的读写,执行名称节点对数据块的管理
分布式文件系统在设计时一般采用C/S格式:
- 客户端访问名称节点,找到请求的数据块,后由数据节点进行读取
- 而在存储时,名称节点为数据分配位置,客户端将数据输入进数据节点,再由数据节点写入数据块
分布式文件系统是针对大规模数据存储而设计的,主要用于处理以TB为单位的大规模文件。规模过小的文件不仅无法发挥系统的优势,还会影响系统的扩展和性能
HDFS体系结构
HDFS采用Master/Slave结构,一个HDFS集群包括一个名称节点和若干个数据节点
- 名称节点作为中心服务器,负责管理分布式文件系统的命名空间和客户端对文件的访问
- 一个数据节点运行一个数据节点进程,负责处理客户端对文件的读写请求,遵从名称节点对数据块进行管理
每个数据节点会周期性的向名称节点发送"心跳"信号,报告自己的状态。没有按时发送的数据节点会被标记为死机,名称节点不会再去使用它
HDFS集群只有唯一一个名称节点
HDFS命名空间管理
HDFS的命名空间包括目录,文件和块。命名空间管理是指命名空间支持对HDFS中的目录,文件和数据库进行类似文件系统的创建
HDFS集群中只有一个命名空间,并且只有唯一一个名称节点。该名称节点对命名空间进行管理
HDFS的存储原理
HDFS采用了多副本方式对数据进行冗余存储
通常一个数据块的多个副本会被分布到不同的数据节点上。如下图所示:
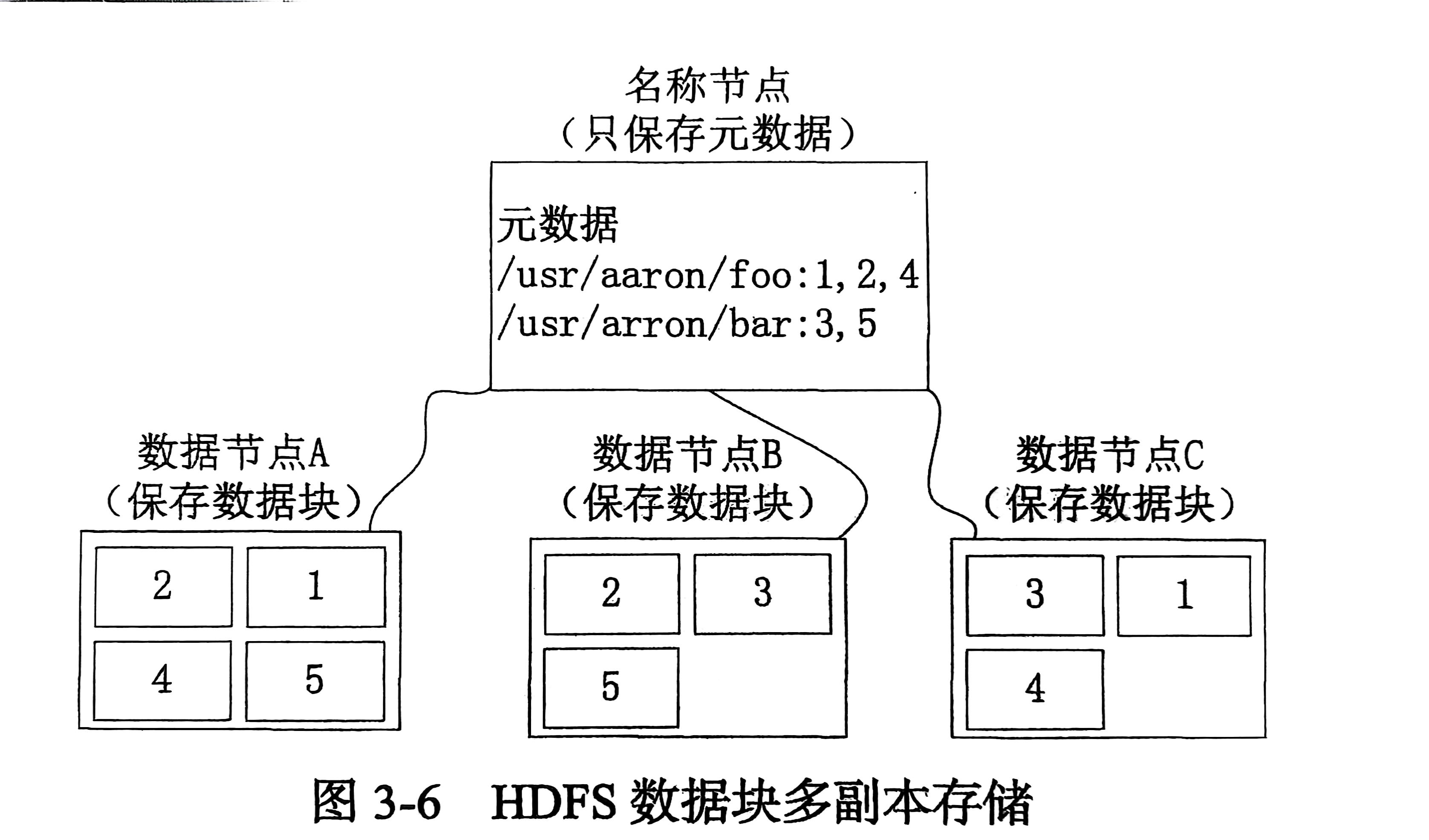
数据2在节点AB都有存储,3在BC都有存储
这种多副本存储方式有以下优点:
- 加快数据访问速度:多个客户端访问同一个数据时,可以让他们从不同的数据块中访问
- 容易检查数据错误:HDFS的数据节点之间通过网络传输数据,采用多个副本可以很容易判断出传输数据是否出错
- 保证数据可靠性:多副本的存在,一个副本出错了也不会影响到其他副本
HBase
HBase是针对谷歌BigTable的开源实现
伪分布式安装
Hbase下载地址→https://archive.apache.org/dist/hbase/
选择你要的版本,下载只有bin.tar.gz后缀的压缩包。这里使用的是2.4.1
下载完毕后,解压到/usr/local下,打开终端执行改名和赋予权限命令:
sudo mv ./你的hbase文件夹名 ./hbase #改名
sudo chown -R hadoop ./hbase #修改目录权限
然后再.bashrc文件里添加环境变量
export HBASE_HOME=/usr/local/hbase
export PATH=${HBASE_HOME}:${HBASE_HOME}/bin
source .bashrc,刷新配置
完成这步后,就可以使用hbase version命令来查看安装的HBase版本了
然后进行文件配置
cd /usr/local/hbase/conf,打开hbase-env.sh文件,添加以下路径
路径要改成你自己的
JAVA_HOME:JDK目录
HBASE_CLASSPATH:指向hadoop配置文件目录
