


团队作业2-《需求规格说明书》
团队作业2-《需求规格说明书》
| 这个作业属于哪个课程 | 计科23级12班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 确定团队要做怎样的系统,通过需求分析形成需求规格说明书 |
仓库链接:KnowHub
队名与队员:
MCoder,Manage Code & Organize Development EffoRt
王宥程-3123004714
关健佳-3121004072
高泽彤-3123004304
黎火坤-3123004310
翁广驰-3123004409
王怡欧-3223004344
1. 需求规格说明书(25 + 0~5)
项目:本地知识库问答系统(RAG + LLM)
1.1 项目概述
- 一句话描述:外挂"第二大脑"的智能问答助手
- 本系统是一个面向本地文档与政策知识的检索增强生成(RAG)问答平台,支持知识库管理、智能问答、流式输出、反馈与会话记忆,并提供图片理解与Prompt设置。
- 架构:前端
Streamlit/React/Vue,后端FastAPI,数据库 SQLite/Mysql,向量存储Milvus,模型接口OpenAI兼容API。 - 运行入口:
run.py(python run.py backend/python run.py frontend)。后端服务由uvicorn启动,前端通过streamlit/react/vue渲染。
1.2 面向用户分析(Persona & 使用场景)
- 政策解读人员:需要快速检索法规条文并生成可读性强的解释性回答。
- 企业法务/运营人员:针对具体业务问题(补偿标准、权利变更)进行查询并留存问答记录。
