寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践W班 |
|---|---|
| 这个作业要求在哪里 | 寒假作业1/2 |
| 这个作业的目标 | 学习构建之法、了解git/github使用、项目编写流程熟悉、单元测试实践 |
| 作业正文 | 博客链接 |
| 其他参考文献 | 无 |
part1:阅读《构建之法》并提问
- 书中介绍了单元测试是“在最基本的功能/参数上验证程序的正确性”,由此,可以得到单元测试不仅需要覆盖的功能多,需要的数据量也要有保证,网上能查到很多单元测试的原则等,能否根据这些原则,结合编程人员的经验,做出单元测试的自动化工具?
- 书中介绍敏捷开发的一种方法,其中提到“每日立会”,但我们也能在网上看到很多关于站会的抱怨,比如“浪费时间”等,作为开发人员,到底如何看待敏捷的流程?项目组长又该如何平衡流程与效率?
- 在讲义中看到了关于“小作坊”的讨论,在我看来,小作坊式的开发固然是能激起很多的创意、想法,但是不可否认,我们现在使用的大型软件,很难依靠小作坊式的开发,在我看来,更合理的模式应该是核心创意团队+大型支持团队的模式,核心团队模式类似小作坊,大型团队为整个项目提供各方面的支持,不懂我的想法对不对?
- 在讲义中看到关于“手势控制电脑”的内容,然后给出用什么控制电脑的问题,让我联想到TNT设备,系统主推语音控制,但是结合阅读,我认为这种控制方式并不实用,尤其是对于长时间的使用,说话也是很累的。但是如果是短时的使用,在不打扰别人的情况下,这也不失为一种提升效率的方法。由此,目标用户的使用习惯是一个需要各个方向综合判断的调查,并不能简单的用读者的日常/读者认为的日常来判断,不懂我的想法对不对?
- 书中强调了用户体验的重要性,但是在实际项目中,可能因为体验优化而影响商业化,网上有介绍一些商业化和用户体验平衡的例子,和原则,能不能做一些标准的类型方案出来呢?
part2:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| ·Estimate | 估计这个任务需要多少时间 | 30 | 45 |
| Development | 开发 | 1680 | 1640 |
| ·Analysis | 需求分析 (包括学习新技术) | 120 | 150 |
| ·Design Spec | 生成设计文档 | 60 | 60 |
| ·Design Review | 设计复审 | 30 | 10 |
| ·Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| ·Design | 具体设计 | 60 | 60 |
| ·Coding | 具体编码 | 960 | 900 |
| ·Code Review | 代码复审 | 120 | 60 |
| ·Test | 测试(自我测试,修改代码,提交修改) | 300 | 360 |
| Reporting | 报告 | 330 | 360 |
| ·Test Repor | 测试报告 | 180 | 240 |
| ·Size Measurement | 计算工作量 | 30 | 60 |
| ·Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 60 |
| 合计 | 2040 | 2045 |
解题思路描述
首先,整个程序的要求很清晰的写出来了,所以就根据需求部分的四个需求作为基础;经过阅读,整理出比较大的功能模块还有文件的读写;注意到需求中的关键字有命令行、单元测试,那这两点需要进行学习;根据最近的学习规划,选择开发语言使用node.js;根据上述需求/关键字,搜索教程学习。
代码规范制定链接
设计与实现过程
这个项目整体很简单,根据需求可以很容易先得出四个重要函数:统计输入字符数、统计输入单词总数、统计输入有效行数、统计单词出现次数,接下来,根据需求中的文件输入输出,得到两个需要写的函数:文件读取、文件写入,如上总共6个需要书写的函数。使用js中的模块概念,将以上六个函数写入模块中,为主程序提供接口。主程序处理流程如下:
