
【机器学习实战】-- Titanic 数据集(6)-- Boosting提升 (AdaBoost、GDBT)
1. 写在前面:
本篇属于实战部分,更注重于算法在实际项目中的应用。如需对感知机算法本身有进一步的了解,可参考以下链接,在本人学习的过程中,起到了很大的帮助:
【1】统计学习方法 李航
【2】Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techiniques to Build Intelligent Systems
【3】sklearn Ensemble methods官方文档 https://scikit-learn.org/stable/modules/ensemble.html#
【4】集成学习之Adaboost算法原理小结 https://www.cnblogs.com/pinard/p/6133937.html
【5】梯度提升树(GBDT)原理小结 https://www.cnblogs.com/pinard/p/6140514.html
【6】梯度下降法和一阶泰勒展开的关系 https://zhuanlan.zhihu.com/p/82757193
2. 数据集:
数据集地址:https://www.kaggle.com/c/titanic
Titanic数据集是Kaggle上参与人数最多的项目之一。数据本身简单小巧,适合初学者上手,深入了解比较各个机器学习算法。
数据集包含11个变量:PassengerID、Pclass、Name、Sex、Age、SibSp、Parch、Ticket、Fare、Cabin、Embarked,通过这些数据来预测乘客在Titanic事故中是否幸存下来。
3. 算法简介:
和之前几篇不同,本篇介绍的不是某一个具体的算法,而是一种集合多个学习器来完成机器学习任务的方法,称为集成方法。正所谓"三个臭皮匠,顶过一个诸葛亮",结合了多个效果一般的学习器(即弱学习器),很有可能将会获得一个效果较好的学习器(强学习器)。集成学习主要有两大类:boosting和bagging。本篇将介绍的是boosting。
3.1 Boosting算法基本思路
Boosting算法泛指任何结合若干个弱学习器称为一个强学习器的集成算法。绝大部分Boosting算法的原理是依次训练各个预测器,每一个预测器都在其上一个的基础上进行改进。在众多Boosting算法中,最流行的是AdaBoost算法和Gradient Boosting。
3.2 AdaBoost算法简介
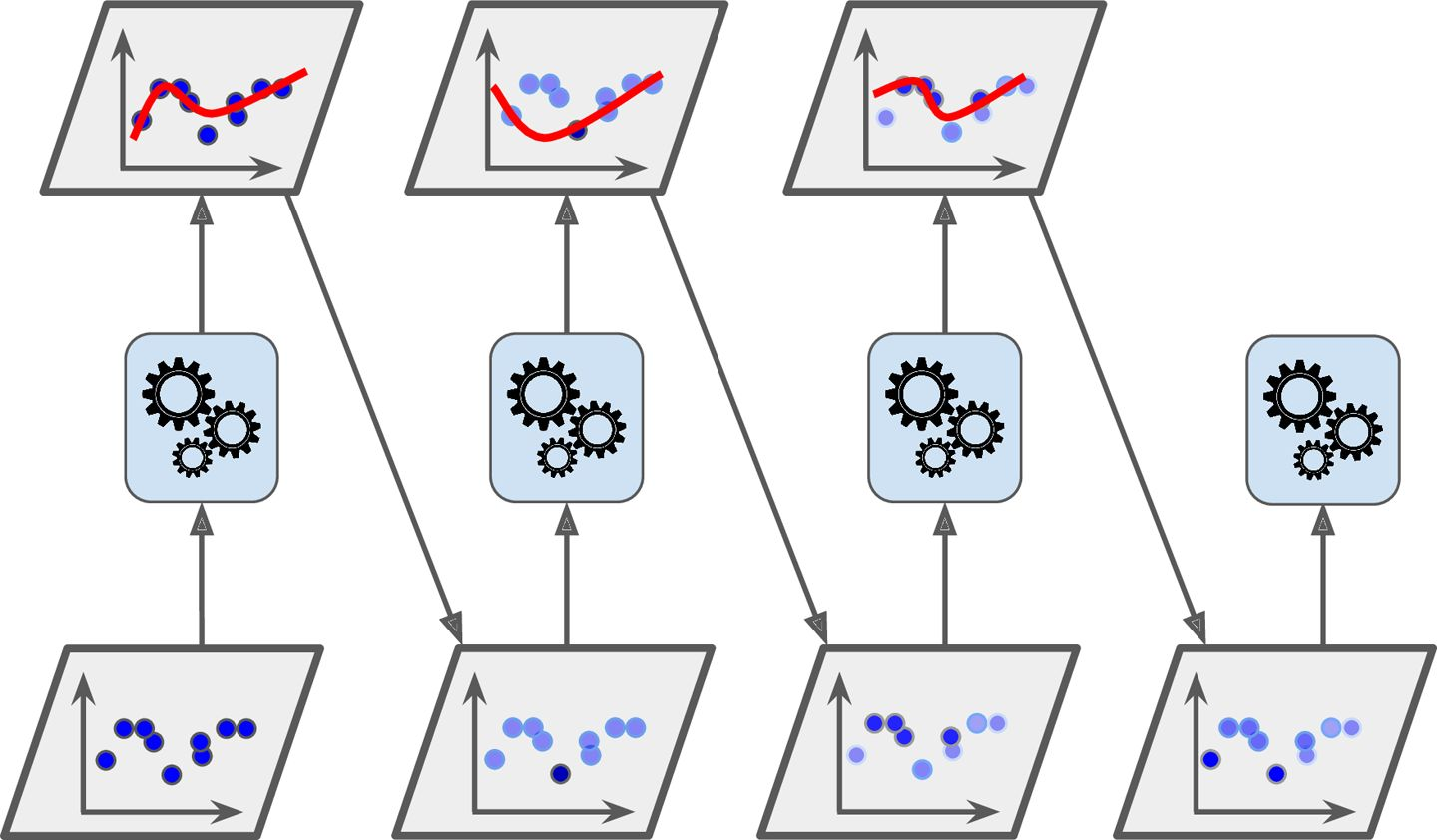
在依次训练各个预测器的过程中,如何根据上一个预测器来改进当前的预测器呢?AdaBoost算法的策略是更关注在上一个预测器中表现较差的样本,即提升这些样本的权重。当所有的预测器训练完成后,再通过一定的方式,结合所有训练器,获得最终的学习器。下面这个图就很好地体现了迭代更新的过程[2]:
介绍完整体思路,那么AdaBoost具体是如何提升样本的权重,又是如何集成(结合)弱学习器的呢?下面以简单的二分类算法进行介绍。
给定一个数据集:$T=\left \{ \left ( x_{1}, y_{1} \right ), \left ( x_{2}, y_{2} \right ), ..., \left ( x_{N}, y_{N} \right ) \right \}$,其中$x_{i}\in \mathcal{X} \subseteq \bf{R^{n}}$,$y_{i} \in \Upsilon= \left \{+1, -1 \right \}$,$i = 1,2,...,N$。这代表数据集共有 N 对 实例,每个实例 $x_{i}$都是n维的。
(1)初始化训练集的权值分布 $D_{1} = (w_{11}, w_{12}, ..., w_{1i}, ..., w_{1N}), \quad w_{1i} = \frac{1}{N}, \quad i=1,2,...,N$
(2)依次训练第$m$个弱学习器,$m=1,2,...,M$
-
- 根据权值分布$D_{m}$,学习训练数据集,得到弱分类器:
$$G_{m}(x): \mathcal{X} \rightarrow \{-1, +1\}$$
-
- 计算按当前弱学习器$G_{m}(x)$在训练数据集上的分类误差率:
$$ e_{m} = P(G_{m}(xi) \neq y_{i}) = \sum_{i=1}^{N} w_{mi} I( G_{m}(x_{i}) \neq y_{i} ) $$
-
- 计算当前弱学习器的系数(误差率越小,系数越大):
$$ \alpha_{m} = \frac{1}{2}\text{log}\frac{1-e_{m}}{e_{m}} $$
-
- 更新训练集的权值分布$D_{m+1}$,作为下一个弱学习器的学习训练数据集时的输入:
$$ D_{m+1} = (w_{m+1,1}, ..., w_{m+1, i}, ..., w_{m+1, N}) $$
$$ w_{m+1, i} = \frac{w_{mi}}{Z_{m}}\text{exp}( -\alpha_{m}y_{i}G_{m}(x_{i}) )$$
$$ Z_{m} = \sum_{i=1}^{N} w_{mi} \text{exp} (-\alpha_{m} y_{i} G_{m}(x_{i})) $$
(3)构建基本分类器的线性组合
$$ f(x) = \sum_{m=1}^{M} \alpha_{m}G_{m}(x) $$
$$ G(x) = \text{sign}(f(x)) = \text{sign} \left( \sum_{m=1}^{M} \alpha_{m}G_{m}(x) \right) $$
