


综合设计————职途启航
职途启航
| 数据采集项目实践 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 组名、项目简介 | 组别:数据矿工,项目需求:爬取招聘网站的求助信息、编辑信息匹配系统等,项目目标:根据求职者的个人信息为其推荐最合适的工作、根据全国各省的各行业信息为求职者提供合适的参考城市、项目开展技术路线:数据库操作:使用 pymysql 库与 MySQL 数据库进行交互,执行 SQL 查询和获取数据、Flask Web 框架:使用了 Flask 作为 Web 应用框架,用于创建 Web 服务和 API 端点 、WSGI 服务器 :pywsgi 作为 WSGI 服务器来运行 Flask 应用 |
| 团队成员学号 | 102202132郑冰智、102202131林鑫、102202143梁锦盛、102202111刘哲睿、102202122张诚坤、102202136洪金举 |
| 这个项目的目标 | 根据求职者的个人信息为其推荐最合适的工作 |
| 其他参考文献 | https://github.com/balloonwj/CppGuide |
GitHub连接:https://gitee.com/zheng-bingzhi/2022-level-data-collection/tree/master/职业规划与就业分析平台
1项目介绍:
1.1项目背景:
随着互联网技术的飞速发展,网络招聘平台如雨后春笋般涌现,为求职者和招聘者提供了一个广阔的交流平台。然而,面对海量的招聘信息,许多求职者感到迷茫,难以判断自己的技能和经验与哪些岗位相匹配。此外,不同城市的发展重点和行业特色导致相同岗位在不同地区的薪资水平和发展前景存在显著差异。因此,一个能够提供精准职位匹配和城市行业分析的工具对于求职者来说显得尤为重要。
1.2项目目标:
本项目旨在开发一个综合性的互联网招聘服务平台,通过智能算法为求职者提供个性化的职位推荐,同时分析各省份的行业发展状况,帮助求职者做出更明智的职业选择。
1.3项目功能:
- 1、职位智能匹配:
- 2、利用机器学习算法分析求职者的简历和技能,与数据库中的招聘信息进行匹配,推荐最适合的工作岗位。
- 3、城市行业分析:
- 4、收集并分析各省份的主要行业数据,包括行业规模、增长趋势、平均薪资等,为求职者提供行业发展前景的参考。
- 5、职业路径规划:根据求职者的长期职业目标和个人偏好,提供职业发展路径规划建议,包括必要的技能提升和转型建议。
- 6、用户界面:设计直观易用的用户界面,使求职者能够轻松浏览职位、查看行业分析报告和获取职业建议。
1.4系统总体结构
数据采集层:
- 通过爬取BOSS直聘和58同城等招聘网站收集薪资待遇,公司地点,公司福利等招聘信息
- 通过爬取中国数据局各省份的不同行业随时间的占比变化
- 将获取的招聘信息存储在云数据库中以便后续的匹配
