结对作业2
| 这个作业属于哪个课程 | 2021春软件工程实践W班 |
|---|---|
| 这个作业要求在哪里 | 链接 |
| 结对学号 | 221801311、221801313 |
| 这个作业的目标 | 合作开发 |
| 其他参考文献 | 无 |
部署地址
106.15.170.116:8000
git仓库链接和代码规范链接
git仓库
https://github.com/Ruleer/PairProject/
前端代码规范
https://github.com/Ruleer/PairProject/blob/main/codestyle-frontend.md
后端代码规范
https://github.com/tkhhhh/PersonalProject-Java/blob/main/221801313/codestyle.md
PSP表格
前端
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| ·Estimate | 估计这个任务需要多少时间 | 30 | 45 |
| Development | 开发 | 3420 | 3900 |
| ·Analysis | 需求分析 (包括学习新技术) | 240 | 300 |
| ·Design Spec | 生成设计文档 | 120 | 180 |
| ·Design Review | 设计复审 | 120 | 60 |
| ·Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| ·Design | 具体设计 | 480 | 480 |
| ·Coding | 具体编码 | 2160 | 2640 |
| ·Code Review | 代码复审 | 120 | 60 |
| ·Test | 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 420 | 360 |
| ·Test Repor | 测试报告 | 240 | 240 |
| ·Size Measurement | 计算工作量 | 60 | 60 |
| ·Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 60 |
| 合计 | 3870 | 4305 |
后端
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| ·Estimate | 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | 1420 | 1350 |
| ·Analysis | 需求分析 (包括学习新技术) | 120 | 150 |
| ·Design Spec | 生成设计文档 | 60 | 50 |