命令行输入 => 读取文件(file to string) => 统计输入字符数、统计输入单词总数、统计输入有效行数、统计单词出现次数 => 写入文件 => 程序结束
接下来介绍实现主要功能的四个函数的实现:
- 统计输入字符数
js中的string如果按位读取,会把\n拆分开读取为\``n,处理起来很麻烦,在尝试过后,使用string.split(""),将输入字符串拆分为单字符构成的数组,统计数组长度即为字符数。
let charArrat = data.split("");
return charArrat.length;
- 统计输入单词总数
统计单词首先需要找出所有单词,首先根据给定的分隔符拆分出单词,分割符为空格,非字母数字符号,可以使用使/[^A-Za-z0-9]/这一正则来表示,用string.split(reg)来根据正则把可能为单词的部分拆分出来;接下来是验证单词,遍历数组,使用^[a-zA-Z]{4}规则来验证每一项是否为单词,如果不是,使用splice函数将其从数组中移出,最后返回数组长度即为单词总数。
let words = data.split(/[^A-Za-z0-9]/);
for(let i=0; i<words.length; i++) {
if(words[i].length < 4) {
words.splice(i, 1);
i--;
}
const reg = new RegExp("^[a-zA-Z]{4}");
if(!reg.test(words[i])) {
words.splice(i, 1);
i--;
}
}
return words.length;
- 统计输入有效行数
根据有效行使用\n换行的定义,将输入字符串使用\n拆分,之后遍历拆分出的数组,检查每一项是否为空行。最后返回数组长度即为有效行数。
let lines = data.split("\n");
for(let i=0; i<lines.length; i++) {
const emptylineReg = new RegExp("^[ \s\r\n\t]*$");
if(lines[i] == "" || emptylineReg.test(lines[i])) {
lines.splice(i, 1);
i--;
}
}
return lines.length;
- 统计单词出现次数
首先根据统计单词总数的经验,拆分出单词数组(未校验格式);维护一个map,遍历数组检查格式符合后,将其转为小写,再检查map中当前单词是否存在,不存在则将当前单词为key,1为value加入map,否则更新单词对应value+1;
let words = data.split(/[^A-Za-z0-9]/);
let wordsMap = new Map();
for(let i=0; i<words.length; i++) {
if(words[i].length < 4) {
words.splice(i, 1);
i--;
}
else {
const reg = new RegExp("^[a-zA-Z]{4}");
if(!reg.test(words[i])) {
words.splice(i, 1);
i--;
}
else{
words[i] = words[i].toLowerCase();
if(wordsMap.has(words[i])) {
wordsMap.set(words[i], wordsMap.get(words[i])+1);
}
else {
wordsMap.set(words[i], 1);
}
}
}
}
之后将map转为数组,使用sort函数自定义比较函数,排序数组,最后返回数组前十项内容(不足十项则返回全部);返回格式为数组,其中每一项是一个对象:
{