从使用算法的角度出发,只要记住权值分布更新的表达式,弱学习器的系数表达式即可。至于为什么权值分布的表达式和弱学习器系数的表达式是这样的呢?详细推导可参见[1], [4]。
简而言之,AdaBoost算法模型是模型为加法模型、损失函数为指数函数($L(y, f(x)) = \text{exp}\left [ -yf(x) \right ]$)、学习算法为前向分步算法时的二分类学习方法。指数损失函数的特性,决定了上述表达式的形式。
3.3 GBDT(Gradient Boosting Decision Tree)算法简介
和AdaBoost一样,GBDT也是使用加法模型,按序训练后,形成集成模型。但和AdaBoost不同的是,它并不是在每次迭代中调整样本的权重,而是尝试去拟合上一个预测器的残差。那么为什么需要GBDT呢?因为如果损失函数是指数函数(分类问题)或平方损失函数(回归问题),每一步的优化是很简单的,但是对于一般损失函数而言,优化并不容易,因此可以使用GBDT。但有一点需要注意的是,对于常用的GBDT而言,其弱学习器为 CART回归树,即便是对于分类问题而言,也是CART回归树,而不是CART分类树。这是因为每一步迭代,都是尝试去拟合残差,而残差是一个连续量。下面介绍以下用于回归问题的GBDT算法:
给定一个数据集:$T=\left \{ \left ( x_{1}, y_{1} \right ), \left ( x_{2}, y_{2} \right ), ..., \left ( x_{N}, y_{N} \right ) \right \}$,其中$x_{i}\in \mathcal{X} \subseteq \bf{R^{n}}$,$y_{i} \in \Upsilon= \left \{+1, -1 \right \}$,$i = 1,2,...,N$。这代表数据集共有 N 对 实例,每个实例 $x_{i}$都是n维的。
(1)初始化回归树:
$$ f_{0}(x) = \text{arg}\min_{c} \sum_{i=1}^{N} L(y_{i}, c) $$
(2)依次训练第$m$个弱学习器,$m=1,2,...,M$:
-
- 计算残差 $ r_{mi} = -\left [ \frac{\partial L(y_{i}, f(x_{i}))}{\partial f(x_{i})} \right ]_{f(x) = f_{m-1}(x)} $
- 对 $ (x1, r_{m1}, ..., (x_{i}, r_{mi}), ..., (x_N, r_{mN})), \quad i=1,2,...,N $,拟合CART回归树,得到第m颗树的叶结点区域$R_{mj}, \quad j = 1,2, ..., J$,及其回归值$C_{mj}$
- 更新 $ f_{m}(x) = f_{m-1}(x) + \sum_{j=1}^{J} c_{mj}I(x \in R_{mj}) $
(3)得到回归树
$$ \widehat{f}(x) = f_{M}(x) = \sum_{m=1}^{M}\sum_{j=1}^{J_{m}}c_{mj}I(x \in R_{mj}) $$
至于为什么使用梯度的形式来表示残差,可以参考[6],主要使用了一阶的泰勒展开式来近似。
4. 实战:
4.1 AdaBoost
我们在上一篇决策树的实战中,获得了单独使用决策树时的最佳参数。但是要注意的是,我们不能直接使用这些参数的决策树作为基学习器,因为我们是将若干个若学习器进行集成,如果本身已经是层数较多的学习器,会有较大过拟合的风险。


1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder, OrdinalEncoder 5 from sklearn.impute import SimpleImputer 6 from sklearn.model_selection import StratifiedKFold, GridSearchCV, train_test_split, cross_validate 7 from sklearn.pipeline import Pipeline, FeatureUnion 8 from sklearn.tree import DecisionTreeClassifier 9 from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier 10 from sklearn.metrics import accuracy_score, precision_score, recall_score 11 from sklearn.base import BaseEstimator, TransformerMixin 12 13 14 class DataFrameSelector(BaseEstimator, TransformerMixin): 15 def __init__(self, attribute_name): 16 self.attribute_name = attribute_name 17 18 def fit(self, x, y=None): 19 return self 20 21 def transform(self, x): 22 return x[self.attribute_name].values 23 24 25 # Load data 26 data = pd.read_csv('train.csv') 27 28 data_x = data.drop('Survived', axis=1) 29 data_y = data['Survived'] 