- 普通用户/公众咨询:提出自然语言问题,获得与本地知识相关的可靠答案。
- 系统管理员/知识维护者:导入PDF、人工编辑分块、维护知识库条目,配置Prompt与会话清理。
1.3 功能性需求
- 知识库管理(CRUD):
POST/GET/PUT/DELETE /knowledge,条目含title/content/category。 - 智能问答:
POST /qa/ask返回QAResult(含检索到的知识与相似度)。 - 流式回答:
POST /qa/ask-stream按字符流返回,提升交互体验。 - 图片理解:
POST /qa/ask-image,支持UploadFile图片+问题生成答案。 - 反馈机制:
POST /qa/feedback点赞/点踩+评论;用于迭代优化。 - 会话管理:
GET /sessions、创建/清空会话(前端按钮操作),基于LangChain SQLChatMessageHistory。 - Prompt设置:
GET/PUT /settings/prompt,后端持久化system_prompt/answer_prompt。 - PDF解析与分块导入:
knowledge_service.import_chunks支持人工编辑后批量导入。
1.4 非功能性需求(质量属性)
- 性能:RAG检索Top-K=5;流式输出减少主观等待;Milvus向量索引(HNSW/IVF)保障检索效率。
- 可靠性:SQLite事务提交;服务初始化
Base.metadata.create_all(bind=engine)自动建表。 - 可用性:前端三栏布局、状态提示与错误处理;支持Prompt动态调整。
- 安全性:API密钥与Base URL经环境变量注入(
