



后端+timing-signoff理解
后端报告解读说明
首先,我要强调,我不是做后端的,但是工作中经常遇到和做市场和芯片同事讨论PPA。这时,后端会拿出这样一个表格:

上图是一个A53的后端实现结果,节点是TSMC16FFLL+,我们就此来解读下。
首先,我们需要知道,作为一个有理想的手机芯片公司,可以选择的工厂并不多,台积电(TSMC),联电(UMC),三星,GlobalFoundries(GF),中芯(SMIC)也勉强算一个。还有,今年开始Intel工厂(ICF)也会开放给ARM处理器。事实上有人已经开始做了,只不过用的不是第三方的物理库。通常新工艺会选TSMC,然后要降成本的时候会去UMC。GF一直比较另类,保险起见不敢选,而三星不太理别人所以也没人理他。至于SMIC,嘿嘿,那需要有很高的理想才能选。
16nm的含义我就不具体说了,网上很多解释。而TSMC的16nm又分为很多小节点,FFLL+,FFC等。他们之间的最高频率,漏电,成本等会有一些区别,适合不同的芯片,比如手机芯片喜欢漏电低,成本低的,服务器喜欢频率高的,不一而足。
接下来看表格第一排,Configuration。这个最容易理解,使用了四核A53,一级数据缓存32KB,二级1MB,打开了ECC和加解密引擎。这几个选项会对面积产生较大影响,对频率和功耗也有较小影响。
接下来是Performancetarget,目标频率。后端工程师把频率称作Performance,在做后端实现时,必须在频率,功耗,面积(PPA)里选定一个主参数来作为主要优化目标。这个表格是专门为高性能A53做的,频率越高,面积和漏电就会越大,这是没法避免的。稍后我再贴个低功耗小面积的报告做对比。
下面是CurrentPerformance,也就是现在实现了的频率。里面的TT/0.9V/85C是什么意思?我们知道,在一个晶圆(Wafer)上,不可能每点的电子漂移速度都是一样的,而电压,温度不同,它们的特性也会不同,我们把它们分类,就有了PVT(Process,Voltage,Temperature),分别对应于TT/0.9V/85C。而Process又有很多Conner,类似正态分布,TT只是其中之一,按照电子漂移速度还可以有SS,S,TT,F,FF等等。
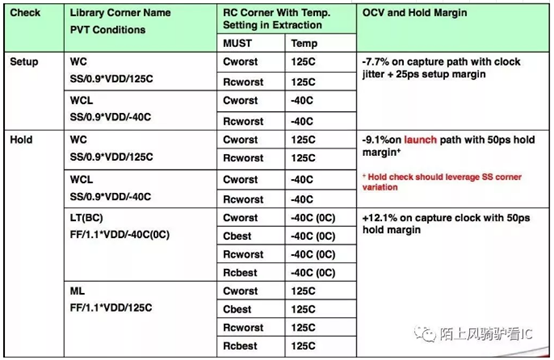
通常后端结果需要一个Signoff条件(我们这通常是SSG),按照这个条件出去流片,作为筛选门槛,之下的芯片就会不合格,跑不到所需的频率。所以条件设的越低,良率(Yield)就会越高。但是条件也不能设的太低,不然后端很难做,或者干脆方程无解,跑不出结果。X86上有个词叫体质,就是这个PVT。
这一栏有四个频率,上下两组容易区分,就是不同的电压。在频率确定时,动态功耗是电压的2次方,这个大家都知道。而左右两组数字的区别就是Corner了,分别为TT和SSG。
下一行是OptimizationPVT。大家都知道后端EDA工具其实就是解方程,需要给他一个优化目标,它会自动找出最优局部解。而1.0V和0.9V中必须选一个值,作为最常用的频率,功耗和面积的甜点(SweetSpot)。这里是选了1.0V,它的SSG和目标要求更接近,那些达不到的Corner可以作为降频贱卖。
再下一行是漏电Leakage,就是静态功耗。CPU停在那啥都不跑也会有这个功耗,它包含了四个CPU中的逻辑和一级缓存的漏电。但是A53本身是不包含二级缓存的,其他的一些小逻辑,比如SCU(SnoopingControlUnit)也在CPU核之外,这些被称作Non-CPU,包含在MP4中。我们待机的时候就是看的它,可以通过powergating关掉二三级缓存,但是通常来说,不会全关,或者没法关。
下面是DynamicPower,动态功耗。基本上我见过的CPU在测量动态功耗的时候,都是跑的Dhrystone。Dhrystone是个非常古老的跑分程序,基本上就是在做字符串拷贝,非常容易被软件,编译器和硬件优化,作为性能指标基本上只有MCU在看了。
