【论文笔记 - pix2pix】Image-to-Image Translation With Conditional Adversarial Networks
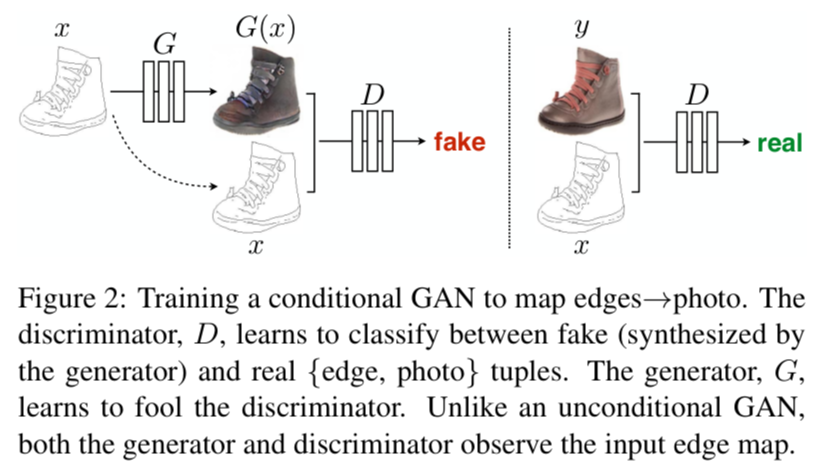 Pix2pix是用cGANs做image translation的鼻祖,image translation是从输入图像像素到输出图像像素的映射,通常用CNN卷积神经网络来缩小欧式距离,但这会导致输出图像的模糊问题,pix2pix提出了利用cGANs解决这类问题的通法。
Pix2pix是用cGANs做image translation的鼻祖,image translation是从输入图像像素到输出图像像素的映射,通常用CNN卷积神经网络来缩小欧式距离,但这会导致输出图像的模糊问题,pix2pix提出了利用cGANs解决这类问题的通法。
pix2pix:Image-to-Image Translation With Conditional Adversarial Networks——基于条件式生成网络(cGANs)的图像迁移,论文发表于2017年的CVPR。
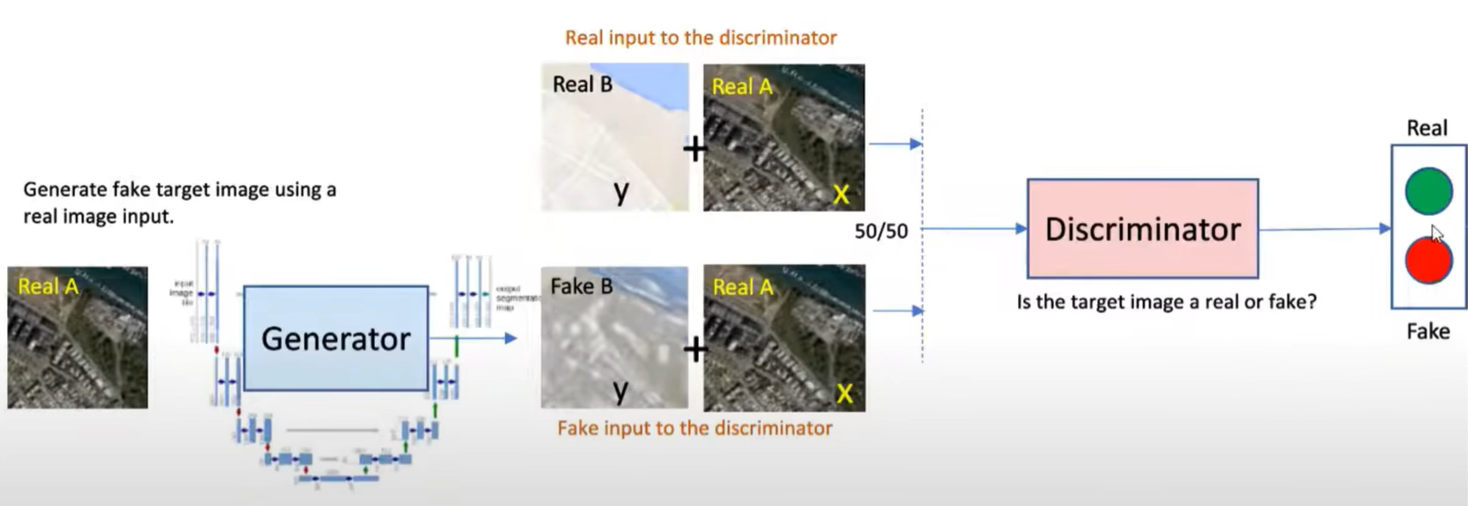
在pix2pix的cGANs中,生成器不光要输入一个噪声,还要输入一个图像。判别器需要判断这一对图像整体是否是真的,因此可以使得生成的图像既像真的,也要和输入的标签(图像、线稿等)相吻合。生成器使用UNet,这种网络结构既可以得到图像的底层信息(如边缘、转角、轮廓、斑块等),又可以得到高层的语义特征(如眼睛、车轮等)。判别器的目标是结合标签进行判别,如下图所示,判别器对于真地图+真照片应当输出“真”,而对于假地图+真照片应当输出“假”。生成器和判别器不断对抗训练、共同进化,最终达到纳什均衡。
源代码与预训练模型在Github上(预训练模型和Github上的代码是配套的,博客里模型已经做过了修改,所以预训练模型没法直接套上去了。。坐等考上研究生后有好显卡训练🤔)
Resources and papers
Image-to-Image Translation With Conditional Adversarial Networks
Pix2Pix implementation from scratch
Read-through
Abstract
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
论文提出的框架能够学习到图像输入到输出的映射,而且可以把GAN当做一种“损失函数”,这种损失函数可以自适应要解决的问题。与以往CNN不同的是,利用GAN不需要调参(without the need for parameter tweaking),不再需要手工设计映射函数(no longer hand-engineer our mapping functions)和损失函数(without hand-engineering our loss functions either)。
Introduction
Many problems in image processing, computer graphics, and computer vision can be posed as “translating” an input image into a corresponding output image. Traditionally, each of these tasks has been tackled with separate, special-purpose machinery, despite the fact that the setting is always the same: predict pixels from pixels. Our goal in this paper is to develop a common framework for all these problems.