30 31 # Data cleaning 32 cat_attribs = ['Pclass', 'Sex', 'Embarked'] 33 dis_attribs = ['SibSp', 'Parch'] 34 con_attribs = ['Age', 'Fare'] 35 36 # encoder: OneHotEncoder()、OrdinalEncoder() 37 cat_pipeline = Pipeline([ 38 ('selector', DataFrameSelector(cat_attribs)), 39 ('imputer', SimpleImputer(strategy='most_frequent')), 40 ('encoder', OneHotEncoder()), 41 ]) 42 43 dis_pipeline = Pipeline([ 44 ('selector', DataFrameSelector(dis_attribs)), 45 ('scaler', MinMaxScaler()), 46 ('imputer', SimpleImputer(strategy='most_frequent')), 47 ]) 48 49 con_pipeline = Pipeline([ 50 ('selector', DataFrameSelector(con_attribs)), 51 ('scaler', MinMaxScaler()), 52 ('imputer', SimpleImputer(strategy='mean')), 53 ]) 54 55 full_pipeline = FeatureUnion( 56 transformer_list=[ 57 ('con_pipeline', con_pipeline), 58 ('dis_pipeline', dis_pipeline), 59 ('cat_pipeline', cat_pipeline), 60 ] 61 ) 62 63 data_x_cleaned = full_pipeline.fit_transform(data_x) 64 65 X_train, X_test, y_train, y_test = train_test_split(data_x_cleaned, data_y, stratify=data_y, test_size=0.25, random_state=1992) 66 67 cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=2) 68 69 clf_stump = DecisionTreeClassifier(max_depth=1, criterion='entropy', class_weight='balanced', random_state=1992) 70 71 cv_results = cross_validate(clf_stump, X_train, y_train, cv=cv, return_train_score=True, return_estimator=True) 72 73 clf_stump.fit(X_train, y_train) 74 75 predicted_train_stump = clf_stump.predict(X_train) 76 predicted_test_stump = clf_stump.predict(X_test) 77 78 print('------------Stump: Results of train------------') 79 print(accuracy_score(y_train, predicted_train_stump)) 80 print(precision_score(y_train, predicted_train_stump)) 81 print(recall_score(y_train, predicted_train_stump)) 82 83 print('------------Stump: Results of test------------') 84 print(accuracy_score(y_test, predicted_test_stump)) 85 print(precision_score(y_test, predicted_test_stump)) 86 print(recall_score(y_test, predicted_test_stump)) 87 88 # adaboost 89 clf_base = DecisionTreeClassifier(criterion='entropy', class_weight='balanced', random_state=1992) 90 clf_ada = AdaBoostClassifier(clf_base, random_state=1992) 91 92 # param_grid = [{ 93 # 'base_estimator__max_depth': [1, 3, 5, 7], 94 # 'n_estimators': [5, 10, 25, 50], 95 # 'learning_rate': [0.1, 0.4, 0.7], 96 # 97 # }] 98 99 # final param_grid 100 param_grid = [{ 101 'base_estimator__max_features': [0.5, 0.6, 0.7, 0.8], 102 'base_estimator__min_samples_leaf': [2, 4, 8], 103 