request库的函数和参数
BeautifulSoup的5个元素
bs4库的捷信器lxml
标签数的图,上行,下行、平行
信息的三种形式如何来标记
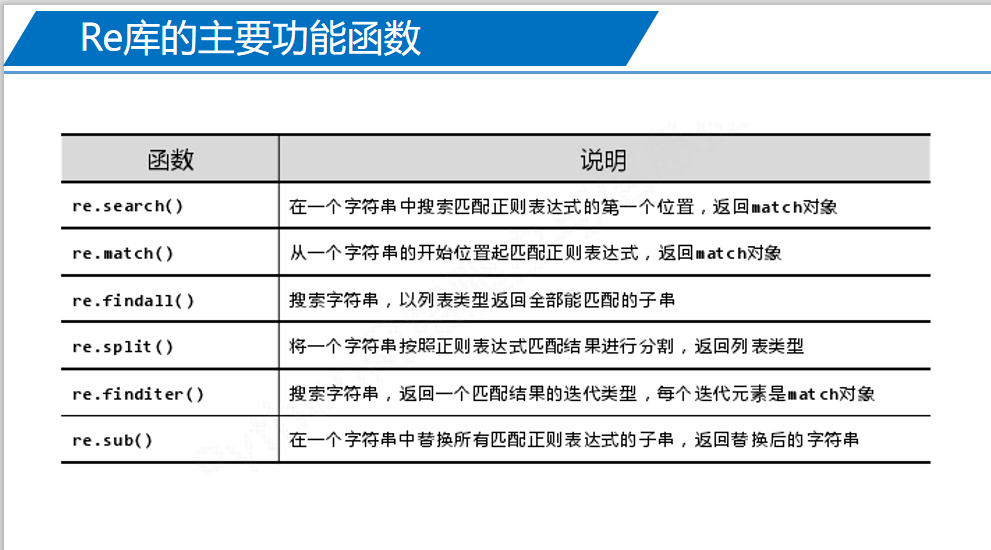
正则表达式的表
re库的6个函数
re库怎么等价成表达式
scrapy的框架,创建(genspider)一个爬虫的命令和运行(crawl)一个爬虫
国内的电话号码正则表达式
读写csv文件
//方法一:
import re
import requests
import csv
r=requests.get("http://python123.io/ws/demo.html")
a=r.text
b=re.compile(r'[1-5]\d{5}')
c=b.findall(a)
l1=[["序号","网址"]]
with open("e://guoli/1.csv","w",newline="")as f1:
x1=csv.writer(f1)
x1.writerows(l1)
with open("e://guoli/1.csv","a",newline="")as f2:
for i in range(0,len(c)):
j=[[i+1,c[i]]]
x2=csv.writer(f2)
x2.writerows(j)
//方法二
import re
import requests
import csv
r=requests.get("http://python123.io/ws/demo.html")
a=r.text
b=re.compile(r'[1-5]\d{5}')
c=b.finditer(a)
l1=[["序号","网址"]]
with open("e://guoli/2.csv","w",newline="")as f1:
x1=csv.writer(f1)
x1.writerows(l1)
t=1
with open("e://guoli/2.csv","a",newline="")as f2:
for i in c:
j=[[t,i.group()]]
x2=csv.writer(f2)
x2.writerows(j)
t=t+1
搜索网站的源码的标签
//方法一
import requests
r=requests.get('https://s.taobao.com/search?q=书包')
a=r.text
from bs4 import BeautifulSoup
b=BeautifulSoup(a,'html.parser')
import re
e="{:4}\t{:4}"
print(e.format("序号","标签"))
x=1
for j in b.find_all(True):
if j.name!=None:
print(e.format(x,j.name))
x+=1
//方法二
import requests
r=requests.get('https://s.taobao.com/search?q=书包')
a=r.text
from bs4 import BeautifulSoup
b=BeautifulSoup(a,'html.parser')
import re
e="{:4}\t{:4}"
print(e.format("序号","标签"))
x=1
for j in b.descendants: #此处不同
if j.name!=None:
print(e.format(x,j.name))
x+=1
获取网页源码数据
import requests
a='http://www.python123.io/ws/demo.html'
try:
b=requests.get(a,timeout=30)
b.raise_for_status()
b.encoding=b.apparent_encoding
except:
print("获取数据失败!")
with open('e://guoli/3.txt','w')as f:
f.write("获取数据如下:")
f.write(b.text)
f.close()
from bs4 import BeautifulSoup
c=b.text
d=BeautifulSoup(c,'html.parser')
with open('e://guoli/3.txt','a')as f:
f.write("\n整理后的数据如下:\n")
f.write(d.prettify())
f.close
Requests库的2主要对象的属性
![]()
Requests库的7个主要方法
![]()
爬取网页的通用代码框架
![]()
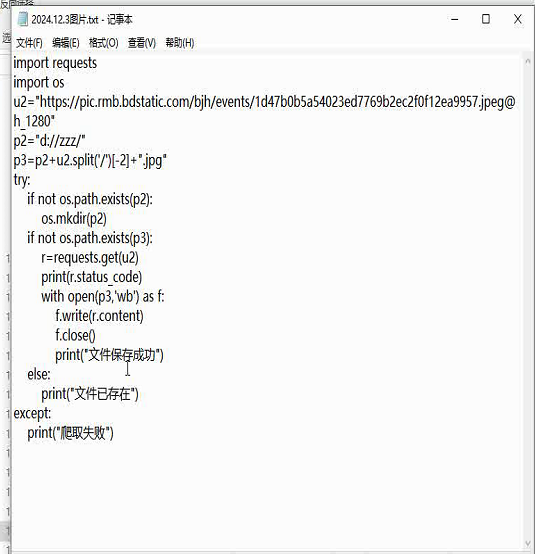
爬取图片
![]()
import requests
import os
url='https://b0.bdstatic.com/f656c7b03072e3675a6b51ae07cb5626.jpg@h_1280'
p2='e://guoli/'
p3=p2+url.split('/')[-1]+'.jpg'
try:
if not os.path.exists(p2):
os.mkdir(p2)
if not os.path.exists(p3):
r=requests.get(url)
r.encoding=r.apparent_encoding
a=r.content
with open(p3,'wb')as f:
f.write(a)
f.close()
print("文件保存成功")
else:
print('文件已经存在!')
except:
print("爬取失败")
用Try和Finally爬取京东
import requests
a='https://www.jd.com'
try:
r=requests.get(a)
# r=requests.request('get',a)
print(r.status_code)
r.encoding=r.apparent_encoding
print(r.text[:500])
except:
print('爬取失败!')
finally:
print('考试成功')
![]()






 浙公网安备 33010602011771号
浙公网安备 33010602011771号