Python学生成绩影响分析
一、摘要
该数据集来自kaggle,数据集包含了直接影响学生成绩的原因,本选题应用Python网络爬虫方法。
二、选题背景:
影响学生学习成绩的因素很多,但就学生本身来说,对学习成绩起决定作用的,主要是学生学习.的心理状态、智能水平、学习方法和学习时间等四个方面的因素。本书根据这四个方面的因素和中学生的学习特点,以方法为线索,从提高学生的认识水平着手,帮助学生提高心理素质、促进智能发展、改进学习方法和科学安排时间。
三、过程及代码:
1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 from matplotlib.font_manager import FontProperties 6 from sklearn.linear_model import LinearRegression 7 from sklearn.linear_model import ElasticNet 8 from sklearn.ensemble import RandomForestRegressor 9 from sklearn.ensemble import ExtraTreesRegressor 10 from sklearn.ensemble import GradientBoostingRegressor 11 from sklearn.svm import SVR 12 from sklearn.model_selection import train_test_split 13 from sklearn.preprocessing import MinMaxScaler 14 from sklearn.metrics import mean_squared_error, mean_absolute_error, median_absolute_error 15 import scipy 16 import pickle 17 18 19 # 初始化数据 20 plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体 21 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 22 sns.set(font='SimHei') # 解决Seaborn中文显示问题 23 student = pd.read_csv('student-mat.csv') 24 # print(student.head()) 25 26 # 分析G3数据属性 27 # print(student['G3'].describe())
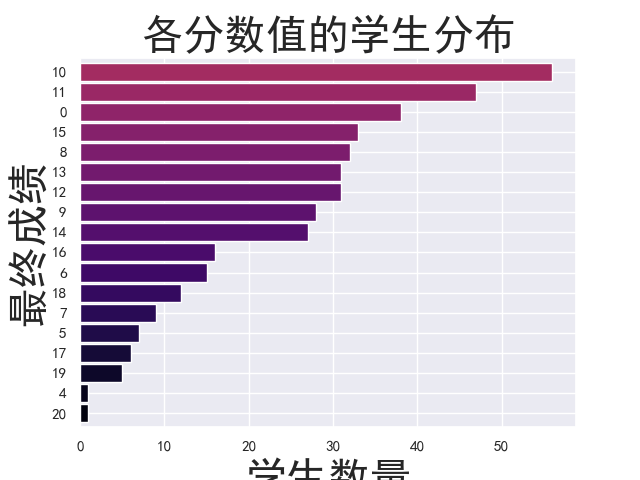
1 # 根据人数多少统计各分数段的学生人数 2 grade_counts = student['G3'].value_counts().sort_values().plot.barh(width=.9,color=sns.color_palette('inferno',40)) 3 grade_counts.axes.set_title('各分数值的学生分布',fontsize=30) 4 grade_counts.set_xlabel('学生数量', fontsize=30) 5 grade_counts.set_ylabel('最终成绩', fontsize=30) 6 plt.show()
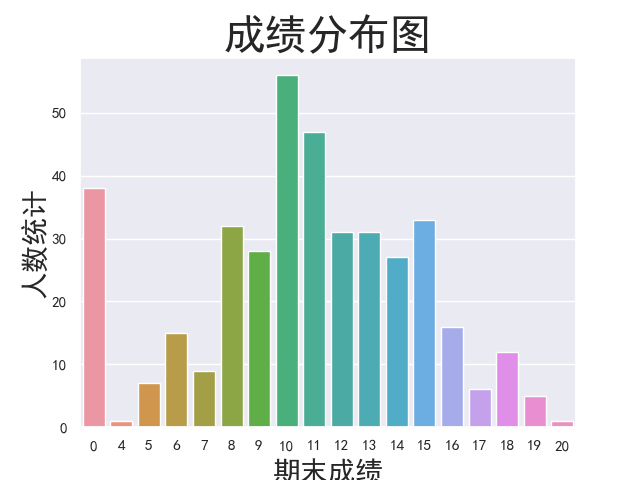
1 # 从低到高展示成绩分布图 2 grade_distribution = sns.countplot(student['G3']) 3 grade_distribution.set_title('成绩分布图', fontsize=30) 4 grade_distribution.set_xlabel('期末成绩', fontsize=20) 5 grade_distribution.set_ylabel('人数统计', fontsize=20) 6 plt.show() 7 8 # 检查各个列是否有null值,如果没有表示成绩中的0分确实是0分 9 # print(student.isnull().any())
1 # 分析性别比例 2 male_studs = len(student[student['sex'] == 'M']) 3 female_studs = len(student[student['sex'] == 'F']) 4 print('男同学数量:',male_studs) 5 print('女同学数量:',female_studs)