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_441
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop
export HBASE_MANAGES_ZK=true
- JAVA_HOME:指向JDK目录
- HBASE_CLASSPATH:指向你安装的hadoop的配置目录
保存,退出
再打开同路径下的hbase-site.xml文件,添加以下配置
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
保存,退出
然后测试启动,首先启动hadoop
启动完毕后cd /usr/local/hbase/bin
启动start-hbase.sh,第一次启动需要输入yes
使用jps命令,若存在以下节点,代表启动成功
DataNode
NameNode
SecondaryNameNode
#这三个代表hadoop启动成功
HMaster
HRegionServer
HQuorumPeer
#有这三个节点代表HBase启动成功
使用hbase shell命令,进入hbase控制台,使用exit命令退出控制台
要结束HBase,使用stop-hbase.sh
如果无法结束,一直出现...,ctrl+c停止执行命令
hbase-daemon.sh stop masterhbase-daemon.sh stop regionserver
执行这两条命令后,再执行结束命令
HBase数据库基本概念
HBase是列式数据库,属于NoSQL(非关系型数据库)
对于他的基本概念,这里根据关系数据库的基本概念来比对着描述:
-
表:即关系,数据库里的一张二维表表
-
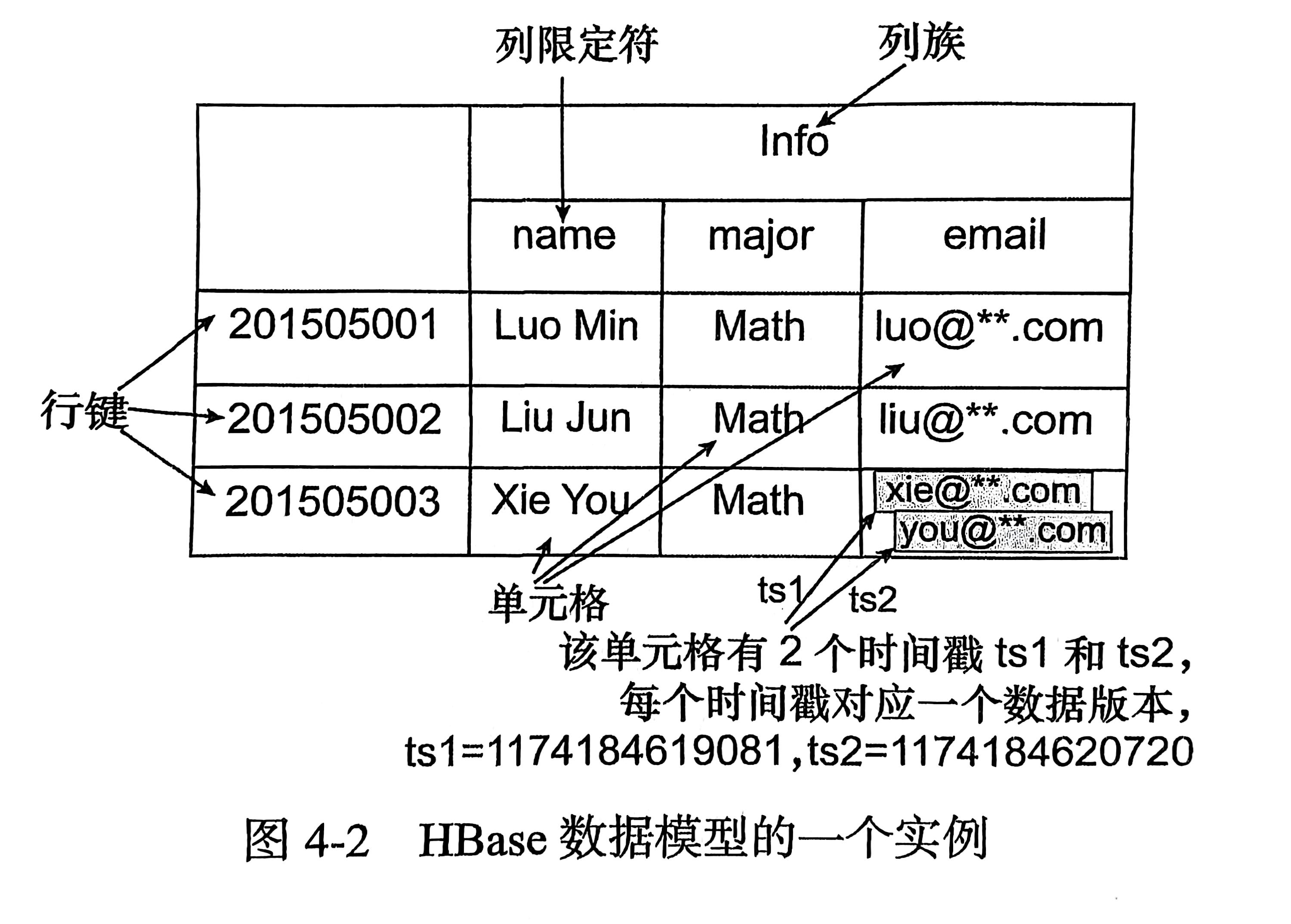
列族,列限定符:
列限定符即属性,每一列最上面的那个。列族就是所有列限定符
- 行键:每一行都有一个行键来代表该行
HBase数据库里没有类似于元组的概念,用行键代表某一行。没有行键代表该行不存在
-
单元格:表中代表数据的一个格子,行键,列族和列限定符确定一个单元格
-
时间戳:
每个单元格可能会保存同一个数据的多个版本,由时间戳作为索引
时间戳最大的版本代表最新的版本
HBase基本命令
使用HBase前,请保证你至少有10G的空闲硬盘空间,否则会出现各种错误
(我遇到的是HMaster启动失败,改了各种配置都没用,扩容之后成功)
Create
使用create来创建一个表
create '表名','列限定符1','列限定符2',...
create '表名','列限定符1','列限定符2',...
例如
create 'student','Sname','Ssex','Sage','Sdept','course'
#创建一个student表,分别有Sname,Ssex,Sage,Sdept,course属性
Update
如果要向表里添加数据,使用put,每次只能向一个单元格里添加数据
put '表名','行键','列限定符','数据'
