
Hadoop(2):Hadoop伪分布式模式安装测试
以下操作在 Hadoop(1):Centos 7 安装 Hadoop 3.2.1 基础上操作。
一、配置集群
1、配置 HDFS
a)、配置 hadoop-end.sh
# cd /opt/module/hadoop-3.2.1/
将 hadoop-env.sh 中的 JAVA_HOME 的值修改为当前JDK的安装目录
获取当前 jdk 的安装路径
# echo $JAVA_HOME

修改 hadoop-env.sh
# vim etc/hadoop/hadoop-env.sh
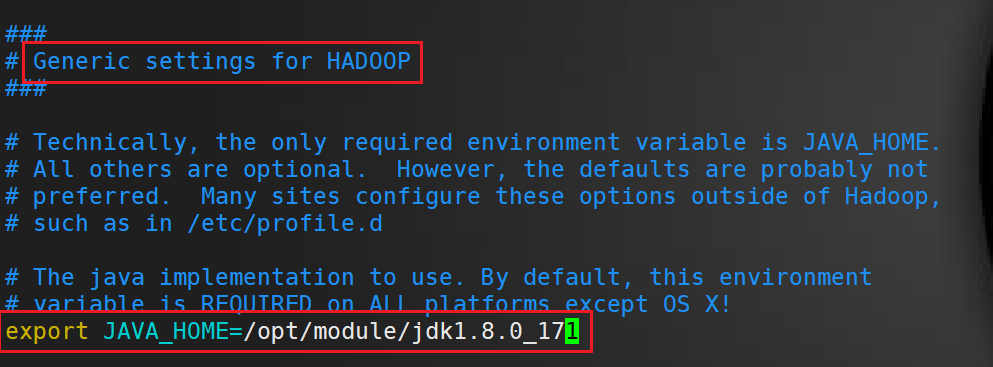
修改 JAVA_HOME 路径
export JAVA_HOME=/opt/module/jdk1.8.0_171
b)、配置 core-site.xml
# vim etc/hadoop/core-site.xml
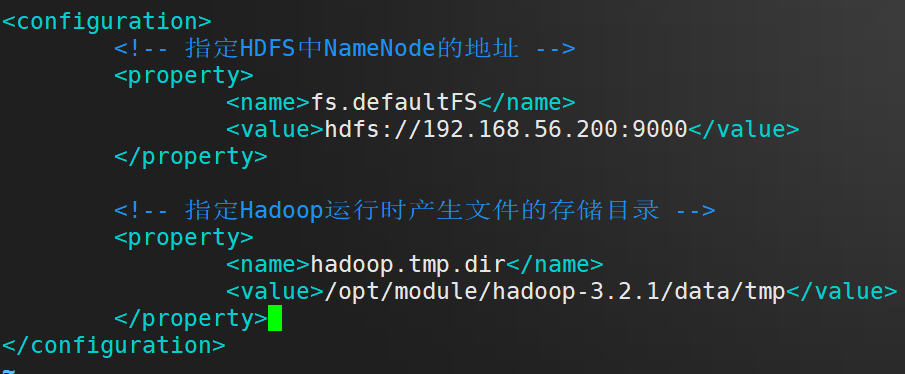
在 configuration 标签里面 插入 以下内容
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.200:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.2.1/data/tmp</value>
</property>
c)、配置 hdfs-site.xml
# vim etc/hadoop/hdfs-site.xml
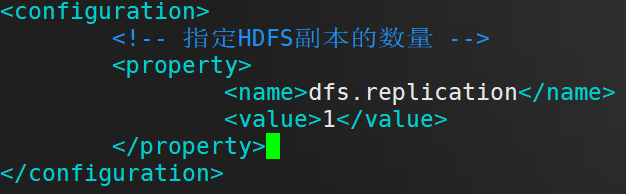