但是它有个好处,就是程序很小,数据量也少,可以只运行在一级缓存(如果有的话),这样二级缓存和它之后的电路全都只有漏电。虽然访问二级三级缓存甚至DDR会比访问一级缓存耗费更多的能量,但是它们的延迟也大,此时CPU流水线很可能陷入停顿。这样的后果就是Dhrystone能最大程度的消耗CPU核心逻辑的功耗,比访问二级以上缓存的程序都要高。所以通常都拿Dhrystone来作为CPU最大功耗指标。实际上,是可以写出比Dhrystone更耗电的程序的,称作MaxPowerVector,做SoC功耗估算的时候会用上。
动态功耗和电压强相关。公式里面本身就是2次方,然后频率变化也和电压相关,在跨电压的时候就是三次方的关系了。所以别看1.0V只比0.72V高了39%,最终动态功耗可能是3倍。而频率高的时候,动态功耗占了绝大部分,所以电压不可小觑。
此外,动态功耗和温度相关,SoC运行的时候不可能温度维持在0度,所以功耗通常会拿85度或者更高来计算,这个就不多说了。
下一行是Area,面积。面积是芯片公司的立足之本,和毛利率直接相关。所以在性能符合的情况下,越小越好,甚至可以牺牲功耗,不惜推高电压,所以有了OD(OverDrive)。有个数据,当前28nm上,每个平方毫米差不多是10美分的成本,一个超低端的手机芯片怎么也得30mm(200块钱那种手机用的,可能你都没见过,还是智能机),芯片面积成本就是3刀,这还不算封测,储存和运输。
低端的也得是40mm(300块的手机)。我们常见的600-700块钱的手机,其中六分之一成本是手机芯片。当然,反过来,也有人不缺钱的,比如苹果,据说A10在16nm上做到了125mm,换算成这里的A53MP4,单看面积不考虑功耗,足足可以放120个A53,极其奢侈,这可是跑在2.8G的A53,如果是1.5G的,150个都可能做到。
那苹果这么大的面积到底是做什么了?首先,像GPU,Video,Display,基带,ISP这些模块,都是可以轻易的拿面积换性能的,因为可以并行处理。而且,功耗也可以拿面积换,一个最简单的方法就是降频,增加处理单元数。这样漏电虽然增加,但是电压下降,动态功耗可以减少很多。一个例外就是CPU的单核性能,为什么苹果可以做到Kirin960的1.8倍,散热还能接受?和物理库,后端,前端,软件都有关系。
首先,A10是6发射,同时代的A73只用了2发射。当然,由于受到了数据和指令相关性限制,性能不是三倍提升,而6发射的后果是面积和功耗非线性增加。作为一个比较,我看过ARM的6发射CPU模型,同工艺下,单核每赫兹性能是A73的1.8倍,动态功耗估算超过2倍,面积也接近2倍。当然,它的微结构和A73是有挺大区别的。这个单核芯片跑在16nm,2.5Ghz,单核功耗差不多是1W。而手机芯片的功耗可以维持在2.5W不降频,所以苹果的2.3Ghz的A10算下来还是可行的。
为了控制功耗,在做RTL的时候就需要插入额外晶体管,做ClockGating,而且这还是分级的,RTL级,模块级,系统级,信号时钟上也有(我看到的SoC时钟通常占了整个逻辑电路功耗的三分之一)。这样一套搞下来,面积起码大1/3.然后就是PowerGating,也是分级的。最简单的是每块缓存给一个开关,模块也有一个开关。复杂的根据不同指令,可以计算出哪些Cachebank短时间内不用,直接给它关了。PowerGating需要的延时会比ClockGating大,有的时候如果操作很频繁,PowerGating反而得不偿失,这需要仔细的考量。而且,设计的越复杂,验证也就越难写,这里面需要做一个均衡。除了时钟域,电源域,还有电压域,可以根据不同频率调电压。当然了,域越多,布线越难,面积越大。
再往上,可以定义出不同的powerstate,让上层软件也参与经来,形成电源管理和调度。
再回到苹果A10,它还使用了6MB的缓存。这个在手机里面也算大的惊世骇俗。通常高端的A73加2MB,A53加1MB,已经很高大上了,低端的加起来也不超过1MB。我拿SPECINT2K在A53做过一些实验,二级缓存从128KB增加到1MB只会增加15%不到的性能,到6MB那性能/面积收益更不是线性的,这是赤裸裸的面积换性能。而且苹果宣扬的不是SPECINT,而是GeekBench4.0,我怀疑是不是这个跑分对缓存大小更敏感,有空可以做做实验。
顺带提一句,安兔兔5.0和缓存大小没半毛钱关系,这让广大高端手机芯片公司情何以堪。到了6.0似乎改了,我还没仔细研究过。至于使用了大面积缓存引起的漏电,倒是有办法解决,那就是部分关闭缓存,用多少开多少,是个精细活,需要软硬件同时配合。