| ·Design Review | 设计复审 | 30 | 10 |
| ·Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| ·Design | 具体设计 | 60 | 50 |
| ·Coding | 具体编码 | 960 | 960 |
| ·Code Review | 代码复审 | 60 | 40 |
| ·Test | 测试(自我测试,修改代码,提交修改) | 120 | 100 |
| Reporting | 报告 | 240 | 180 |
| ·Test Repor | 测试报告 | 120 | 90 |
| ·Size Measurement | 计算工作量 | 10 | 10 |
| ·Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 110 | 80 |
| 合计 | 1680 | 1545 |
成品展示
-
论文列表
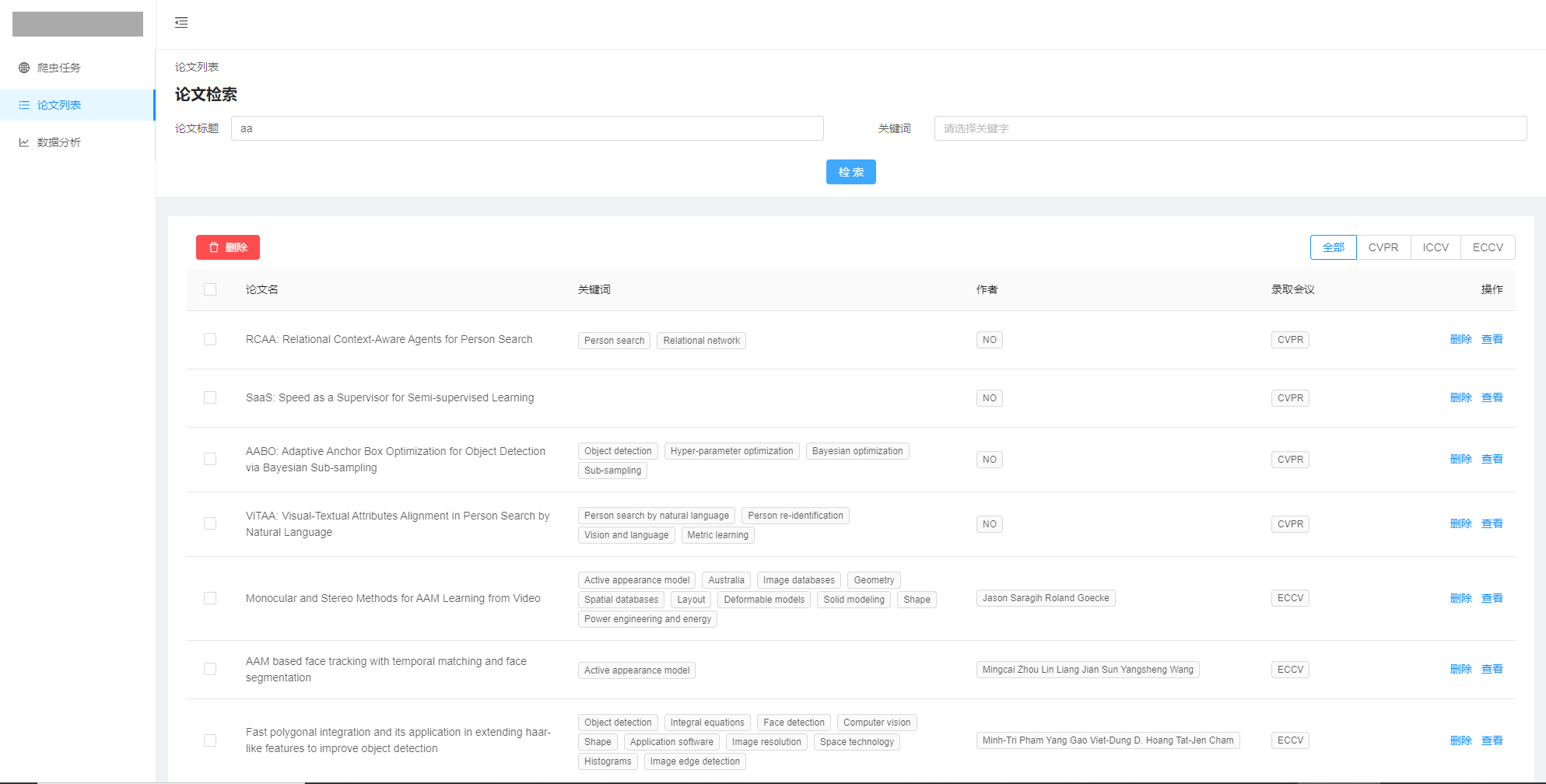
-
爬虫任务列表
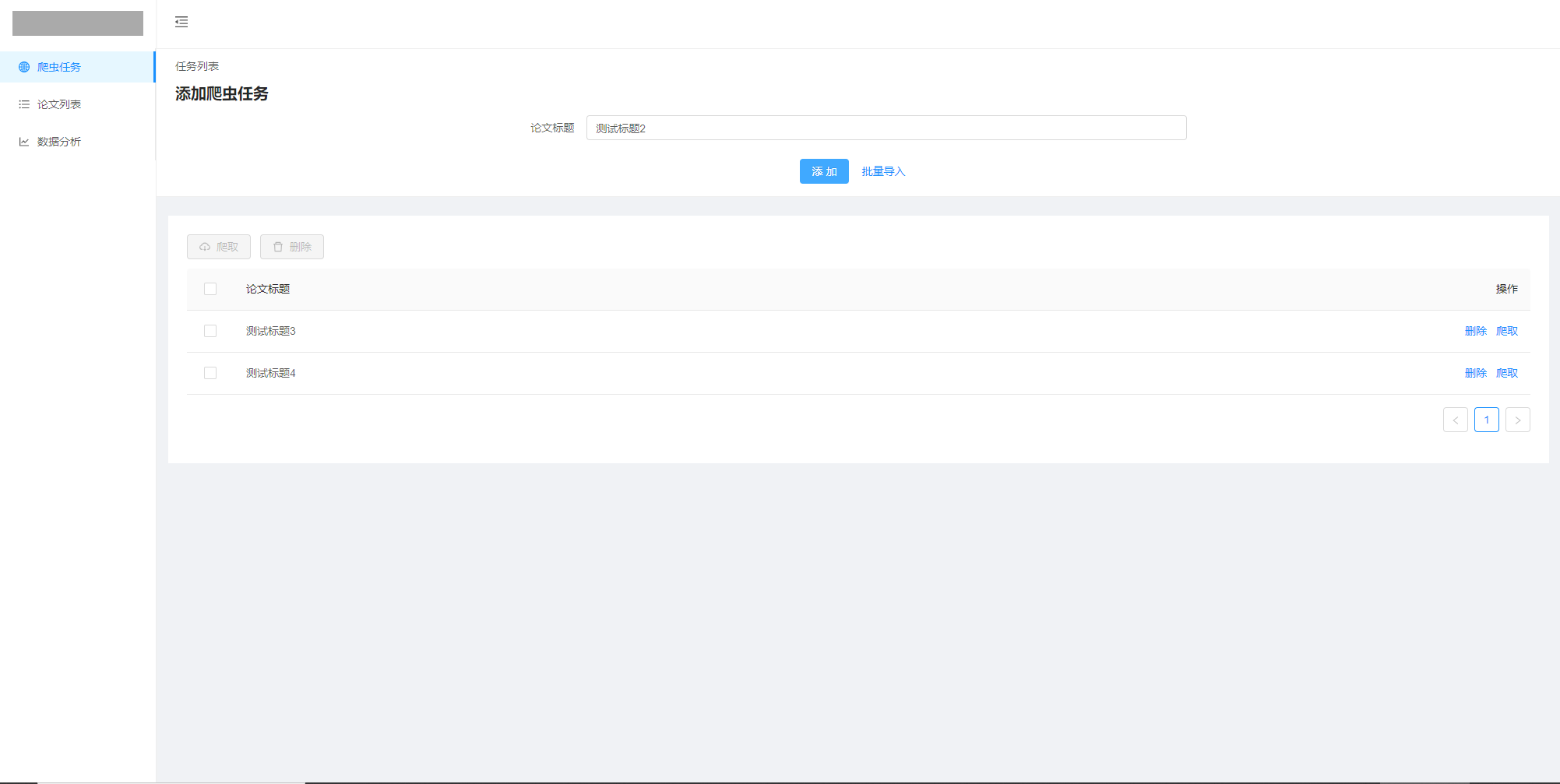
-
批量导入爬虫任务
加载过程有剪辑