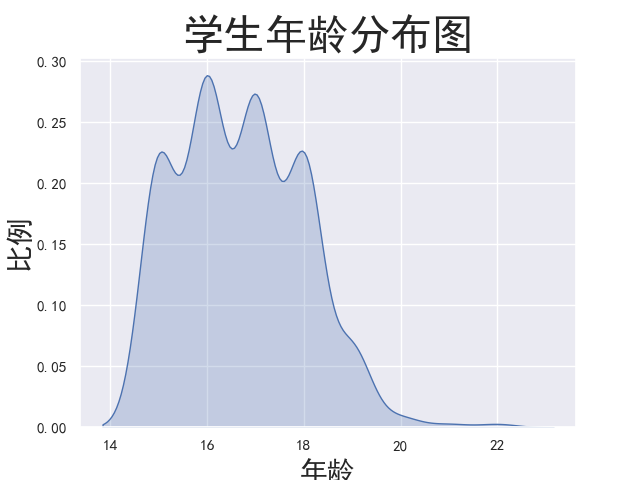
1 # 分析年龄分布比例(曲线图) 2 age_distribution = sns.kdeplot(student['age'], shade=True) 3 age_distribution.axes.set_title('学生年龄分布图', fontsize=30) 4 age_distribution.set_xlabel('年龄', fontsize=20) 5 age_distribution.set_ylabel('比例', fontsize=20) 6 plt.show()
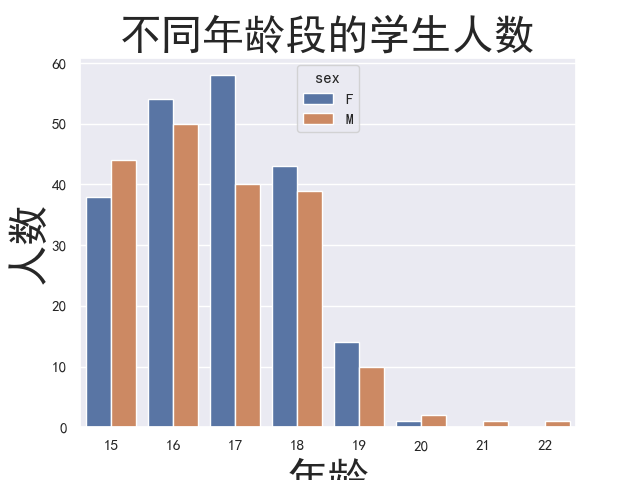
1 # 分性别年龄分布图(柱状图) 2 age_distribution_sex = sns.countplot('age', hue='sex', data=student) 3 age_distribution_sex.axes.set_title('不同年龄段的学生人数', fontsize=30) 4 age_distribution_sex.set_xlabel('年龄', fontsize=30) 5 age_distribution_sex.set_ylabel('人数', fontsize=30) 6 plt.show()
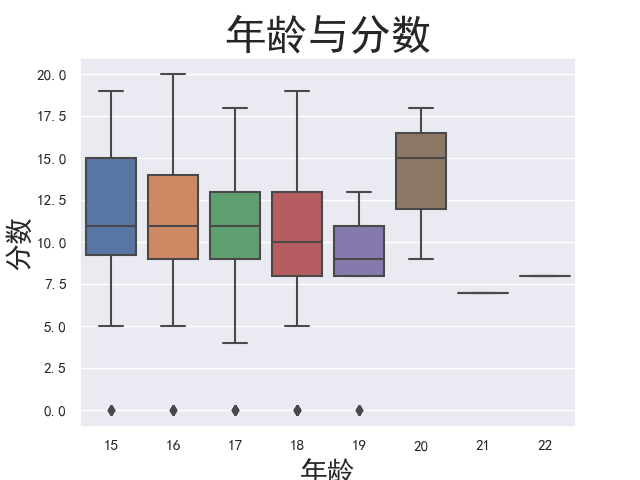
1 # 各年龄段的成绩箱型图 2 age_grade_boxplot = sns.boxplot(x='age', y='G3', data=student) 3 age_grade_boxplot.axes.set_title('年龄与分数', fontsize = 30) 4 age_grade_boxplot.set_xlabel('年龄', fontsize = 20) 5 age_grade_boxplot.set_ylabel('分数', fontsize = 20) 6 plt.show()
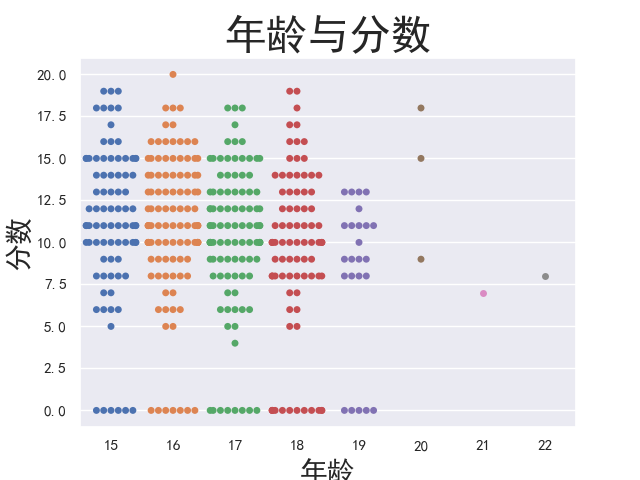
1 # 各年龄段的成绩分布图 2 age_grade_swarmplot = sns.swarmplot(x='age', y='G3', data=student) 3 age_grade_swarmplot.axes.set_title('年龄与分数', fontsize = 30) 4 age_grade_swarmplot.set_xlabel('年龄', fontsize = 20) 5 age_grade_swarmplot.set_ylabel('分数', fontsize = 20) 6 plt.show()
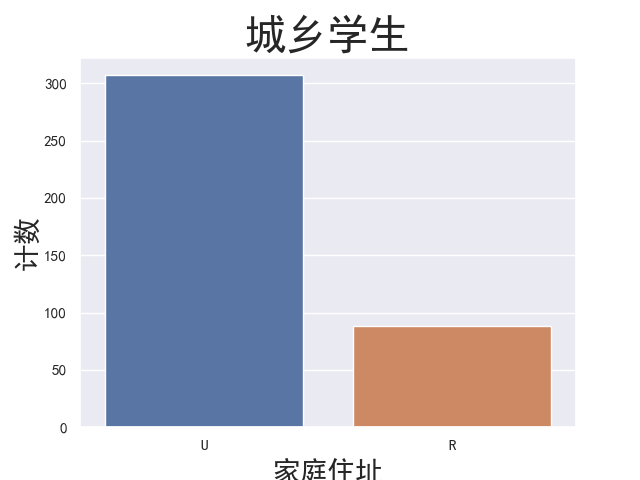
1 # 城乡学生计数 2 areas_countplot = sns.countplot(student['address']) 3 areas_countplot.axes.set_title('城乡学生', fontsize = 30) 4 areas_countplot.set_xlabel('家庭住址', fontsize = 20) 5 areas_countplot.set_ylabel('计数', fontsize = 20) 6 plt.show()
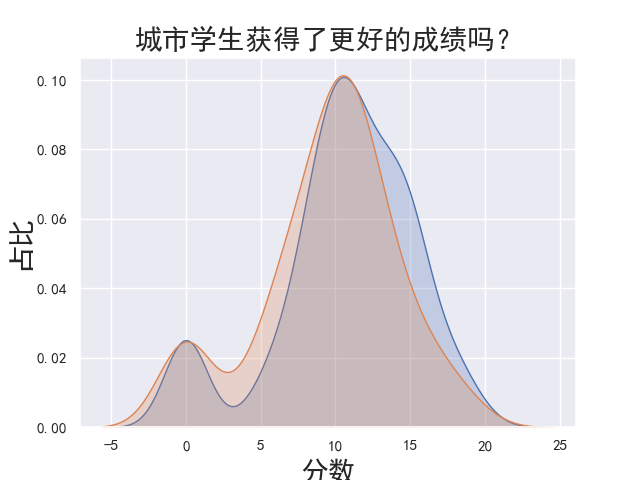
1 # Grade distribution by address 2 sns.kdeplot(student.loc[student['address'] == 'U', 'G3'], label='Urban', shade = True) 3 sns.kdeplot(student.loc[student['address'] == 'R', 'G3'], label='Rural', shade = True) 4 plt.title('城市学生获得了更好的成绩吗?', fontsize = 20) 5 plt.xlabel('分数', fontsize = 20) 6 plt.ylabel('占比', fontsize = 20) 7 plt.show() 8 9 # 选取G3属性值 10 labels = student['G3'] 11 12 # 删除school,G1和G2属性 13 student = student.drop(['school', 'G1', 'G2'], axis='columns') 14 15 # 对离散变量进行独热编码 16 student = pd.get_dummies(student) 17 18 # 选取相关性最强的8个 19 most_correlated = student.corr().abs()['G3'].sort_values(ascending=False) 20 most_correlated = most_correlated[:9] 21 print(most_correlated)