影响面积的因素还没完,上面只是前端,后端还有一堆考量呢。
首先就是表格下一排,MetalStack。芯片制造的时候是一层层蚀刻的,而蚀刻的时候需要一层层打码,免得关键部分见光,简称Mask。这里的11m就表示有11层。晶体管本身是在最底层的,而走线就得从上面走,层数越多越容易,做板子布线的同学肯定一看就明白了。照理说这就该多放几层,但是工厂跟你算钱也是按照层数来的,越多越贵。层数少了不光走线难,总体面积的利用率也低,像A53,11层做到80%的利用率就挺好了。所以芯片上不是把每个小模块面积求和就是总体面积,还得考虑布局布线(PR,Placing&Routing),考虑面积利用率。
再看表格下两排,LogicArchitecture和Memory。这个也容易理解,就是逻辑和内存,数字电路的两大模块分类。这个内存是片上静态内存,不是外面的DDR。uLVT是什么意思呢,UltraLowVoltageThreshold,指的是标准逻辑单元(StandardCell)用了超低电压门限。电压低对于动态功耗当然是个好事,但是这个标准单元的漏电也很高,和频率是对数关系,也就是说,漏电每增加10倍,最高频率才增加log10%。后端可以给EDA工具设一个限制条件,比如只有不超过1%的需要冲频率的关键路径逻辑电路使用uLVT,其余都使用LVT,SVT或者HVT(电压依次升高,漏电减小),来减小总体漏电。
对于动态功耗,后端还可以定制晶体管的源极和漏极的长度,越窄的电流越大,漏电越高,相应的,最高频率就可以冲的更高。所以我们有时候还能看到uLVTC16,LVTC24之类的参数,这里的C就是指ChannelLength。
接下去就是Memory,又作MemoryInstance,也有人把它称作FCI(FastCacheInstance)。访问Memory有三个重要参数,read,write和setup。这三个参数可以是同样的时间,也可以不一样。对于一级缓存来说基本用的是同样的时间,并且是一个时钟周期,而且这当中没法流水化。从A73开始,我看到后端的关键路径都是卡在访问一级缓存上。也就是说,这段路径能做多快,CPU就能跑到多快的频率,而一级缓存的大小也决定了索引的大小,越大就越慢,频率越低,所以ARM的高端CPU一级缓存都没超过64KB,这和后端紧密相关。当然,一级缓存增大带来的收益本身也会非线性减小。之后的二三级缓存,可以使用多周期访问,也可以使用多bank交替访问,大小也因此可以放到几百KB/几MB。
逻辑和内存统称为PhysicalLibrary,物理库,它是根据工厂给的每个工艺节点的物理开发包(PDK)设计的,而Library是一个Fabless芯片公司能做到的最底层。能够定制自己的成熟物理库,是这家公司后端领先的标志之一。
最后一行,Margin。这是指的工厂在生产过程中,肯定会产生偏差,而这行指标定义了偏差的范围。如下图:
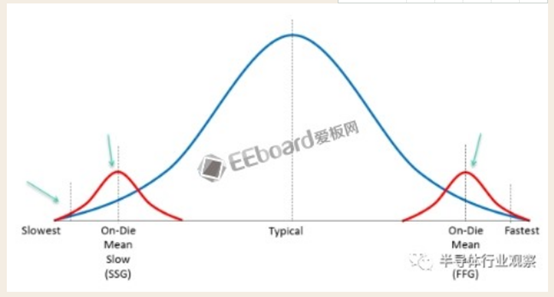
蓝色表示我们刚才说的一些Corner的分布,红色表示生产偏差Variation。必须做一些测试芯片来矫正这些偏差。SB-OCV表示stage-basedon-chipvariation,和其他的几个偏差加在一起,总共+-7%,也就是说会有7%的芯片不在后端设计结束时确定的结果之内。
后面还有一些setupUC之类的,表示信号建立时间,保持时间的不确定性(Uncertainty),以及PLL的抖动范围。
至此,一张报告解读完毕,我们再看看对应的低功耗版实现版本:
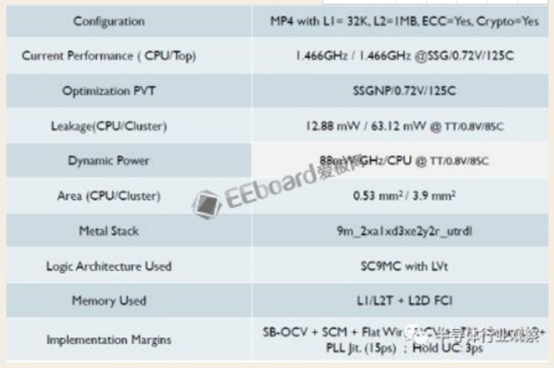
这里频率降到1.5G左右,每Ghz动态功耗少了10%,但是静态降到了12.88mW,只有25%。我们可以看到,这里使用了LVT,没有uLVT,这就是静态能够做低的原因之一。由于面积不是优化目标,它基本没变,这个也是可以理解的,因为Channel宽度没变,逻辑的面积没法变小。
数字标准单元库-后端简要理解
参考博文:https://blog.csdn.net/u011729865/article/details/53488431
对umc28nm standard cell library,做一些阅读理解,很多数据资料来源。
HVT/SVT/LVT的意思?