例如我要往上面创建的学生表里添加一个完整的学生数据,就要输入下面几行
put 'student','95001','Sname','LiYing'
put 'student','95001','Ssex','male'
put 'student','95001','Sage','23'
put 'student','95001','Sdept','CS'
put 'student','95001','course','80'
Read
想要查看某个表里的数据,有两种方式
get:查看表的指定一行
scan:查看整个表
get 'student','95001' #查看行键为95001的数据
scan 'student' #查看student表的所有数据
结果:
hbase:017:0> get 'student','95001'
COLUMN CELL
Sage: timestamp=2025-04-23T12:34:31.184, value=23
Sdept: timestamp=2025-04-23T12:34:37.830, value=22-1
Sname: timestamp=2025-04-23T12:34:11.714, value=Liying course: timestamp=2025-04-23T12:34:45.744, value=software
1 row(s)
Took 0.0159 seconds
hbase:018:0> scan 'student'
ROW COLUMN+CELL 95001 column=Sage:, timestamp=2025-04-23T12:34:31.184, value=23
95001 column=Sdept:, timestamp=2025-04-23T12:34:37.830, value=22-1
95001 column=Sname:, timestamp=2025-04-23T12:34:11.714, value=Liying
95001 column=course:, timestamp=2025-04-23T12:34:45.744, value=software
95002 column=Sname:, timestamp=2025-04-23T13:15:11.311, value=ZhangSan
1 row(s)
Took 0.0077 seconds
查看有哪些表:
describe '表名':查看指定表的描述
list:列出所有表
Delete
删除某个单元格数据
delete '表名','行键','列限定符' #删除这三位确定的单元格内数据
deleteall '表名','行键' #删除该行所有数据
delete不会马上删除数据,会给数据打上标记,当系统合并数据时一并处理
删除表
disable '表名' #代表使该表不可用,并没有删除
drop '表名' #删除该表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号