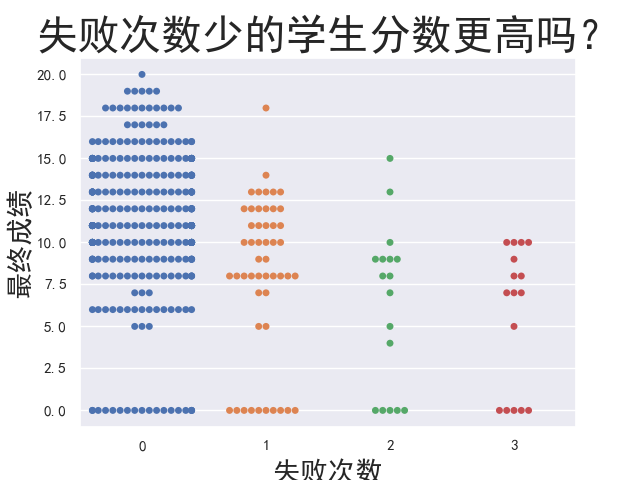
1 # 失败次数成绩分布图 2 failures_swarmplot = sns.swarmplot(x=student['failures'],y=student['G3']) 3 failures_swarmplot.axes.set_title('失败次数少的学生分数更高吗?', fontsize = 30) 4 failures_swarmplot.set_xlabel('失败次数', fontsize = 20) 5 failures_swarmplot.set_ylabel('最终成绩', fontsize = 20) 6 plt.show()
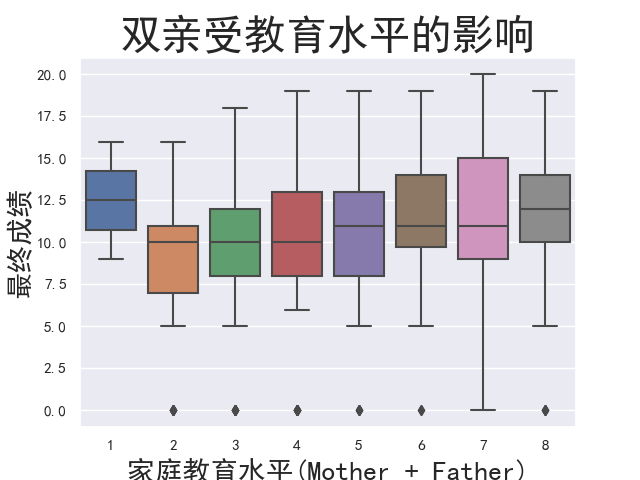
1 # 双亲受教育水平的影响 2 family_ed = student['Fedu'] + student['Medu'] 3 family_ed_boxplot = sns.boxplot(x=family_ed,y=student['G3']) 4 family_ed_boxplot.axes.set_title('双亲受教育水平的影响', fontsize = 30) 5 family_ed_boxplot.set_xlabel('家庭教育水平(Mother + Father)', fontsize = 20) 6 family_ed_boxplot.set_ylabel('最终成绩', fontsize = 20) 7 plt.show()
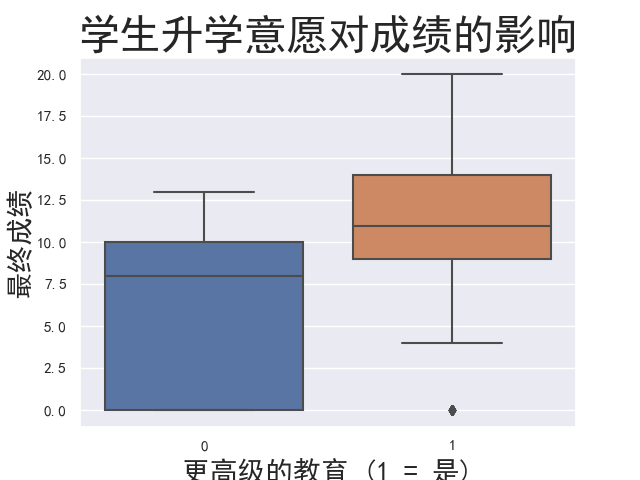
1 # 学生自己的升学意志对成绩的影响 2 personal_wish = sns.boxplot(x = student['higher_yes'], y=student['G3']) 3 personal_wish.axes.set_title('学生升学意愿对成绩的影响', fontsize = 30) 4 personal_wish.set_xlabel('更高级的教育 (1 = 是)', fontsize = 20) 5 personal_wish.set_ylabel('最终成绩', fontsize = 20) 6 plt.show()
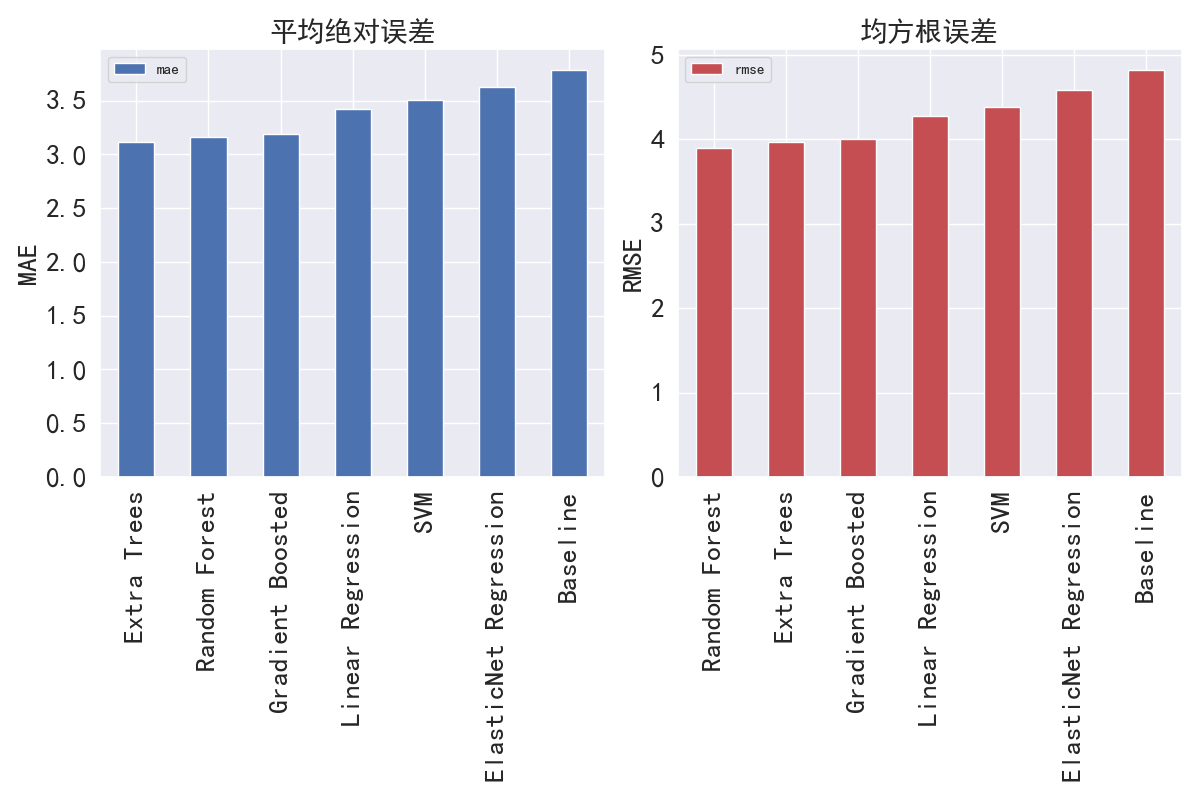
1 # 分割数据集 2 X_train, X_test, y_train, y_test = train_test_split(student, labels, test_size = 0.25, random_state=42) 3 4 # 计算平均绝对误差和均方根误差 5 # MAE-平均绝对误差 6 # RMSE-均方根误差 7 def evaluate_predictions(predictions, true): 8 mae = np.mean(abs(predictions - true)) 9 rmse = np.sqrt(np.mean((predictions - true) ** 2)) 10 11 return mae, rmse 12 13 # 求中位数 14 median_pred = X_train['G3'].median() 15 16 # 所有中位数的列表 17 median_preds = [median_pred for _ in range(len(X_test))] 18 19 # 存储真实的G3值以传递给函数 20 true = X_test['G3'] 21 22 # 展示基准 23 mb_mae, mb_rmse = evaluate_predictions(median_preds, true) 24 print('Median Baseline MAE: {:.4f}'.format(mb_mae)) 25 print('Median