high Vt
Standard Vt(也有称为Regular Vt,即RVT)
low Vt
阈值电压越低,因为饱和电流变小,所以速度性能越高;但是因为漏电流会变大,因此功耗会变差。
PVT
process、voltage、temperature
technology是28nm工艺;process是制造流程,一般分为FF/TT/SS。两者的内容应该包括high-speed/high-density/HVT/SVT/LVT/multi-channel等信息。
multi-channel library
对应不同的gate-length,即沟道长度。一般比工艺28nm要大一些。
例如,umc28nm的SVTmin 相对 SVTmax,性能增加20%,静态功耗增加80%。
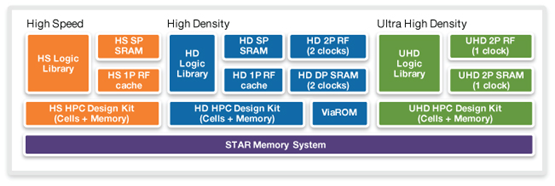
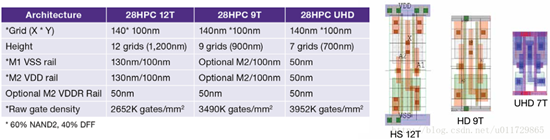
7T/9T/12T
分别对应ultra-high-density(for lowest power in SOC blocks)、high-density(for highest density in GPU
blocks)、high-speed(for highest performance in CPU blocks)。
T,代表track;是单元库的版图规则;作为一个计量单位。
标准单元库的单元高度,基本都是固定的,方便版图的布局;高度,通常以track作为计量单位,即用M2 track
pitch来表示。
track和pitch的区别?
对于前端设计人员来说,不必深入。只要看懂databook就可以了。个人当前理解track和pitch,就是一样的;pitch=minSpacing+minWidth。
grid是单元库里,与工艺制造精度相关的名称。一般pin都放置在grid上,这也不需要多加深入,就认为是工艺在版图上的最小精度就可以了。
don’t use单元列表
综合不允许使用的,一般是驱动能力太强或者太弱的标准单元不用;还有其它为了性能、功耗、面积衡量的单元。
推荐的单元库选择方法
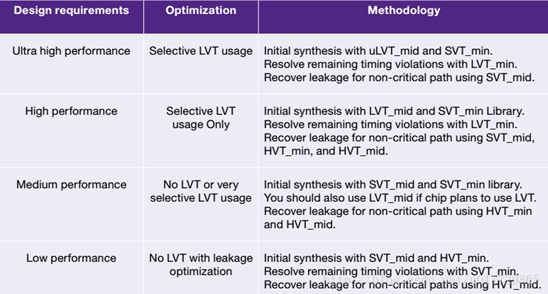
HLP和HPC的区别
HLP,high performance low power;这个应该是主流?