Config),避免硬编码泄露。 - 可维护性:后端服务分层清晰(
qa_service/knowledge_service/embedding_service/...)。 - 可扩展性:向量存储使用Milvus,易替换为Faiss、Pinecone;模型接口兼容。
1.5 技术需求(技术栈与依赖)
- 后端:
FastAPI、uvicorn、SQLAlchemy、pydantic v2、openai>=1.0.0、httpx。 - 前端:
Streamlit/React/Vue。 - 数据库:
SQLite(Config.DATABASE_URL),会话记忆复用同一库。 - 向量存储:
Milvus(pymilvus>=2.4.0),集合维度校验、索引创建、Top-K检索。 - 文档处理:
pdfplumber(PDF分块与清洗)。
1.6 系统架构(模块与职责)
main.py:API路由与依赖注入;初始化KnowledgeService/QAService/SettingsService/MemoryService。qa_service.py:问答流程编排:检索→上下文构建→调用LLM→记录QARecord→返回QAResult。knowledge_service.py:知识条目CRUD、PDF分块导入、Milvus索引(插入/更新/删除/搜索)。embedding_service.py:Embedding生成(OpenAI兼容接口,模型可配)。vector_store.py:Milvus集合管理、索引创建、插入/删除/Top-K检索。settings_service.py:Prompt设置的持久化(AppSetting)。memory_service.py:会话记忆(LangChain SQLChatMessageHistory)。frontend.py:三页签UI(问答/知识库管理/系统信息),流式展示与操作入口。