Baseline RMSE: {:.4f}'.format(mb_rmse)) 26 27 # 通过训练集训练和测试集测试来生成多个线性模型 28 def evaluate(X_train, X_test, y_train, y_test): 29 # 模型名称 30 model_name_list = ['Linear Regression', 'ElasticNet Regression', 31 'Random Forest', 'Extra Trees', 'SVM', 32 'Gradient Boosted', 'Baseline'] 33 X_train = X_train.drop('G3', axis='columns') 34 X_test = X_test.drop('G3', axis='columns') 35 36 # 实例化模型 37 model1 = LinearRegression() 38 model2 = ElasticNet(alpha=1.0, l1_ratio=0.5) 39 model3 = RandomForestRegressor(n_estimators=100) 40 model4 = ExtraTreesRegressor(n_estimators=100) 41 model5 = SVR(kernel='rbf', degree=3, C=1.0, gamma='auto') 42 model6 = GradientBoostingRegressor(n_estimators=50) 43 44 # 结果数据框 45 results = pd.DataFrame(columns=['mae', 'rmse'], index = model_name_list) 46 47 # 每种模型的训练和预测 48 for i, model in enumerate([model1, model2, model3, model4, model5, model6]): 49 model.fit(X_train, y_train) 50 predictions = model.predict(X_test) 51 52 # 误差标准 53 mae = np.mean(abs(predictions - y_test)) 54 rmse = np.sqrt(np.mean((predictions - y_test) ** 2)) 55 56 # 将结果插入结果框 57 model_name = model_name_list[i] 58 results.loc[model_name, :] = [mae, rmse] 59 60 # 中值基准度量 61 baseline = np.median(y_train) 62 baseline_mae = np.mean(abs(baseline - y_test)) 63 baseline_rmse = np.sqrt(np.mean((baseline - y_test) ** 2)) 64 65 results.loc['Baseline', :] = [baseline_mae, baseline_rmse] 66 67 return results 68 results = evaluate(X_train, X_test, y_train, y_test) 69 print(results) 70 71 # 找出最合适的模型 72 plt.figure(figsize=(12, 8)) 73 74 # 平均绝对误差 75 ax = plt.subplot(1, 2, 1) 76 results.sort_values('mae', ascending = True).plot.bar(y = 'mae', color = 'b', ax = ax, fontsize=20) 77 plt.title('平均绝对误差', fontsize=20) 78 plt.ylabel('MAE', fontsize=20) 79 80 # 均方根误差 81 ax = plt.subplot(1, 2, 2) 82 results.sort_values('rmse', ascending = True).plot.bar(y = 'rmse', color = 'r', ax = ax, fontsize=20) 83 plt.title('均方根误差', fontsize=20) 84 plt.ylabel('RMSE',fontsize=20) 85 plt.tight_layout() 86 plt.show() 87 88 # 保存线性回归模型 89 model = LinearRegression() 90 model.fit(X_train, y_train) 91 filename = 'LR_Model' 92 pickle.dump(model, open(filename, 'wb'))