在 configuration 标签里面 插入 以下内容
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
2、配置YARN
a)、配置 yarn-site.xml
查看hadoop classpath
# hadoop classpath
将回显的内容记录下来

在 configuration 标签里面 插入 以下内容
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.56.200</value>
</property
<!-- value值 输入刚才返回的Hadoop classpath路径-->
<property>
<name>yarn.application.classpath</name>
<value>/opt/module/hadoop-3.2.1/etc/hadoop:/opt/module/hadoop-3.2.1/share/hadoop/common/lib/*:/opt/module/hadoop-3.2.1/share/hadoop/common/*:/opt/module/hadoop-3.2.1/share/hadoop/hdfs:/opt/module/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.2.1/share/hadoop/hdfs/*:/opt/module/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.2.1/share/hadoop/mapreduce/*:/opt/module/hadoop-3.2.1/share/hadoop/yarn:/opt/module/hadoop-3.2.1/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.2.1/share/hadoop/yarn/*</value>
</property>

3、配置 MapReduce
a)、配置:mapred-site.xml
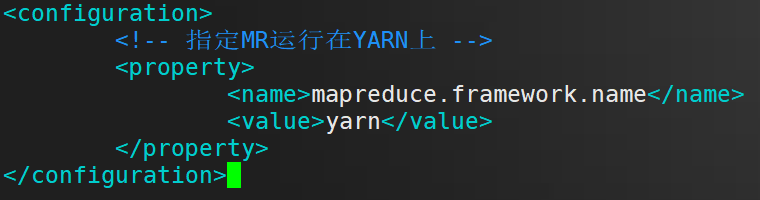
在 configuration 标签里面 插入 以下内容
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
二、启动集群
格式化NameNode(第一次启动时格式化,以后就不要总格式化)
# bin/hdfs namenode -format
启动NameNode
# sbin/hadoop-daemon.sh start namenode
启动DataNode
# sbin/hadoop-daemon.sh start datanode
查看是否启动成功
# jps
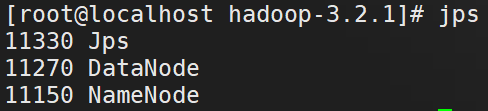
web端查看HDFS文件系统
浏览器访问: http://192.168.56.200:9870/dfshealth.html#tab-overview
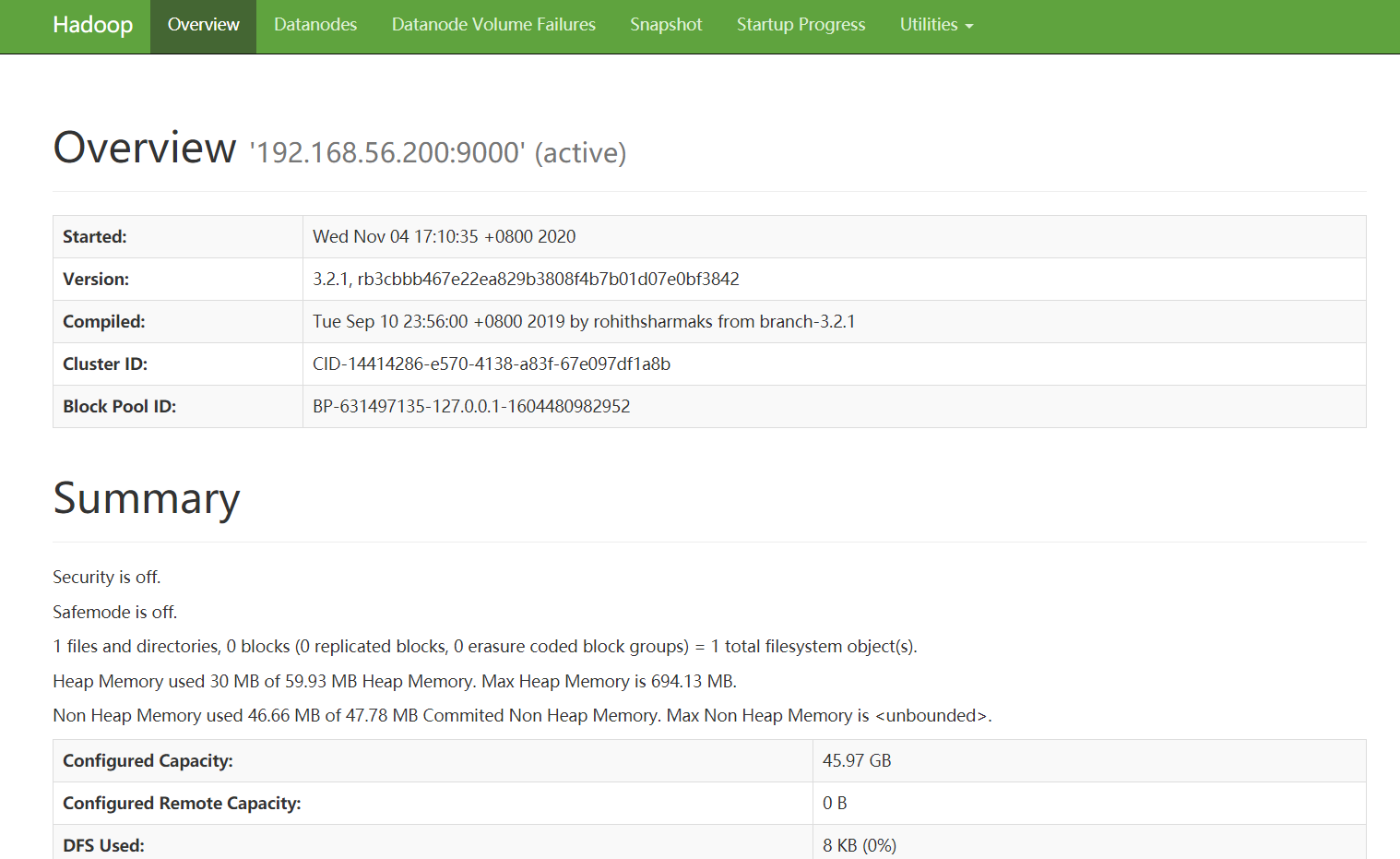