1.7 关键数据流(RAG链路)
- 用户提交问题(或图片+问题)。
EmbeddingService.get_embedding(query)生成查询向量。MilvusVectorStore.search(query_embedding, top_k=5)返回候选条目ID+相似度。KnowledgeService读取条目,QAService组装上下文。- 通过
openai客户端调用文本/图像模型生成答案,过程日志入库。 - 返回
QAResult(含retrieved_knowledges与similarity)。
1.8 主要API(节选)
POST /knowledge/|GET /knowledge/|GET /knowledge/{id}|PUT /knowledge/{id}|DELETE /knowledge/{id}POST /qa/ask|POST /qa/ask-stream|POST /qa/ask-image|POST /qa/feedbackGET /sessions(前端使用)|GET/PUT /settings/prompt
期望:需求描述详尽,包含用户分析、功能与非功能、技术与数据流、分包/API初步设计,具备加分条件(+5)依据。
2. 预期用户数量(3)
- 预期用户数量:
300(初期活跃用户)(本地大模型显存消耗大)。 - 依据:面向校内试点,日活300可支撑问答与知识维护;峰值并发约
30(10% 并发系数)。
3. 真实性・可用性・价值(2×3)
| 维度 | 说明 |
|---|---|
| 真实性 | 技术成熟可靠,目标明确,符合校内使用场景,完全可落地 |
| 可用性 | 流式输出、会话管理、Prompt设置、反馈机制、PDF导入 |
| 价值 | 为学校专有知识建立可检索问答入口,降低学习与解读成本 |
4. 团队项目github链接(3)
Link-> KnowHub
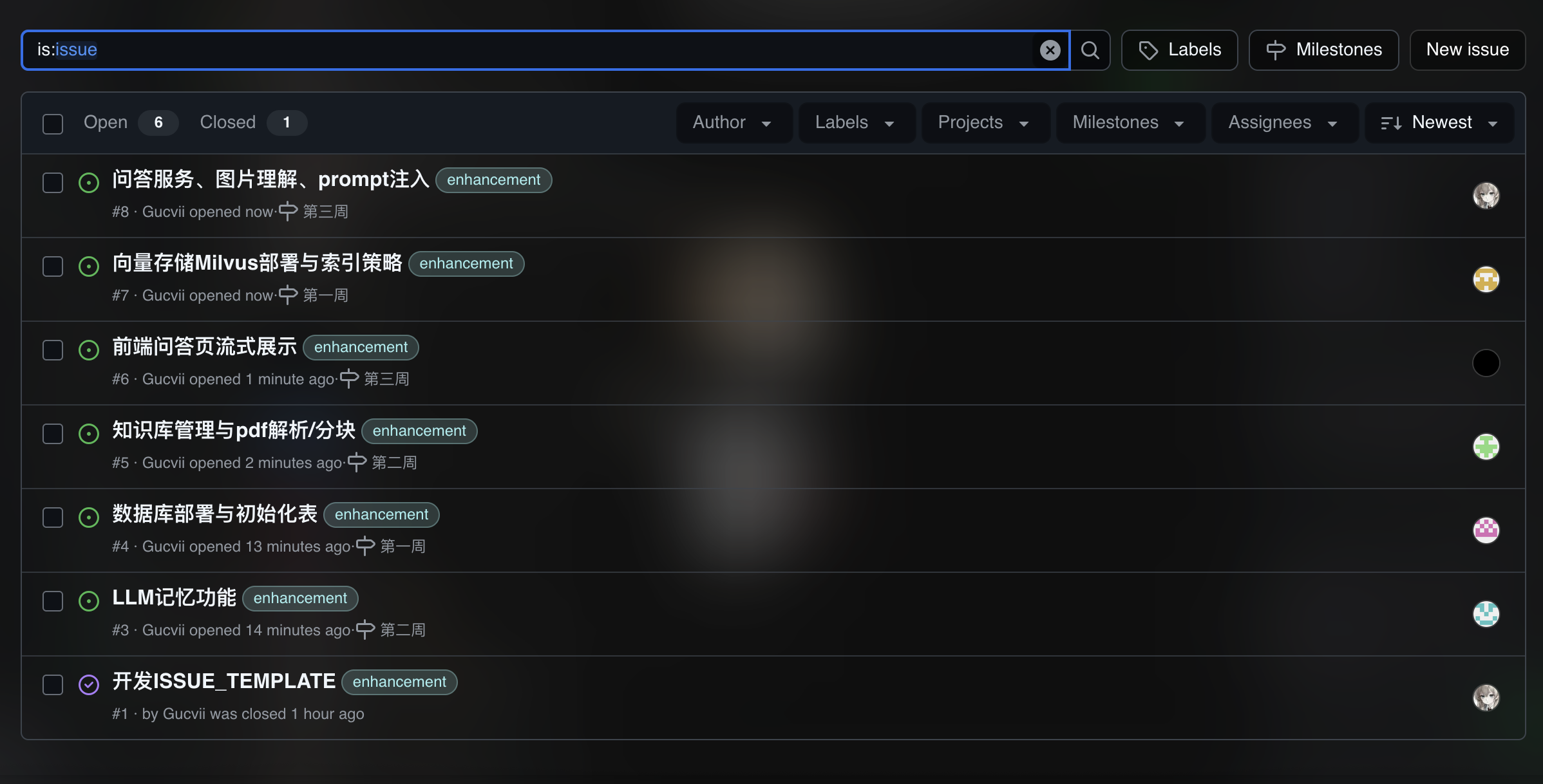
5. 团队分工、计划与 Issues(5+5)
-
规划:将以下任务分解为
Gitee Issues,并设置负责人、里程碑与标签。 -
建议 Issues 列表:
- 数据库部署与初始化表(负责人:高泽彤)
- 向量存储Milvus部署与索引策略(负责人:关健佳)
- 知识库管理与pdf解析/分块(负责人:王怡欧)
- LLM记忆功能(负责人:黎火坤)
- 问答服务、图片理解、prompt注入(负责人:翁广驰)
- 前端问答页流式展示(负责人:王宥程)
6. 博客中提供 Issues 截图(2)
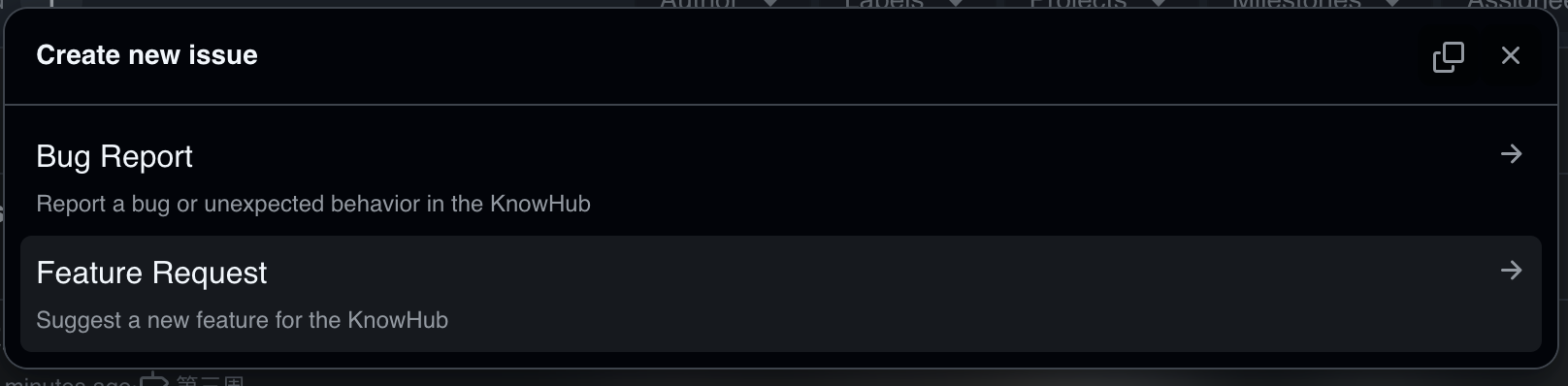
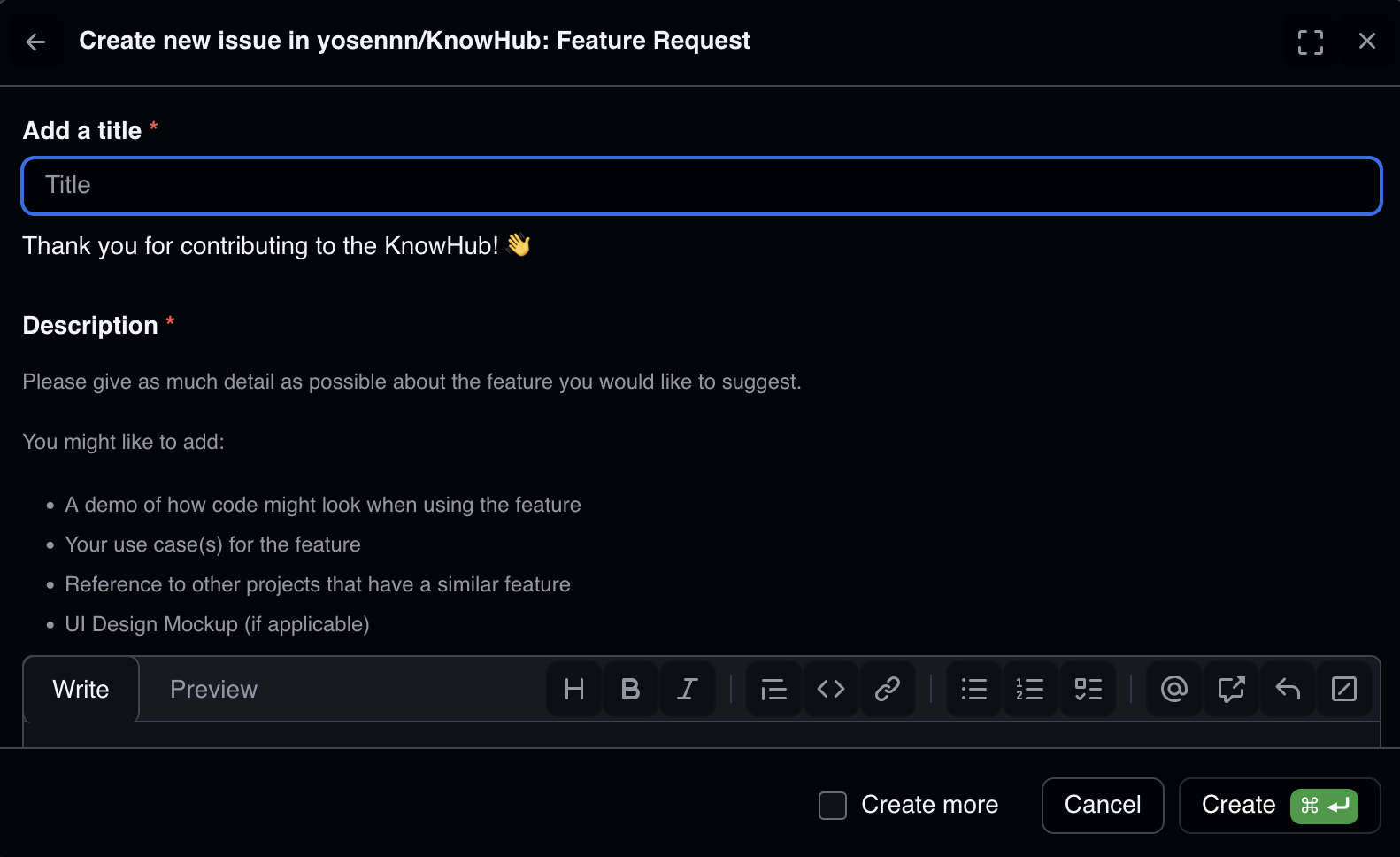
-
添加了 issue template,可以规范地提交 issue
![截屏2025-11-12 19.44.37]()
![截屏2025-11-12 19.44.43]()
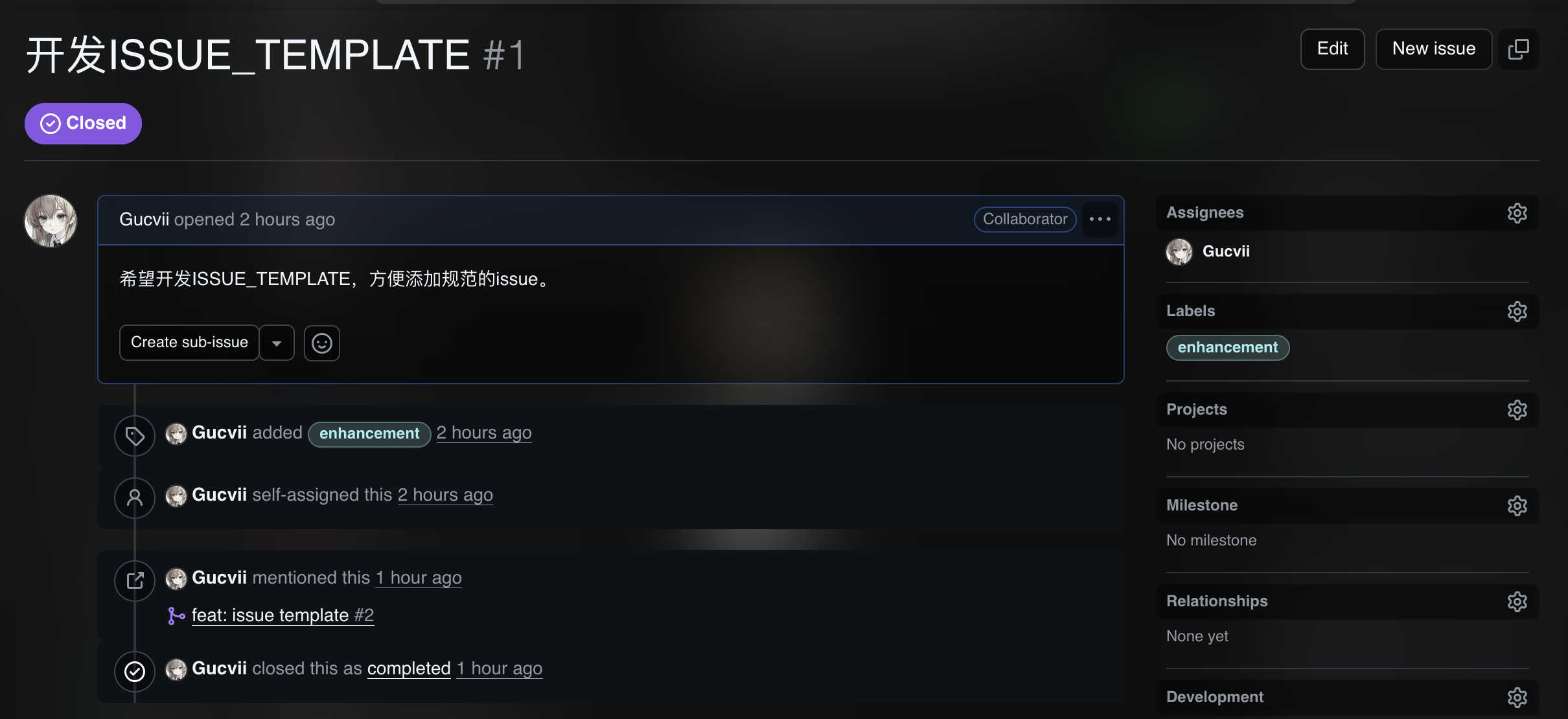
-
团队协作流程,因为是小团队,所以只开了main和feat开发分支(每个feat开一个feat分支),开发review完可以合并到main分支