前端:
- 使用HTML、JavaScript进行界面设计,实现用户与系统的交互。用户可以上传文本、图片等文件。
后端:
- 使用Python语言和Flask框架实现,调用AI接口和爬虫数据存储处理信息并匹配。
2个人分工及收获
2.1爬取招聘网页数据
2.1.1代码展示
import scrapy
from job.items import JobItem
class ScrapyjobSpider(scrapy.Spider):
name = "scrapyJob"
allowed_domains = ["www.zhipin.com"]
base_url = 'https://www.zhipin.com/web/geek/job?city=101230100&position=100309&page={}'
def start_requests(self):
url = self.base_url.format(1)
yield scrapy.Request(url,callback=self.parse)
def parse(self, response):
jobs = response.xpath("//ul[@class='job-list-box']/li")
for job in jobs:
b = 0
t = ''
item = JobItem()
item['Occupation_Name'] = job.xpath(".//span[@class='job-name']//text()").extract_first()
item['Location'] = job.xpath(".//span[@class='job-area']//text()").extract_first()
item['Salary'] = job.xpath(".//span[@class='salary']//text()").extract_first()
item['Work_Experience'] = job.xpath(".//ul[@class='tag-list']/li[1]//text()").extract_first()
item['Education'] = job.xpath(".//ul[@class='tag-list']/li[2]//text()").extract_first()
tags = job.xpath(".//div[@class='job-card-footer clearfix']//ul[@class='tag-list']//li")
for tag in tags:
if b==0:
t = tag.xpath(".//text()").extract_first()
b = b + 1
else:
t = t + '139842'+tag.xpath(".//text()").extract_first()
