

使用Solr构建企业级的全文检索(二)---------管理界面简介
昨天这个系列开篇了,今天就趁热打铁吧。有一点要注意的是,一开始我是在64位的Windows 7上的Tomcat中部署Solr的,在使用过程中发现非常的不稳定,经常添加两个文档或者是查询一两次后,tomcat就崩溃了,让我对Solr的稳定性很是担忧,又来部署到虚拟机中的CentOS上,非常的稳定又高效。在Windows 7上为什么不稳定,我没有去分析,可能是因为各个组件的版本间的问题吧。如果哪位同学希望在Tomcat中部署Solr,请参考《Solr with Apache Tomcat》或者《在tomcat上部署solr 》。如果使用Tomcat,一定不要忘记在server.xml文件中connector节点中添加URIEncoding="UTF-8",否则你在做中文检索的时候就会出问题。
现在环境已经搭建了好,我们通过http://localhost:8983/slor/admin地址来访问Solr的管理页面,如下:
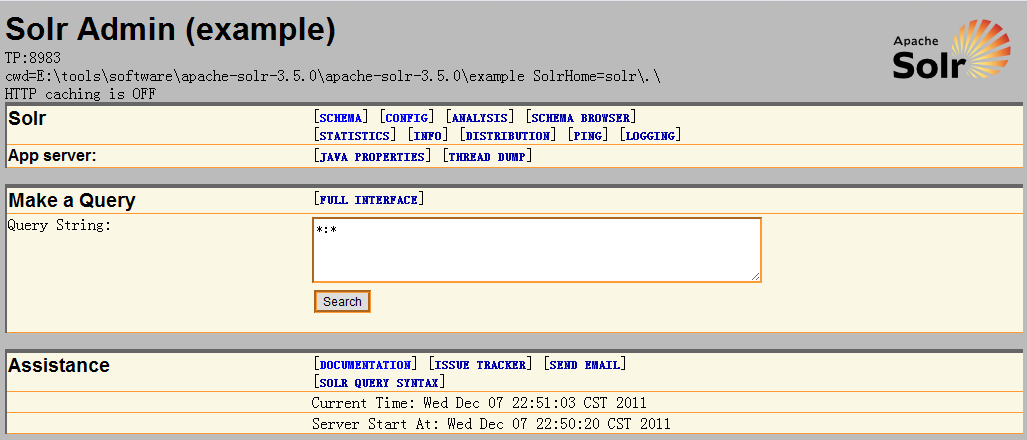
简要的介绍一下这个管理界面吧,首先是Schema,点击这个链接可以看到Solr的conf目录下的schema.xml文件的内容,从这里看到的内容和从Schema Browser链接里看到的内容是一致的,只是形式不同,SCHEMA BROWSER看到的更友好一些,儿SCHEMA里看到的就是原本的schema.xml的文本。在这两个地方你都不能修改里面的内容。Schema文件定义了Solr里面存储的文档的字段类型以及字段,这个我们后边会详细讲。
ANALYSIS这个链接是用来帮助你开发和调试的,如下图:
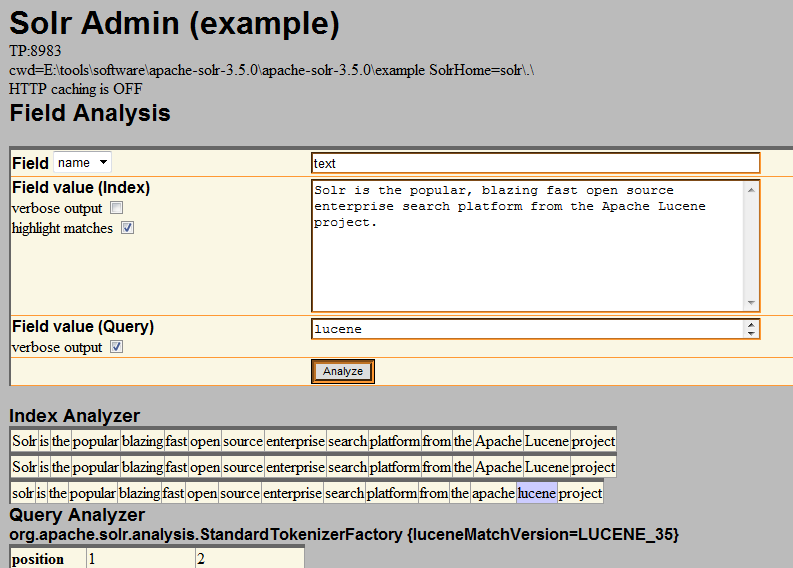
在这里你可以很方便的测试你定义的字段类型以及字段是否正确,你指定字段,然后在Field Value(Index)中放入你期望分析的文档内容,在Field Value(query)中放入你期望检索的词,点即Analyze按钮,下边就会出现文档是如何进行分词的,然后你检索的词命中的话就会高亮显示。这个工具对于我们进行字段定义,配置是很有用的。