![截屏2025-11-12 19.40.54]()
![截屏2025-11-12 19.41.05]()
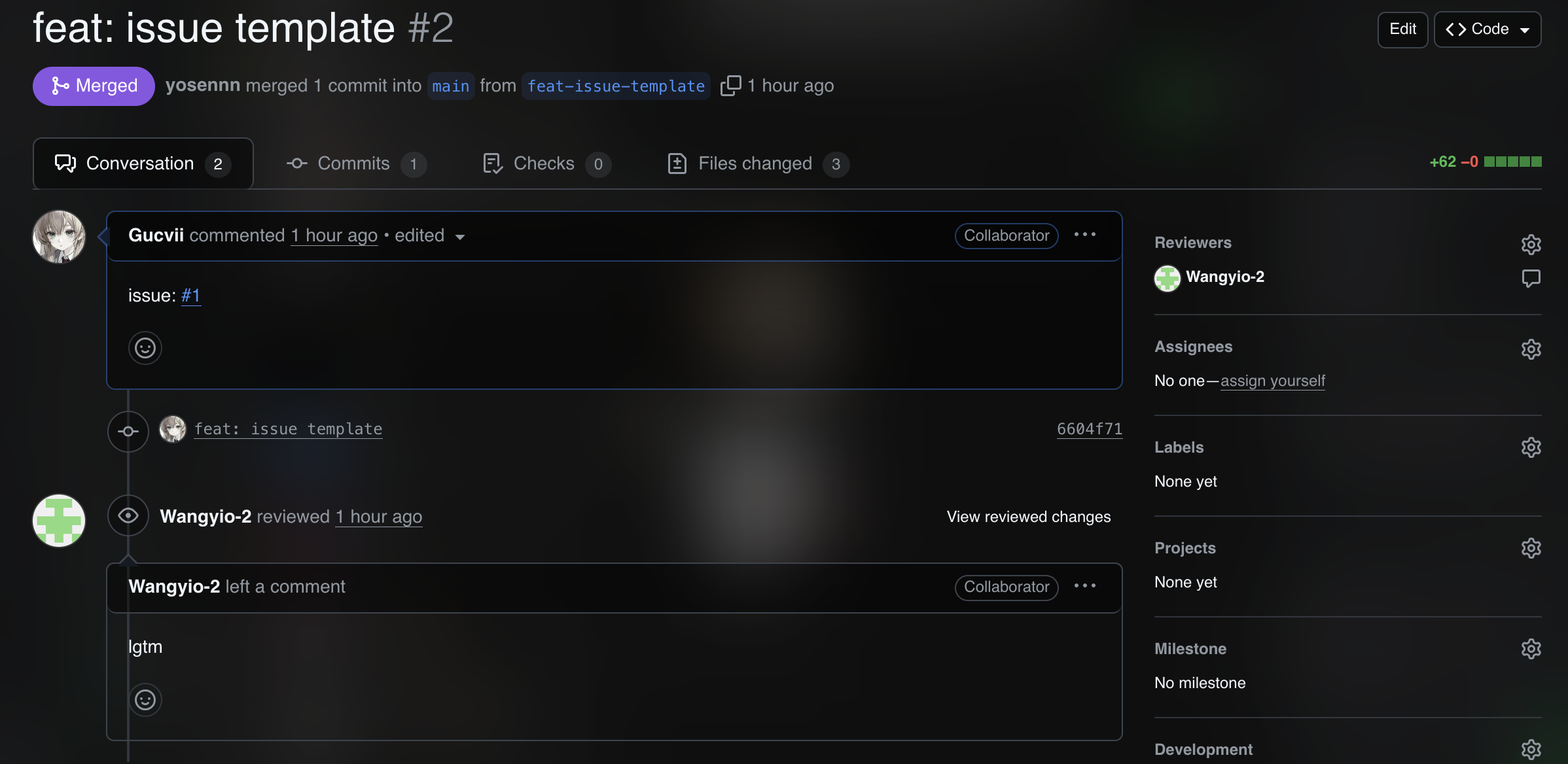
-
milestone制定,issue设定与指派
![截屏2025-11-12 19.17.36]()
![截屏2025-11-12 19.40.28]()
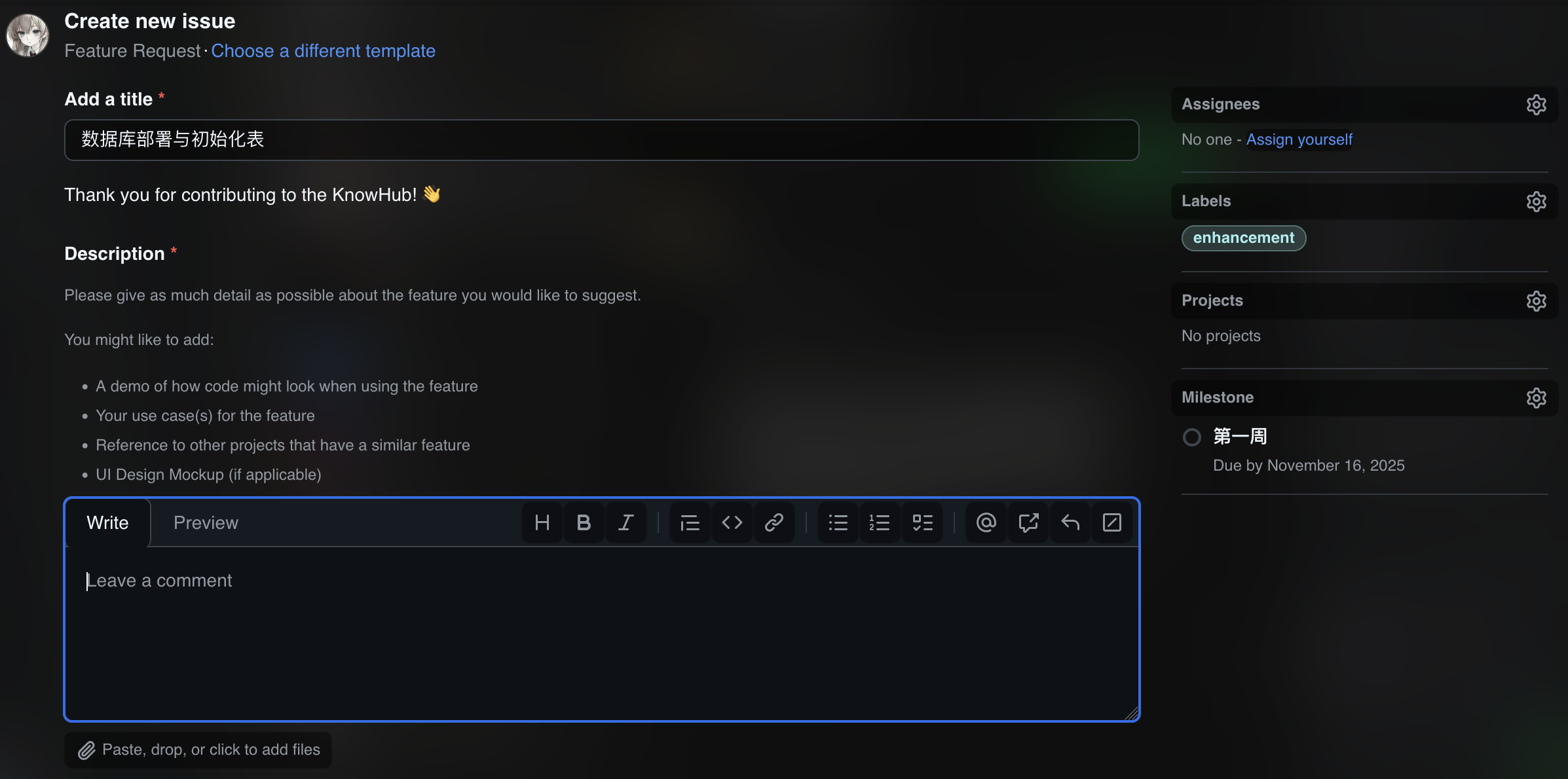
7. 项目时间安排表(8)
7.1 原有安排(3)
| 阶段 | 任务 | 时长(天) | 交付物 |
|---|---|---|---|
| 需求&设计 | 明确功能、API、数据流 | 3 | SRS & API草案 |
| 后端开发 | 路由、服务层、DB/向量存储 | 6 | 可运行的API服务 |
| 前端开发 | 问答页、知识库管理、系统页 | 4 | 三页签UI,流式输出 |
| 算法/数据 | Embedding/Milvus部署与调优 | 4 | 索引与Top-K检索稳定 |
| 联调与测试 | 功能回归、性能与异常处理 | 3 | 测试报告、问题单 |
| 文档与交付 | README/部署/使用说明 | 2 | 文档与演示 |
合计:22 天。
7.2 校正后的安排(3)
- 基于风险与不确定性进行校正:
阶段 原时长 校正后时长 备注 需求&设计 3 3 明确且稳定 后端开发 6 7 增加异常与会话管理细节 前端开发 4 5 流式输出与状态管理复杂度上调 算法/数据 4 6 Milvus索引与维度兼容性风险 联调与测试 3 4 端到端流式与图片问答覆盖 文档与交付 2 2 无变化
校正后合计:27 天。
7.3 矫正计算方法(2)