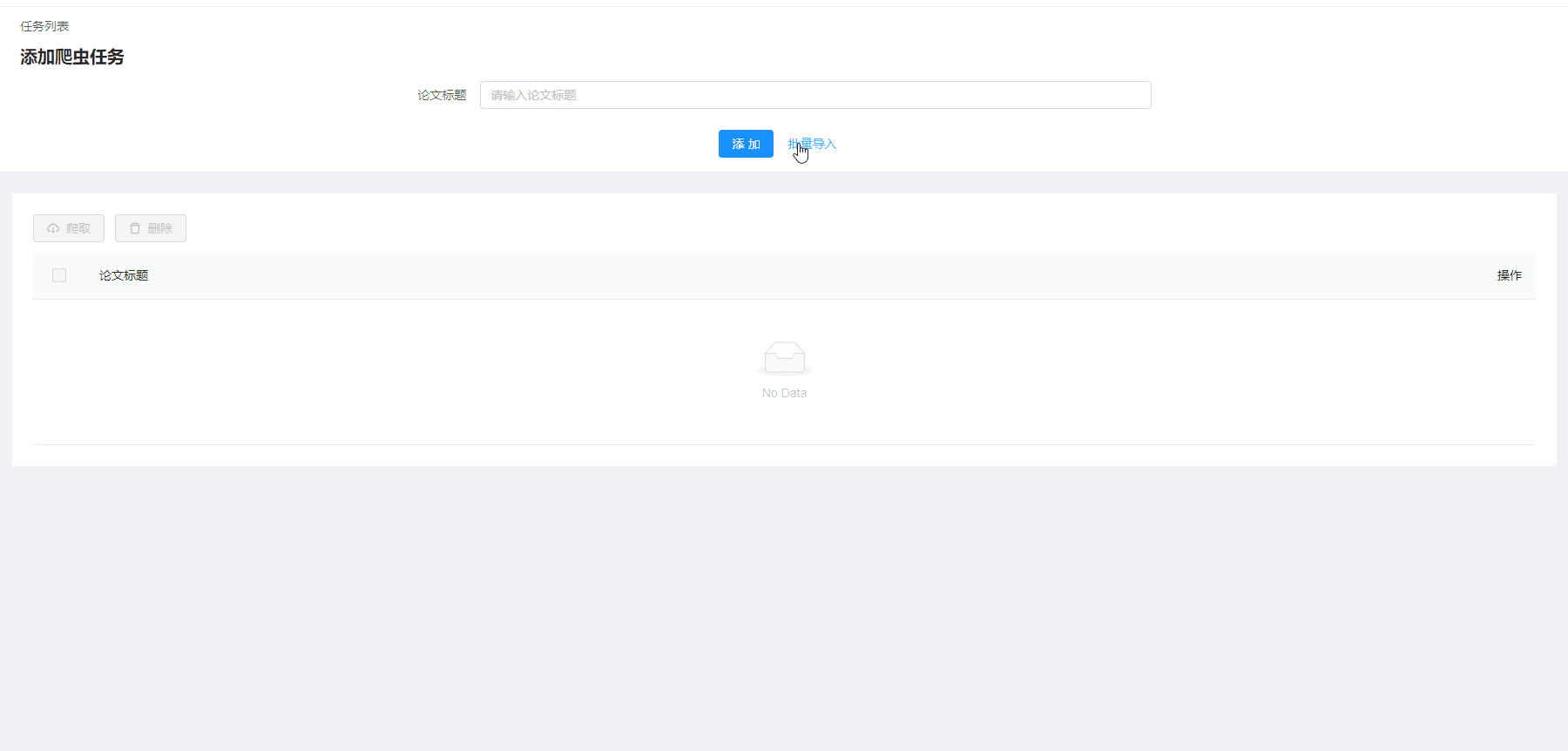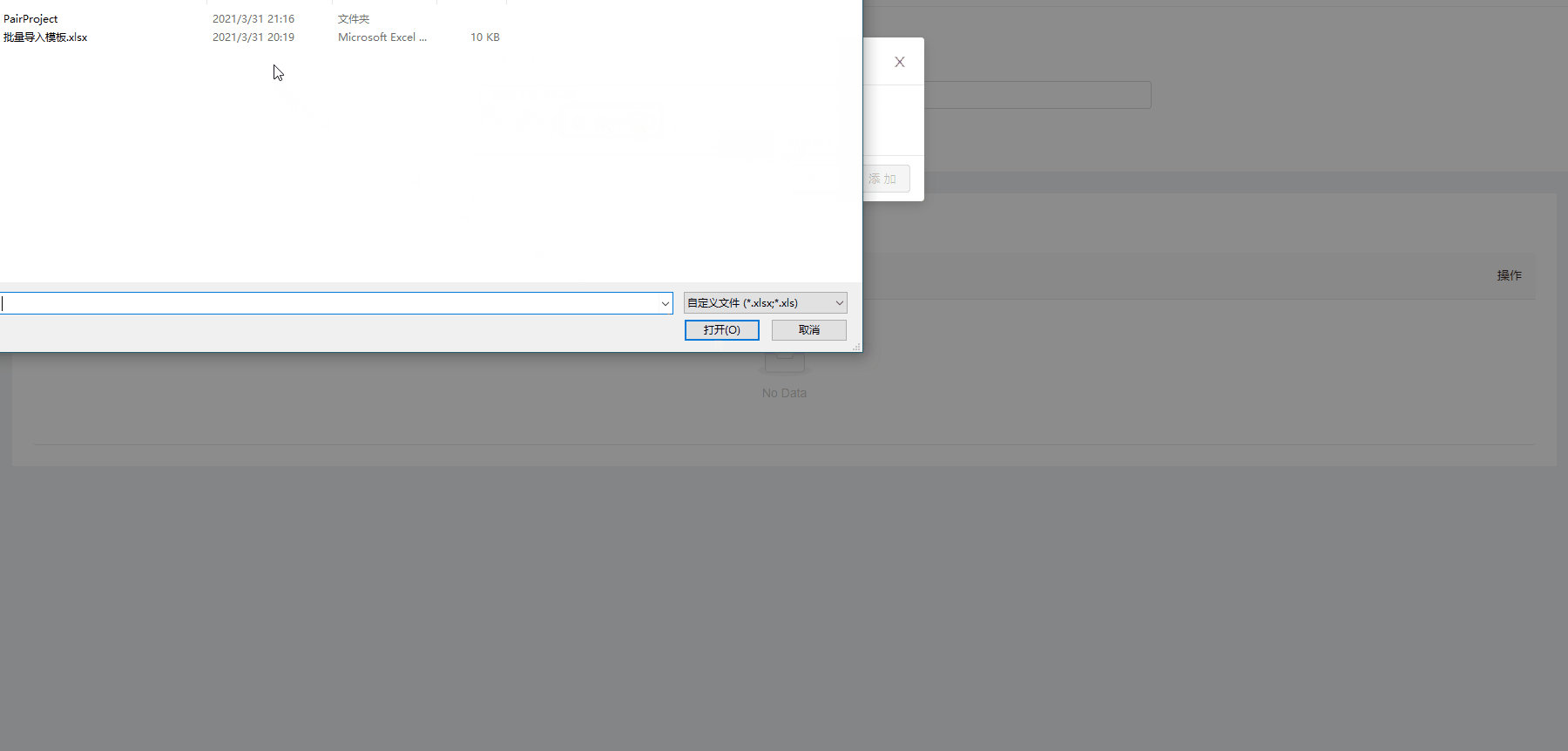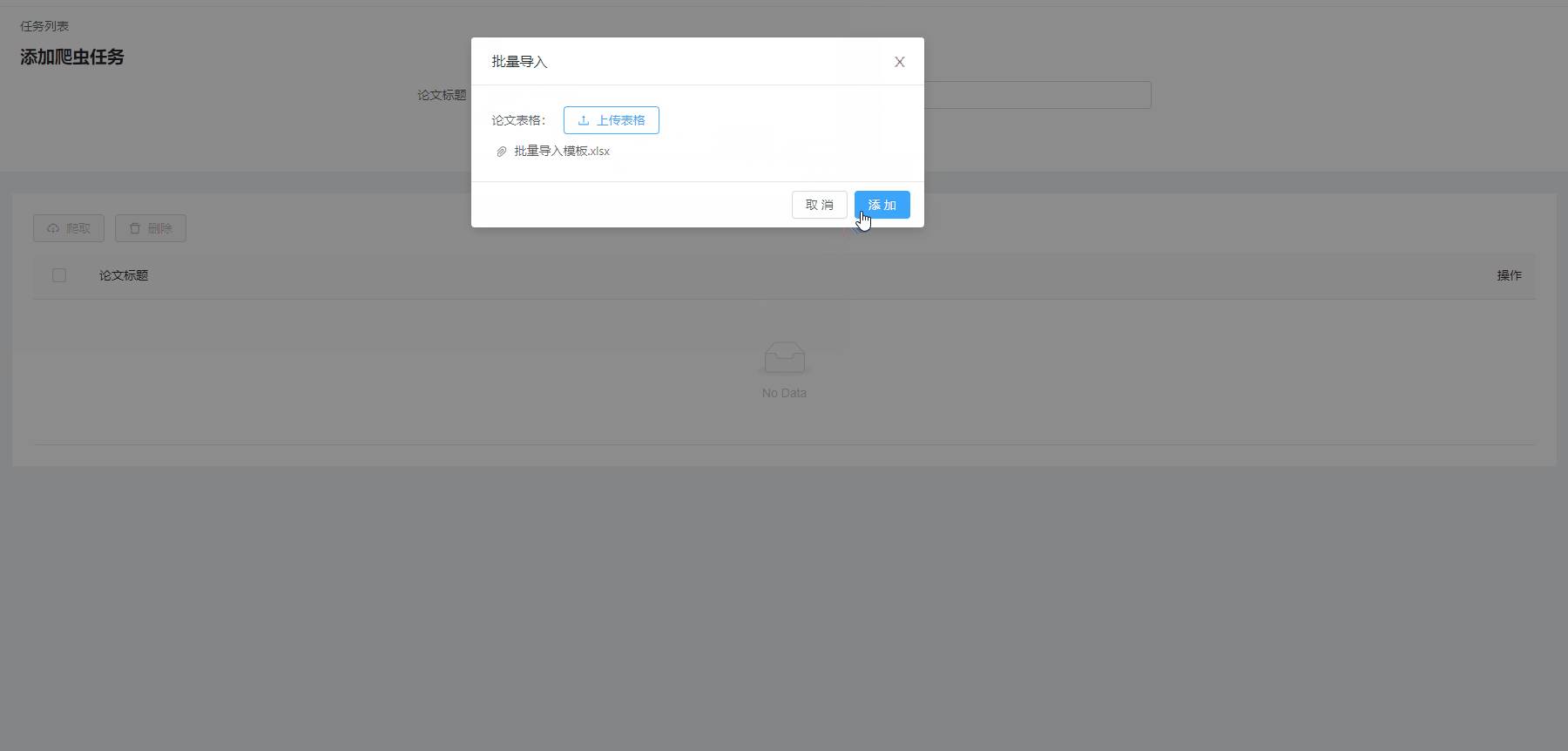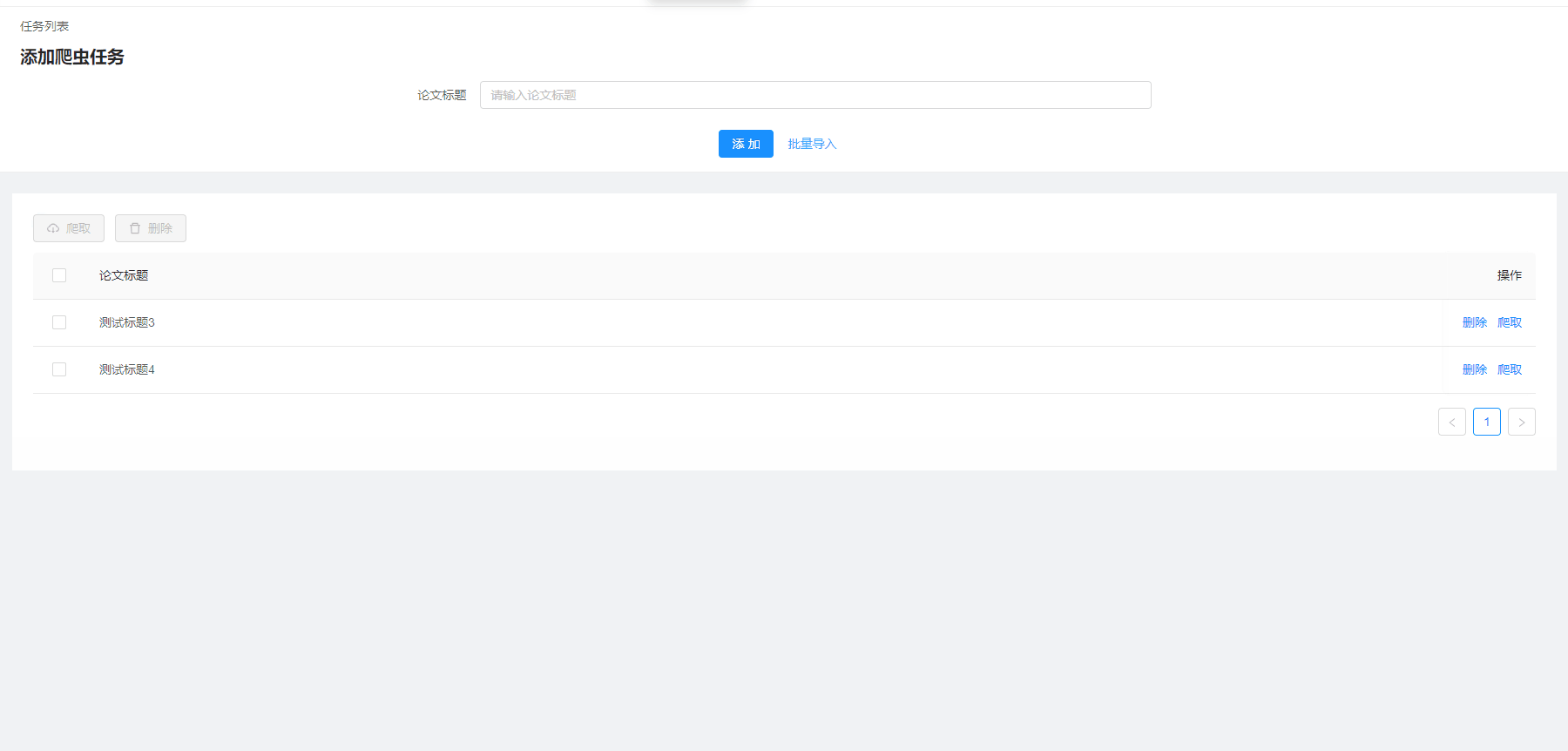
-
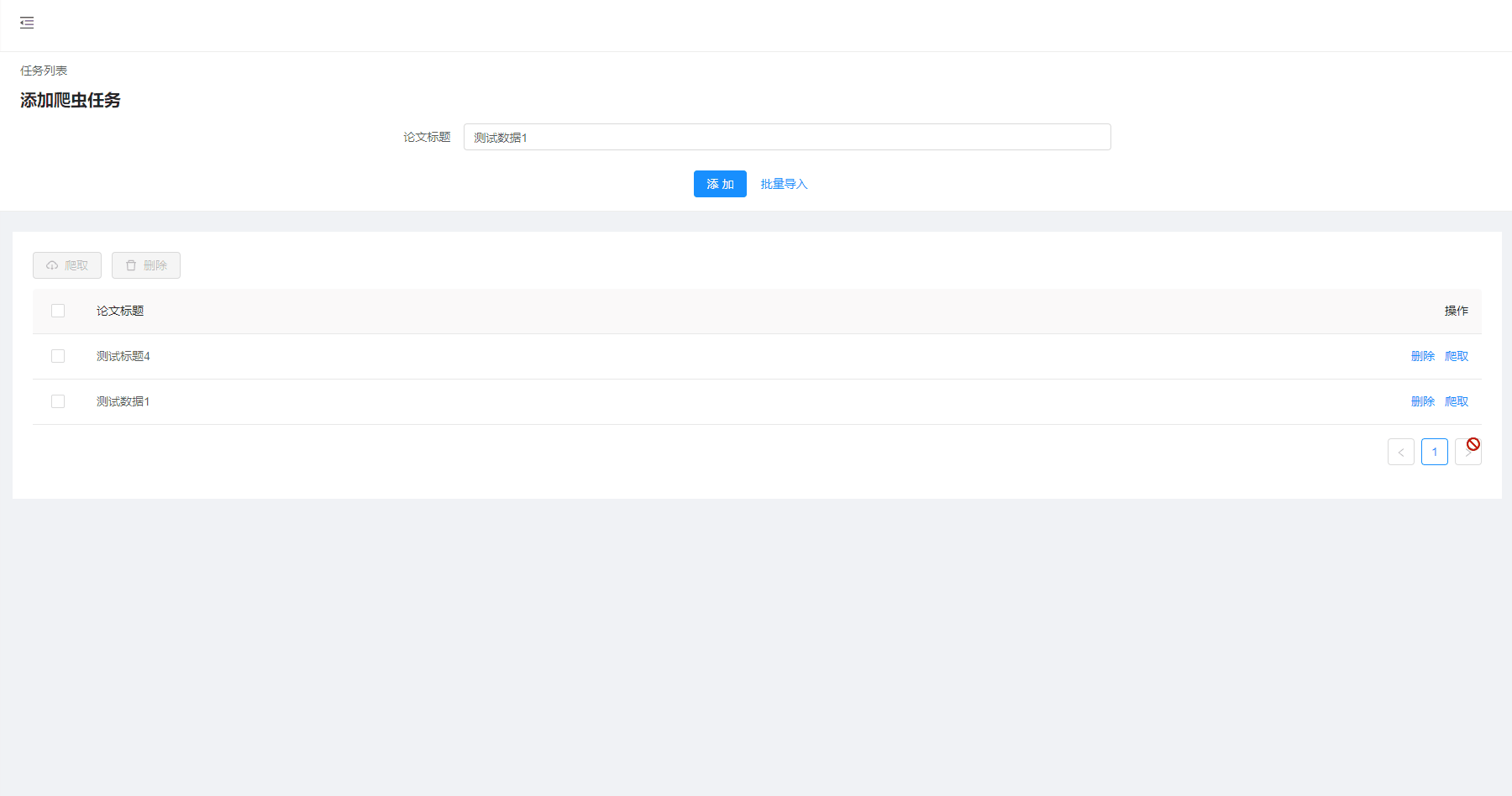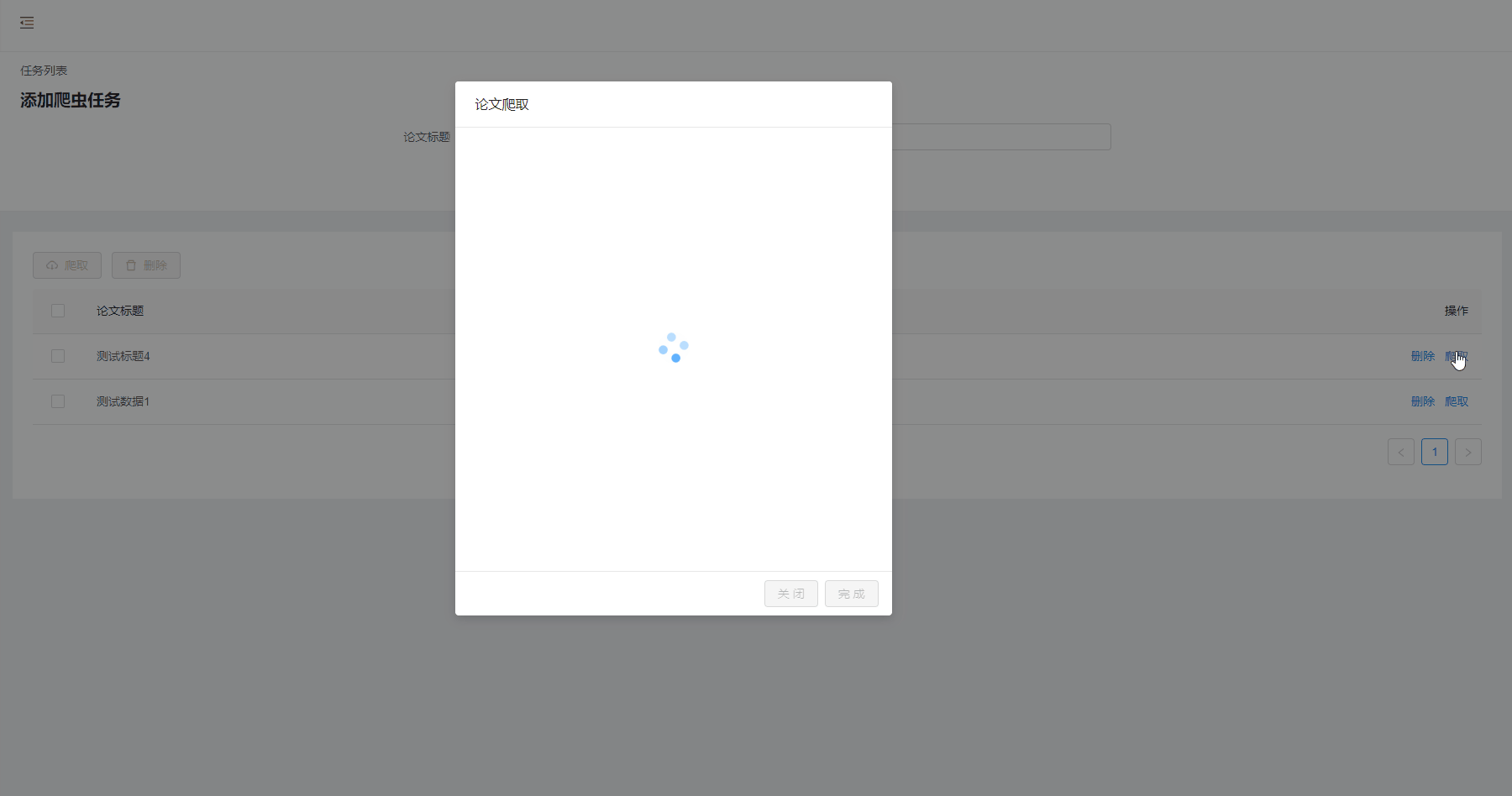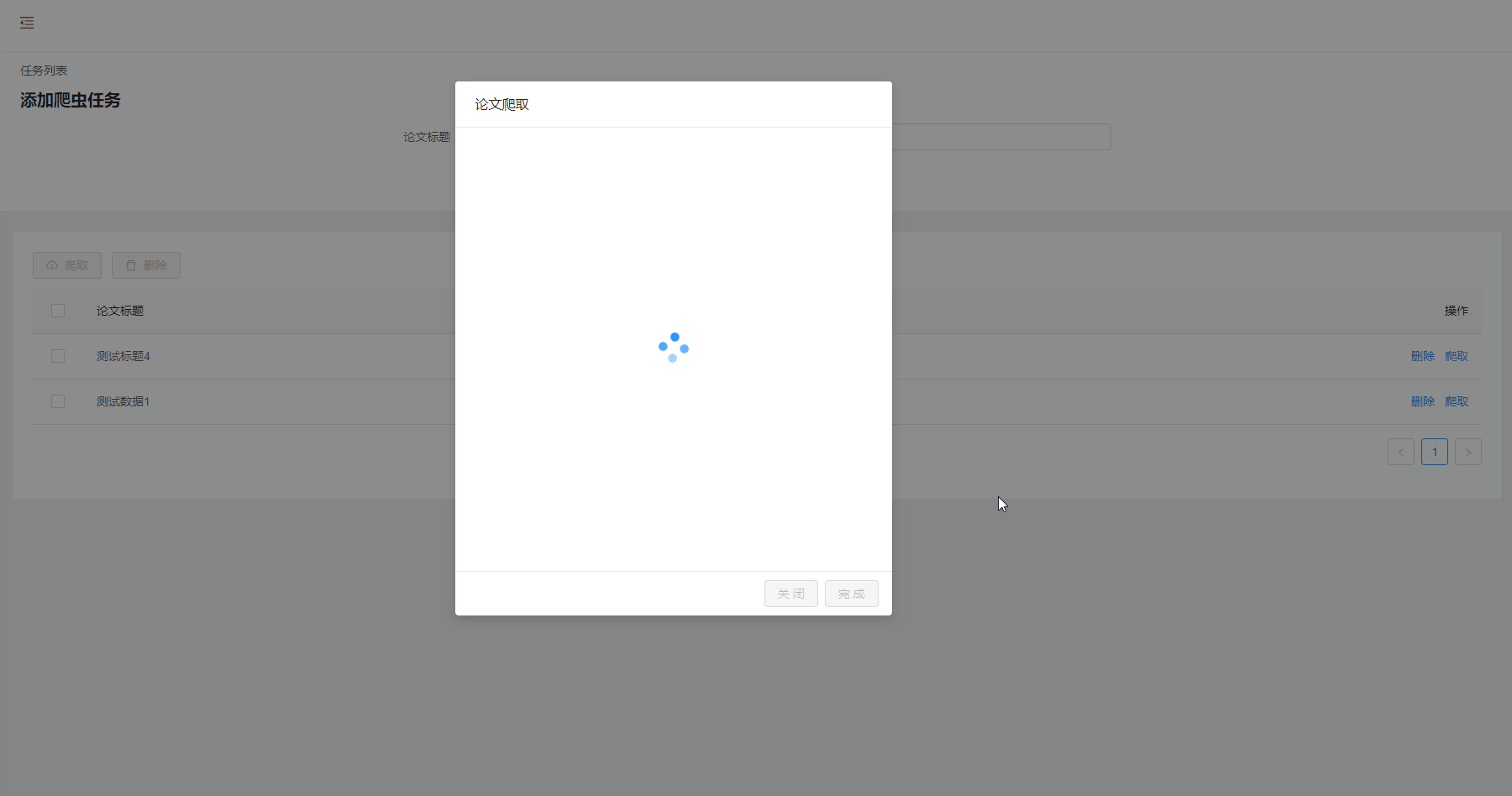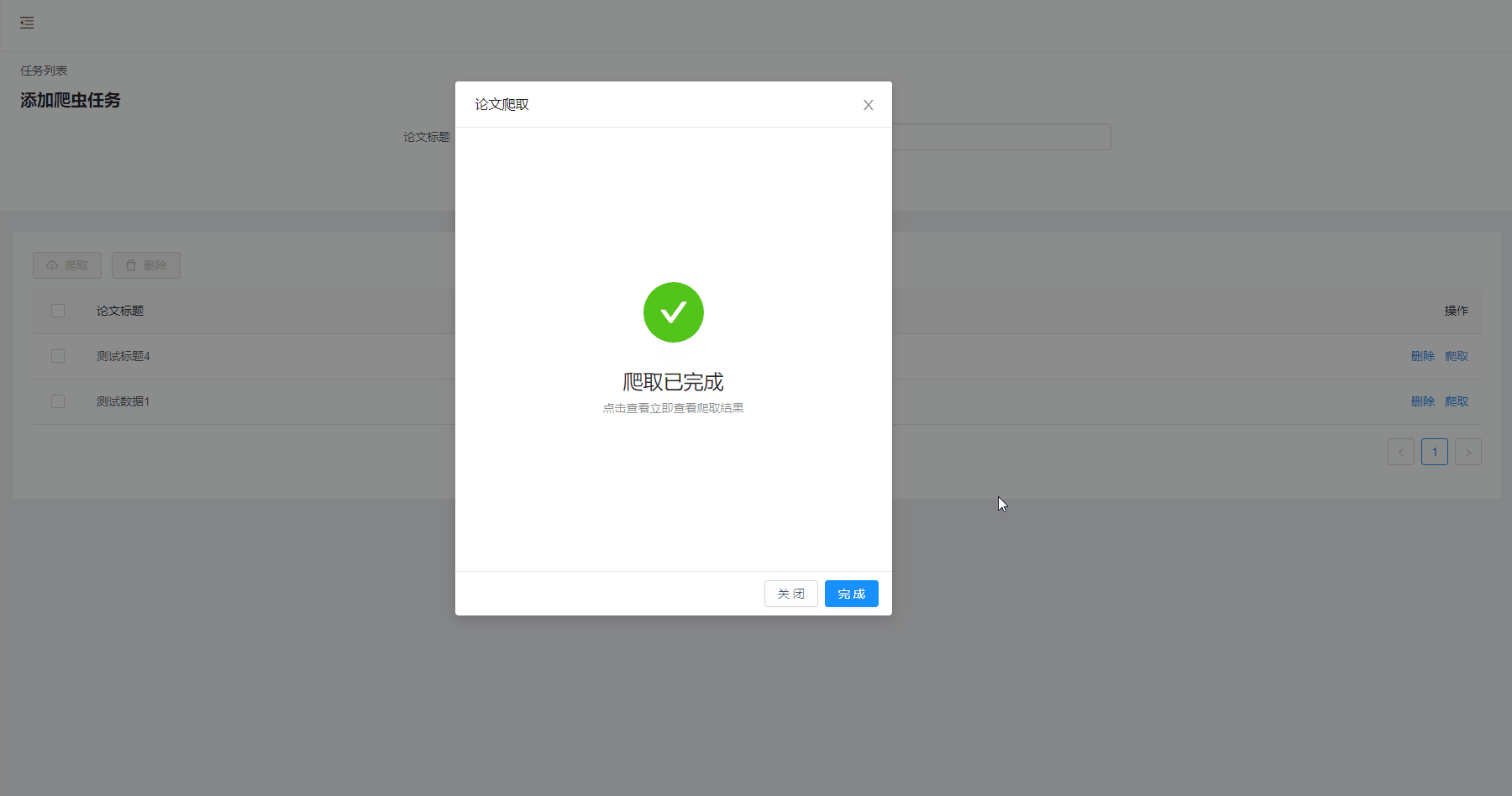
爬取结果
加载过程功能有剪辑
-
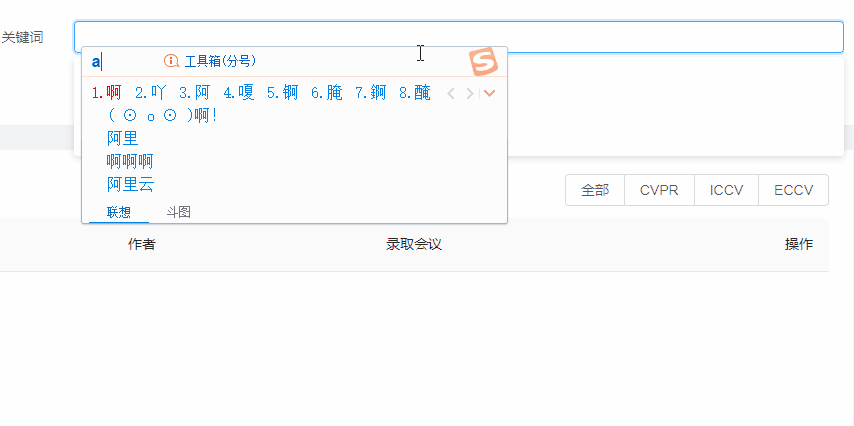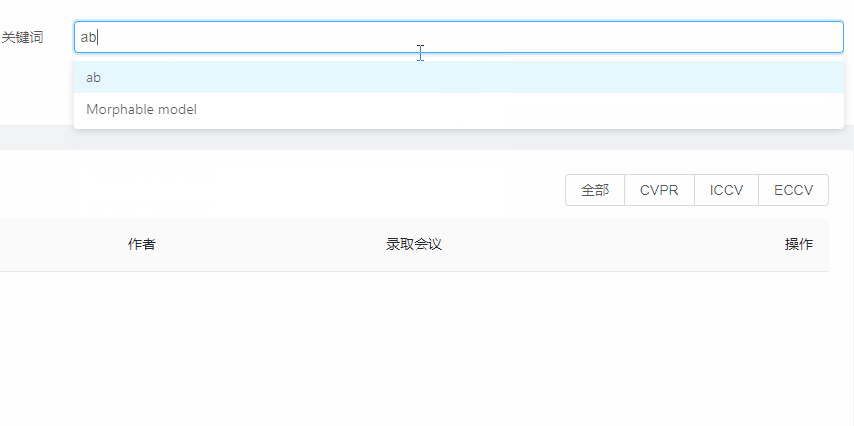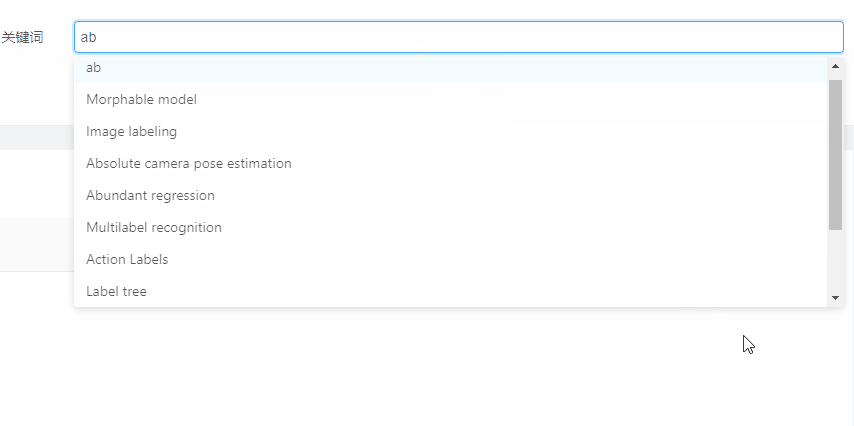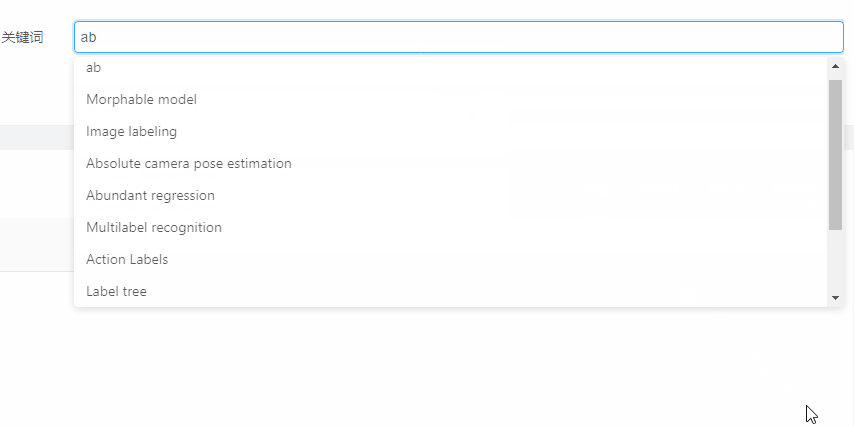
关键词提示
-
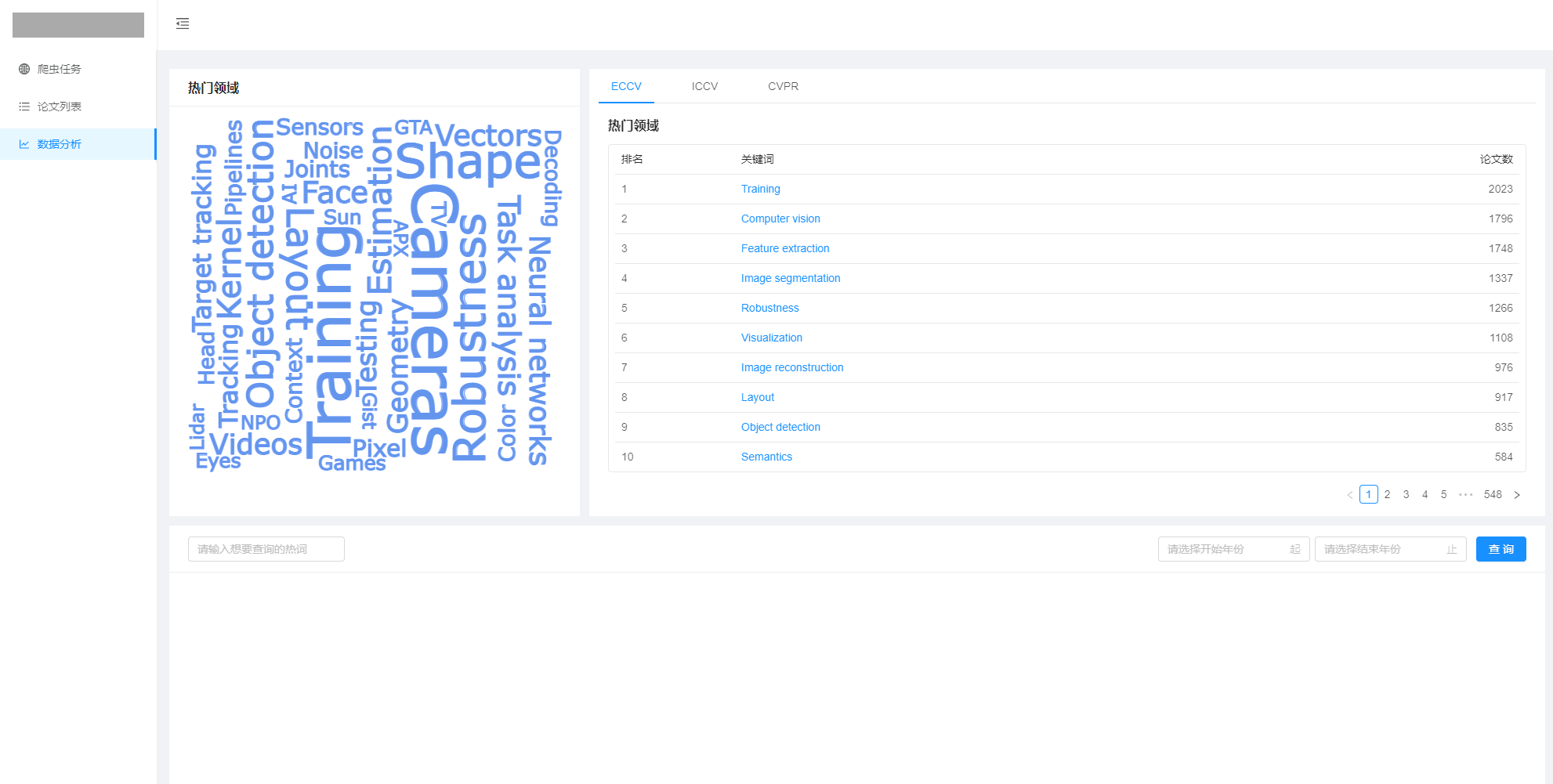
数据分析
-
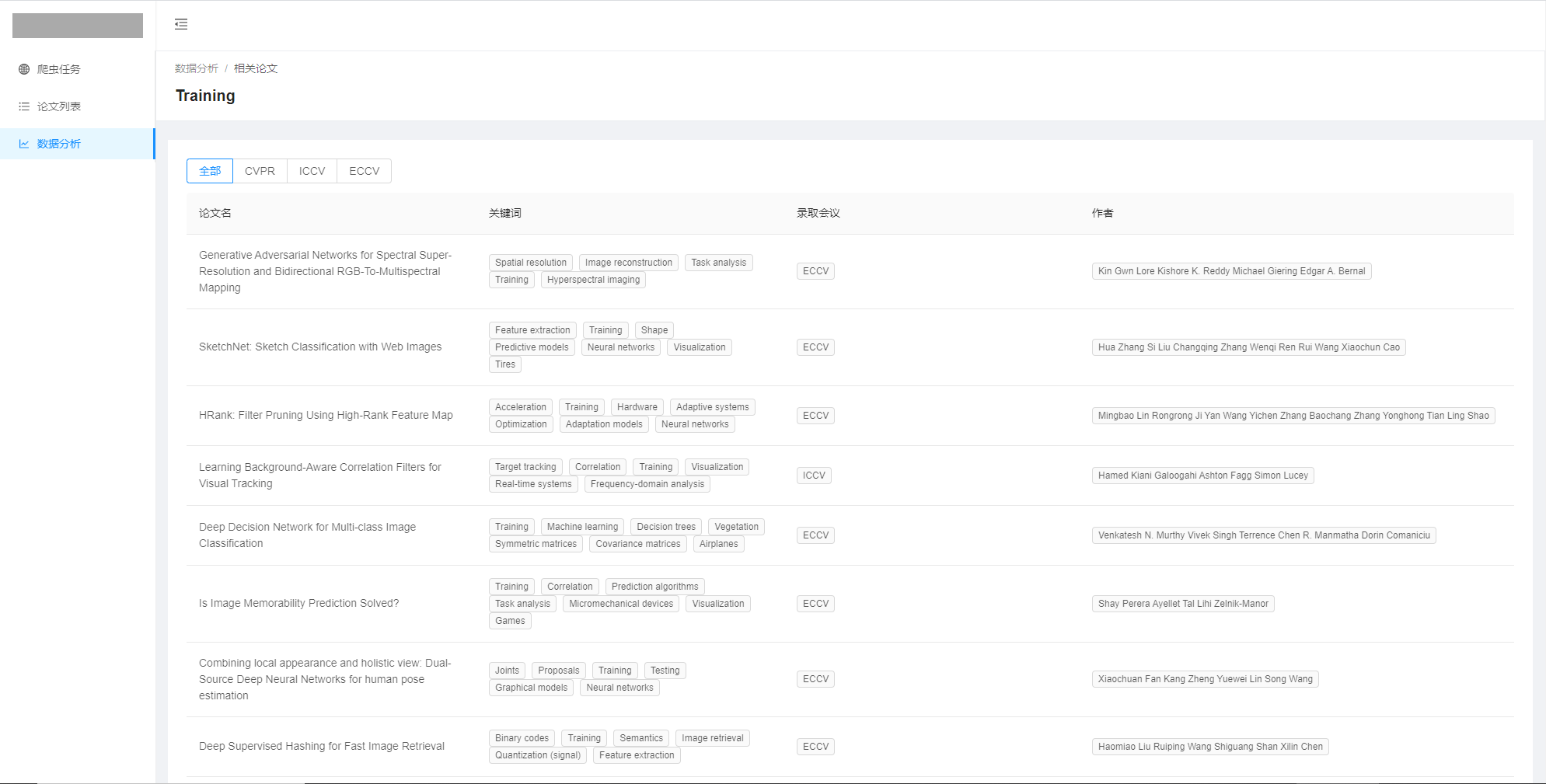
相关论文列表
-