许多图像处理(image processing)、计算机图形学(computer graphics)和计算机视觉(computer vision)问题都可以被归结为迁移(translating)问题,即输入一张图,转成对应的输出——image-to-image translation。以前这些image translation虽然都是从输入图像到生成图像的映射,但它们被当做不同的问题,人们为这些问题分别设计了不同的损失函数和算法。论文认为这些问题都可以归结为像素到像素的转化,pix2pix提出了一种通用的框架。
If we take a naive approach and ask the CNN to minimize the Euclidean distance between predicted and ground truth pixels, it will tend to produce blurry results. This is because Euclidean distance is minimized by averaging all plausible outputs, which causes blurring. Coming up with loss functions that force the CNN to do what we really want – e.g., output sharp, realistic images – is an open problem and generally requires expert knowledge.
在论文发表的时候,CNN已经成为了图像处理任务中的扛鼎算法,在很多任务中都得到了应用。但尽管CNN的学习过程是自动的,人们还是要手工设计高效的损失函数,告诉CNN到底要学到什么特征。我们必须确保CNN学习的目标和我们想要达到的效果相吻合,否则就可能成为King Midas(团队之点金)。如果只用普通的CNN,不用GAN,让CNN去最小化欧氏距离(Euclidean distance,即L2距离),就会造成模糊(比如,生成的鞋与真实的鞋偏离了一个像素,那么L2距离就会非常大,这会鼓励CNN生成模糊的边界)。
It would be highly desirable if we could instead specify only a high-level goal, like “make the output indistinguishable from reality”, and then automatically learn a loss function appropriate for satisfying this goal.
能不能改用一种更高层次的目标(a high-level goal)呢?GAN就是这样的一种解决方案,它不关注于具体要怎么定义损失函数,不需要规定生成的效果如何,GAN的目标直接设定为“要让假的看起来像真的(make the output indistinguishable from reality)”。GAN不可能生成模糊的图像,否则判别器一眼就能看得出来。GAN还是自适应、自监督的——传统CNN网络设计损失函数时,我们为了引导网络朝着正确的方向训练,需要各种各样不同的先验知识,而GAN只要朝着“像真的”这一个目标努力就行了——因此GAN可以应用到各式各样的任务中。
In this paper, we explore GANs in the conditional setting. Just as GANs learn a generative model of data, conditional GANs (cGANs) learn a conditional generative model. This makes cGANs suitable for image-to-image translation tasks, where we condition on an input image and generate a corresponding output image.