'base_estimator__min_samples_split': [8, 16, 32], 104 'base_estimator__max_depth': [3], 105 'n_estimators': [5, 25, 50], 106 'learning_rate': [0.01, 0.05, 0.1], 107 }] 108 109 grid_search = GridSearchCV(clf_ada, param_grid=param_grid, cv=cv, scoring='accuracy', n_jobs=-1, return_train_score=True) 110 grid_search.fit(X_train, y_train) 111 cv_results_grid_search = pd.DataFrame(grid_search.cv_results_).sort_values(by='rank_test_score') 112 113 predicted_train_ada = grid_search.predict(X_train) 114 predicted_test_ada = grid_search.predict(X_test) 115 116 print('------------Ada grid_search: Results of train------------') 117 print(accuracy_score(y_train, predicted_train_ada)) 118 print(precision_score(y_train, predicted_train_ada)) 119 print(recall_score(y_train, predicted_train_ada)) 120 121 print('------------Ada grid search: Results of test------------') 122 print(accuracy_score(y_test, predicted_test_ada)) 123 print(precision_score(y_test, predicted_test_ada)) 124 print(recall_score(y_test, predicted_test_ada)) 125 126 clf_ada_grid_search = grid_search.best_estimator_ 127 cv_results2 = cross_validate(clf_ada_grid_search, X_train, y_train, cv=cv, return_train_score=True, return_estimator=True) 128 129 130 def plot_staged_accuracy_estimator(X_train, X_test, y_train, y_test, estimator): 131 n_instances_train = X_train.shape[0] 132 n_instances_test = X_test.shape[0] 133 134 n_estimators = estimator.n_estimators 135 136 staged_score_train = estimator.staged_score(X_train, y_train) 137 staged_score_test = estimator.staged_score(X_test, y_test) 138 139 plt.figure() 140 plt.plot(list(staged_score_test), label='test') 141 plt.plot(list(staged_score_train), label='train') 142 143 plt.legend() 144 plt.grid(axis='both') 145 146 147 # clf_ada_chosen = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1, criterion='entropy', class_weight='balanced', random_state=1992), n_estimators=3, learning_rate=0.6, random_state=1992) 148 # clf_ada_chosen.fit(X_train, y_train) 149 # cv_results3 = cross_validate(clf_ada_chosen, X_train, y_train, cv=cv, return_train_score=True, return_estimator=True) 150 151 plot_staged_accuracy_estimator(X_train, X_test, y_train, y_test, clf_ada_grid_search) 152 153 154 # 导入预测数据,预测结果,并生成csv文件 155 data_test = pd.read_csv('test.csv') 156 submission = pd.DataFrame(columns=['PassengerId', 'Survived']) 157 submission['PassengerId'] = data_test['PassengerId'] 158 159 test_x_cleaned = full_pipeline.fit_transform(data_test) 160 161 