HPC,high performace compact。
ps:28nmHLP的core电压,是1.05V;HPC的core电压,则是0.9V。
举例,以CA53来看,HPC相对HLP,性能增加32%;面积减小5%。
另外,发现HLP的版图,跟HPC不一样。
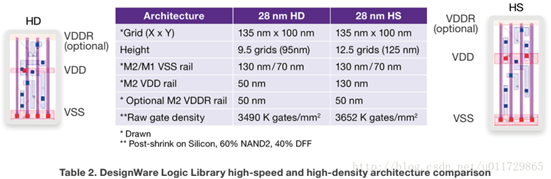
SOC系统需要的单元库划分
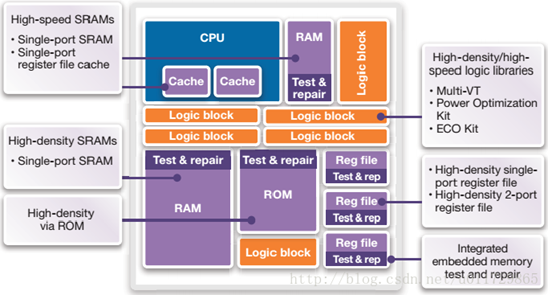
推荐的单元库优化方法

举例说明ulvt:
uLVT是什么意思呢,UltraLowVoltageThreshold,指的是标准逻辑单元(StandardCell)用了超低电压门限。电压低对于动态功耗当然是个好事,但是这个标准单元的漏电也很高,和频率是对数关系,也就是说,漏电每增加10倍,最高频率才增加log10%。后端可以给EDA工具设一个限制条件,比如只有不超过1%的需要冲频率的关键路径逻辑电路使用uLVT,其余都使用LVT,SVT或者HVT(电压依次升高,漏电减小),来减小总体漏电。对于动态功耗,后端还可以定制晶体管的源极和漏极的长度,越窄的电流越大,漏电越高,相应的,最高频率就可以冲的更高。所以我们有时候还能看到uLVTC16,LVTC24之类的参数,这里的C就是指ChannelLength。

芯片timing signoff
一颗健壮的IC芯片应该具有能屈能伸的品质,他需要适应于他所在应用范围内变化的温度、电压,他需要承受制造工艺的偏差,这就需要在设计实现过程中考虑这些变化的温度、电压和工艺偏差。
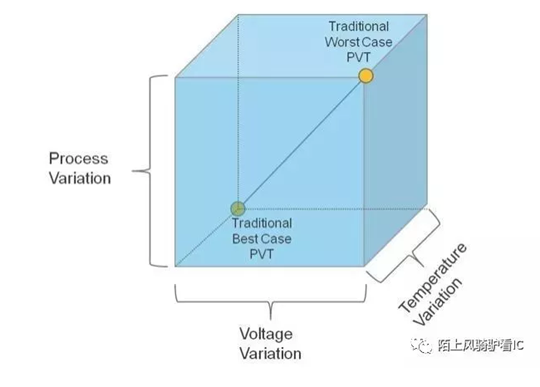
在STA星球,用library PVT、RC corner跟OCV来模拟这些不可控的随机因素。在每个工艺结点,通过大量的建模跟实测,针对每个具体的工艺,foundary厂都会提供一张推荐的timingsignoff表格, 建议需要signoff的corner及各个corner需要设置的ocv跟margin。这些corner能保证大部分芯片可以承受温度、电压跟工艺偏差,一个corner=libraryPVT+ RC corner + OCV,本文将关注于library PVT。
PVT也称为Operating condition,是STA一个基本且重要的概念,在library的表头会有operating condition的定义,如下图,其中『ss0p81vm40c』是这个operating condition的名字,通常这个名字是有意义的,它会标示出该lib对应的电压跟温度,如0p81对应于voltage:0.81,m40c对应于temperature:-40度。

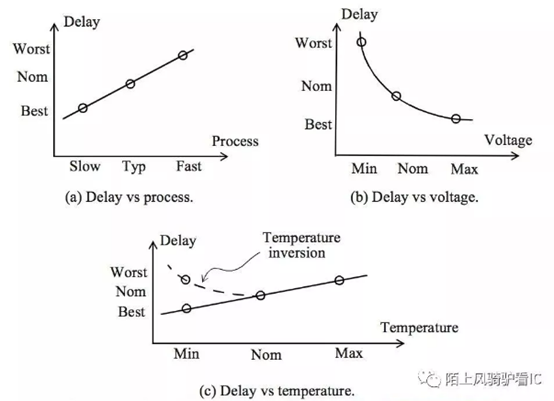
P-process:IC制造工艺本身的不完美,使得制造偏差不可避免,在library中会用一个百分比来表示工艺偏差,如process:1表示没偏差。在沉积或参杂过程中,杂质浓度密度、氧化层厚度、扩散深度都可能发生偏差,从而导致管子的电阻跟阈值电压发生偏差;光刻过程中由于分辨率的偏差会导致管子的宽长比产生偏差。而这些偏差,都会导致管子性能的差异。
V-voltage:管子的延时取决于饱和电流,而饱和电流取决于供电电压。且不论多电压域芯片,就单电压芯片而言,电池的供电电压本身就在一个范围内变化,再加上片外或片上voltage regulator的误差、再加上IR,一个芯片上的每个管子都可能工作在不同电压下,从而性能也有所差别。
T-temperature:在日常操作中,IC芯片必须适应温度不恒定的环境,当芯片运行时,由于开关功耗、短路功耗和漏电功耗会使芯片内部的温度发生变化。温度波动对性能的影响通常被认为是线性的,但在深亚微米温度对性能的影响是非线性的。对于一个管子,当温度升高,空穴/电子的移动速度会变慢,使延时增加,而同时温度的升高也会使管子的阈值电压降低,较低的阈值电压意味着更高的电流,因此管子的延时减小。而通常温度升高对空穴/电子移动速度的影响会大于对阈值电压的影响,所以温度升高管子的延时呈增加趋势。但是并不是温度越低管子的延时就越小,晶体管有温度翻转效应,当温度低到某个值之后,随着温度的降低,管子的延时会增加,至于温度翻转点跟具体的工艺相关。