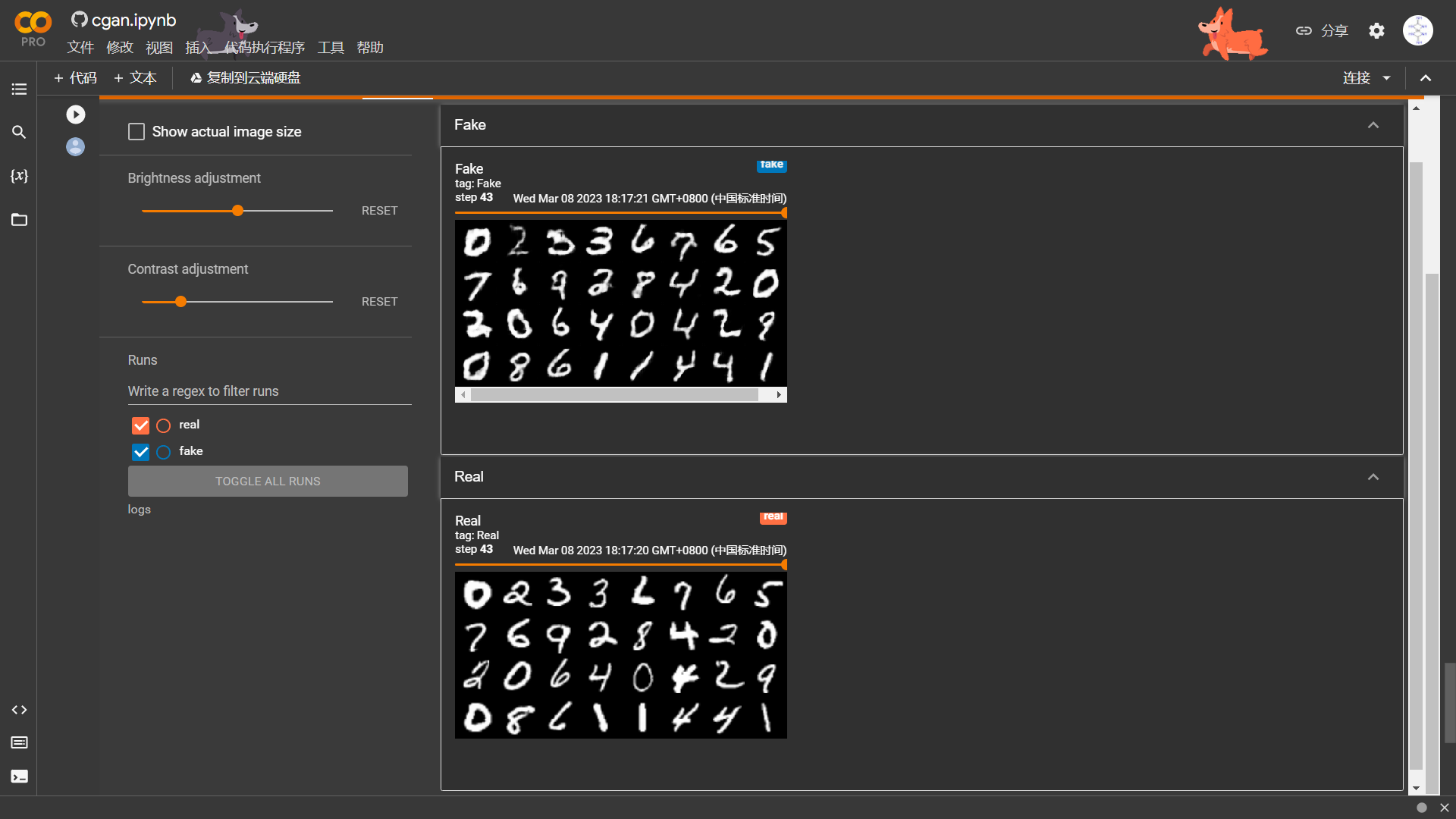
论文用的是条件GAN(Conditional-GANs),需要输入一张图像作为条件,生成输入图像对应的图像。例如cGANs最简单的应用,在MNIST数据集中,我们可以指定生成器输出一个特定的数字,就像下面图中显示的这样,Fake图像显示的数字和真实的手写数字是一样的,因为生成器是按照手写数字的label去生成的。
Our primary contribution is to demonstrate that on a wide variety of problems, conditional GANs produce reasonable results. Our second contribution is to present a simple framework sufficient to achieve good results, and to analyze the effects of several important architectural choices.
在论文发表之前,GANs已经被广泛应用,但都是用在特定任务中。论文的主要贡献是证明了在解决很大范围的一系列任务中,cGANs都可以产生不错的结果。论文的第二个贡献是提出了一个简洁的代码框架,并分析了几个重要网络结构的效果(论文给出的代码是利用Lua语言的Torch实现的)。
Related Work
Image-to-image translation problems are often formulated as per-pixel classification or regression. These formulations treat the output space as “unstructured” in the sense that each output pixel is considered conditionally independent from all others given the input image. Conditional GANs instead learn a structured loss. Structured losses penalize the joint configuration of the output.
