
java基础之----mysql存储结构
概述
mysql作为一个最常见的数据库,平时我们基本上只会对其进行增删改查操作,对于mysql的读写过程,数据存储结构,索引存储结构都所知甚少,一般来说专业的数据库性能调试是由dba完成的,普通的开发人员一般只会涉及到sql调优的问题,不过对底层的存储原理了解对工作还是很有帮组的,这篇文章主要讲述mysql数据存储结构和索引存储结构。
数据库存储方式
堆存储:这种存储方式是一种无序的存储,数据随机插入有空闲空间的数据块上
聚簇索引存储:聚簇是根据码值找到数据的物理存储位置,从而达到快速检索数据的目的,常见的有索引聚簇和hash聚簇,上面的解释不能不够大白话,举例来说,聚簇索引方式存储就是存储的磁盘存储顺序和索引的顺序是一样的,当查询的时候根据主键可以很快的找到存储的数据。
mysql聚簇索引存储结构
mysql是使用b+ tree方式存储的。对于b+ tree结构不熟悉的看这篇文章:为什么MySQL数据库索引选择使用B+树?。
mysql是如何通过b+ tree存储的?
mysql是b+ tree,那树的节点中存的是什么,树的节点中存的就是page,这个page就是mysql的数据页,默认大小是16kb,实际上在page上面还有Tablespace、Segment、Extent存储结构,具体可以看这篇文章:MySQL Innodb 数据页结构分析,下面主要讲解page这个结构。
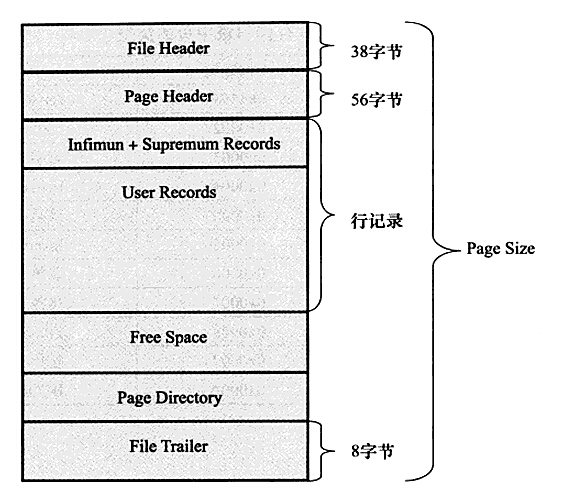
上图中的各个部分的含义在上面那篇文章中都有介绍,这里我主要说一下两个重点,第一就是user records这个是真正存储数据的地方,page directory这个是目录页,存放是一些id相关的信息,具体看下一张图。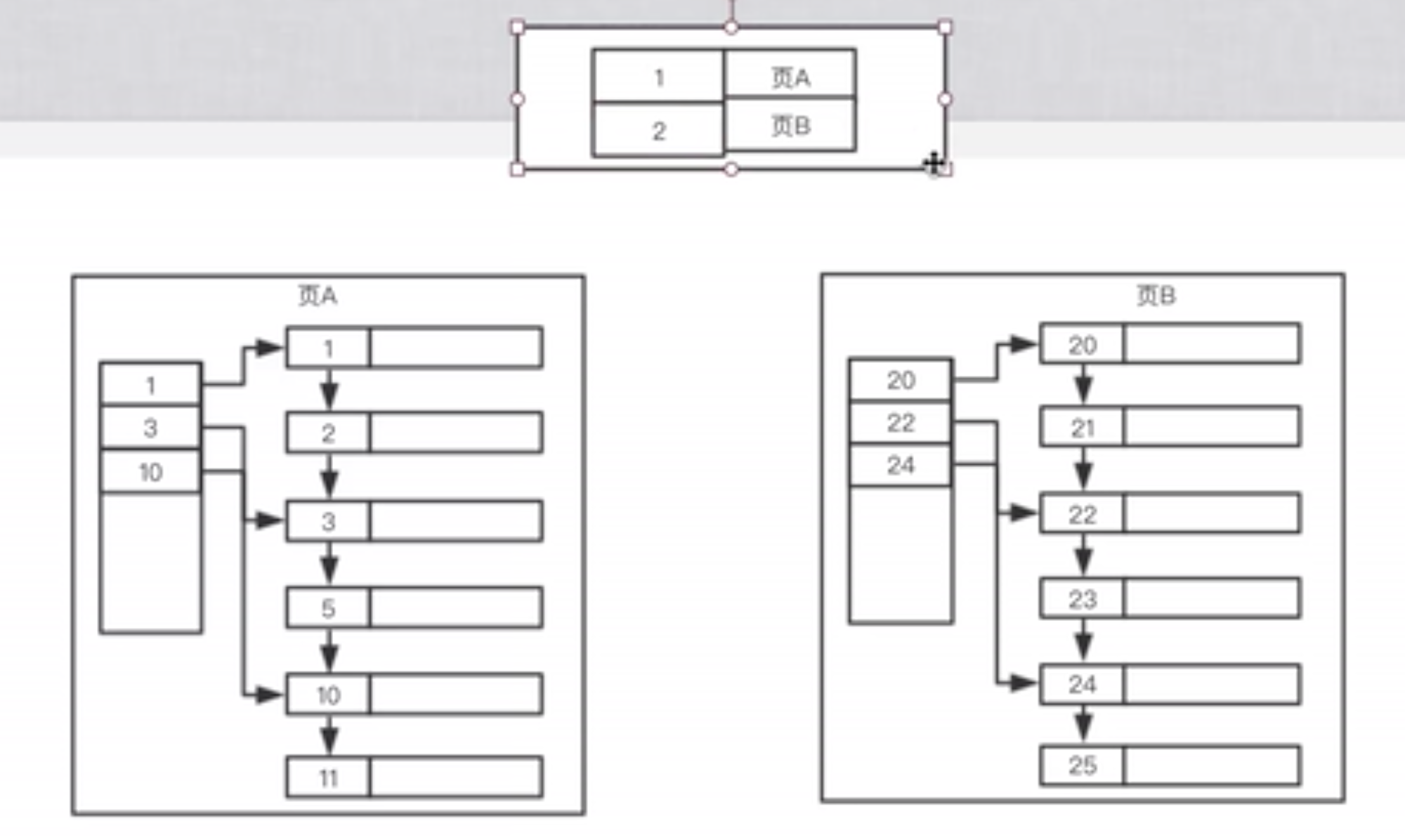
图中的下面两个分别是数据页,上面那个是目录页,在数据页中可以看到左边还有一个1,3,10,那个就是上面介绍的page directory,右边那个1,2,3,5,10,11就是user records中放的东西,其中这些数字表示主键值,每一个小块表示数据库中的一行,这一页的大小是16kb,举个例子如果一行存的数据是1kb,那一页也就只能存储16行数据,左边那个page directory是为了方便查询数据搞出来,就像一本书每一页会分为几节一样,但是细心的朋友可能发现,他并没有把所有的主键都放在这个里面,而是放一部分,这样方便快速定位到数据位置,比如要查询一个id为5的行,先根据目录页(发现上图画的有点问题,那个页B那里不应该是2,而是20,就是每一页开始的id)确定id=5的那一行应该在第一页,然后通过二分查找法快速定位到5在3和10之间,之后再从3开始遍历找到5就可以,这样可以减少二分查找法查找的次数,同时可以减少page directory的存储大小。
下面思考一个问题,一个目录页下面可以挂多少个数据页?
