排序算法之快速排序
一、算法思想
快速排序(Quick Sort)使用分治法策略。它的基本思想是:选择一个基准数,通过一趟排序将要排序的数据分割成独立的两部分;其中一部分的所有数据都比另外一部分的所有数据都要小。然后,再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
二、算法流程
(1) 从数列中挑出一个基准值。
(2) 将所有比基准值小的摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边);在这个分区退出之后,该基准就处于数列的中间位置。
(3) 递归地把"基准值前面的子数列"和"基准值后面的子数列"进行排序。
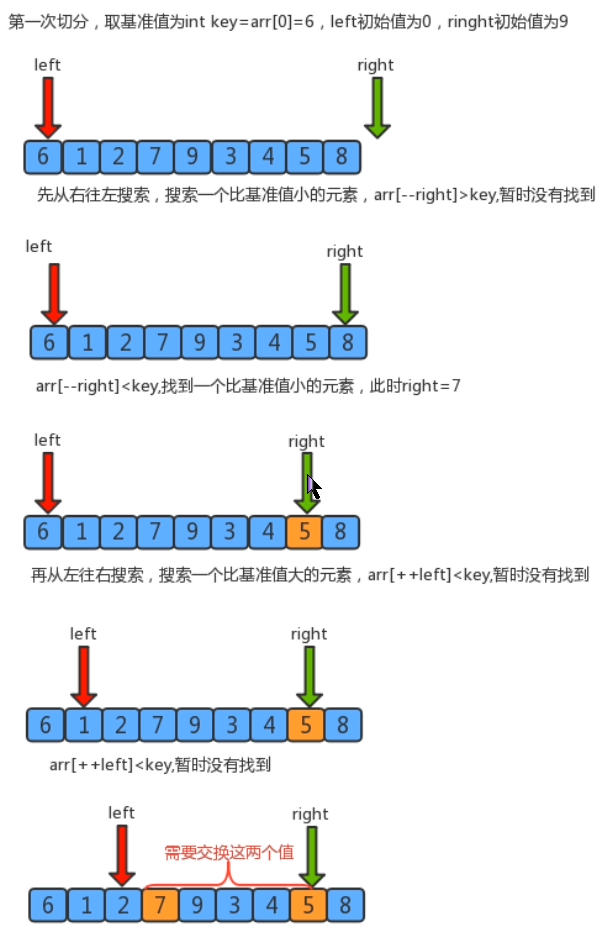
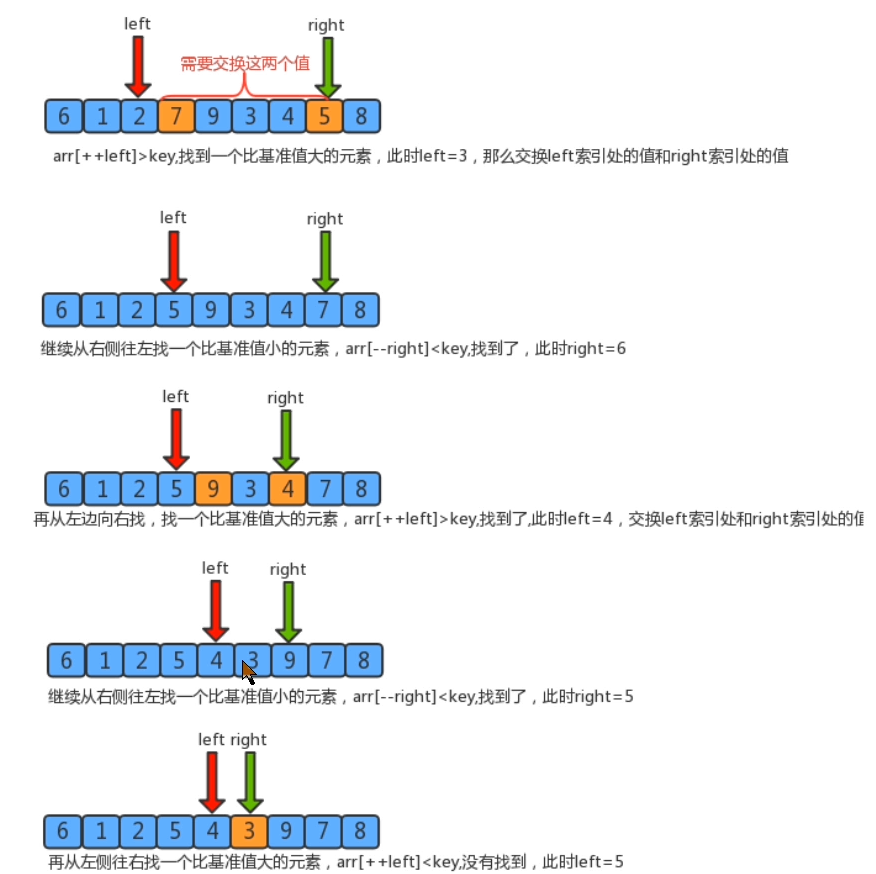
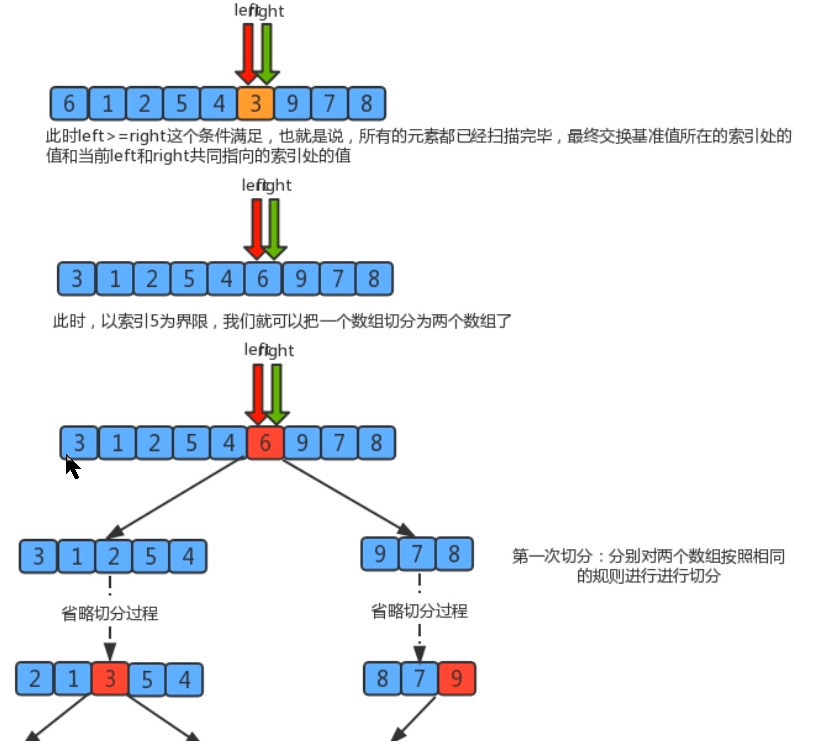
三、算法实现
1 //快速排序 2 static class QuickSort implements Sort { 3 @Override 4 public String sortName() { 5 return "快速排序"; 6 } 7 @Override 8 public Comparable[] sort(Comparable[] data) { 9 int lo = 0, hi = data.length - 1; 10 sort(data, lo, hi); 11 return data; 12 } 13 //递归体 14 private static void sort(Comparable[] data, int lo, int hi) { 15 if(hi <= lo) return; 16 int partition = partition(data, lo, hi); 17 sort(data, lo, partition - 1); 18 sort(data, partition + 1, hi); 19 } 20 //分组 21 private static int partition(Comparable[] data, int lo, int hi) { 22 //确定分界值 23 Comparable key = data[lo]; 24 //定义两个指针,分别指向待切分元素的最小索引处和最大索引处的下一个位置 25 int left = lo, right = hi + 1; 26 //切分 27 while(true) { 28 //先从左往右扫描,移动right指针,找到一个比分界值小的元素,停止 29 while(!Sort.greater(key, data[--right])) { 30 if(right == lo) break; 31 } 32 //再从左往右扫描,移动left指针,找到一个比分界值大的元素,停止 33 while(!Sort.greater(data[++left], key)) { 34 if(left == hi) break; 35 } 36 //判断left>=right,如果是,则证明元素扫描完毕,结束循环,如果不是,则交换元素即可 37 if(left >= right) { 38 break; 39 } else { 40 Sort.swap(data, left, right); 41 } 42 } 43 //交换分界值 44 Sort.swap(data, lo, right); 45 return right; 46 } 47 }
四、算法分析
复杂度
因为快速排序有两个主要操作,所以分析时间复杂度的时候咱们也是从这两个操作着手。
首先是切割操作,对于长度为 的队列,切割操作有两种可能:
:不执行切割操作,所以时间复杂度为常数 1
:执行切割操作,因为
接着是递归操作,设对于长度为 的队列递归操作的时间复杂度为
,执行切割操作后其中一个子队列的长度为
。
那么根据递归操作的逻辑,咱们可以得出递归操作的时间复杂度计算公式:
分析完两个主要操作的时间复杂度之后,咱们就可以开始从整体上分析快排的时间复杂度了。快排的时间复杂度分析分三种情况:最坏、最好和平均。
- 最坏:每次都只切割出一个子队列,即
。这时候每次递归操作的时间复杂度
,所以对于长度为
的队列来说,快排最坏情况下的时间复杂度
,即
- 最好:每次都对半切割,即
,总共会执行
次递归。这时候每次递归操作的时间复杂度
,而
,代入
可得
……
所以最好情况下快排的时间复杂度为 - 平均:每次都随机切割,即
。这时候每次递归操作的时间复杂度
,最后得出时间复杂度约为
。
稳定性
快速排序出于性能上的考虑,牺牲了算法的稳定性。虽然可以改变交换规则,使得算法保持稳定性,但却牺牲了性能,对于一个排序算法而言,这是得不偿失的,除非是上下文有稳定性方面的需求,否则,不建议改变交换规则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号