Structured losses:像素之间不是无关的,纹理、斑块之间都是相互联系的。过去定义损失函数的时候,都是非结构化的(unstructed),只关注像素本身,而不关注它与周围像素的联系。而conditional-GANs则可以学习到一种结构化的损失函数(structed loss)。
Several other papers have also used GANs for image-to-image mappings, but only applied the GAN unconditionally, relying on other terms (such as L2 regression) to force the output to be conditioned on the input. Each of the methods was tailored for a specific application. Our framework differs in that nothing is application-specific. This makes our setup considerably simpler than most others.
Conditional GANs:论文并不是不是第一个使用cGANs的,但不同于以往为不同应用量身打造的算法,论文提出的框架适用于很多类似问题。
Our method also differs from the prior works in several architectural choices for the generator and discriminator. Unlike past work, for our generator we use a “U-Net”-based architecture, and for our discriminator we use a convolutional “PatchGAN” classifier, which only penalizes structure at the scale of image patches.
论文提出的框架在判别器和生成器的结构上也与先前的有所不同。pix2pix的生成器用的是"U-Net"-base architecture,判别器用的是"PatchGAN",把图像分成若干个小图块,论文也研究了不同大小的patch对网络效果的影响。
Method
GANs are generative models that learn a mapping from random noise vector \(z\) to output image \(y\), \(G:z \rightarrow y\). In contrast, conditional GANs learn a mapping from observed image \(x\) and random noise vector \(z\), to \(y\), \(G:\{x, z\}\rightarrow y\). The generator G is trained to produce outputs that cannot be distinguished from “real” images by an adversarially trained discriminator, D, which is trained to do as well as possible at detecting the generator’s “fakes”.
非条件GAN:\(G:z \rightarrow y\)
条件GAN:\(G:\{x, z\}\rightarrow y\),这个 \(x\) 可以是条件信息,也可以是图像之类的
Objective
\(D(x,y)\) 是判别器认为是真图的概率,\(D(x,G(x,z))\) 是判别器认为生成器生成的图像是真图的概率。判别器要最大化两个期望,而生成器则是使得 \(\mathbb{E}_{x,z}[\log(1-D(x,G(x,z)))]\) 越小越好——生成器影响不了 \(\mathbb{E}_{x,y}[\log D(x,y)]\)。这便是双人极大极小零和博弈 \(\displaystyle G^*=\arg\min_G\max_D\mathcal{L}_{cGAN}(G,D).\)
Previous approaches have found it beneficial to mix the GAN objective with a more traditional loss, such as L2 distance. The discriminator’s job remains unchanged, but the generator is tasked to not only fool the discriminator but also to be near the ground truth output in an L2 sense. We also explore this option, using L1 distance rather than L2 as L1 encourages less blurring:
还要加一个L1距离,鼓励生成图像与输入图像在像素上接近——不管是L1还是L2,都是这样的鼓励效果。论文使用L1,因为它生成的图片更不模糊一点。
最终的目标函数是:
Without \(z\), the net could still learn a mapping from \(x\) to \(y\), but would produce deterministic outputs, and therefore fail to match any distribution other than a delta function. Past conditional GANs have acknowledged this and provided Gaussian noise \(z\) as an input to the generator, in addition to \(x\). In initial experiments, we did not find this strategy effective – the generator simply learned to ignore the noise. Instead, for our final models, we provide noise only in the form of dropout, applied on several layers of our generator at both training and test time.
如果没有 \(z\),网络仍然可以学到 \(x\rightarrow y\) 的映射,但会输出确定性的输出——狄拉克函数,除了零以外的点取值都等于零,指这个结果非常的具有确定性(deterministic)。以往的cGANs公认使用高斯分布作为G的噪声输入,直接加在 \(x\) 上。论文中则没有用 \(z\)——论文用的是dropout,在生成器的某几层网络中加入dropout来引入噪声。
Designing conditional GANs that produce highly stochastic output, and thereby capture the full entropy of the conditional distributions they model, is an important question left open by the present work.
如何设计cGANs,让它生成足够高质量随机(stochastic)的输出,从而把conditional distribution全部的熵捕获下来,是未来要研究的重点。
Network architectures
We adapt our generator and discriminator architectures from those in [DCGAN]. Both generator and discriminator use modules of the form convolution-BatchNorm-ReLu.
生成器和判别器网络使用的是DCGAN论文中的结构,都是Conv-BN-ReLU的形式。
A defining feature of image-to-image translation problems is that they map a high resolution input grid to a high resolution output grid. In addition, for the problems we consider, the input and output differ in surface appearance, but both are renderings of the same underlying structure. Therefore, structure in the input is roughly aligned with structure in the output.
图像迁移问题都是从一个高分辨率输入到一个高分辨率输出的映射,它们表面样式不同,但底层纹理轮廓大致是对齐的。
Many previous solutions to problems in this area have used an encoder-decoder network. In such a network, the input is passed through a series of layers that progressively downsample, until a bottleneck layer, at which point the process is reversed. Such a network requires that all information flow pass through all the layers, including the bottleneck. For many image translation problems, there is a great deal of low-level information shared between the input and output, and it would be desirable to shuttle this information directly across the net.