item['Job_Keywords'] = t
part_url = job.xpath(".//a[@class='job-card-left']/@href").extract_first()
detail_url =response.urljoin(part_url)
yield scrapy.Request(
url=detail_url,
callback=self.parse_detail,
meta={'item' : item}
)
def parse_detail(self,response):
a = 0
w = ''
t = ''
item =response.meta['item']
texts = response.xpath("//div[@class='job-detail-section']//div[@class='job-sec-text']//text()")
for text in texts:
t = t + text.extract()
item['Details'] = t
welfares = response.xpath(".//div[@class='job-tags']//span")
for welfare in welfares:
if a == 0:
w = welfare.xpath(".//text()").extract_first()
a = a + 1
else:
w = w + '139842' + welfare.xpath(".//text()").extract_first()
item['Company_welfare'] = w
item['Company_Name'] = response.xpath("//li[@class='company-name']//text()").extract()[1]
part_url = response.xpath("//a[@class='look-all'][@ka='job-cominfo']/@href").extract_first()
image_url = response.urljoin(part_url)
yield scrapy.Request(
url = image_url,
callback=self.parse_image,
meta={'item' : item}
)
def parse_image(self,response):
a = 0
item = response.meta['item']
img_url = ''
t = ''
images = -1
if len(response.xpath("//ul[@class='swiper-wrapper swiper-wrapper-row']//li")) > 0:
