

机器学习与Tensorflow(1)——机器学习基本概念、tensorflow实现简单线性回归
一、机器学习基本概念
1.训练集和测试集
训练集(training set/data)/训练样例(training examples): 用来进行训练,也就是产生模型或者算法的数据集
测试集(testing set/data)/测试样例 (testing examples):用来专门进行测试已经学习好的模型或者算法的数据集
2.特征向量
特征向量(features/feature vector):属性的集合,通常用一个向量来表示,附属于一个实例
3.分类问题和回归问题
分类 (classification): 目标标记为类别型(离散型)数据(category)
回归(regression): 目标标记为连续性数值 (continuous numeric value)
4.机器学习分类
有监督学习(supervised learning): 训练集有类别标记(class label)
无监督学习(unsupervised learning): 无类别标记(class label)
半监督学习(semi-supervised learning):有类别标记的训练集 + 无标记的训练集
二、简单线性回归
基本概念:
- 简单线性回归包含一个自变量(x)和一个因变量(y)
- 被用来进行预测的变量叫做: 自变量(independent variable), x, 输入(input)
- 被预测的变量叫做:因变量(dependent variable), y, 输出(output)
- 以上两个变量的关系用一条直线来模拟
三、Tensorflow基本概念
1.使用图(graphs)来表示计算任务
2.在被称之为会话(Session)的上下文(context)中执行图
3.使用tensor(张量)表示数据
4.通过变量(Variable)来维护状态
5.使用feed和fetch可以为任何的操作赋值或者从其中获取数据
总结
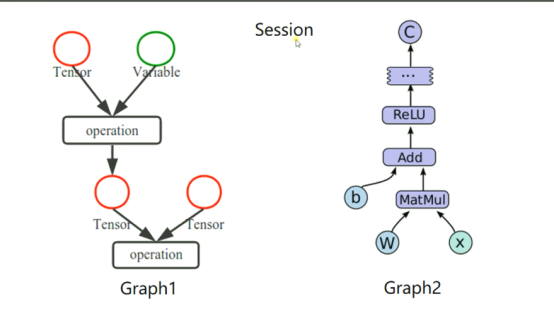
- Tensorflow是一个编程系统,使用图(graphs)来表示计算任务,
- 图(graphs)中的节点称之为op(operation)
- 一个op获得0个或者多个tensor(张量),执行计算,产生0个或者多个tensor。
- tensor看作是一个n维的数组或者列表。
- 图必须在会话(Session)里被启动。
#通过示意图来理解其中含义:
#通过程序来理解其中含义:
#这两句代码是防止警告(The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.) import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf m1 = tf.constant([[3,3]]) #创建一个常量op m2 = tf.constant([[2],[3]]) #创建一个常量op product =tf.matmul(m1,m2) #创建一个矩阵乘法op,并将m1和m2传入 sess = tf.Session() #定义一个会话,启动默认图 result = sess.run(product) #调用sess的run方法来执行矩阵乘法op,run(product)触发了图中的3个op print(result) sess.close #关闭会话 #执行结果 [[15]]
#上述程序关于启动默认图有一个简单写法
sess = tf.Session() result = sess.run(product) print(result) sess.close
等价表达方式:
with tf.Session() as sess: result = sess.run(product) print(result)
四、Tensorflow变量介绍
#变量介绍 import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf x = tf.Variable([1,2]) #创建一个变量op a = tf.constant([3,3]) #创建一个常量op sub_m = tf.subtract(x,a) #创建一个减法op add_m = tf.add(x,sub_m) #创建一个加法op init = tf.global_variables_initializer() #变量初始化(要想使用变量,必须写这句代码) with tf.Session() as sess: #定义一个会话,启动默认图 sess.run(init) #触发变量op print(sess.run(sub_m)) print(sess.run(add_m))
# 要想使用变量,必须进行变量初始化
init = tf.global_variables_initializer()
#利用程序实现自增1
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf state = tf.Variable(0,name='counter') #创建一个变量op,并初始化为0 new_value = tf.add(state,1) #创建一个op,作用是使state加1 update = tf.assign(state,new_value) #赋值op init = tf.global_variables_initializer() #变量初始化 with tf.Session() as sess: sess.run(init) print(sess.run(state)) for _ in range(5): sess.run(update) print(sess.run(state)) #执行结果 0 1 2 3 4 5
五、Tensorflow(fetch和feed)
fetch:在会话中可以运行多个op
#举例理解 import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf input1 = tf.constant(3.0) input2 = tf.constant(2.0) input3 = tf.constant(5.0) add_m = tf.add(input2,input3) mul = tf.multiply(input1,add_m) with tf.Session() as sess: result = sess.run([mul,add_m]) #运行多个op print(result) #执行结果 [21.0, 7.0]
feed:feed的数据以字典的形式传入
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf input1 = tf.placeholder(tf.float32) input2 = tf.placeholder(tf.float32) output = tf.multiply(input1,input2) with tf.Session() as sess: print(sess.run(output,feed_dict={input1:[8.],input2:[2.]})) #feed:feed的数据以字典的形式传入
六、利用tensorflow 实现简单线性回归
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf import numpy as np #使用numpy生成100个随机点 x_data = np.random.rand(100) y_data = x_data * 0.1 + 0.2 #构造一个线性模型 b = tf.Variable(0.0) k = tf.Variable(0.0) y = k * x_data + b #二次代价函数 loss = tf.reduce_mean(tf.square(y_data-y)) #定义一个梯度下降算法来进行训练的优化器 optimizer = tf.train.GradientDescentOptimizer(0.2) #最小化代价函数 train = optimizer.minimize(loss) #初始化变量 init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) for step in range(201): sess.run(train) if step % 20 == 0: print(step,sess.run([k,b])) #执行结果 0 [0.057367731, 0.1013036] 20 [0.10604427, 0.19655526] 40 [0.10355464, 0.19797418] 60 [0.10209047, 0.19880863] 80 [0.10122941, 0.19929935] 100 [0.10072301, 0.19958796] 120 [0.10042521, 0.19975767] 140 [0.10025007, 0.19985747] 160 [0.10014708, 0.19991617] 180 [0.10008651, 0.1999507] 200 [0.10005087, 0.19997101]
#训练200次后,k的值为0.10005087,接近0.1;b的值为0.19997101,接近0.2.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号