
【机器学习实战】-- Titanic 数据集(8)-- Boosting提升 (XGBOOST)
1. 写在前面:
本篇属于实战部分,更注重于算法在实际项目中的应用。如需对感知机算法本身有进一步的了解,可参考以下链接,在本人学习的过程中,起到了很大的帮助:
【1】XGBoost算法原理小结 https://www.cnblogs.com/pinard/p/10979808.html
【2】XGBoost Parameters https://xgboost.readthedocs.io/en/latest/parameter.html
【3】XGBoost Python API Reference https://xgboost.readthedocs.io/en/latest/python/python_api.html#module-xgboost.sklearn
2. 数据集:
数据集地址:https://www.kaggle.com/c/titanic
Titanic数据集是Kaggle上参与人数最多的项目之一。数据本身简单小巧,适合初学者上手,深入了解比较各个机器学习算法。
数据集包含11个变量:PassengerID、Pclass、Name、Sex、Age、SibSp、Parch、Ticket、Fare、Cabin、Embarked,通过这些数据来预测乘客在Titanic事故中是否幸存下来。
3. 算法简介:
XGBoost实际上是对GBDT的优化,GBDT利用了泰勒一阶展开,拟合负梯度;而XGBoost则对损失函数泰勒二阶展开,一次求解出决策树最优的所有J个叶子节点区域$R_{tj}$和每个叶子节点区域的最优解$c_{tj}$。



4. 实战:


1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder, OrdinalEncoder 6 from sklearn.impute import SimpleImputer 7 from sklearn.model_selection import StratifiedKFold, GridSearchCV, train_test_split, cross_validate 8 from sklearn.pipeline import Pipeline, FeatureUnion 9 from sklearn.tree import DecisionTreeClassifier 10 from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier 11 from sklearn.metrics import accuracy_score, precision_score, recall_score, auc 12 from sklearn.base import BaseEstimator, TransformerMixin 13 from sklearn.utils import class_weight 14 15 import xgboost as xgb 16 17 18 class DataFrameSelector(BaseEstimator, TransformerMixin): 19 def __init__(self, attribute_name): 20 self.attribute_name = attribute_name 21 22 def fit(self, x, y=None): 23 return self 24 25 def transform(self, x): 26 return x[self.attribute_name].values 27 28 29 # Load data 30 data = pd.read_csv('train.csv') 31 32 data_x = data.drop('Survived', axis=1) 33 data_y = data['Survived'] 34 35 # Data cleaning 36 cat_attribs = ['Pclass', 'Sex', 'Embarked'] 37 dis_attribs = ['SibSp', 'Parch'] 38 con_attribs = ['Age', 'Fare'] 39 40 # encoder: OneHotEncoder()、OrdinalEncoder() 41 cat_pipeline = Pipeline([ 42 ('selector', DataFrameSelector(cat_attribs)), 43 ('imputer', SimpleImputer(strategy='most_frequent')), 44 ('encoder', OneHotEncoder()), 45 ]) 46 47 dis_pipeline = Pipeline([ 48 ('selector', DataFrameSelector(dis_attribs)), 49 ('scaler', MinMaxScaler()), 50 ('imputer', SimpleImputer(strategy='most_frequent')), 51 ]) 52 53 con_pipeline = Pipeline([ 54 ('selector', DataFrameSelector(con_attribs)), 55 ('scaler', MinMaxScaler()), 56 ('imputer', SimpleImputer(strategy='mean')), 57 ]) 58 59 full_pipeline = FeatureUnion( 60 transformer_list=[ 61 ('con_pipeline', con_pipeline), 62 ('dis_pipeline', dis_pipeline), 63 ('cat_pipeline', cat_pipeline), 64 ] 65 ) 66 67 data_x_cleaned = full_pipeline.fit_transform(data_x) 68 69 X_train, X_test, y_train, y_test = train_test_split(data_x_cleaned, data_y, stratify=data_y, test_size=0.25, random_state=1992) 70 71 cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=2) 72 73 # XGBoost 74 xgb_cla = xgb.XGBClassifier(use_label_encoder=False, verbosity=1, objective='binary:logistic', random_state=1992) 75 cls_wt = class_weight.compute_class_weight('balanced', np.unique(y_train), y_train) # cls_wt[1]/cls_wt[0] 76 77 param_grid = [{ 78 'learning_rate': [0.5], 79 'n_estimators': [5], 80 'max_depth': [5], 81 'min_child_weight': [5], 82 'gamma': [5], 83 'scale_pos_weight': [1], 84 'subsample': [0.8], 85 }] 86 87 grid_search = GridSearchCV(xgb_cla, param_grid=param_grid, cv=cv, scoring='accuracy', n_jobs=-1, return_train_score=True) 88 grid_search.fit(X_train, y_train) 89 cv_results_grid_search = pd.DataFrame(grid_search.cv_results_).sort_values(by='rank_test_score') 90 91 predicted_train_xgb = grid_search.predict(X_train) 92 predicted_test_xgb = grid_search.predict(X_test) 93 94 print('------------XGBoost grid_search: Results of train------------') 95 print(accuracy_score(y_train, predicted_train_xgb)) 96 print(precision_score(y_train, predicted_train_xgb)) 97 print(recall_score(y_train, predicted_train_xgb)) 98 99 print('------------XGBoost grid search: Results of test------------') 100 print(accuracy_score(y_test, predicted_test_xgb)) 101 print(precision_score(y_test, predicted_test_xgb)) 102 print(recall_score(y_test, predicted_test_xgb))
4.1 xgboost中自定义eval_metric:
和 Adaboost 和 GBDT 一样,也想将每一步的分步强学习器在训练集以及验证集上的表现。由于xgboost并没有直接的staged_predict方法,这就需要用到参数 “eval_metric”,来指定 evaluation metric,其自带的有 “error”,在这里我也自己写了一个 “accuracy” 的eval metric, 正好可以和 "error" 进行对比。然而在这里我发现了一个问题:我们之前设定的 objective 是 “binary:logistic”,根据官方文档:binary:logistic: logistic regression for binary classification, output probability,然而实际上它只是在使用 predict 方法时,输出的是 probability,输入到 eval_metric 中的所谓的“y_predicted”,其实是 $f(x)$,也就是未经过 transformation 的值,因此在 eval_metric 中的定义需要小心。
1 def metric_precision(y_predicted, y_true): 2 label = y_true.get_label() 3 predicted_binary = [1 if y_cont > 0 else 0 for y_cont in y_predicted] 4 5 print('max_y_predicted:%f' % max(y_predicted)) 6 print('min_y_predicted:%f' % min(y_predicted)) 7 8 precision = precision_score(label, predicted_binary) 9 return 'Precision', precision 10 11 12 def metric_accuracy(y_predicted, y_true): 13 label = y_true.get_label() 14 # predicted_binary = np.round(y_predicted) 15 # y_predicted = 1 / (1 + np.exp(-y_predicted)) 16 predicted_binary = [1 if y_cont > 0 else 0 for y_cont in y_predicted] 17 18 print('max_y_predicted:%f' % max(y_predicted)) 19 print('min_y_predicted:%f' % min(y_predicted)) 20 21 accuracy = accuracy_score(label, predicted_binary) 22 return 'Accuracy', accuracy 23 24 25 def metric_recall(y_predicted, y_true): 26 label = y_true.get_label() 27 predicted_binary = [1 if y_cont > 0 else 0 for y_cont in y_predicted] 28 29 print('max_y_predicted:%f' % max(y_predicted)) 30 print('min_y_predicted:%f' % min(y_predicted)) 31 32 recall = recall_score(label, predicted_binary) 33 return 'Recall', recall 34 35 36 xgb_cla2 = grid_search.best_estimator_ 37 temp2 = xgb_cla2.predict(X_train) 38 temp2_pro = xgb_cla2.predict_proba(X_train) 39 xgb_cla2.fit(X_train, y_train, eval_set=[(X_train, y_train), (X_test, y_test)], eval_metric=['error']) 40 41 xgb_cla2.fit(X_train, y_train, eval_set=[(X_train, y_train), (X_test, y_test)], eval_metric=metric_accuracy) 42 43 plt.figure() 44 plt.plot(xgb_cla2.evals_result()['validation_1']['Accuracy'], label='test') 45 plt.plot(xgb_cla2.evals_result()['validation_0']['Accuracy'], label='train') 46 47 plt.legend() 48 plt.grid(axis='both')
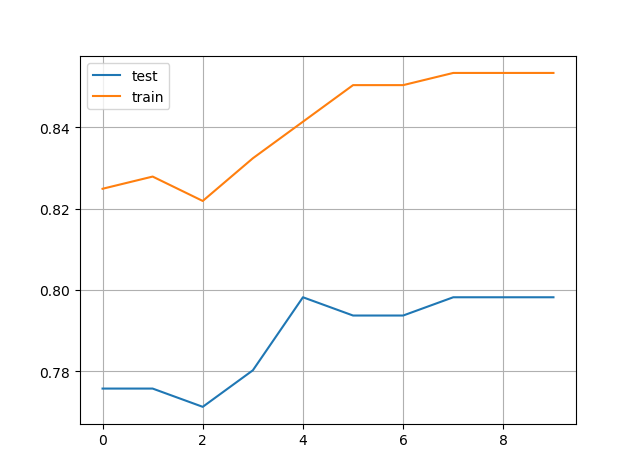
在训练集上,经过grid_search, n_estiamtors(sklearn api) / num_boost_round(learning api) 为5最优。可以发现在测试集上,同样是在5时取得最优解,后续 test_accuracy 不再提升,而 train_accuracy 进一步提升,逐渐过拟合。
4.2 结果分析:
和前几篇一样,将 XGBoost 的最优参数用于预测集,并将结果上传kaggle,结果如下(注这里的训练集只是全体训练集,包括代码中的 train 和 test):
可以看到其效果和AdaBoost、GBDT差不多,略差于RF(随机森林)。
|
训练集 accuracy |
训练集 precision |
训练集 recall |
预测集 accuracy(需上传kaggle获取结果) |
|
| 朴素贝叶斯最优解 | 0.790 | 0.731 | 0.716 | 0.756 |
| 感知机 | 0.771 | 0.694 | 0.722 | 0.722 |
| 逻辑回归 | 0.807 | 0.781 | 0.690 | 0.768 |
| 线性SVM | 0.801 | 0.772 | 0.684 | 0.773 |
| rbf核SVM | 0.834 | 0.817 | 0.731 | 0.785 |
| AdaBoost | 0.844 | 0.814 | 0.769 | 0.789 |
| GBDT | 0.843 | 0.877 | 0.687 | 0.778 |
| RF | 0.820 | 0.917 | 0.585 | 0.792 |
| XGBoost | 0.831 | 0.847 | 0.681 | 0.780 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号