在做STA分析时,operating condition通常通过lib读入,如果多个library中的operating condition不同,通常用第一个读入的library中定义的operating condition。也可以用命令设置/定义operating condition,不同的工具有不同的实现方式,如:set_operating_condition。在debug环境时可以report_design来check当前所用的operating condition。
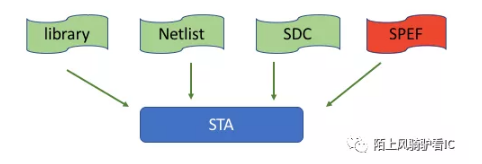
Timing sign-off Corner=library PVT+ RC corner + OCV,PVT在《巴山夜雨涨秋池,邀君共学PVT:STA之PVT》中。 今天来把玩一下RC corner,这里的RC指gate跟network的寄生参数,寄生参数抽取工具根据电路的物理信息,抽取出电路的电阻电容值,再以寄生参数文件输入给STA工具,常见的寄生参数文件格式为SPEF。
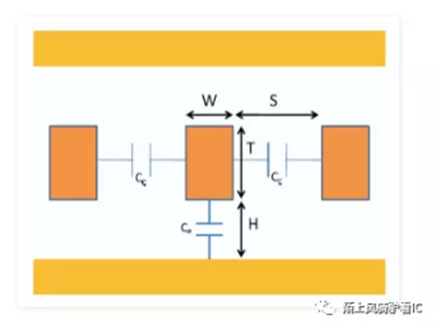
ICer都知道在集成电路中是多层走线的,专业术语叫metal layer,不同工艺有不同层metal layer,任何两层metal layer间由介电材料隔离,『走线』通过过孔(VIA)连接。Width跟Spacing是衡量绕线的两条最重要的物理设计规则,它们随着工艺的进步逐步减小。 介电材料、绕线材料、线间距、线宽及线的厚度这些物理特性决定了network的RC值。
Network电容:
耦合电容:Coupling capacitance=e*T/S
表面电容:Surface capcitance=e*W/H
边缘电容:Fringe capcitance
决定容值的因素:
介电常数:e
线宽:W
线厚:T
线间距:S
介电材料的厚度:H
随着工艺进步,W, S, T 逐代递减,表面电容跟随减小,耦合电容随之增加,耦合电容在总电容中占比增加,当线厚 T 一定时为了减少耦合电容要么增加线间距要么减小介电常数。通常为了减小噪声敏感信号线(如clock net)上的耦合电容,在物理实现时会人为增加对应信号的线宽及线间距,俗称NDR。要减小介电常数需要从材料入手,从 .18开始引入low K介电材料。
Network电阻:
R=r/W*T, r为电阻率,除了跟线宽 W 和线厚 T 相关之外,还跟温度相关,随着温度的上升而增大。
|
Parameters |
Resistance |
Surface Capacitance |
Coupling Capacitance |
|
温度增加 |
增加 |
-- |
-- |
|
线宽减小 |
增加 |
减小 |
-- |
|
线厚减小 |
增加 |
-- |
减小 |
|
线间距减小 |
无影响 |
无影响 |
增加 |
由上面的分析可知,Network的单位电容和单位电阻是不可能同时最大或同时最小的。有了这些铺垫,来看一下不同工艺结点是如何定义RC corner的。
90nm 之前,Cell delay占主导,Network电容主要是对地电容,STA只需要两个RC corner即可:
Cbest(Cmin): 电容最小电阻最大
Cworst(Cmax):电容最大电阻最小
90nm 之后,netdelay的比重越来越大,而且network的耦合电容不可忽略,所以又增加了两个RC corner:
RCbest(XTALK corner): 耦合电容最大,(对地电容*电阻)最小
RCworst(Delay corner): 耦合电容最小,(对地电容*电阻)最大
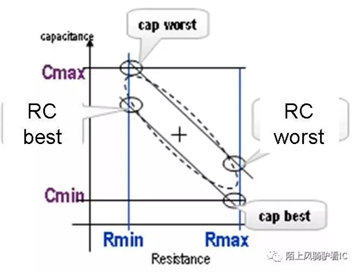
至此总共有两个需要setup timing sign-off的RC corner,有四个需要hold timing sign-off的RC corner:
Setup time sign-off 的RC corner是: Cworst / RCworst
Hold time sign-off 的RC corner是: Cbest / RCbest / Cworst / RCworst
C-best:
It hasminimum capacitance. So also known as Cmin corner.