words: 单词,
frequency: 频数
}
除以上四个函数外,还有文件系统的读写,使用node.js自带的fs库来实现,使用process.argv获取到命令行的输入参数后,将输入参数作为URL传给文件读写函数,读函数返回读取到的内容,写函数返回写入结果。
性能改进
使用模拟生成的100000个英文单词做性能测试,测试数据格式如下:rxz borxn ruptuvr zglsms ygto ojxpn pylcoev opnaicrqmk iyxqbm gyshqou dvncbelx pmz hoqtkntjja zgljtw
程序运行总耗时3.84s,以下是运行概况以及对应的统计图表:
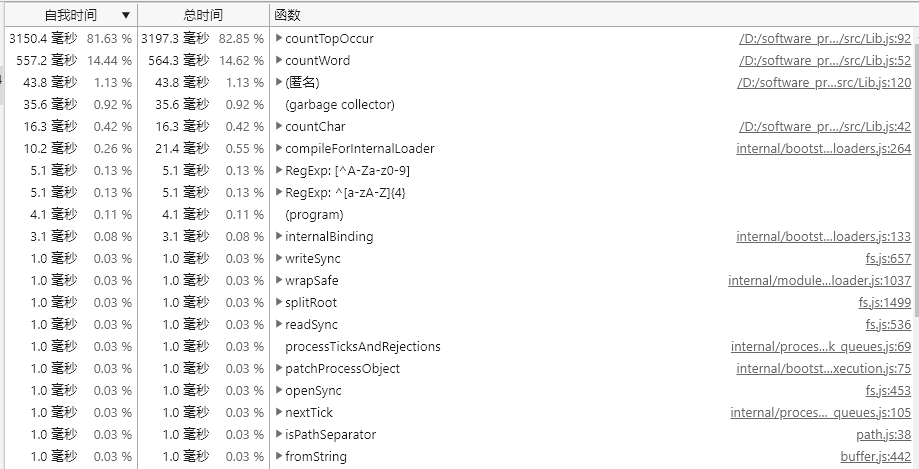

可以看到几个耗时较多的函数,包括countTopOccur统计出现次数的函数、countWord统计单词数量的函数、countChar统计字符数量的函数、以及两个用于验证格式的RegExp正则表达式;
目前针对以上函数,进行的改进包括:在循环遍历统计时,遇到空/长度不足字符直接跳过,减少正则验证的次数;使用set而不是array存储频率表;
可能的改进还有:不使用正则,优化验证规则对单词进行验证;
单元测试
根据上述,单元测试的重点在于四个对字符串进行统计的函数,测试数据主要关注的细节包括:大小写、字符顺序、格式定义、空字符串、特殊字符。以下针对四个函数各提供一个测试范例:
describe('字符统计函数测试', function() {
it('空格与换行', function() {
expect(lib.countChar(" \n \n \r\n ")).to.be.equal(8);
});
});
describe('行数统计函数测试', function() {
it('换行测试', function() {
expect(lib.countValidLine("\r\r\r\r")).to.be.equal(1);
});
});
describe('单词总数统计函数测试', function() {
it('空内容', function() {
expect(lib.countWord("a a a a a")).to.be.equal(0);
});
});
describe('单词频率统计函数测试', function() {
it('单个大小写', function() {
expect(lib.countTopOccur("four Four FOUR FOUr")).to.deep.include({
words: "four",
frequency: 4
});
});
})
测试结果如下:
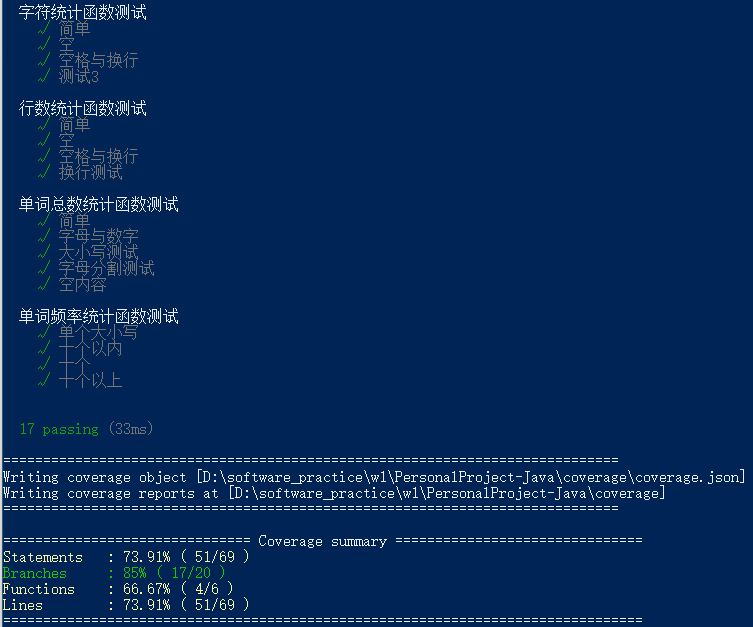
Statements : 73.91% ( 51/69 )
Branches : 85% ( 17/20 )
Functions : 66.67% ( 4/6 )
Lines : 73.91% ( 51/69 )
测试仅针对主体四个统计函数进行测试,剩余文件读写部分没有进行单元测试。
对于分支覆盖率的优化,需要考虑各种if分支的情况设计测试用例,优化行/语句覆盖率,则需要尽可能的把主体代码设计成可以进行测试的函数。
异常处理说明
本次时间的代码异常主要集中在文件读写、命令行参数部分
- 当文件找不到或文件系统读取出错时,程序将返回
fiel system error并附带错误信息 - 当命令行参数不完整时,会返回
missing parameter并结束程序
心路历程与收获
项目过程还算顺利,本来以为统计功能会比较难实现,但是正好刷题遇到了类似的题目,所以很快的解决了;之前没做过的是单元测试部分,这次实践了单元测试;最后对项目过程的总结很重要,项目需要及时复盘能发现之前的很多问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号