images = response.xpath("//ul[@class='swiper-wrapper swiper-wrapper-row']//li")
if len(response.xpath("//ul[@class='swiper-wrapper swiper-wrapper-col']//li")) > 0:
images = response.xpath("//ul[@class='swiper-wrapper swiper-wrapper-col']//li")
texts = response.xpath("//div[@class='job-sec']//div[@class='text fold-text']//text()")
for text in texts:
t = t + text.extract()
item['Company_Profile'] = t
if images != -1:
for image in images:
if a ==0:
img_url = image.xpath(".//img/@src").extract_first()
a = a + 1
else:
img_url = img_url +'139842'+image.xpath(".//img/@src").extract_first()
item['Company_Photo'] = img_url
yield item
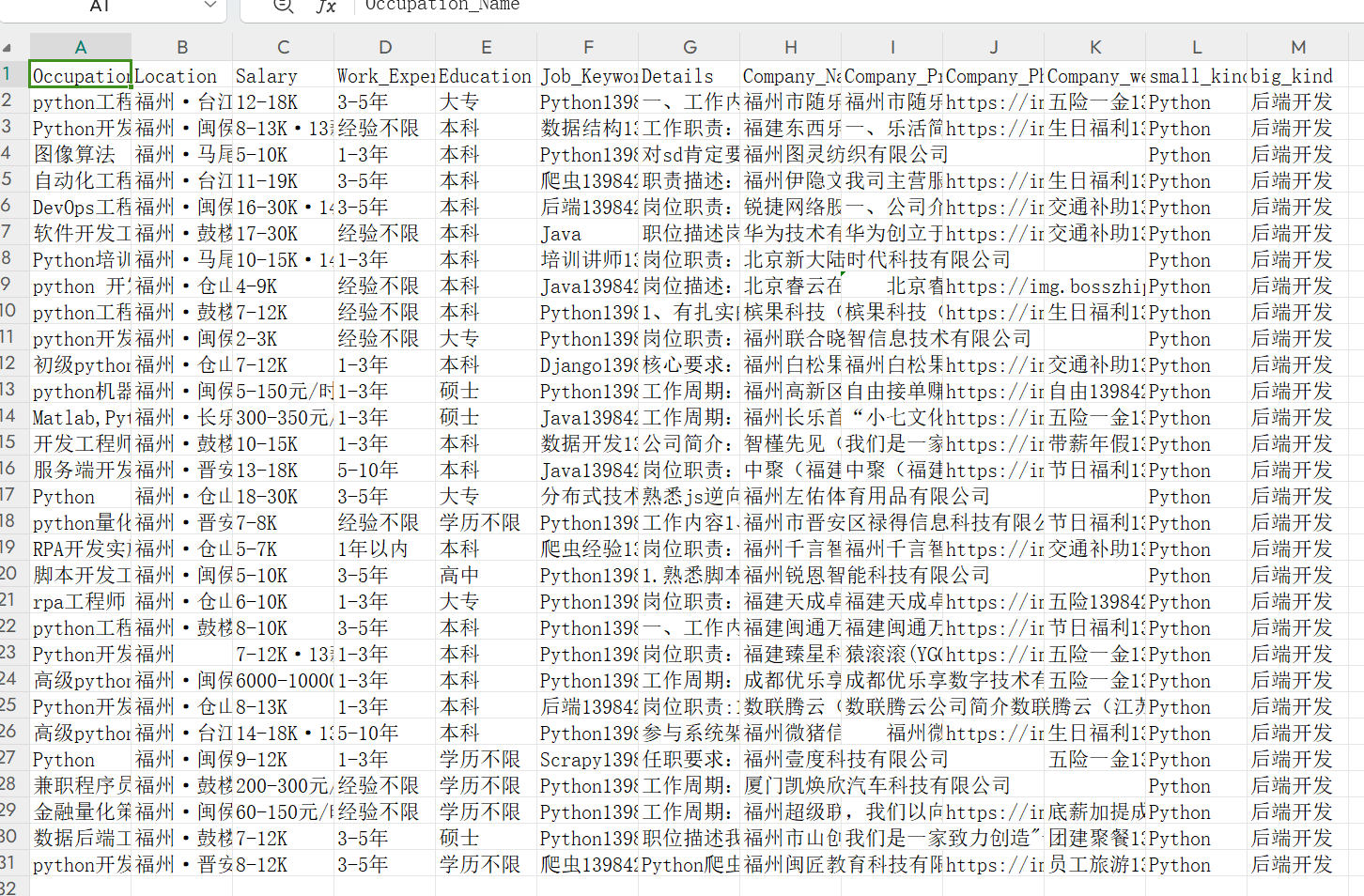
2.1.2成果展示
2.2数据可视化
2.2.1部分代码展示
2.2.2成果展示:![]()
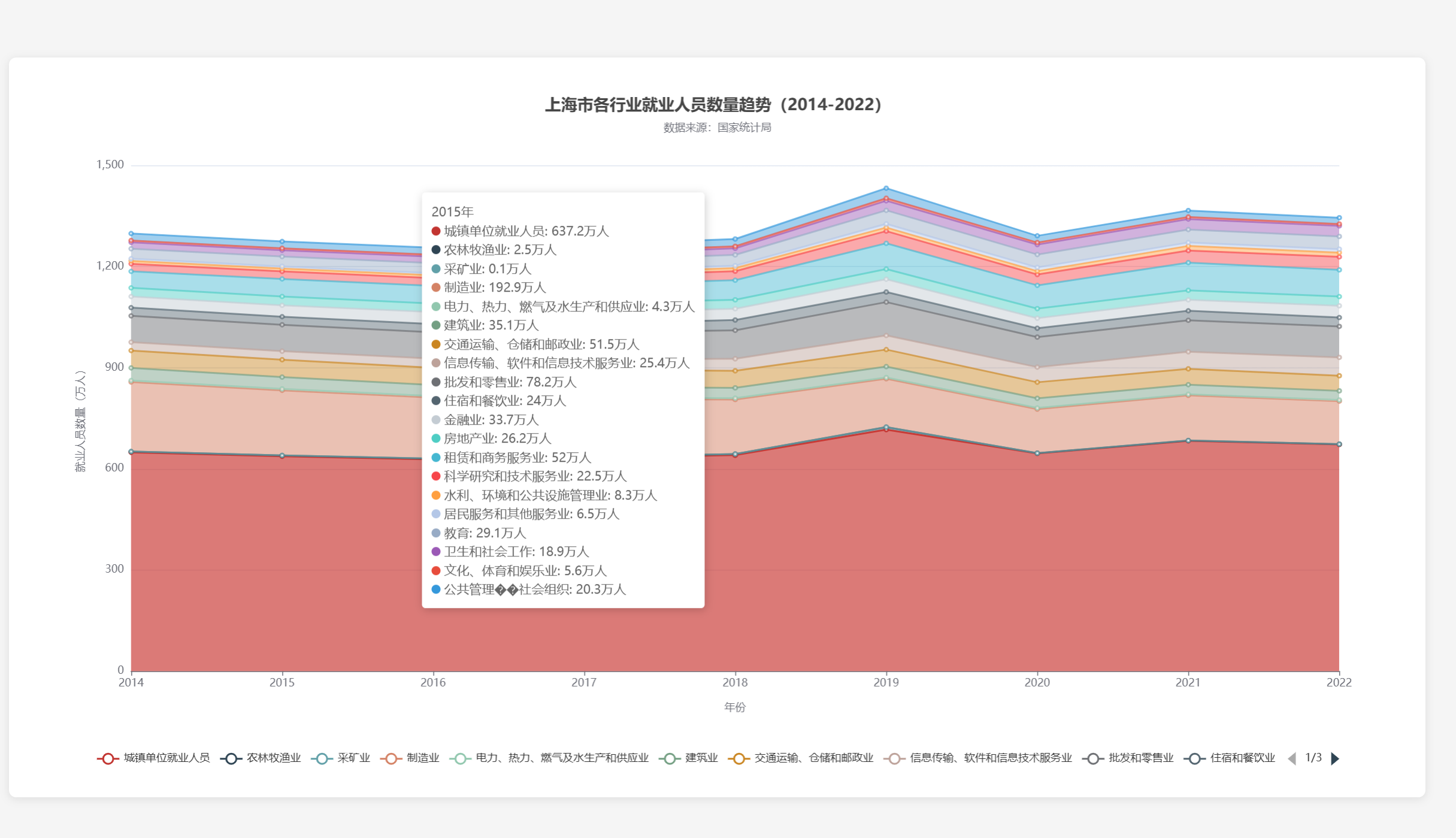
2.2.3遇到的问题:在实现可视化的过程中一开始发现在众多数据的背景下难以很好的表现各个行业的情况(比如使用折线图由于数据众多会显得交错复杂)
2.2.4解决方案:通过试验一个个可视化模型后,最终选择一个能很好表示各行业占比的模式,就是堆叠面积图
2.2.3
-
心得体会:数据理解能力提升:通过采集工作,我能够更深入地理解数据的结构和内容,这有助于在项目中做出更准确的决策。
-
技术技能增强:学习和应用数据采集工具(如 BeautifulSoup、Scrapy 或 APIs)和可视化库(如 Matplotlib、Seaborn 或 Plotly)能够增强我的技术技能。
-
分析能力提高:可视化数据可以帮助我发现数据中的模式、趋势和异常,从而提高我的数据分析能力。
-
沟通和表达能力:通过创建图表和图形来展示数据,我可以更有效地与团队成员和利益相关者沟通复杂信息。
-
问题解决策略:在数据采集和可视化过程中遇到的问题可以锻炼我的问题解决能力,比如数据清洗、处理缺失值和异常值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号