目录页的每条数据由两部分组成,第一步就是每页id的开始id,大小为8b,第二部分是一个指针,指向每一页的存储位置,大小为6b,也就是说每一条数据的大小是14b,而每一页的默认大小是16kb,可以算一下:16kb/14b=16*1024/14=1170,也就是说一个目录页下面可以挂1170个数据页。
一个目录页下面可以挂1170个数据页,那大约可以存储多少条数据?
假设数据库表中一行数据大小是1kb(1kb其实一样很大了,一般的表中一行数据没有这么多),那一页可以存储16行,那1170页可以存储的数据行数是:1170*16=18724行,也就是说一个目录页大约可以存储将近两万行数据。
假设一个b+ tree的深度是3层,那可以存多少行数据呢?
一个根目录页对应1170个目录页,一个目录页对应1170个数据页,每个数据页可以存16行数据,那公式就是1170*1170*16=21902400,两千多万行,基本上两千多万行数据就要分表了,所以一般一个b+ tree深度为3就可以了。
为什么使用b+ tree,而不是使用b tree呢?
b+ tree和b tree都是平衡多叉树,但是b tree每个节点都会存放数据,而b+ tree只有叶子节点存放数据,这样一个简单的区别却使mysql选择了b+ tree,原因就是如果使用b tree会导致每一页存的数据条数很少,使得树的深度很深,查询效率变低。
为什么使用主键要使用自增的,而不使用uuid这种?
通过上面的分析,可以看出,如果id是自增的,存储的时候就是有序的,如果使用uuid这种,会导致本来一页已经存储好了,突然来了一个顺序应该插入到中间的uuid,那么就会导致页分裂,而且由于uuid的无序性,会导致磁盘上有很多的碎片。
hash索引b+ tree索引的区别?
hash索引是使用hash算法来进行查询的,时间复杂度往往只有O(1),查询速度非常快,而b+ tree的查询速度就没有那么快了,由于二分查找法极端情况的时间复杂度是log2(n),也就是说在每一页上的查询的时间复杂度都是log2(n),如果需要查询3页,也就是说时间复杂度是3log2(ni),其中ni表示每一页目录页的条数。但是hash索引不能用于排序和范围查询,或者时类似于like查询等。
辅助索引为什么不推荐使用unique特性的索引?
首先要明白辅助索引的结构,其实辅助索引的结构和上面的数据存储的b+ tree结构一样,不同的是索引的b+ tree叶子节点存放的不是数据,而是主键id,如果要想寻找辅助索引中不存在的字段,那么只能通过主键进行回表操作,来查询这个字段。那知道了什么是辅助索引,回到上面的问题,innodb存储引擎是这样做的,当有新数据插入时,这时需要更新辅助索引,但是innodb不会去磁盘中读出来索引,然后更新完再写回去,这样太慢了,innodb会把这个索引先放到write buffer中,然后后台启动一个线程慢慢的写回到磁盘,但是如果使用了unique索引,那就需要和之前的索引比较是不是重复了,那就不得不去磁盘中把索引读出来,然后再比较,这个过程是很耗时的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号