InterconnectResistance is larger than the Typical corner.
Thiscorner results in smallest delay for paths with short nets and can be used formin-path-analysis.
C-worst:
Refers tocorners which results maximum Capacitance. So also known as Cmax corner.
Interconnectresistance is smaller than at typical corner.
Thiscorners results in largest delay for paths with shorts nets and can be used formax-path-analysis.
RC-best:
Refers tothe corners which minimize interconnect RC product. So also known as RC-mincorner.
Typicallycorresponds to smaller etch which increases the trace width. This results insmallest resistance but corresponds to larger than typical capacitance.
Corner hassmallest path delay for paths with long interconnects and can be used formin-path-analysis.
RC-worst:
Refers tothe corners which maximize interconnect RC product. So also known as RC-maxcorner.
Typicallycorresponds to larger etch which reduces the trace width. This results inlargest resistance but corresponds to smaller than typical capacitance.
Corner haslargest path delay for paths with long interconnects and can be used formax-path-analysis.
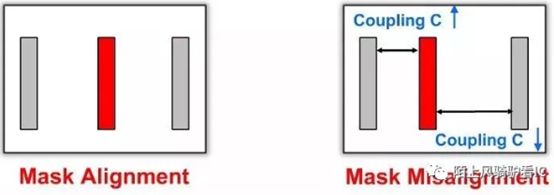
引入的DPT(Double Patterning Technology)之后,在同一层layer上要做两次mask,两次mask之间的偏差,会导致线间距变化,从而影响耦合电容值,需要将这一因素考虑到RC corner中,所以DPT 的RC corner是:Cworst_CCworst, RCworst_CCworst, Cbest_CCbest, RCbest_CCbest.
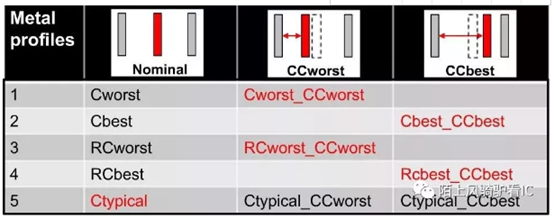
其中:
Setup timesign-off 的RC corner是: Cworst_CCworst / RCworst_CCworst
Hold timesign-off 的RC corner是: Cbest_CCbest / RCbest_CCbest / Cworst_CCworst /RCworst_CCworst
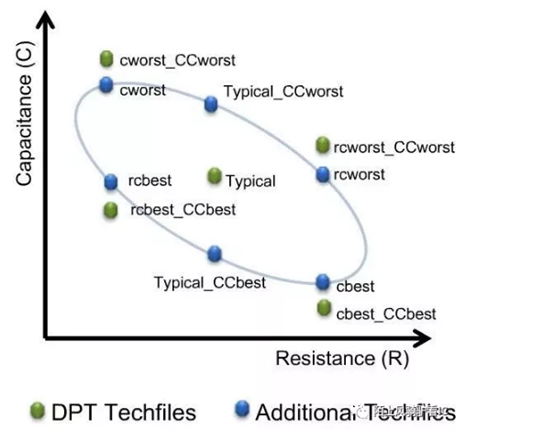
除以上这些corner外,还有一个corner叫Typical corner,对应于DPT的是Ctypical_CCworst, Ctypical_CCbest,这些corner不用于timing sign-off。
《抽刀断水水更流,RC Corner不再愁:STA之RC Corner》发出之后,陆续收到一些问题跟指正,打铁趁热,总结于此,来,一起继续讨论完善。
Q:还有一种RC corner 带后缀『_T』,只用于setup signoff,T指的是什么?
A:T代表tighten,在rc的variation上的sigma分布比不带T的更紧,因此只能用于setup,hold不推荐。Appleto Apple地比较,T的variation更小,理论看到的rc变化更小,单从setup产生violation的可能性更小。至于悲观还是乐观,除非自己定criteria,其余的follow foundry或者vendor的rule最重要。
注:感谢驴群里提问的@the1ne 和回答的大神 @没人认识我,各记小红花一朵。
Q:为什么setup既需要sign-off C-corner又需要sign-offRC-corner?