完整代码:
1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 from matplotlib.font_manager import FontProperties 6 from sklearn.linear_model import LinearRegression 7 from sklearn.linear_model import ElasticNet 8 from sklearn.ensemble import RandomForestRegressor 9 from sklearn.ensemble import ExtraTreesRegressor 10 from sklearn.ensemble import GradientBoostingRegressor 11 from sklearn.svm import SVR 12 from sklearn.model_selection import train_test_split 13 from sklearn.preprocessing import MinMaxScaler 14 from sklearn.metrics import mean_squared_error, mean_absolute_error, median_absolute_error 15 import scipy 16 import pickle 17 18 19 # 初始化数据 20 plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体 21 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 22 sns.set(font='SimHei') # 解决Seaborn中文显示问题 23 student = pd.read_csv('student-mat.csv') 24 25 # print(student.head()) 26 27 # 分析G3数据属性 28 # print(student['G3'].describe()) 29 30 # 根据人数多少统计各分数段的学生人数 31 grade_counts = student['G3'].value_counts().sort_values().plot.barh(width=.9,color=sns.color_palette('inferno',40)) 32 grade_counts.axes.set_title('各分数值的学生分布',fontsize=30) 33 grade_counts.set_xlabel('学生数量', fontsize=30) 34 grade_counts.set_ylabel('最终成绩', fontsize=30) 35 plt.show() 36 37 # 从低到高展示成绩分布图 38 grade_distribution = sns.countplot(student['G3']) 39 grade_distribution.set_title('成绩分布图', fontsize=30) 40 grade_distribution.set_xlabel('期末成绩', fontsize=20) 41 grade_distribution.set_ylabel('人数统计', fontsize=20) 42 plt.show() 43 44 # 检查各个列是否有null值,如果没有表示成绩中的0分确实是0分 45 46 # print(student.isnull().any()) 47 48 # 分析性别比例 49 male_studs = len(student[student['sex'] == 'M']) 50 female_studs = len(student[student['sex'] == 'F']) 51 print('男同学数量:',male_studs) 52 print('女同学数量:',female_studs) 53 54 # 分析年龄分布比例(曲线图) 55 age_distribution = sns.kdeplot(student['age'], shade=True) 