To give the generator a means to circumvent the bottleneck for information like this, we add skip connections, following the general shape of a “U-Net”. Specifically, we add skip connections between each layer \(i\) and layer \(n − i\), where \(n\) is the total number of layers. Each skip connection simply concatenates all channels at layer \(i\) with those at layer \(n − i\).

很多过去的研究都是用的自编译器——图片的所有信息都会流过瓶颈层,这个瓶颈层的维度很小,因此不可避免地会带来信息的丢失。论文中引入了跳跃连接(skip connections),大致形状和U-Net类似,从而规避这样的信息瓶颈(circumvent the bottleneck for information)。论文直接用concatenate把对称的两层信息摞起来,能够使底层特征与高层特征融合。
It is well known that the L2 loss – and L1 – produces blurry results on image generation problems. Although these losses fail to encourage high-frequency crispness, in many cases they nonetheless accurately capture the low frequencies. For problems where this is the case, we do not need an entirely new framework to enforce correctness at the low frequencies. L1 will already do.
马尔科夫判别器(Markovian Discriminator)。L2(L1也不例外)会导致模糊,这让它们无法捕捉到高频边缘信息(high-frequency crispness),而只能准确地捕捉低频渐变信息(low frequencies)。论文指出我们不需要完全从新设计网络架构,如果让判别器捕捉高频,L1损失函数捕捉低频,这样我们就可以把所有信息捕捉下来了。
We design a discriminator architecture – which we term a PatchGAN – that only penalizes structure at the scale of patches. This discriminator tries to classify if each \(N×N\) patch in an image is real or fake. We run this discriminator convolutionally across the image, averaging all responses to provide the ultimate output of \(D\).
This is advantageous because a smaller PatchGAN has fewer parameters, runs faster, and can be applied to arbitrarily large images.
如何捕捉高频呢?论文中设计了局部小图块(local image patches)的结构,对 \(N\times N\) 个图块,每一个图块分别做一次二分类(classify),判断它是真的还是假的。这样做的好处是可以对图片做全卷积,对所有的结果取平均得到最终判别器的输出。论文还证明了小图块的尺度相对于整张图而言可以非常的小(比如分成 \(70\times70\),效果依旧很不错)。图块小的好处在于,网络可以运行地更快,并且可以应用于任意大小的图像输入。
Such a discriminator effectively models the image as a Markov random field, assuming independence between pixels separated by more than a patch diameter. Therefore, our PatchGAN can be understood as a form of texture/style loss.
判别器把图像建模成一个马尔科夫随机场(Markov random field),假设两个像素的距离超过一个图块的直径后是独立无关的。PatchGAN对每一小块的纹理、颜色判别真伪。
Optimization and inference
We alternate between one gradient descent step on \(D\), then one step on \(G\). As suggested in the original GAN paper, rather than training G to minimize \(\log(1 − D(x, G(x, z))\), we instead train to maximize \(\log D(x, G(x, z))\). In addition, we divide the objective by \(2\) while optimizing \(D\), which slows down the rate at which \(D\) learns relative to \(G\). We use minibatch SGD and apply the Adam solver, with a learning rate of \(0.0002\), and momentum parameters \(\beta_1 = 0.5, \beta_2 = 0.999\).