HDFS 成功启动。
启动ResourceManager
# sbin/yarn-daemon.sh start resourcemanager
启动NodeManager
# sbin/yarn-daemon.sh start nodemanager
web端查看yarn
浏览器访问: http://192.168.56.200:8088/cluster
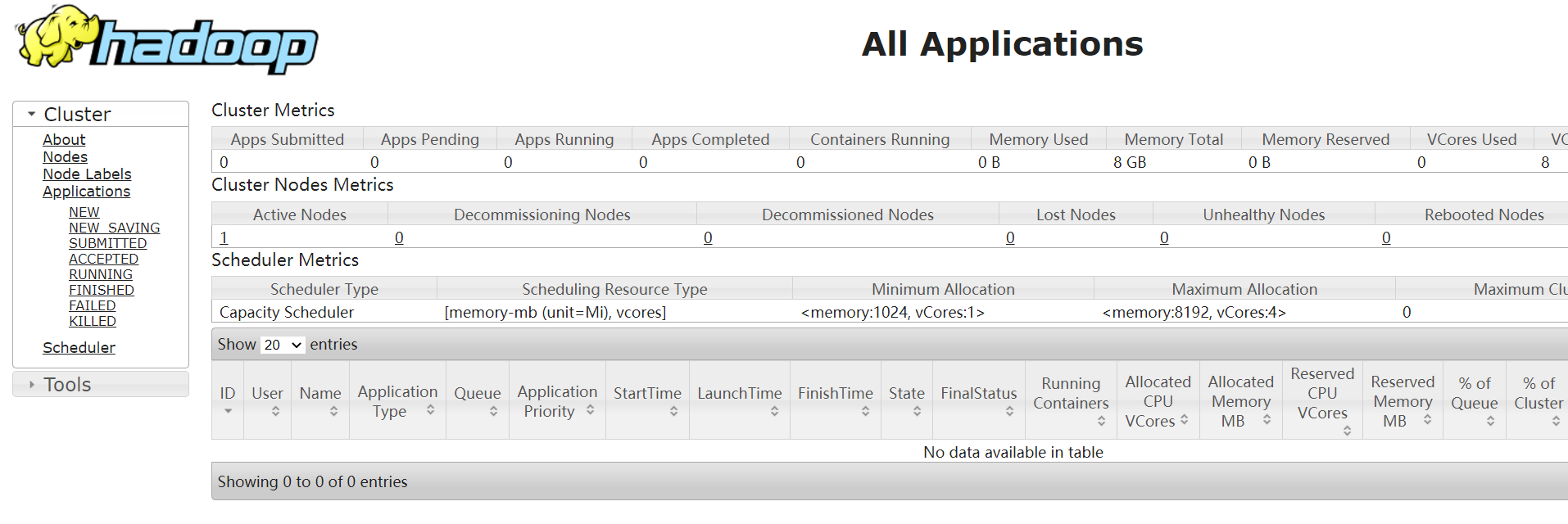
YARN 启动成功。
三、测试 wordcount 案例
1、将 wcinput 文件夹上传至 hdfs 根目录
# hadoop fs -put wcinput /
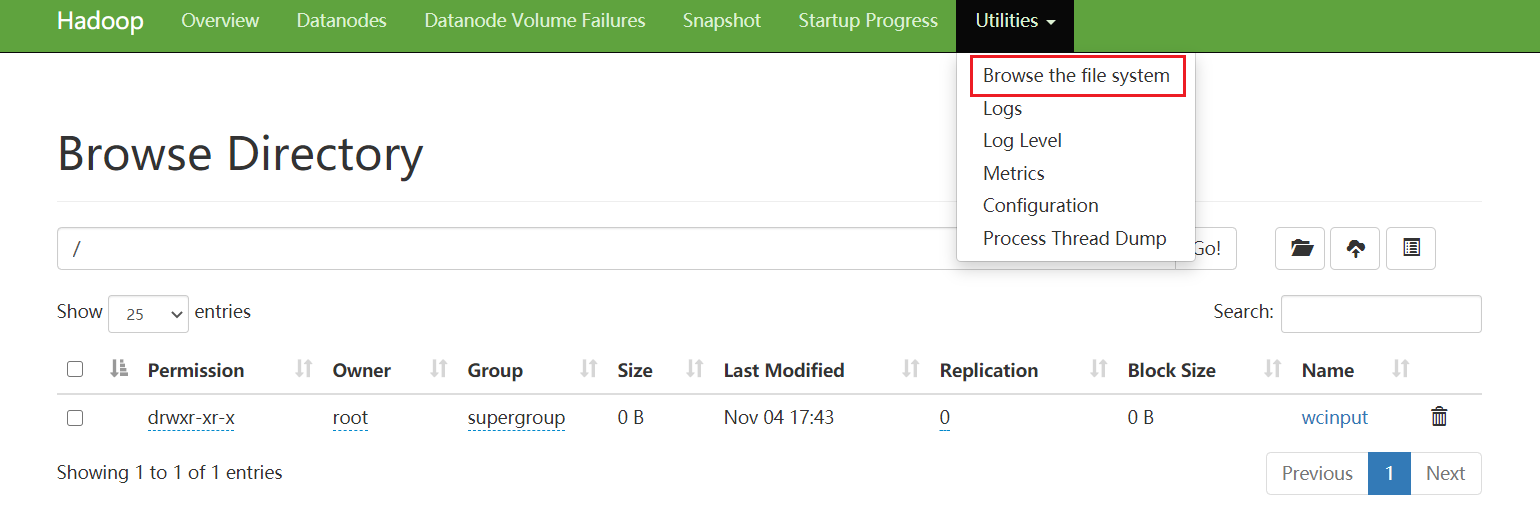
浏览器查看 文件目录 可以看到新上传 wcinput 文件夹。
2、运行MapReduce程序
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /wcinput /wcoutput
执行完成,刷新浏览器 可以看到执行输出的 wcoutput 文件夹
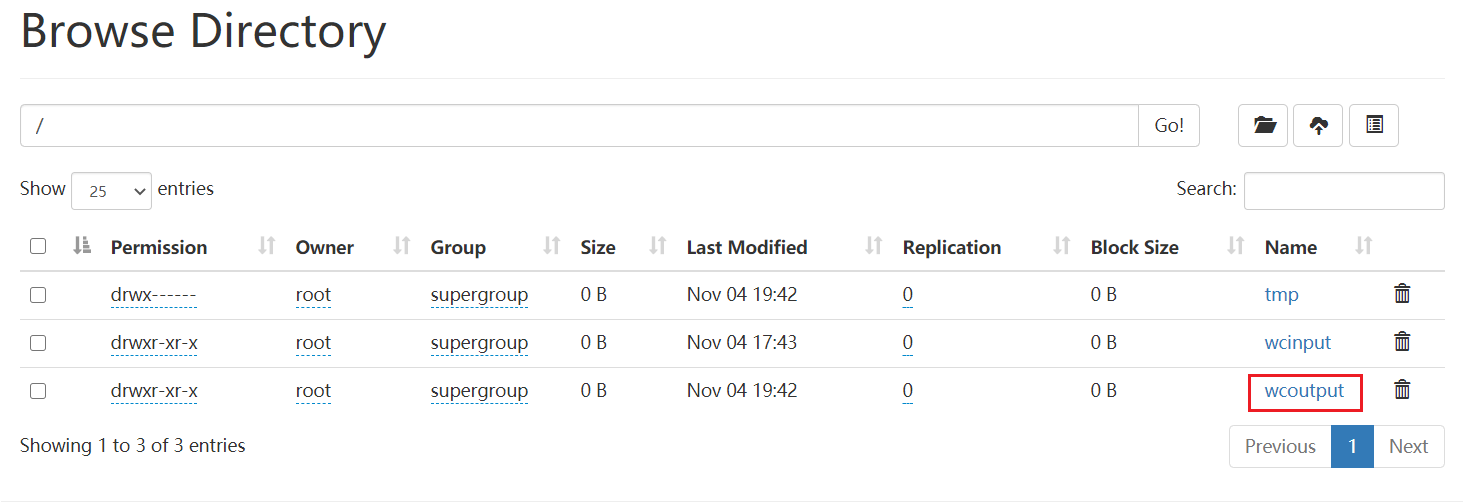
命令行查看结果
# hadoop fs -cat /wcoutput/*
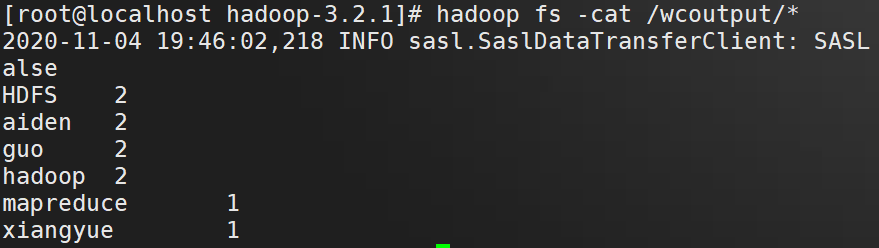
至此Hadoop伪分布式模式安装完成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号