56 age_distribution.axes.set_title('学生年龄分布图', fontsize=30) 57 age_distribution.set_xlabel('年龄', fontsize=20) 58 age_distribution.set_ylabel('比例', fontsize=20) 59 plt.show() 60 61 # 分性别年龄分布图(柱状图) 62 age_distribution_sex = sns.countplot('age', hue='sex', data=student) 63 age_distribution_sex.axes.set_title('不同年龄段的学生人数', fontsize=30) 64 age_distribution_sex.set_xlabel('年龄', fontsize=30) 65 age_distribution_sex.set_ylabel('人数', fontsize=30) 66 plt.show() 67 68 # 各年龄段的成绩箱型图 69 age_grade_boxplot = sns.boxplot(x='age', y='G3', data=student) 70 age_grade_boxplot.axes.set_title('年龄与分数', fontsize = 30) 71 age_grade_boxplot.set_xlabel('年龄', fontsize = 20) 72 age_grade_boxplot.set_ylabel('分数', fontsize = 20) 73 plt.show() 74 75 # 各年龄段的成绩分布图 76 age_grade_swarmplot = sns.swarmplot(x='age', y='G3', data=student) 77 age_grade_swarmplot.axes.set_title('年龄与分数', fontsize = 30) 78 age_grade_swarmplot.set_xlabel('年龄', fontsize = 20) 79 age_grade_swarmplot.set_ylabel('分数', fontsize = 20) 80 plt.show() 81 82 # 城乡学生计数 83 areas_countplot = sns.countplot(student['address']) 84 areas_countplot.axes.set_title('城乡学生', fontsize = 30) 85 areas_countplot.set_xlabel('家庭住址', fontsize = 20) 86 areas_countplot.set_ylabel('计数', fontsize = 20) 87 plt.show() 88 89 # Grade distribution by address 90 sns.kdeplot(student.loc[student['address'] == 'U', 'G3'], label='Urban', shade = True) 91 sns.kdeplot(student.loc[student['address'] == 'R', 'G3'], label='Rural', shade = True) 92 plt.title('城市学生获得了更好的成绩吗?', fontsize = 20) 93 plt.xlabel('分数', fontsize = 20) 94 plt.ylabel('占比', fontsize = 20) 95 plt.show() 96 97 # 选取G3属性值 98 labels = student['G3'] 99 100 # 删除school,G1和G2属性 101 student = student.drop(['school', 'G1', 'G2'], axis='columns') 102 103 # 对离散变量进行独热编码 104 student = pd.get_dummies(student) 105 106 # 选取相关性最强的8个 107 most_correlated = student.corr().abs()['G3'].sort_values(ascending=False) 108 most_correlated = most_correlated[:9] 109 print(most_correlated) 110 111 # 失败次数成绩分布图 