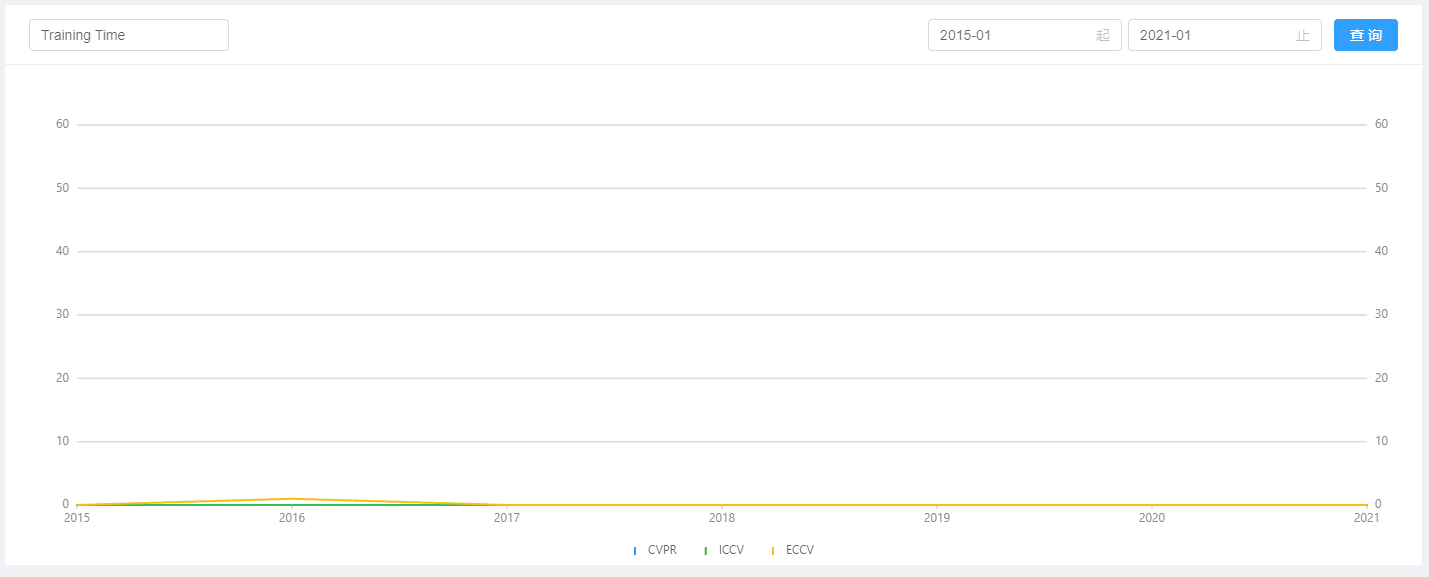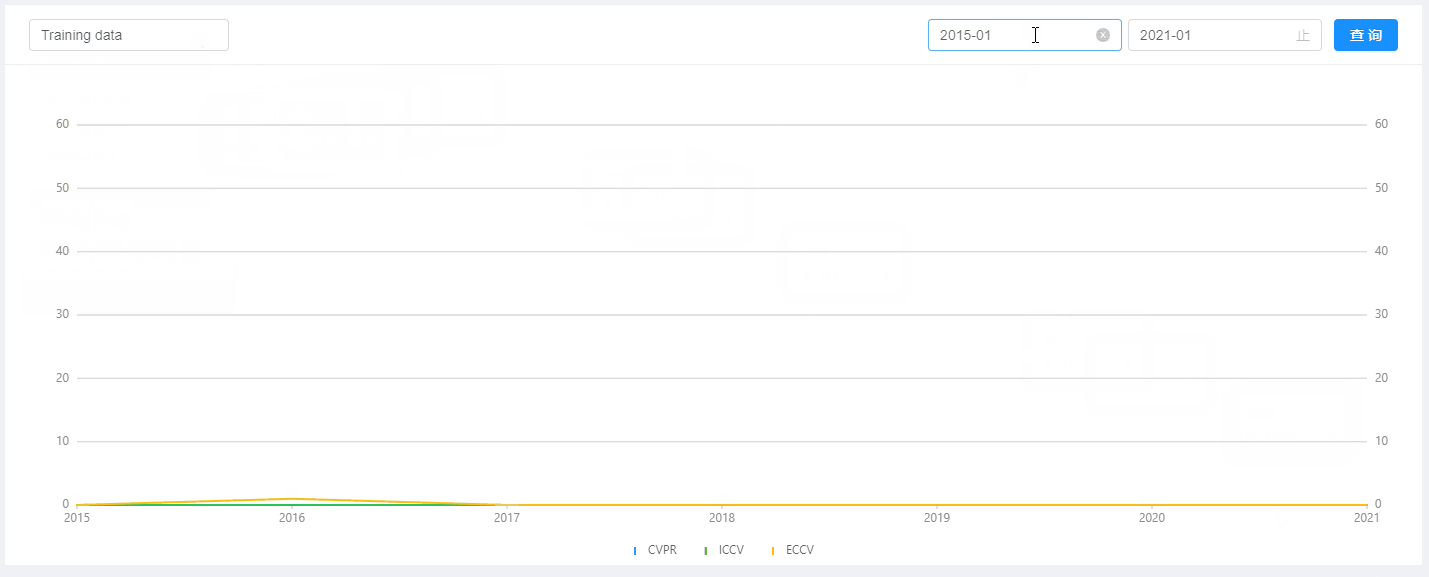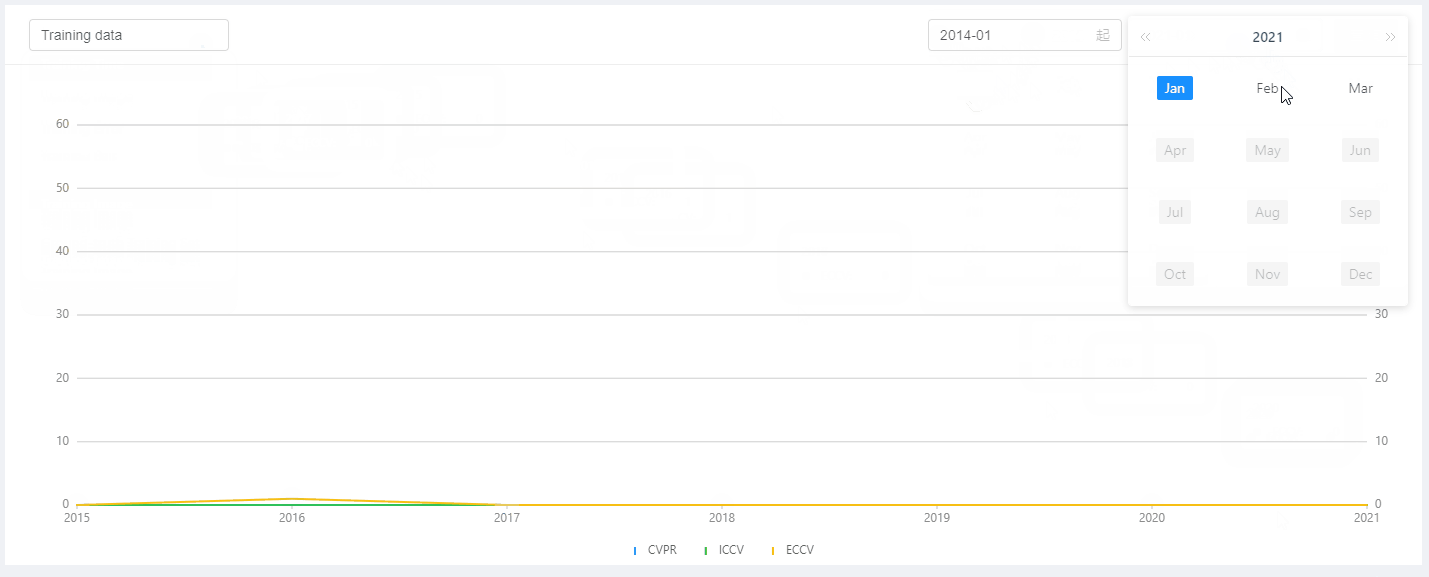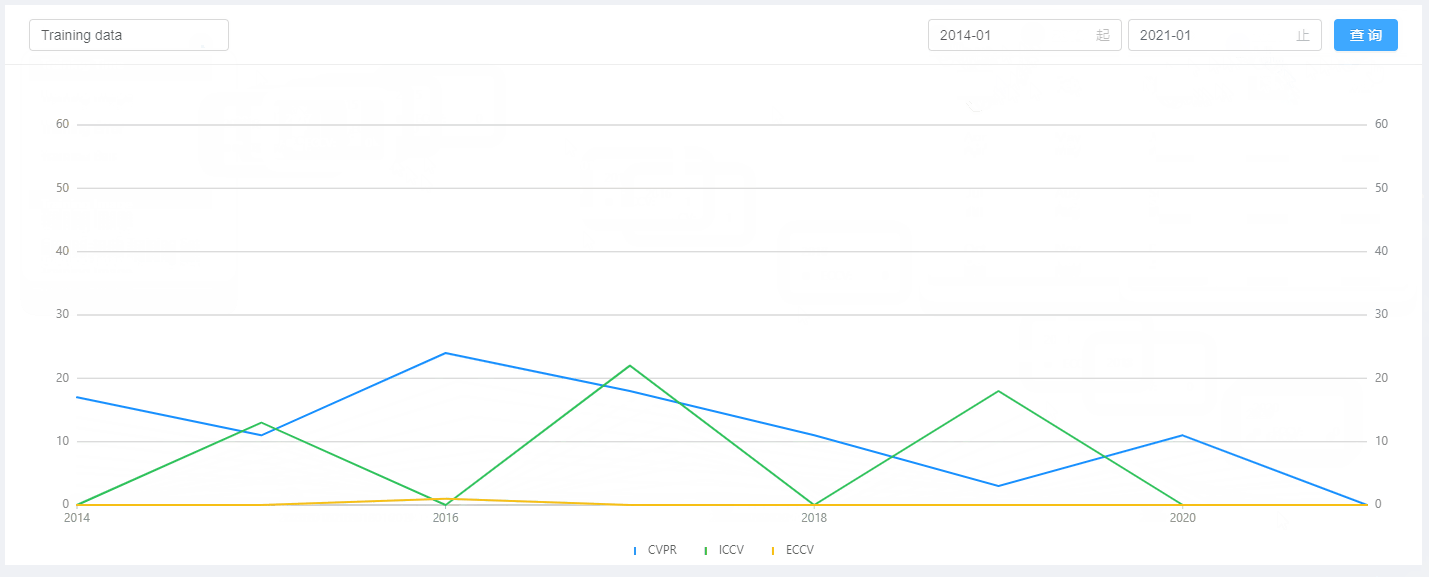
折线图数据检索
-
反馈提示

-
loading界面
结对讨论过程描述
由于需求功能有减少,先对整体功能做了一次梳理,最后决定把爬虫任务和论文列表区分开,使功能逻辑更简洁:
确定功能、页面逻辑后,协商API文档的格式等:
之后就是分前后端开发,前后端分别进行分离的调试后,进行接口对接:
过程中出现接口参数缺失等问题时,协商后更新接口文档;
设计实现过程
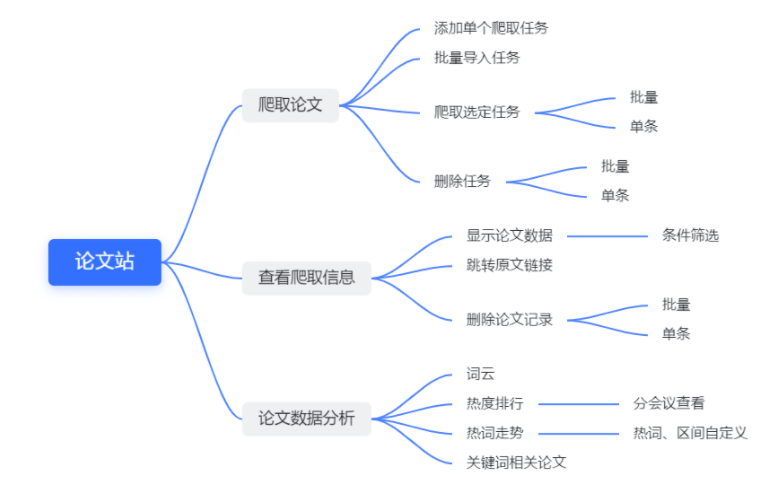
整体设计
划分了“任务”、“论文”两个模块,“任务”模块参考迅雷的任务模式,需要进行论文爬虫时,先添加爬虫标题生成任务,再执行任务进行爬虫;
“任务”执行完成后,添加结果到“论文”,论文记录对应一篇真实的论文,可以显示这条记录的相关参数并跳转查看原文;
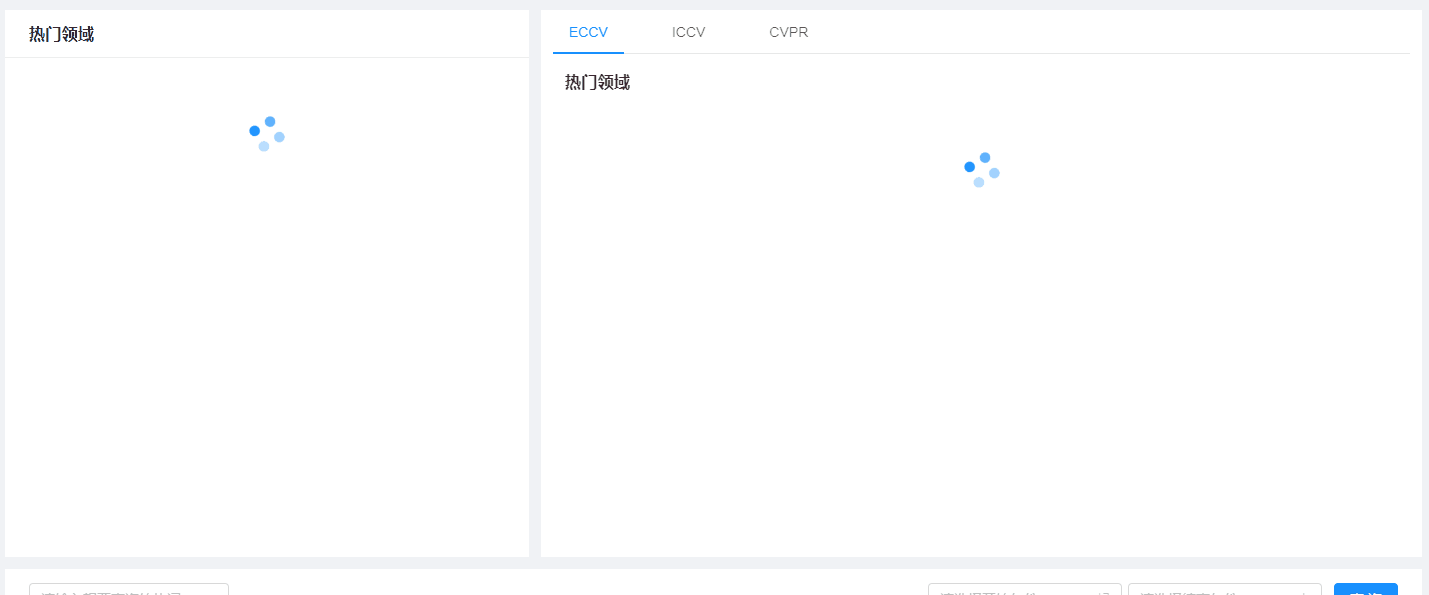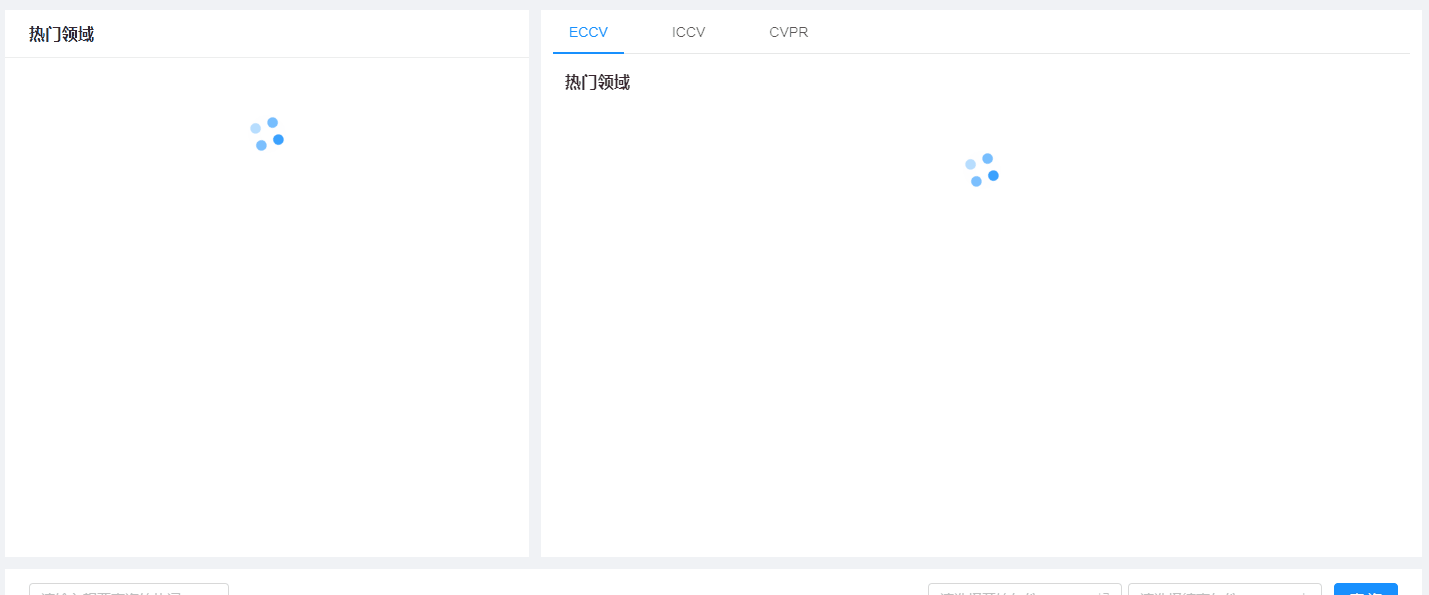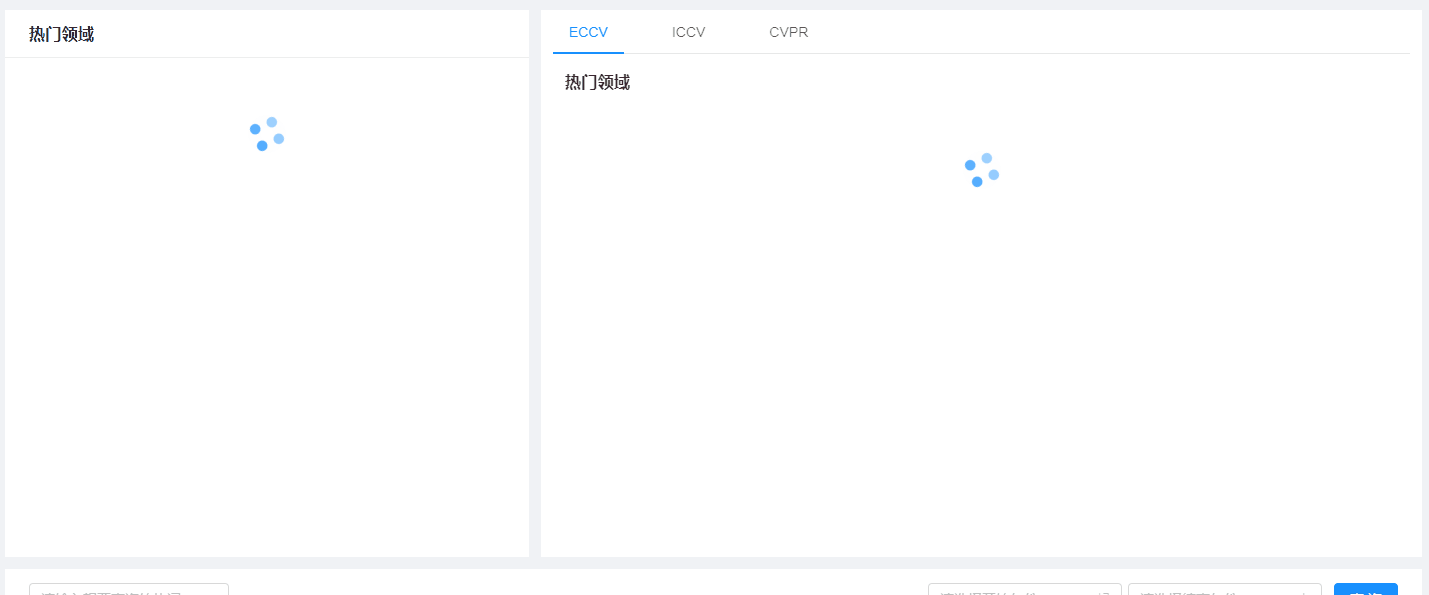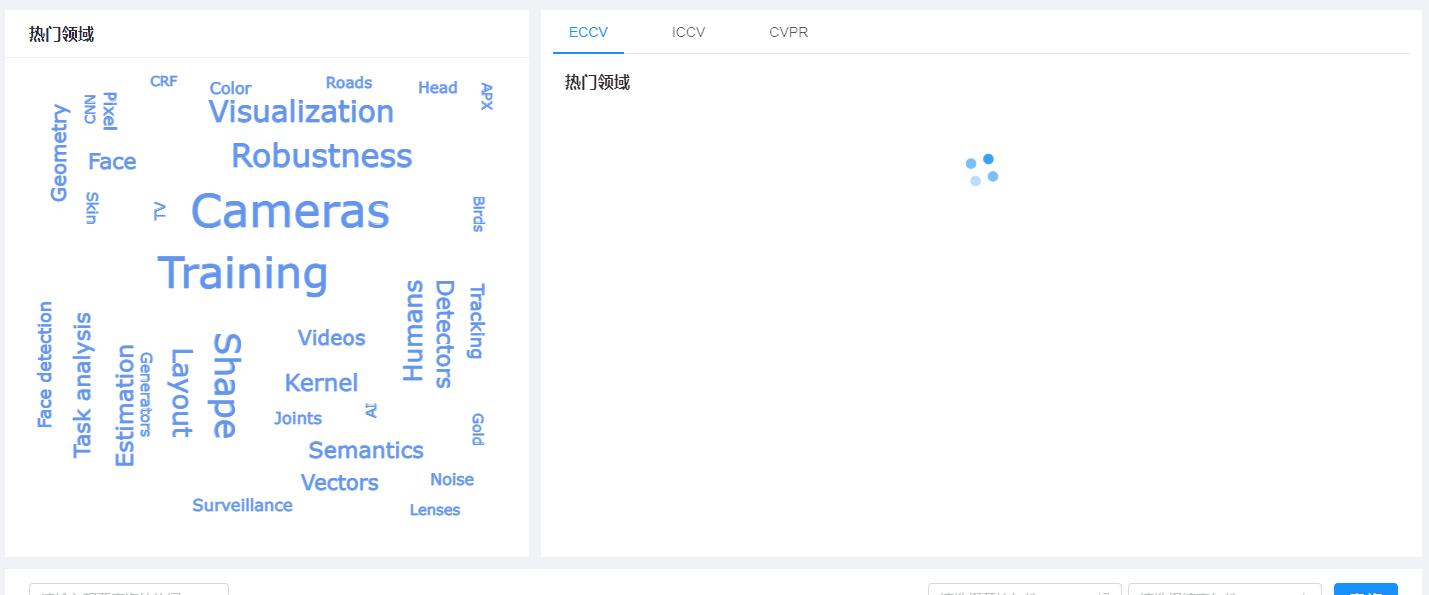