- 经典 \(\min\log(1 − D(x, G(x, z))\Leftrightarrow\max\log D(x, G(x, z))\)
- 经典的判别器loss除以 \(2\),以减慢它的训练速度
- Adam参数:学习率 \(2\times10^{-4}\),动量参数 \(\beta_1 = 0.5, \beta_2 = 0.999\)
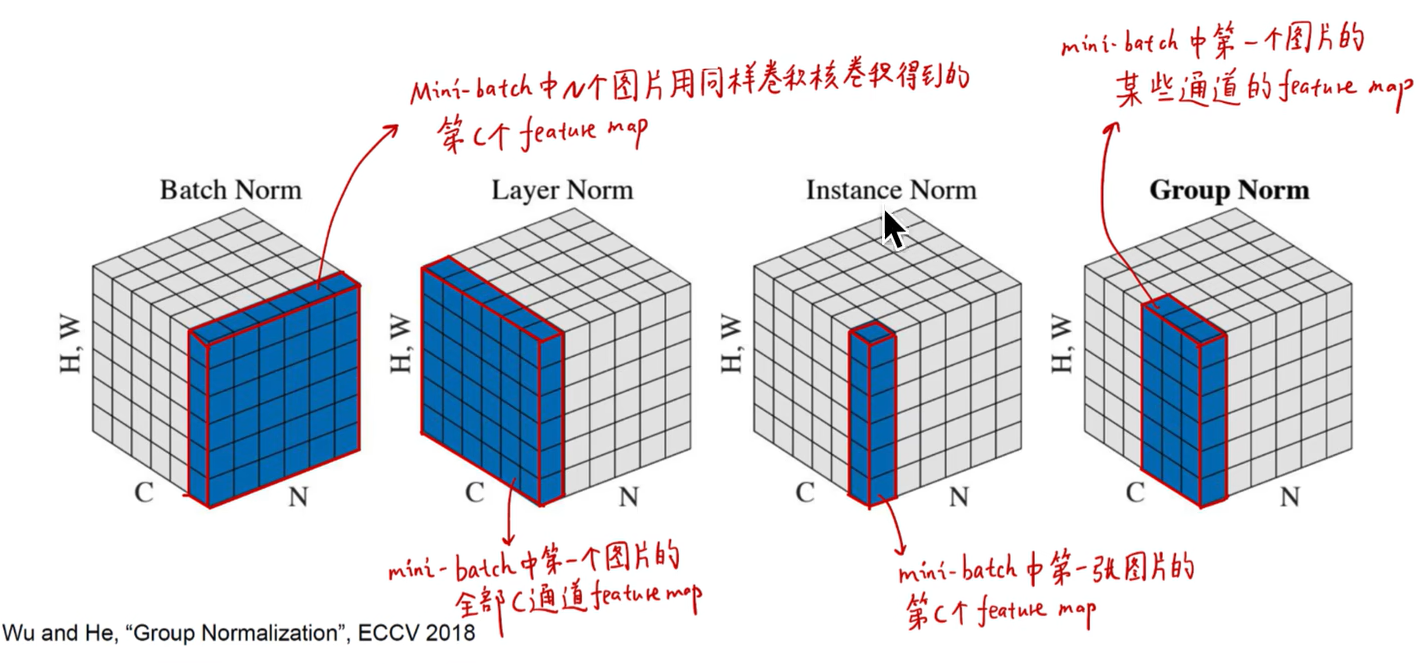
We apply dropout at test time, and we apply batch normalization using the statistics of the test batch, rather than aggregated statistics of the training batch. This approach to batch normalization, when the batch size is set to \(1\), has been termed “instance normalization”.
- Dropout以往用于训练,而我们还把它用在了测试中
- 我们用测试集的数据做Batch Normalization,而不是用训练集的数据。当batch size被设置成 \(1\) 之后,Batch Normalization就变成了Instance Normalization
Experiments
We note that decent results can often be obtained even on small datasets. Our facade training set consists of just \(400\) images, and the day to night training set consists of only \(91\) unique webcams.
小样本学习能力强,训练速度快,预测速度快。
Evaluation metrics
Evaluating the quality of synthesized images is an open and difficult problem. Traditional metrics such as per-pixel mean-squared error do not assess joint statistics of the result, and therefore do not measure the very structure that structured losses aim to capture.
传统算L1、L2之类的loss是很不科学的,要整体全面地评估。
论文提到他们用了AMT众包平台和FCN-score(FCN是一个现成的的图像分割模型,\(labels\overset{pix2pix}\rightarrow photo\overset{FCN}\rightarrow labels\),通过对labels的比对即可判定结果)。
Analysis of the objective function

| L1 | L1+cGAN | |
|---|---|---|
| Encoder-devoder | 效果最差 | 上采样时导致纹理重复(原因在于边界细节缺失) |
| U-Net | 边缘细节出现 | 效果比较不错 |

Uncertainty in the output manifests itself differently for different loss functions. Uncertain regions become blurry and desaturated under L1. The \(1\times1\) PixelGAN encourages greater color diversity but has no effect on spatial statistics. The \(16\times16\) PatchGAN creates locally sharp results, but also leads to tiling artifacts beyond the scale it can observe. The \(70\times70\) PatchGAN forces outputs that are sharp, even if incorrect, in both the spatial and spectral (colorfulness) dimensions. The full \(286\times286\) ImageGAN produces results that are visually similar to the \(70\times70\) PatchGAN, but somewhat lower quality according to our FCN-score metric.