submission_AdaboostTree = pd.DataFrame(submission, copy=True) 162 163 grid_search.best_estimator_.fit(data_x_cleaned, data_y) 164 submission_AdaboostTree['Survived'] = pd.Series(grid_search.best_estimator_.predict(test_x_cleaned)) 165 166 # submission_AdaboostTree['Survived'] = pd.Series(grid_search.predict(test_x_cleaned)) 167 168 submission_AdaboostTree.to_csv('submission_AdaboostTree_max_depth3_final_with_valid.csv', index=False)
首先,和前几个方法不同的是,我们引入了验证集:
- 我们首先将训练数据集拆分成了训练集(代码中的train)和测试集(代码中的test),在训练集上进行网格搜索,确认超参数。
- 其次,在训练集上训练完成后,在测试集上验证泛化效果
- 最后,在效果达到要求的情况下,利用训练完的模型,对完整的训练数据集进行学习(这一步超参数已定,学习过程中仅就该模型的参数,如权重分布等)
在第2步中,我们如何验证训练集和验证集的效果呢?利用 sklearn 中 AdaBoostClassifier 类的方法,我们可以把前进分步过程中,每一步的预测器的结果分别对训练集和验证集进行输出:
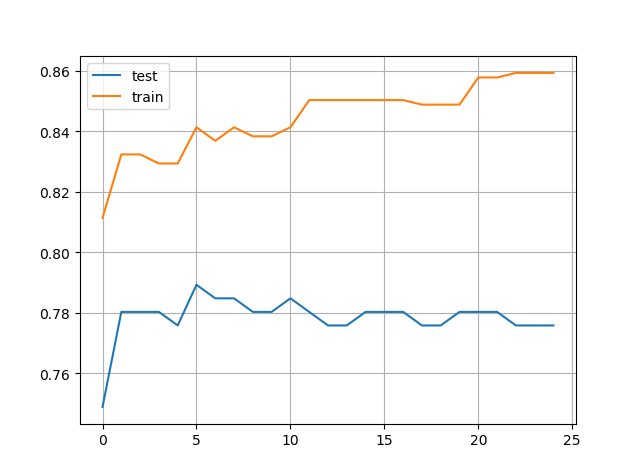
可以看到随着弱学习器的增加,accuracy在初期有一定提升,后续是一个平稳状态,在训练集中也没有出现明显的过拟合现象。
4.2 GBDT
类似AdaBoost,使用 sklearn 中 GradientBoostingClassifer 类对数据集进行学习,同样拆分成训练集和测试集。
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder, OrdinalEncoder 5 from sklearn.impute import SimpleImputer 6 from sklearn.model_selection import StratifiedKFold, GridSearchCV, train_test_split, cross_validate 7 from sklearn.pipeline import Pipeline, FeatureUnion 8 from sklearn.tree import DecisionTreeClassifier 9 from sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier 10 from sklearn.metrics import accuracy_score, precision_score, recall_score 11 from sklearn.base import BaseEstimator, TransformerMixin 12 13 14 class DataFrameSelector(BaseEstimator, TransformerMixin): 15 def __init__(self, attribute_name): 16 self.attribute_name = attribute_name 17 18 def fit(self, x, y=None): 19 return self 20 21 def transform(self, x): 22 return x[self.attribute_name].values 23 24 25 # Load data 26 data = pd.read_csv('train.csv') 27 28 data_x = data.drop('Survived', axis=1) 29 data_y = data['Survived'] 30 31 # Data cleaning 32 cat_attribs = ['Pclass', 'Sex', 'Embarked'] 33 dis_attribs = ['SibSp', 'Parch'] 34 con_attribs = ['Age', 'Fare'] 35 36 # encoder: OneHotEncoder()、OrdinalEncoder() 37 cat_pipeline = Pipeline([ 38 ('selector', DataFrameSelector(cat_attribs)), 39 ('imputer', SimpleImputer(strategy='most_frequent')), 40 ('encoder', OneHotEncoder()), 41 ]) 42 43 dis_pipeline = Pipeline([ 44 ('selector', DataFrameSelector(dis_attribs)), 45 ('scaler', MinMaxScaler()), 46 ('imputer', SimpleImputer(strategy='most_frequent')), 47 ]) 48 49 con_pipeline = Pipeline([ 50 ('selector', DataFrameSelector(con_attribs)), 51 ('scaler', MinMaxScaler()), 