此外,还制作了数据分析页面,根据已爬取的数据进行分析,分析结果包括:
- 词云:根据关键词以及其频率生成,
- 排行:根据各个会议的热词热度进行排行,
- 折线图:根据输入条件(标题、起止日期)进行查询数据并进行对比展示;
使用设计
- 增加了输入补全功能:通常论文标题较长、复杂,增加输入补全功能(添加任务标题),允许用户选择提示的关键词/标题进行检索,折线图检索为了确保检索到数据,只允许用户选择已存在的关键词进行查询;
- 批量操作:任务部分通常较多,表格支持批量操作,可以多选删除/爬取,提高效率;
- 操作反馈:用户点击按钮、链接后都有操作反馈;
代码说明
前端
- 网络请求
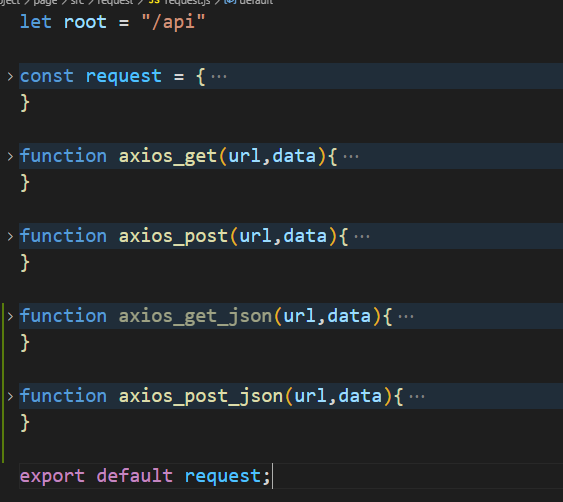
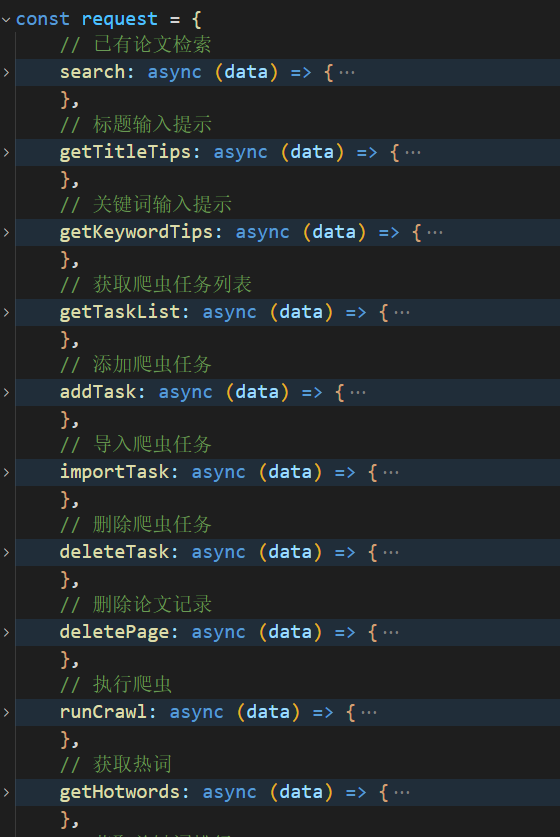
根据api接口书写对应的request模块,模块中封装各个请求接口的参数处理:
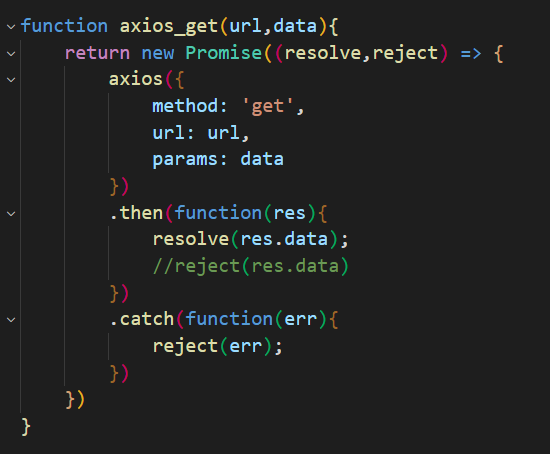
函数处理输入数据,执行get/post方法,再处理返回数据,方便前端开发,实现请求、主体分离
-
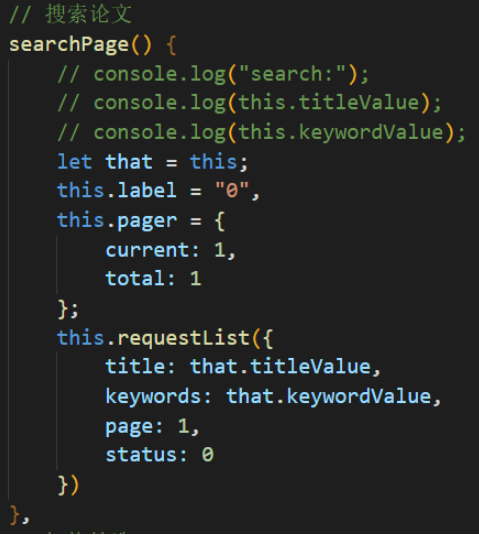
论文检索
输入信息点击检索后,执行searchPage方法,请求新的列表数据,最后更新到对应表格中
-
批量导入
点击批量导入按钮后,打开导入对话框,点击上传文件,进行文件上传:

之后点击添加按钮对上传的文件进行解析并发送请求:
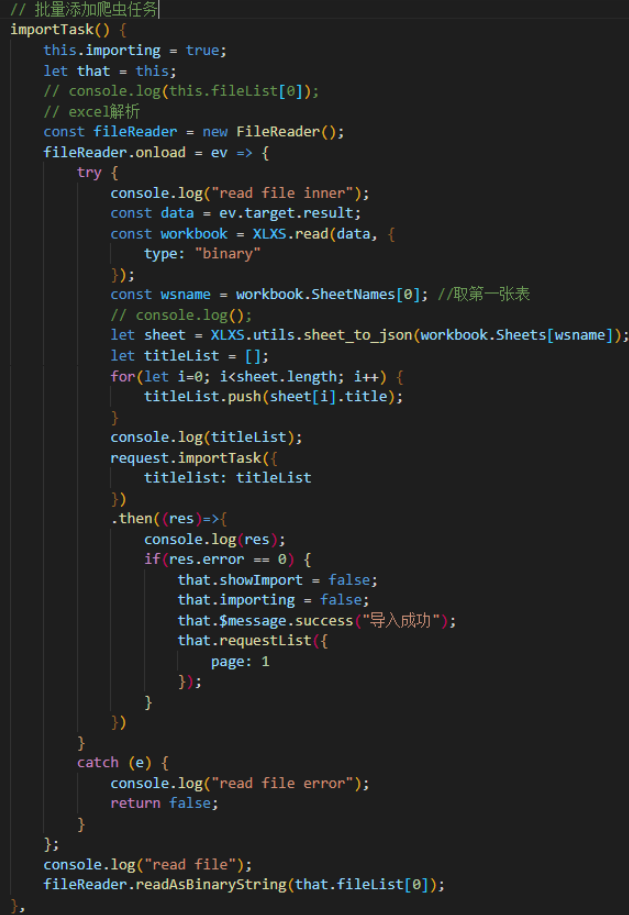
-
词云
词云部分封装为单独组件,使用g2-plot库进行展示,组件挂载后,使用库api进行渲染,添加点击事件以实现跳转
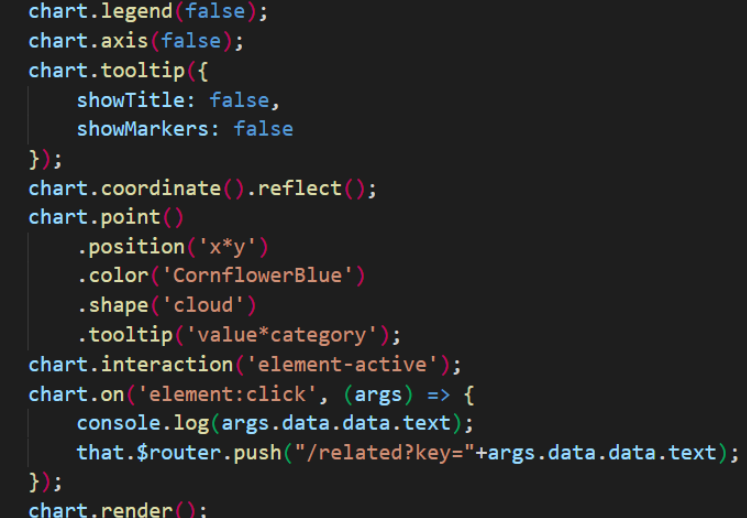
-
折线图
折线图封装为组件,分三条线渲染三个顶会的走势:
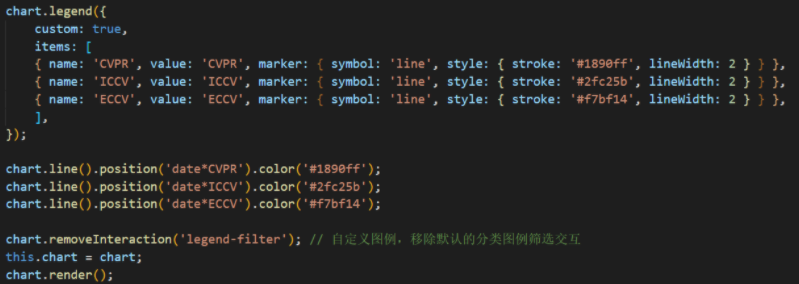
用户查询新的数据后触发update函数进行数据更新:
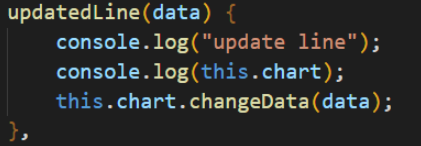
- 页面结构
页面主体分左侧aside和主体部分
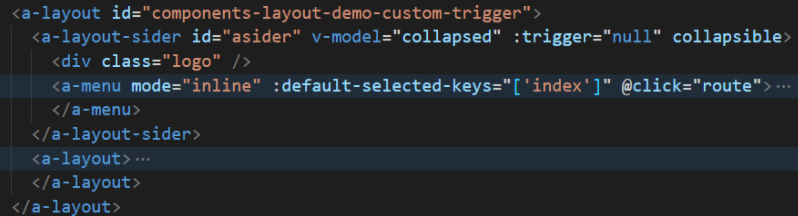
左侧主要为导航部分;
右侧主体部分使用router进行路由,可用页面如下:

页面切换后更新右侧主体内视图。
后端
- api接口编写
使用flask进行接口编写,分别由json和表单接收数据

- curd设计
pymysql进行数据库链接
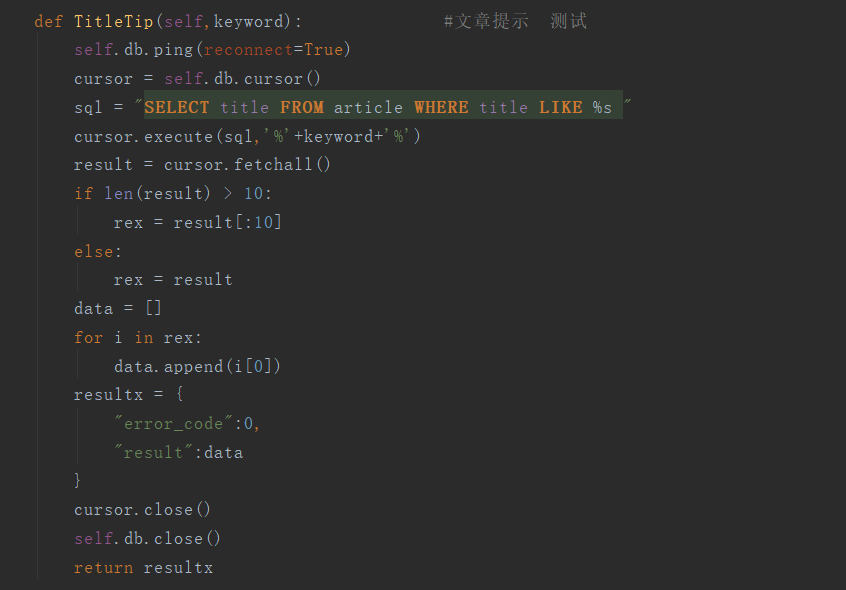
- 爬虫实现
post请求模拟进行爬虫

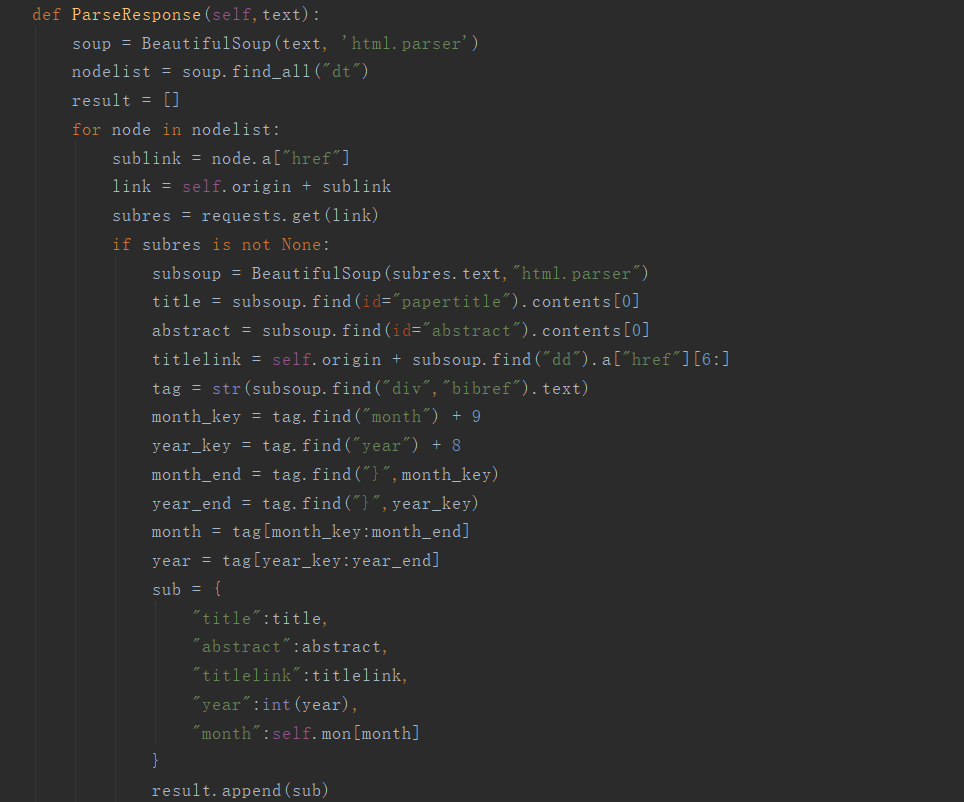
- 爬虫解析