patch数越多,生成的细节就越逼真。\(16\times16\) 会产生瓦片状的伪影,\(286\times286\) 效果和 \(70\times 70\) 接近,但在FCN-score中表现却不太好。
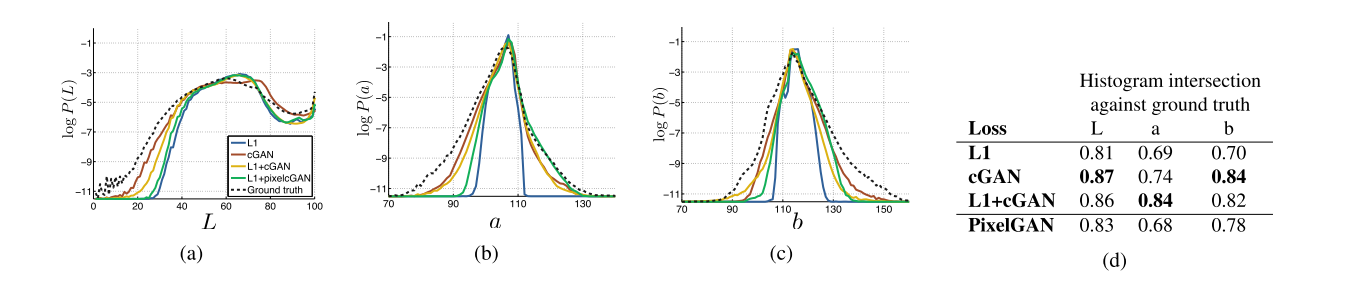
Color distribution matching property of the cGAN, tested on Cityscapes. Note that the histogram intersection scores are dominated by differences in the high probability region, which are imperceptible in the plots, which show log probability and therefore emphasize differences in the low probability regions.
L1是图中蓝线部分,可以看到在像素比较密集的地方,L1的效果还是比较接近的,但除此之外就很差了(不求无功,但求无过)。采用cGAN后还原色彩的效果较好。

This may be because minor structural errors are more visible in maps, which have rigid geometry, than in aerial photographs, which are more chaotic.
地图->航拍图相对容易骗过AMT的志愿者们;航拍图->地图就比较困难,原因可能在于,地图有很多微小的细节,难以骗过人眼——路断了,沙滩上一大片都很模糊,房子不是分开的格子,而是一片……

当然,也有些失败的图像:白天转黑夜(可能是因为有一大片区域不好处理);鞋(应该是边缘太复杂)
Conclusion
The results in this paper suggest that conditional adversarial networks are a promising approach for many imageto-image translation tasks, especially those involving highly structured graphical outputs. These networks learn a loss adapted to the task and data at hand, which makes them applicable in a wide variety of settings.
结果表明,条件GAN在很多图像迁移任务中都是一个非常有前景的方法,尤其是对于那些输出高度结构化的问题。这些网络自适应地学习任务的损失函数,这使得它们在很多场合中都有应用。
Implementation
Let Ck denote a Convolution-BatchNorm-ReLU layer with \(k\) filters. CDk denotes a Convolution-BatchNorm-Dropout-ReLU layer with a dropout rate of \(50\%\). All convolutions are \(4 × 4\) spatial filters applied with stride \(2\). Convolutions in the encoder, and in the discriminator, downsample by a factor of \(2\), whereas in the decoder they upsample by a factor of \(2\).
生成器和判别器结构(警告:图文不符,示例图仅供参考)
U-Net结构(警告:图文不符,示例图仅供参考)
Generator
class Block(nn.Module):
def __init__(self, in_channels, out_channels, down=True, act="relu", use_dropout=False):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 4, 2, 1, bias=False, padding_mode="reflect") if down else
nn.ConvTranspose2d(in_channels, out_channels, 4, 2, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU() if act == "relu" else nn.LeakyReLU(0.2)
)
self.use_dropout = use_dropout
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.conv(x)
return self.dropout(x) if self.use_dropout else x
encoder:
C64-C128-C256-C512-C512-C512-C512-C512
decoder:
CD512-CD512-CD512-C512-C256-C128-C64
After the last layer in the decoder, a convolution is applied to map to the number of output channels (\(3\) in general, except in colorization, where it is \(2\)), followed by a Tanh function. As an exception to the above notation, BatchNorm is not applied to the first C64 layer in the encoder. All ReLUs in the encoder are leaky, with slope \(0.2\), while ReLUs in the decoder are not leaky.