- 采用 PERT 三点估算:
E = (a + 4m + b) / 6(a=乐观、m=最可能、b=悲观)。 - 风险系数R引入:
E' = E × (1 + R);Milvus集成R=0.25,原E=4,则E'≈5。 - 燃尽图校正:每日报告实际完成量(EV)与计划量(PV),若
EV/PV < 0.8连续两日,则对后续阶段+20%缓冲。
8. 每个人完成的情况(2)
- 王宥程:完成前端UI的画稿设计
- 翁广驰:设计了API草案
- 关健佳:初步完成milvus的部署
- 黎火坤:完成LLM记忆方案
- 高泽彤:完成数据库表设计
- 王怡欧:完成PDF解析库的调研
9. 每个人的感想(10)
- 王宥程:第一次做大项目,才知道前端不是“画皮”,而是“读心术”:一句一句蹦字,得猜用户下一秒想问啥;切会话像换电视频道,线不能断。跟后端吵完才懂,数据不骗人;大家一起填坑,代码才写得像人话
- 翁广驰:很开心和大家一起合作~
- 黎火坤:在本次项目中,我主要负责为LLM打造“记忆功能”。这不仅仅是一个技术模块,更像是为模型注入灵魂的尝试。通过项目,懂得了需要学习怎么记住对话历史、理解上下文,甚至要洞察用户偏好,才能打造一个更好的产品。
- 高泽彤:第一次搞数据库,发现建表就像给系统搭积木。每个字段都是我们讨论出来的,这个存用户名,那个存时间。外键就是把不同表的数据连起来,索引是为了查得快。当测试数据在各个表之间顺利跑通的时候,我突然懂了:我们这不只是在写代码,是在给电脑建立一套它能理解的记忆方式。那些加班争论字段该多长、数据怎么关联的日子,现在看都值了——这套记忆方式能让我们的LLM真正活起来。
- 关健佳:数据库优化和不优化性能差一截!