Beautifulsoup解析html树
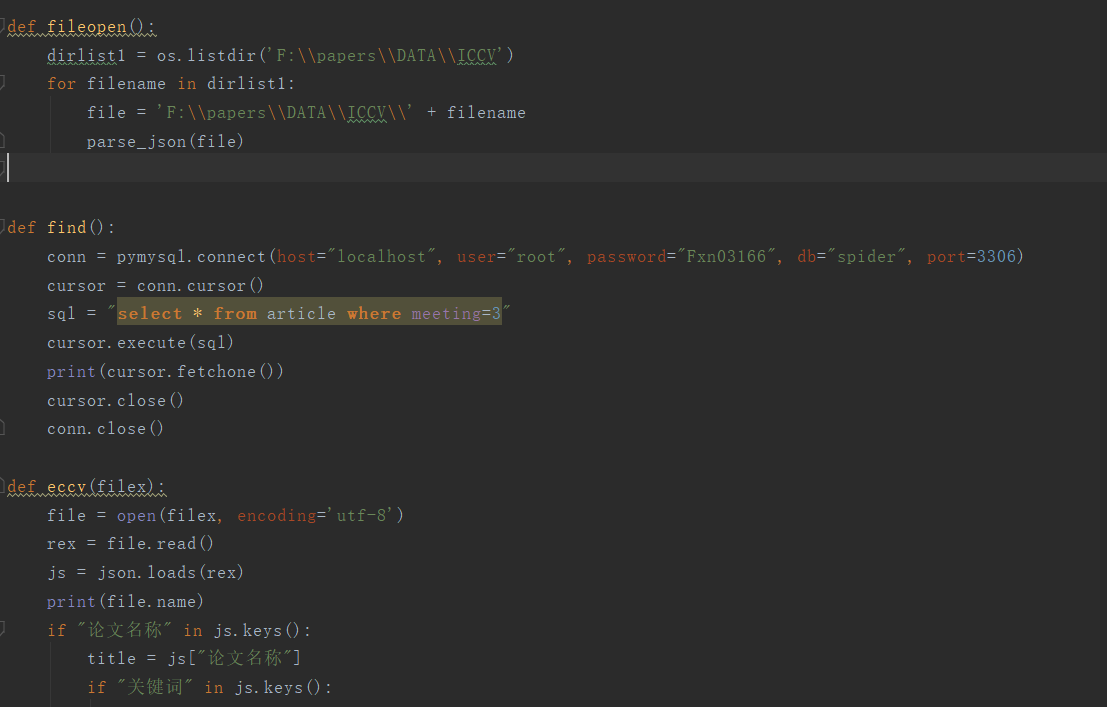
- 原始数据导入
解析json
心路历程和收获
郭晗宇
前期准备方面来说,由于删了需求,之前准备的原型有一些都用不上,然后论文的数据和原定的也有差异,导致原型大改,设计方面还是要尽量保证容错性,逻辑一定要清晰,宁可麻烦一点,也不要把逻辑整的太复杂;对接方面还是沟通少了,个人按着个人理解来,如果多一个专门的产品来负责说明会好很多;编码方面没有啥难度,就是多了点。

方燮楠
有点高估了爬虫网站的数据量吧,因为时间没规划好的原因,导致删了一些需求,主要是论文网站找的比较不合适,数据太少不适合做原始数据,前期写好的爬虫几乎等于无用功了,还有是对接方面沟通比较少,导致后期改需求比较频繁,编程方面还是蛮快的,跟hackathon对比轻松不少。
评价结对队友
221801311郭晗宇 to 221801313方燮楠
fxn同学挺不容易的,顶着病写代码,但是也挺菜的,BUG一堆,太遗憾了。要是能更多的沟通应该能减少调试需要的时间。
221801313方燮楠 to 221801311郭晗宇
ghy同学挺不适合干产品的,问题逻辑不清晰,想当然太多了,太遗憾了。要是能少摸点鱼说不定不用加急改BUG了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号