STATISTICS,顾名思义就是统计信息,在这里你可以看到在Solr里面索引了多少文档,各种Handler的处理情况,比如搜索处理器,每秒钟处理多少个响应,每个响应使用了多长时间,还有Cache的使用情况,比如林林种种的Cache是如何设置的,Cache的命中率如何,命中次数如何,自热的次数以及自热的用时等等,这些信息对日后的性能调校是又很大的用处的。
INFO的用处不太大,从这里面你可以看到Solr内部的这个种Handler是如何配置的。
Distribution 是用来查看Solr的分布式设置的,从这里你可以看到当前的Solr实例是Master Server还是Slave Server,系统是如何分布的。分布式正是Solr的强大之处,利用这些特性你可以很方便的Scale up或者Scale out你的系统。
在LOGGING里,你可以设定哪些日志是需要输出的。
最后介绍一下管理界面中的一个重要的组成部分,就是Make a Query,如果你仅仅只是想看看现在solr里面是否能检索到某个词,就可以直接在这里输入,然后查看结果,比如输入“text:lucene”,就是查询在text字段的内容中包含lucene这个单词的文档。这里能使用的功能十分有限,相当于仅仅只发送给Solr了q参数的内容。如果你想使用更复杂的查询,那么点击Make a Query 右边的FULL INTERFACE,会出现下边的界面:
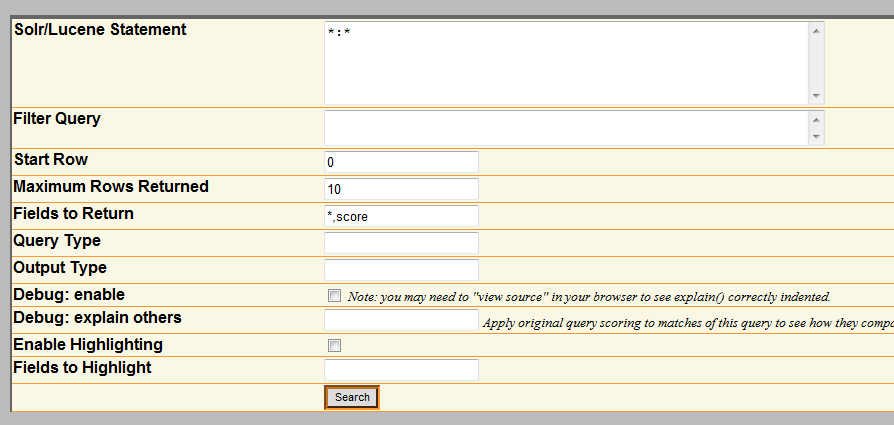
不要被这个FULL INTERFACE给忽悠了,以为这就是Solr全部的查询功能,其实,除了debug参数,这里面不过依次列出了q,fq,start,rows,fl,qt,hl,hl.fl参数,二实际上lucene/Solr提供的的查询参数是数倍于这些。所以这个应付简单的查询还可以,复杂的查询,可以通过查询结果的地址栏手动修改吧,如下图:
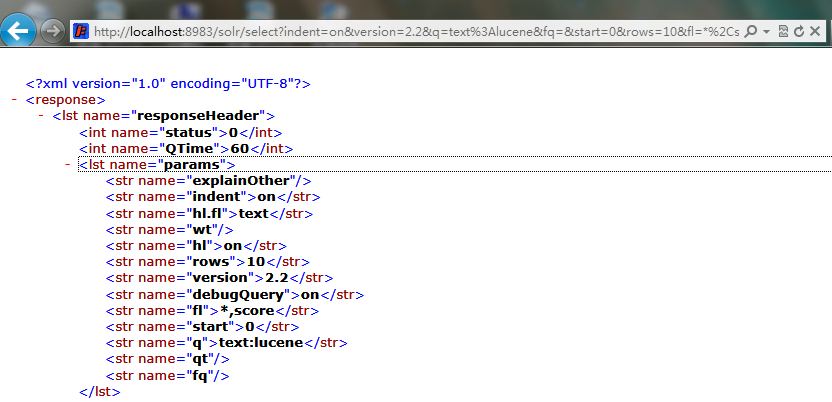
好了,天色已晚,今天就写到这里吧,接下来讲解schema的定义

 浙公网安备 33010602011771号
浙公网安备 33010602011771号