112 failures_swarmplot = sns.swarmplot(x=student['failures'],y=student['G3']) 113 failures_swarmplot.axes.set_title('失败次数少的学生分数更高吗?', fontsize = 30) 114 failures_swarmplot.set_xlabel('失败次数', fontsize = 20) 115 failures_swarmplot.set_ylabel('最终成绩', fontsize = 20) 116 plt.show() 117 118 # 双亲受教育水平的影响 119 family_ed = student['Fedu'] + student['Medu'] 120 family_ed_boxplot = sns.boxplot(x=family_ed,y=student['G3']) 121 family_ed_boxplot.axes.set_title('双亲受教育水平的影响', fontsize = 30) 122 family_ed_boxplot.set_xlabel('家庭教育水平(Mother + Father)', fontsize = 20) 123 family_ed_boxplot.set_ylabel('最终成绩', fontsize = 20) 124 plt.show() 125 126 # 学生自己的升学意志对成绩的影响 127 personal_wish = sns.boxplot(x = student['higher_yes'], y=student['G3']) 128 personal_wish.axes.set_title('学生升学意愿对成绩的影响', fontsize = 30) 129 personal_wish.set_xlabel('更高级的教育 (1 = 是)', fontsize = 20) 130 personal_wish.set_ylabel('最终成绩', fontsize = 20) 131 plt.show() 132 133 # 分割数据集 134 X_train, X_test, y_train, y_test = train_test_split(student, labels, test_size = 0.25, random_state=42) 135 136 # 计算平均绝对误差和均方根误差 137 138 # MAE-平均绝对误差 139 140 # RMSE-均方根误差 141 def evaluate_predictions(predictions, true): 142 mae = np.mean(abs(predictions - true)) 143 rmse = np.sqrt(np.mean((predictions - true) ** 2)) 144 145 return mae, rmse 146 147 # 求中位数 148 median_pred = X_train['G3'].median() 149 150 # 所有中位数的列表 151 median_preds = [median_pred for _ in range(len(X_test))] 152 153 # 存储真实的G3值以传递给函数 154 true = X_test['G3'] 155 156 # 展示基准 157 mb_mae, mb_rmse = evaluate_predictions(median_preds, true) 158 print('Median Baseline MAE: {:.4f}'.format(mb_mae)) 159 print('Median Baseline RMSE: {:.4f}'.format(mb_rmse)) 160 161 # 通过训练集训练和测试集测试来生成多个线性模型 162 def evaluate(X_train, X_test, y_train, y_test): 163 164 # 模型名称 165 model_name_list = ['Linear Regression', 'ElasticNet Regression', 166 'Random Forest', 'Extra Trees', 'SVM', 167 'Gradient Boosted', 'Baseline'] 168 X_train = X_train.drop('G3', axis='columns') 169 X_test = X_test.drop('G3', axis='columns') 170 171 # 实例化模型 172 model1 = LinearRegression() 173 model2 = ElasticNet(alpha=1.0, l1_ratio=0.5) 174 model3 = RandomForestRegressor(n_estimators=100) 175 model4 = ExtraTreesRegressor(n_estimators=100) 176 model5 = SVR(kernel='rbf', degree=3, C=1.0, gamma='auto') 177 model6 = GradientBoostingRegressor(n_estimators=50) 178 179 # 结果数据框 180 results = pd.DataFrame(columns=['mae', 'rmse'], index = model_name_list) 181 182 # 每种模型的训练和预测 183 for i, model in enumerate([model1, model2, model3, model4, model5, model6]): 184 model.fit(X_train, y_train) 185 predictions = model.predict(X_test) 186 187 # 误差标准 188 mae = np.mean(abs(predictions - y_test)) 189 rmse = np.sqrt(np.mean((predictions - y_test) ** 2)) 190 191 # 将结果插入结果框 192 model_name = model_name_list[i] 193 results.loc[model_name, :] = [mae, rmse] 194 195 # 中值基准度量 196 baseline = np.median(y_train) 197 baseline_mae = np.mean(abs(baseline - y_test)) 198 baseline_rmse = np.sqrt(np.mean((baseline - y_test) ** 2)) 199 200 results.loc['Baseline', :] = [baseline_mae, baseline_rmse] 201 202 return results 203 results = evaluate(X_train, X_test, y_train, y_test) 204 print(results) 205 206 # 找出最合适的模型 207 plt.figure(figsize=(12, 8)) 208 209 # 平均绝对误差 210 ax = plt.subplot(1, 2, 1) 211 results.sort_values('mae', ascending = True).plot.bar(y = 'mae', color = 'b', ax = ax, fontsize=20) 212 plt.title('平均绝对误差', fontsize=20) 213 plt.ylabel('MAE', fontsize=20) 214 215 # 均方根误差 216 ax = plt.subplot(1, 2, 2) 217 results.sort_values('rmse', ascending = True).plot.bar(y = 'rmse', color = 'r', ax = ax, fontsize=20) 218 plt.title('均方根误差', fontsize=20) 219 plt.ylabel('RMSE',fontsize=20) 220 plt.tight_layout() 221 plt.show() 222 223 # 保存线性回归模型 224 model = LinearRegression() 225 model.fit(X_train, y_train) 226 filename = 'LR_Model' 227 pickle.dump(model, open(filename, 'wb'))
四、总结:
通过以上分析,可以初步得出以下的结论:
1.双亲受教育水平会影响孩子成绩,父母学历越高,学生成绩越好
2.学生升学意愿会影响学生自身成绩
3.考试准备充分的同学成绩较高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号