A:因为C-corner表示『电容』最大/最小,而RC-corner是『电容*电阻』最大/最小。通常对于短线而言,电容占主导地位,C-corner可以cover RC-corner,但对于长线则电阻占主导地位,C-corner无法cover RC-corner,而是反过来RC-corner去cover C-corner。而没人保证一个设计里只有短线没有长线,也没权威对长短的幅度有量化的定义,所以最保险的就是两者分别sign-off。
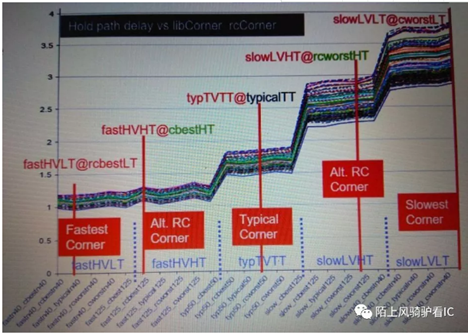
Q:为什么hold需要sign-off所有的corner?
A:对于hold而言,根据其仿真曲线,相互之间都无法完全覆盖,故需要sign-off所有corner。
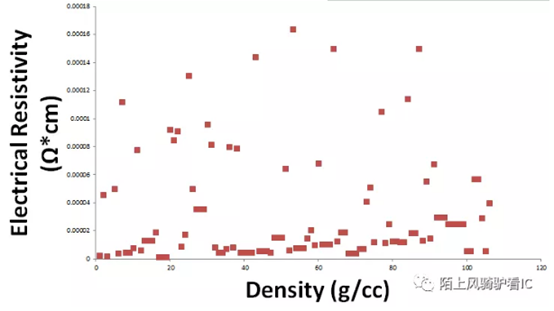
Q:金属电阻是否跟density/spacing相关?为什么方块电阻跟density/spacing相关?
A:就电阻本身而言,阻值跟density没有关系,只跟金属线自身的宽厚和电阻率相关,详细描述:
There is no relationship between the density of a metal and itselectrical resistivity.
There is a big database of material properties called MatWeb which is recommend as a legitimate source of data by UCSD's and Stanford's library systems, Rose-Hulman, etc. I took data fromaround 60 different metals and graphed them:
As you can see there is no empirical relationship. From a theoryperspective, density has to do with atomic packing and resistivity has to dowith electronic structure.
Iwill admit, however, that gaseous copper is an extremely poor conductor.
但是,在半导体制造过程中,由于工艺偏差,电阻跟金属线的density是相关的。此时,电阻率是线宽跟线间距的函数。这一关系,在foundry给的工艺文件里都有相应的描述,这些都是在抽RC时需要考虑的因素。
Resistivity as a Function of Width and Spacing (Rs = f(W) or rho=f(W,S))
Variationin resistivity is caused by a number of phenomena. Copper is a softer materialthan the dielectric in which it is embedded. As a result, the polishing of thewafer during the CMP process has a tendency to remove a little extra copperfrom the top of the wire. This effect is called dishing because of the shape ofthe resulting wire top. The effect becomes more pronounced as the wire widthincreases. This effect is shown in exaggerated form in following pic.
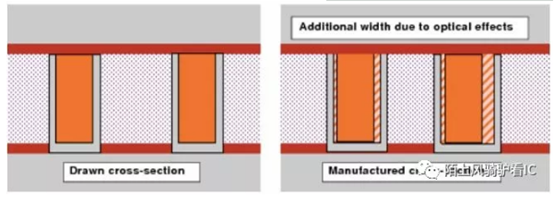
To reduce theeffect of dishing on wide wires, small holes, or slots, can be inserted atregular intervals in wide wires. These slots insert a form of hard"posts" in the wire so that the CMP process removes less copper. Thistechnique reduces the dishing, as well as the effective resistivity.
Anothercontributor to resistivity variation is the cladding in copper wires. Claddingis the material grown around the sides and bottom of copper wires to protectthem from chemical reactions with the dielectric material. This cladding isillustrated in gray in following pic. The thickness ofthe cladding on the sides and bottoms of wires also varies with the width of awire. Because cladding has a much higher resistance than copper, it impacts theeffective resistivity of copper wires. This effect is more pronounced in thenarrowest wires. The combination of the effects ofdishing, slotting, and cladding thickness is modeled by the wire resistivity asa function of the wire width in silicon, and its spacing.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号