K8s的工作原理
K8s概述
我清晰地记得曾经读到过的一篇博文,上面是这样写的,
“云端教父AWS云端架构策略副总裁Adrian Cockcroft曾指出,两者虽然都是运用容器技术,但最大的差异是,Docker是要解决应用程序开发(Developing)问题,而Kubernetes是要解决更上层的应用程序运维问题(Operation)。开发问题是早期的痛点,但随着企业越来越依赖容器技术,内部应用越来越多是云原生应用时,运维会是企业IT的新痛点。”大佬的一番话,明确地指出K8S的生存土壤!
学习一项技术,除了需要明确这项技术的应用场景和发展方向之外,最主要的是理解她的工作原理。
K8s的工作原理
1. 什么是K8s
Kubernetes(k8s)是跨主机集群的自动部署、扩展以及运行应用程序容器的开源平台,这些操作包括部署,调度和节点集群间扩展。大二下学期我曽用过Docker容器技术部署容器,经历过compose的变种,对于应用版本之间的兼容性问题深恶痛绝。我们可以将Docker看成Kubernetes内部使用的低级别组件。Kubernetes不仅仅支持Docker,还支持Rocket(没有接触过),这是另一种容器技术。
wikipedia给出的定义:K8s是用于自动部署、扩展和管理容器化(containerized)应用程序的开源系统。Google设计并捐赠给Cloud Native Computing Foundation(今属Linux基金会)来使用的。它支持一系列容器工具, 包括Docker等。CNCF于2017年宣布首批Kubernetes认证服务提供商(KCSPs),包含IBM、华为、MIRANTIS、inwinSTACK迎栈科技等[5]服务商。
在《Kubernetes权威指南(第二版)》中给出的定义:她是一个全新的基于容器技术的分布式架构领先方案,她提供了强大的自动化机制,系统后期的运维难度和运维成本大幅度降低。她是Google的大闺女Borg的开源版本。使用K8s提供的解决方案,可以节省大概30%的开发成本,可以将精力更加集中于业务本身。
2. 用法
使用Kubernetes可以:
- 自动化容器的部署和复制
- 随时扩展或收缩容器规模
- 将容器组织成组,并且提供容器间的负载均衡
- 很容易地升级应用程序容器的新版本
- 提供容器弹性,如果容器失效就替换它,等等...
3. 核心概念
1) 集群
在集群管理方面,K8s将集群中的机器划分为一个Master节点和一群工作节点Node。Master节点上运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kube-scheduler。这些进程自动化实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能。

上图可以看到如下组件,使用特别的图标表示Service和Label:
- Kubernetes Master(Kubernetes主节点)
- Node(节点)
- Pod
- Container(容器)
- Label(label)(标签)
- Replication Controller(复制控制器)
- Service(enter image description here)(服务)
2) Kubernetes Master
Master指的是集群控制节点。每个K8s集群里需要有一个Ms节点负责整个集群的管理和控制。Kubernetes Master提供集群的独特视角,并且拥有一系列组件。
- Kubernetes API Server(kube-apiserver),侍卫大统领!提供HTTP Rest接口的关键服务进程,是K8s里所有资源的增删改查等操作的唯一入口,也是集群控制的入口进程。API Server提供可以用来和集群交互的Rest端点。
- Kubernetes Controller Master(kube-controller-manager)掌印大太监,大总管!K8s里所有资源对象的自动化控制中心。
- Kubernetes Scheduler(kube-scheduler),御马间的调度室!负责资源调度(Pod调度)的进程。创建和复制Pod的Replication Controller。
3) Node
节点(上图橘色方框)是物理或者虚拟机器,作为Kubernetes worker,通常称为Minion。每个节点都运行如下Kubernetes关键组件。
(1) Kubelet:与Master节点协作,是主节点的代理,负责Pod对应容器的创建,启动,停止等任务。默认情况下Kubelet会向Master注册自己。Kubelet定期向主机点汇报加入集群的Node的各类信息。
(2) Kube-proxy:Kubernetes Service使用其将链接路由到Pod,作为外部负载均衡器使用,在一定数量的Pod之间均衡流量。比如,对于负载均衡Web流量很有用。
(3) Docker或Rocket:Kubernetes使用的容器技术来创建容器。
4) Pod
Pod是K8s最重要也是最基础的概念!每个Pod都有一个特殊的被称为“根容器”的Pause容器,此容器与引入业务无关并且不易死亡。且以它的状态代表整个容器组的状态!Pause容器对应的镜像属于K8s平台的一部分,除了Pause容器,每个Pod还包含一个或多个用户业务容器。Pod其实有两种类型:普通的Pod及静态Pod(static Pod),static Pod并不存放在Kubemetes的eted存储里,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。而普通的Pod一旦被创建,就会被放入到etcd中存储,确后会被KubernetesMaster调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的kubelet进程实例化成一组相关的Docker容器并启动起来。在默认情况下,当Pod里的某个容器停止时,Kubemetes会自动检测到这个问题并且重新启动这个Pod(重启Podel)的所有容器),如果Pod所在的Node完机,则会将这个Node上的所有Pod重新调度到其他节点上。Pod(上图绿色方框)安排在节点上,包含一组容器和卷。同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。