class Generator(nn.Module):
def __init__(self, in_channels=3, features=64):
super().__init__()
self.initial_down = nn.Sequential(
nn.Conv2d(in_channels, features, 4, 2, 1, padding_mode="reflect"),
nn.LeakyReLU(0.2)
)
self.down1 = Block(features, features * 2, down=True, act="leaky", use_dropout=False)
self.down2 = Block(features * 2, features * 4, down=True, act="leaky", use_dropout=False)
self.down3 = Block(features * 4, features * 8, down=True, act="leaky", use_dropout=False)
self.down4 = Block(features * 8, features * 8, down=True, act="leaky", use_dropout=False)
self.down5 = Block(features * 8, features * 8, down=True, act="leaky", use_dropout=False)
self.down6 = Block(features * 8, features * 8, down=True, act="leaky", use_dropout=False)
self.bottleneck = nn.Sequential(
nn.Conv2d(features * 8, features * 8, 4, 2, 1, padding_mode="reflect"),
nn.ReLU()
)
self.up1 = Block(features * 8, features * 8, down=False, act="relu", use_dropout=True)
self.up2 = Block(features * 8 * 2, features * 8, down=False, act="relu", use_dropout=True)
self.up3 = Block(features * 8 * 2, features * 8, down=False, act="relu", use_dropout=True)
self.up4 = Block(features * 8 * 2, features * 8, down=False, act="relu", use_dropout=False)
self.up5 = Block(features * 8 * 2, features * 4, down=False, act="relu", use_dropout=False)
self.up6 = Block(features * 4 * 2, features * 2, down=False, act="relu", use_dropout=False)
self.up7 = Block(features * 2 * 2, features, down=False, act="relu", use_dropout=False)
self.final_up = nn.Sequential(
nn.ConvTranspose2d(features * 2, in_channels, kernel_size=4, stride=2, padding=1),
nn.Tanh()
)
def forward(self, x):
d1 = self.initial_down(x)
d2 = self.down1(d1)
d3 = self.down2(d2)
d4 = self.down3(d3)
d5 = self.down4(d4)
d6 = self.down5(d5)
d7 = self.down6(d6)
bottleneck = self.bottleneck(d7)
up1 = self.up1(bottleneck)
up2 = self.up2(torch.cat([up1, d7], 1))
up3 = self.up3(torch.cat([up2, d6], 1))
up4 = self.up4(torch.cat([up3, d5], 1))
up5 = self.up5(torch.cat([up4, d4], 1))
up6 = self.up6(torch.cat([up5, d3], 1))
up7 = self.up7(torch.cat([up6, d2], 1))
return self.final_up(torch.cat([up7, d1], 1))
Discriminator
class Block(nn.Module):
def __init__(self, in_channels, out_channels, stride=2):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 4, stride, 1, bias=False, padding_mode="reflect"),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2)
)
def forward(self, x):
return self.conv(x)
70 × 70 discriminator architecture:
C64-C128-C256-C512
After the last layer, a convolution is applied to map to a 1-dimensional output, followed by a Sigmoid function. As an exception to the above notation, BatchNorm is not applied to the first C64 layer. All ReLUs are leaky, with slope 0.2.
class Discriminator(nn.Module):
def __init__(self, in_channels=3, features=None):
super().__init__()
if features is None:
features = [64, 128, 256, 512]
self.initial = nn.Sequential(
nn.Conv2d(in_channels * 2, features[0], kernel_size=4, stride=2, padding=1, padding_mode="reflect"),
nn.LeakyReLU(0.2)
)
layers = []
in_channels = features[0]
for feature in features[1:]:
layers.append(Block(in_channels, feature, stride=1 if feature == features[-1] else 2))
in_channels = feature
self.model = nn.Sequential(*layers)
self.final = nn.Sequential(
nn.Conv2d(in_channels, 1, kernel_size=4, stride=1, padding=1, padding_mode="reflect"),
nn.Sigmoid()
)
def forward(self, x, y):
x = torch.cat([x, y], dim=1)
x = self.initial(x)
x = self.model(x)
return self.final(x)
Train
# DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# L1_LAMBDA = 100
def train_fn(disc, gen, loader, opt_disc, opt_gen, l1, bce, g_scaler, d_scaler):
loop = tqdm(loader, leave=True)
for idx, (x, y) in enumerate(loop):
x, y = x.to(config.DEVICE), y.to(config.DEVICE)
# Train Discriminator
with torch.cuda.amp.autocast():
y_fake = gen(x)
d_real = disc(x, y)
d_fake = disc(x, y_fake.detach())
d_real_loss = bce(d_real, torch.ones_like(d_real))
d_fake_loss = bce(d_fake, torch.zeros_like(d_fake))
d_loss = (d_real_loss + d_fake_loss) / 2
opt_disc.zero_grad()
d_scaler.scale(d_loss).backward()
d_scaler.step(opt_disc)
d_scaler.update()
# Train Generator
with torch.cuda.amp.autocast():
d_fake = disc(x, y_fake)
g_fake_loss = bce(d_fake, torch.ones_like(d_fake))
l1_loss = l1(y_fake, y) * config.L1_LAMBDA
g_loss = g_fake_loss + l1_loss
opt_gen.zero_grad()
g_scaler.scale(g_loss).backward()
g_scaler.step(opt_gen)
g_scaler.update()
Datasets
pix2pix dataset
Kaggle: link.
其中Aerial->Map的预训练权重:link
Anime Sketch Colorization Pair
Kaggle: link.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号