- 王怡欧:这是我第一次参与团队合作项目,负责知识库管理与PDF解析模块,既要考虑文本解析的准确性,又要与其他成员的模块接口对接。刚开始有些不适应和紧张,但在不断沟通和调整中摸清了流程,遇到问题大家一起想办法,解决后那种成就感特别棒。这次经历让我更清楚地认识到合作比单打独斗更高效,也让我更敢于去尝试和承担。
10. 真实性与代码锚点附录
- 入口:
run.py(后端:uvicorn main:app;前端:streamlit run frontend.py)。 - API:
main.py(/knowledge、/qa/ask、/qa/ask-stream、/qa/ask-image、/qa/feedback、/settings/prompt)。 - 服务:
qa_service.py(检索/上下文/生成/记录)、knowledge_service.py(CRUD/索引)、embedding_service.py、vector_store.py。 - 数据:
models.py(Knowledge/QARecord/AppSetting)、schemas.py(请求与返回模型)。 - 会话记忆:
memory_service.py(SQLChatMessageHistory)。
评分点对照(便于老师您核验)
- 需求规格说明书(详尽,含用户/功能/非功能/技术/架构/数据流/主要API)
- 预期用户数量(明确数值:300)
- 真实性/可用性/价值(表格说明)
- 码云链接(KnowHub)
- 团队计划(Issues列表)
- 时间安排(原有vs校正)
- 排版(标题/分节/表格/提示)
- 团队分工/完成情况/个人感想

 浙公网安备 33010602011771号
浙公网安备 33010602011771号