Endpoint(Pod IP + ContainerPort) pod ip:一个Pod里多个容器共享Pod IP地址。K8s要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,使用虚拟二层网络技术(Flannel(没有接触过 ),OpenvSwitch)实现。在Vmware中类似的二层交换技术是VSwitch,当然了,现在整个数据中心网络二层逐步从vSwitch—>OpenvSwitch
5) Lable
Lable类似Docker中的tag,一个是对“特殊”镜像、容器、卷组等各种资源做标记,一个是attach到各种诸如Node、Pod、Server、RC资源对象上。不同的是Lable是一对键值对!Lable类似Tag,可使用K8s专有的标签选择器(Label Selector)进行组合查询。
6) Replication Controller
Replication Controller,简称RC,她用来干啥呢?就是通过她来实现Pod副本数量的自动控制!RC确保任意时间都有指定数量的Pod“副本”在运行。
如果为某个Pod创建了RC并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它,保持总数为3。如果之前不响应的Pod恢复了,现在就有4个Pod了,那么Replication Controller会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Replication Controller会立刻启动2个新Pod,保证总数为5。还可以按照这样的方式缩小Pod,这个特性在执行滚动升级时很有用。
注意:删除RC,不会影响该RC已经创建好的Pod。在逻辑上Pod副本和RC是解耦和的!创建RC时,需要指定Pod模板(用来创建Pod副本的模板)和Label(RC需要监控的Pod标签)。
由Replication Controller衍生出Deployment,与RC相似90%,目的是更好地解决Pod编排。暂时不讨论。
Horizontal Pod Autoscaler,简称HPA,Pod横向自动扩容智能控件。与RC,Deployment一样,也属于K8s的一种资源对象。她的实现原理是通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否针对性地调整目标Pod的副本数。
7) Service
微服务架构中的一个“微服务”,她是正真的新娘,而之前的Pod,RC等资源对象其实都是嫁衣。
每个Pod都会被分配一个单独的IP地址,而且每个Pod都提供了一个独立的Endpoint(Pod lP + ContainerPort)以被客户端访问,现在多个Pod副本组成了一个集群来提供服务,客户端要想访问集群,一般的做法是部署一个负载均衡器(软件或硬件),为这组Pod开启一个对外的服务端口如8000端口,并且将这些Pod的Endpoint列表加入8000端口的转发列表中,客户端就可以通过负载均衡器的对外IP地址 + 服务端口来访问此服务,而客户端的请求最后会被转发到哪个Pod,则由负载均衡器的算法所决定。
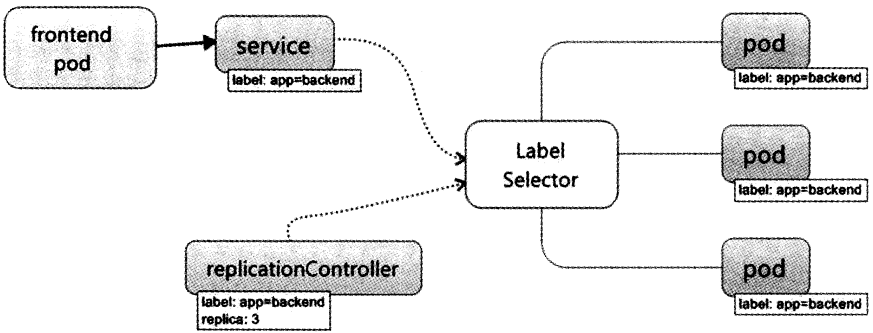
K8s的server定义了一个服务的访问入口地址,前端(Pod)通过入口地址访问其背后的一组由Pod副本组成的集群实例,service与其后端Pod副本集群之间通过Label Selector 实现“无缝对接”。
可以将Server抽象成特殊的扁平的双向管道,Service借助Label Selector保证了前端容器正确可靠地指向对应的后台容器。 RC的作用保证了Service的服务能力和服务质量始终处于预期的标准。
Kubemetes也遵循了上述常规做法,运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制。但Kubernetes发明了一种很巧妙又影响深远的设计:Service不是共用一个负载均衡器的IP地址,而是每个Service分配了一个全局唯一的虚拟IP地址,这个虚拟IP被称为ClusterIP。这样一来,每个服务就变成了具备唯一IP地址的“通信节点”,服务调用就变成了最基础的TCP网络通信问题。
Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧Pod的不同。而Service一旦创建,Kubemetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内,它的ClusterIP不会发生改变。于是,服务发现这个棘手的问题Kubemetes的架构里也得以轻松解决:只要用Service的Name与Service的Cluster IP地址做一个DNS域名映射即可完美解决问题。
版本问题
| 初始版本 | 2014年6月7日,4年前 |
|---|---|
| 稳定版本 | 1.10.3(2018年5月21日,3个月前) |
| 开发状态 | 活跃 |
| 编程语言 | Go |
| 操作系统 | 跨平台 |
| 类型 | 集群管理 |
| 许可协议 | Apache许可证 2.0 |
| 网站 | kubernetes.io |
| 源代码库 | github.com/kubernetes/kubernetes |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号