52 ('imputer', SimpleImputer(strategy='mean')), 53 ]) 54 55 full_pipeline = FeatureUnion( 56 transformer_list=[ 57 ('con_pipeline', con_pipeline), 58 ('dis_pipeline', dis_pipeline), 59 ('cat_pipeline', cat_pipeline), 60 ] 61 ) 62 63 data_x_cleaned = full_pipeline.fit_transform(data_x) 64 65 X_train, X_test, y_train, y_test = train_test_split(data_x_cleaned, data_y, stratify=data_y, test_size=0.25, random_state=1992) 66 67 cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=2) 68 69 clf_stump = DecisionTreeClassifier(max_depth=1, criterion='entropy', class_weight='balanced', random_state=1992) 70 71 cv_results = cross_validate(clf_stump, X_train, y_train, cv=cv, return_train_score=True, return_estimator=True) 72 73 clf_stump.fit(X_train, y_train) 74 75 predicted_train_stump = clf_stump.predict(X_train) 76 predicted_test_stump = clf_stump.predict(X_test) 77 78 print('------------Stump: Results of train------------') 79 print(accuracy_score(y_train, predicted_train_stump)) 80 print(precision_score(y_train, predicted_train_stump)) 81 print(recall_score(y_train, predicted_train_stump)) 82 83 print('------------Stump: Results of test------------') 84 print(accuracy_score(y_test, predicted_test_stump)) 85 print(precision_score(y_test, predicted_test_stump)) 86 print(recall_score(y_test, predicted_test_stump)) 87 88 # gbdt 89 clf_gbdt = GradientBoostingClassifier(random_state=1992) 90 91 # param_grid = [{ 92 # 'base_estimator__max_depth': [1, 3, 5, 7], 93 # 'n_estimators': [5, 10, 25, 50], 94 # 'learning_rate': [0.1, 0.4, 0.7], 95 # 96 # }] 97 98 # final param_grid 99 param_grid = [{ 100 'max_features': [0.8], 101 'min_samples_split': [2, 4, 8, 16], 102 'min_samples_leaf': [1, 2, 4, 8], 103 'max_depth': [3], 104 'n_estimators': [25], 105 'learning_rate': [0.01, 0.05, 0.1], 106 }] 107 108 grid_search = GridSearchCV(clf_gbdt, param_grid=param_grid, cv=cv, scoring='accuracy', n_jobs=-1, return_train_score=True) 109 grid_search.fit(X_train, y_train) 110 cv_results_grid_search = pd.DataFrame(grid_search.cv_results_).sort_values(by='rank_test_score') 111 112 predicted_train_ada = grid_search.predict(X_train) 113 predicted_test_ada = grid_search.predict(X_test) 114 115 print('------------GBDT grid_search: Results of train------------') 116 print(accuracy_score(y_train, predicted_train_ada)) 117 print(precision_score(y_train, predicted_train_ada)) 118 print(recall_score(y_train, predicted_train_ada)) 119 120 print('------------GBDT grid search: Results of test------------') 121 print(accuracy_score(y_test, predicted_test_ada)) 122 print(precision_score(y_test, predicted_test_ada)) 123 print(recall_score(y_test, predicted_test_ada)) 124 125 clf_gbdt_grid_search = grid_search.best_estimator_ 126 cv_results2 = cross_validate(clf_gbdt_grid_search, X_train, y_train, cv=cv, return_train_score=True, return_estimator=True) 127 128 129 def plot_staged_accuracy_estimator(X_train, X_test, y_train, y_test, estimator): 130 n_instances_train = X_train.shape[0] 131 n_instances_test = X_test.shape[0] 132 133 score_train = [] 134 score_test = [] 135 136 n_estimators = estimator.n_estimators 137 138 for i, score in enumerate(estimator.staged_predict(X_train)): 139 score_train.append( accuracy_score(y_train, score) ) 140 141 for i, score in enumerate(estimator.staged_predict(X_test)): 142 score_test.append( accuracy_score(y_test, score) ) 143 144 plt.figure() 145 plt.plot(score_test, label='test') 146 plt.plot(score_train, label='train') 147 148 plt.legend() 149 plt.grid(axis='both') 150 151 152 plot_staged_accuracy_estimator(X_train, X_test, y_train, y_test, clf_gbdt_grid_search) 153 154 155 # 导入预测数据,预测结果,并生成csv文件 156 data_test = pd.read_csv('test.csv') 157 submission = pd.DataFrame(columns=['PassengerId', 'Survived']) 158 submission['PassengerId'] = data_test['PassengerId'] 159 160 test_x_cleaned = full_pipeline.fit_transform(data_test) 161 162 submission_AdaboostTree = pd.DataFrame(submission, copy=True) 163 164 grid_search.best_estimator_.fit(data_x_cleaned, data_y) 165 submission_AdaboostTree['Survived'] = pd.Series(grid_search.best_estimator_.predict(test_x_cleaned)) 166 167 # submission_AdaboostTree['Survived'] = pd.Series(grid_search.predict(test_x_cleaned)) 168 169 submission_AdaboostTree.to_csv('submission_GBDTTree_max_depth3_test_with_valid.csv', index=False)
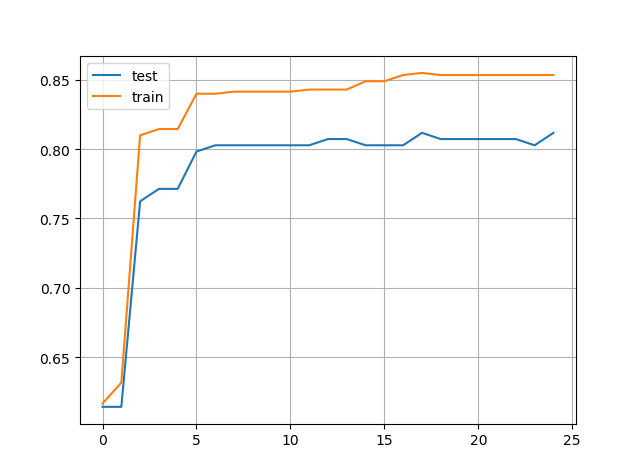
由上图可以看到,在此超参数下,对过拟合的控制比较好。
4.3 结果分析
和前几篇一样,分别将 AdaBoostClassifier 和 GradientBoostingClassifer 的最优参数用于预测集,并将结果上传kaggle,结果如下(注这里的训练集只是全体训练集,包括上一节提到的 train 和 test):
|
训练集 accuracy |
训练集 precision |
训练集 recall |
预测集 accuracy(需上传kaggle获取结果) |
|
| 朴素贝叶斯最优解 | 0.790 | 0.731 | 0.716 | 0.756 |
| 感知机 | 0.771 | 0.694 | 0.722 | 0.722 |
| 逻辑回归 | 0.807 | 0.781 | 0.690 | 0.768 |
| 线性SVM | 0.801 | 0.772 | 0.684 | 0.773 |
| rbf核SVM | 0.834 | 0.817 | 0.731 | 0.785 |
| AdaBoost | 0.844 | 0.814 | 0.769 | 0.789 |
| GBDT | 0.843 | 0.877 | 0.687 | 0.778 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号