


HDFS元数据合并过程详解
1、问题来源
1、随着集群的运行,edit logs文件逐步增大,管理该文件需要消耗资源
2、Namenode合并fsimage文件需要消耗资源
3、Namenode宕机后,再次恢复时会丢失一部分操作。
2、解决办法
使用secondarynamenode对元数据进行合并
3、触发条件(满足任意条件即可)
1、到达检查点周期,默认3600 秒,可通过 dfs.namenode.checkpoint.period属性手动配置。
2、到达设置事务数量,默认一百万条。可通过dfs.namenode.checkpoint.txns属性配置
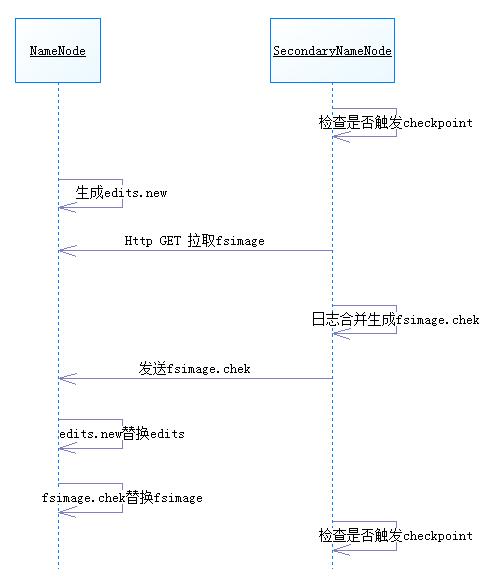
4、合并过程
1、secondarynamenode检查当前集群状态是否触发checkpoint的合并条件
2、若未触发则继续运行,否则开始元数据合并。
3、namenode停止向日志文件edits写入数据,并生成一个新的edits文件用于存储在合并期间产生的操作。
4、secondarynamenode通过Http GET方式从namenode处下载edits文件和fsimage文件,并将fsimage文件载入内存。
5、secondarynamenode逐条执行edits文件的更新操作,使内存中的fsimage文件保存最新的操作日志,结束后生成一个fsimage.chkt文件。
6、namenode从secondarynamenode出复制fsimage.chkt文件。此时namenode中存在四个相关文件,分别是edits、fsimage、edits.new、fsimage.chkt,在后两个文件中记录了最近的操作记录,因此将后两个新文件替换前两个旧记录,完成本次元数据合并的过程。
7、等待下一次出发checkpoint条件。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号